



聚类是如何度量数据间的“远近”的?
在聚类分析中,距离度量是核心概念之一,它决定了数据点之间的相似性或差异性,从而影响聚类结果的质量。 选择合适的距离度量方法,就像为数据选择合适的“观察视角”,能够帮助我们发现隐藏的...

集成学习常用组合策略:让多个模型“合作”得更好
集成学习通过组合多个学习器的预测结果,达到超越单个学习器的效果。 就像医生会诊时综合多位专家的意见,集成学习的关键在于如何有效整合不同学习器的判断。 这些学习器可以是不同类型的模型,...

你的聚类模型靠谱吗?5大外部指标彻底揭秘
在聚类分析中,我们常常需要评估聚类结果的质量。 外部指标是一种通过与已知的“真实标签”进行比较来评估聚类性能的方法。 这些指标可以帮助我们判断聚类算法是否能够准确地将数据划分为有意义...

从“朴素”到“半朴素”:贝叶斯分类器的进阶之路
在机器学习分类任务中,朴素贝叶斯(Naive Bayes)因其简单高效而广受欢迎,但它的“朴素”之名也暗示了其局限性。 为了突破这一局限,半朴素贝叶斯(Semi-Naive Bayes) 应运而生。 本文将详细...
降维技术:带你走进数据的“瘦身”世界
在机器学习和数据分析中,数据的维度常常是一个让人头疼的问题。 想象一下,你面前有一张包含成千上万列特征的表格,每一列都可能是一个重要的信息源,但同时也会让计算变得异常复杂。 这时候,...

线性判别分析(LDA):降维与分类的完美结合
在机器学习领域,线性判别分析(Linear Discriminant Analysis,简称LDA)是一种经典的算法,它在降维和分类任务中都表现出色。 LDA通过寻找特征空间中能够最大化类间方差和最小化类内方差的方...

概率图模型:机器学习的结构化概率之道
当复杂世界的不确定性遇上图的结构化表达,概率图模型应运而生。 它可以帮助我们理解和建模变量之间的复杂关系。 想象一下,你正在尝试预测明天的天气,你需要考虑温度、湿度、气压等多种因素,...
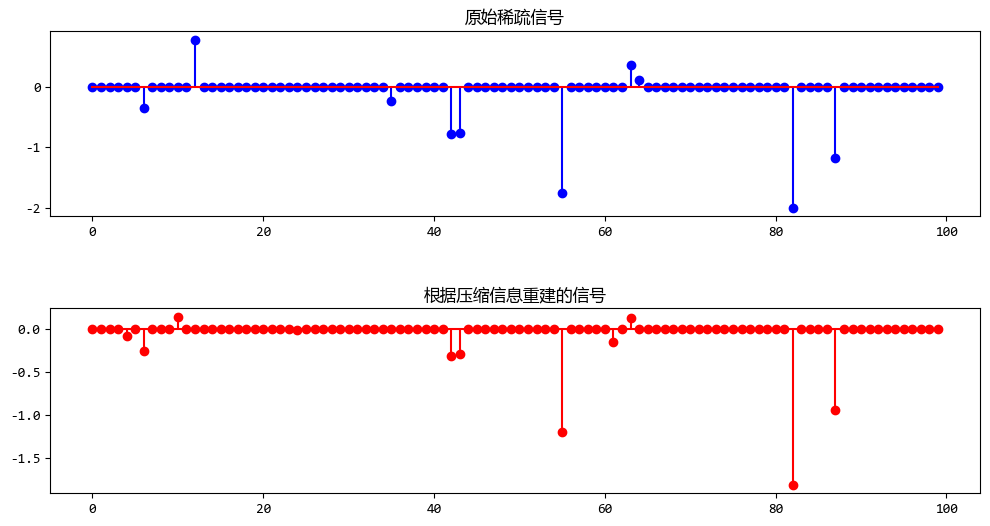
当机器学习遇见压缩感知:用少量数据重建完整世界
在数据处理的世界里,我们常常会遇到这样的问题:数据量太大,存储和传输成本高昂,但又不能丢失重要信息。 这时候,压缩感知(Compressive Sensing,CS)就像一位神奇的“数据魔法师”,能够帮...

稀疏表示与字典学习:让数据“瘦身”的魔法
在机器学习的世界里,我们常常会遇到各种复杂的数据,它们可能包含大量的特征,但其中真正有用的信息却很少。 这就像是在一个杂乱无章的房间里,我们只需要找到那些真正重要的物品,而忽略掉那...

当决策树遇上脏数据:连续值与缺失值的解决方案
在机器学习中,决策树算法因其简单易懂、可解释性强而被广泛应用。 然而,现实世界中的数据往往复杂多变,尤其是连续值和缺失值的存在,给决策树的构建带来了诸多挑战。 连续值(如年龄、收入)...
