

 猿柒
猿柒





实战干货|Spark 在袋鼠云数栈的深度探索与实践
Spark 是一个快速、通用、可扩展的大数据计算引擎,具有高性能、易用、容错、可以与 Hadoop 生态无缝集成、社区活跃度高等优点。在实际使用中,具有广泛的应用场景: · 数据清洗和预处理:在大...
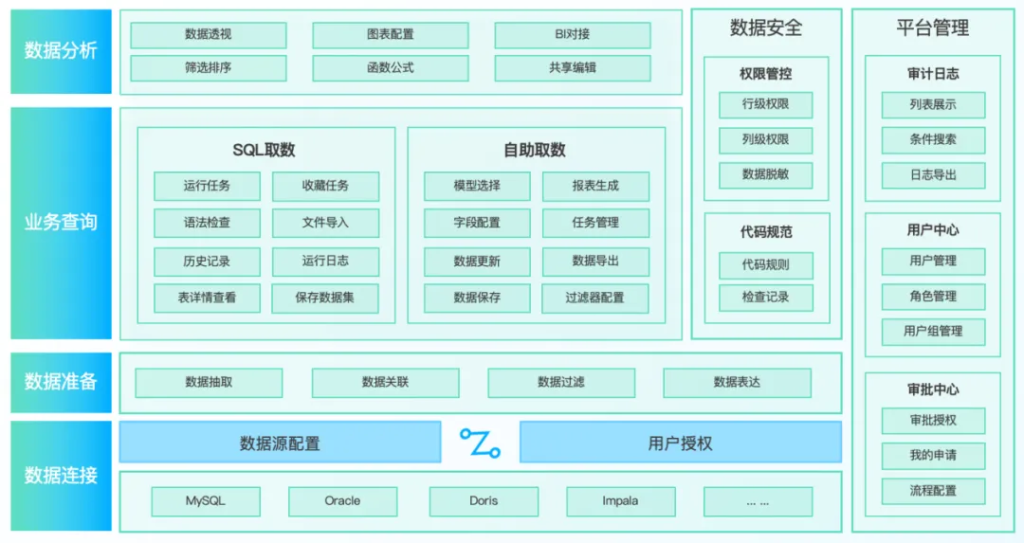
金融案例:统一查询方案助力数据治理与分析应用更高效、更安全
随着企业数据规模的增长和业务多元化发展,海量数据实时、多维地灵活查询变成业务常见诉求。同时多套数据库系统成为常态,这既带来了数据管理的复杂性,又加大了数据使用的难度,面对日益复杂的...

SQL窗口分析函数使用详解系列三之偏移量类窗口函数
1.综述 本文以HiveSQL语法进行代码演示。 对于其他数据库来说同样也适用,比如SparkSQL,FlinkSQL以及Mysql8,Oracle,SqlServer等传统的关系型数据库。 已更新第一类聚合函数类,点击这里阅读 ...

OLAP开源引擎对比之历史概述
前言 OLAP概念诞生于1993年,工具则出现在更早以前,有史可查的第一款OLAP工具是1975年问世的Express,后来走进千家万户的Excel也可归为此类,所以虽然很多数据人可能没听过OLAP,但完全没打过...

什么是SQL 语句中相关子查询与非相关子查询
1.什么是SQL子查询 要理解相关子查询和非相关子查询,我们得首先理解什么是子查询,子查询是指在一个查询语句中嵌套的另一个查询语句。 子查询可以嵌套在其他查询语句中,如 SELECT、INSERT、UP...
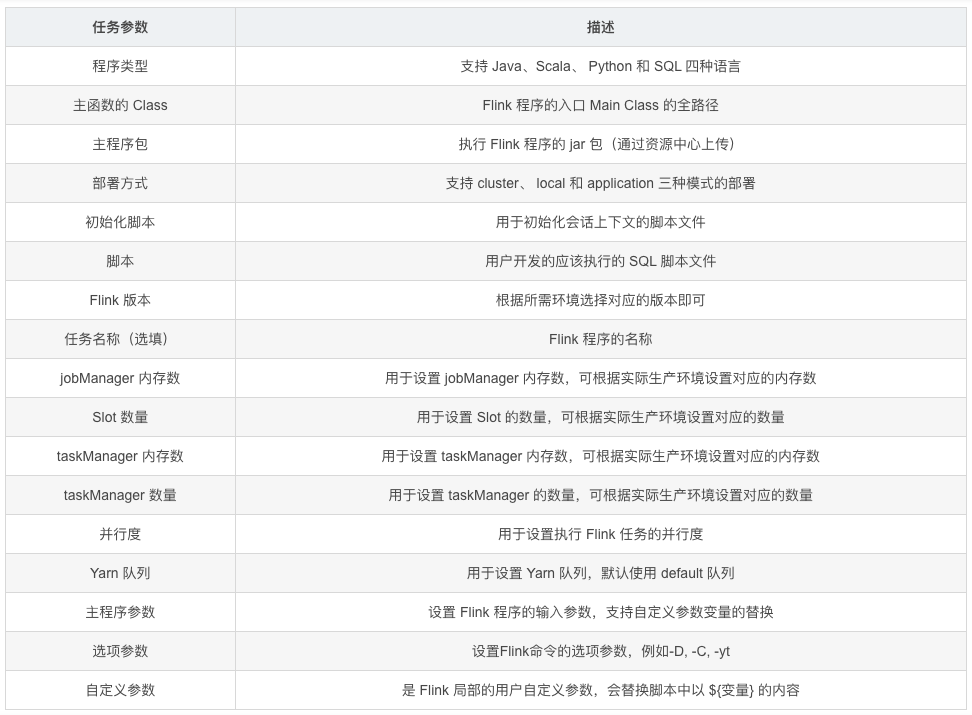
Apache DolphinScheduler支持Flink吗?
随着大数据技术的快速发展,很多企业开始将Flink引入到生产环境中,以满足日益复杂的数据处理需求。而作为一款企业级的数据调度平台,Apache DolphinScheduler也跟上了时代步伐,推出了对Flink...

Apache SeaTunnel k8s 集群模式 Zeta 引擎部署指南
SeaTunnel提供了一种运行Zeta引擎(cluster-mode)的方法,可以让Kubernetes在本地运行Zeta引擎,实现更高效的应用程序部署和管理。在本文中,我们将探索SeaTunnel k8s运行zeta引擎(cluster-mode...

大数据怎么学?对大数据开发领域及岗位的详细解读,完整理解大数据开发领域技术体系
经常有小伙伴和我咨询大数据怎么学,我觉得有必要写一下关于大数据开发的具体方向,下次就不用苦哈哈的打字回复了。直接回复文章。 1.大数据岗位划分 我们通常说的大数据开发主要分为三大方向:...
基于Hadoop实现的对历年四级单词的词频分析(入门级Hadoop项目)
前情提要:飞物作者屡次四级考试未能通过,进而恼羞成怒,制作了基于Hadoop实现的对历年四级单词的词频分析项目,希望督促自己尽快通过四级(然而并没有什么卵用) 项目需求:Pycharm、IDEA、Li...

Spark中的闭包引用和广播变量
闭包引用 概念 所有编程语言都有闭包的概念,闭包就是在一个函数中引用了函数外的变量。 Spark中,普通的变量是在Driver程序中创建的,RDD的计算是在分布式集群中的task程序上进行的。因此,当...
