

 猿柒
猿柒





指标+AI:迈向智能化,让指标应用更高效
近日,以“Data+AI,构建新质生产力”为主题的袋鼠云春季发布会圆满落幕,大会带来了一系列“+AI”的数字化产品与最新行业沉淀,旨在将数据与AI紧密结合,打破传统的生产力边界,赋能企业实现更...

对接HiveMetaStore,拥抱开源大数据
本文分享自华为云社区《对接HiveMetaStore,拥抱开源大数据》,作者:睡觉是大事。 1. 前言 适用版本:9.1.0及以上 在大数据融合分析时代,面对海量的数据以及各种复杂的查询,性能是我们使用一...

用DolphinScheduler轻松实现Flume数据采集任务自动化!
转载自天地风雷水火山泽 目的 因为我们的数仓数据源是Kafka,离线数仓需要用Flume采集Kafka中的数据到HDFS中。 在实际项目中,我们不可能一直在Xshell中启动Flume任务,一是因为项目的Flume任务...

利用 Amazon EMR Serverless、Amazon Athena、Apache Dolphinscheduler 以及本地 TiDB 和 HDFS 在混合部署环境中构建无服务器数据仓库(一)云上云下数据同步方案设计
引言 在数据驱动的世界中,企业正在寻求可靠且高性能的解决方案来管理其不断增长的数据需求。本系列博客从一个重视数据安全和合规性的 B2C 金融科技客户的角度来讨论云上云下混合部署的情况下如...

实战干货|Spark 在袋鼠云数栈的深度探索与实践
Spark 是一个快速、通用、可扩展的大数据计算引擎,具有高性能、易用、容错、可以与 Hadoop 生态无缝集成、社区活跃度高等优点。在实际使用中,具有广泛的应用场景: · 数据清洗和预处理:在大...
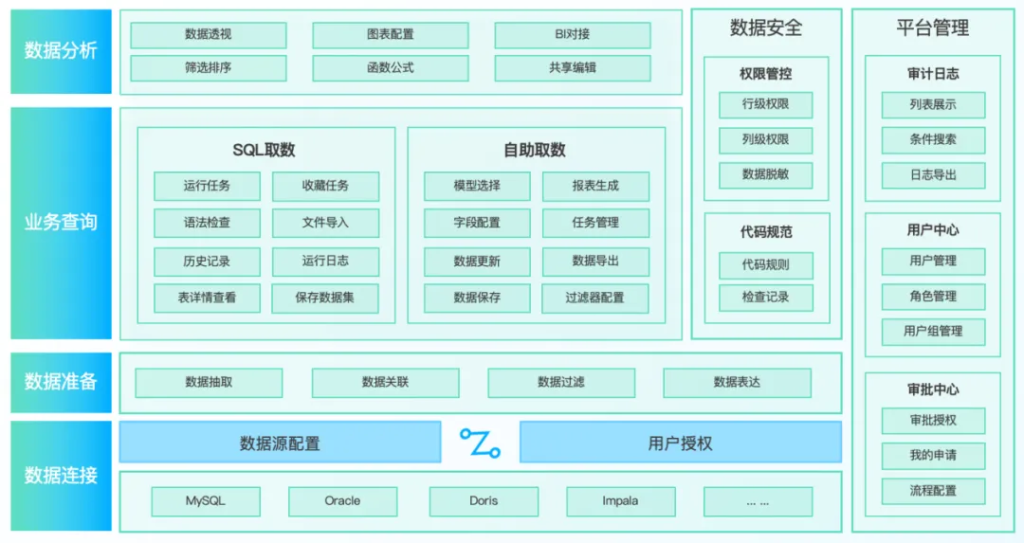
金融案例:统一查询方案助力数据治理与分析应用更高效、更安全
随着企业数据规模的增长和业务多元化发展,海量数据实时、多维地灵活查询变成业务常见诉求。同时多套数据库系统成为常态,这既带来了数据管理的复杂性,又加大了数据使用的难度,面对日益复杂的...

SQL窗口分析函数使用详解系列三之偏移量类窗口函数
1.综述 本文以HiveSQL语法进行代码演示。 对于其他数据库来说同样也适用,比如SparkSQL,FlinkSQL以及Mysql8,Oracle,SqlServer等传统的关系型数据库。 已更新第一类聚合函数类,点击这里阅读 ...

OLAP开源引擎对比之历史概述
前言 OLAP概念诞生于1993年,工具则出现在更早以前,有史可查的第一款OLAP工具是1975年问世的Express,后来走进千家万户的Excel也可归为此类,所以虽然很多数据人可能没听过OLAP,但完全没打过...

什么是SQL 语句中相关子查询与非相关子查询
1.什么是SQL子查询 要理解相关子查询和非相关子查询,我们得首先理解什么是子查询,子查询是指在一个查询语句中嵌套的另一个查询语句。 子查询可以嵌套在其他查询语句中,如 SELECT、INSERT、UP...
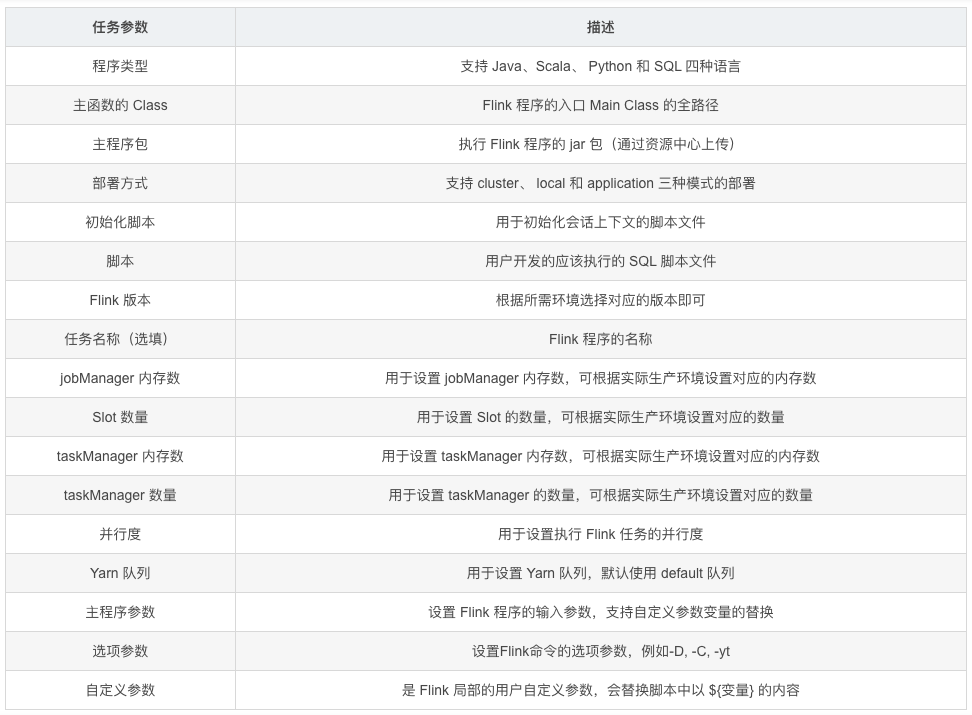
Apache DolphinScheduler支持Flink吗?
随着大数据技术的快速发展,很多企业开始将Flink引入到生产环境中,以满足日益复杂的数据处理需求。而作为一款企业级的数据调度平台,Apache DolphinScheduler也跟上了时代步伐,推出了对Flink...
