



线性判别分析(LDA):降维与分类的完美结合
在机器学习领域,线性判别分析(Linear Discriminant Analysis,简称LDA)是一种经典的算法,它在降维和分类任务中都表现出色。 LDA通过寻找特征空间中能够最大化类间方差和最小化类内方差的方...

决策树:机器学习中的“智慧树”
在机器学习的广阔森林中,决策树(Decision Tree)是一棵独特而强大的“智慧树”。 它是一种监督学习算法,既可以用于分类任务,也能用于回归任务,通过树形结构模拟人类决策过程。 这篇文章会...

你的聚类模型靠谱吗?5大外部指标彻底揭秘
在聚类分析中,我们常常需要评估聚类结果的质量。 外部指标是一种通过与已知的“真实标签”进行比较来评估聚类性能的方法。 这些指标可以帮助我们判断聚类算法是否能够准确地将数据划分为有意义...
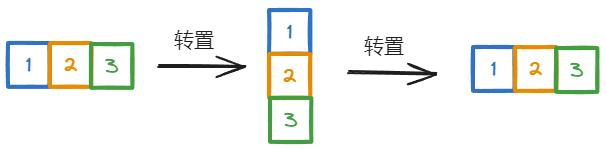
机器学习的数学基础–向量,矩阵
机器学习与传统编程的一个重要区别在于机器学习比传统编程涉及了更多的数学知识。不过,随着机器学习的飞速发展,各种框架应运而生,在数据分析等应用中使用机器学习时,使用现成的库和框架成为...

集成学习中的多样性密码:量化学习器的多样性
在集成学习中,多样性是一个关键概念,简单来说,多样性衡量的是各个学习器之间的差异程度。 如果学习器之间差异很大,那么它们的组合就更有可能覆盖更多的情况,从而提高集成模型的性能, 就像...
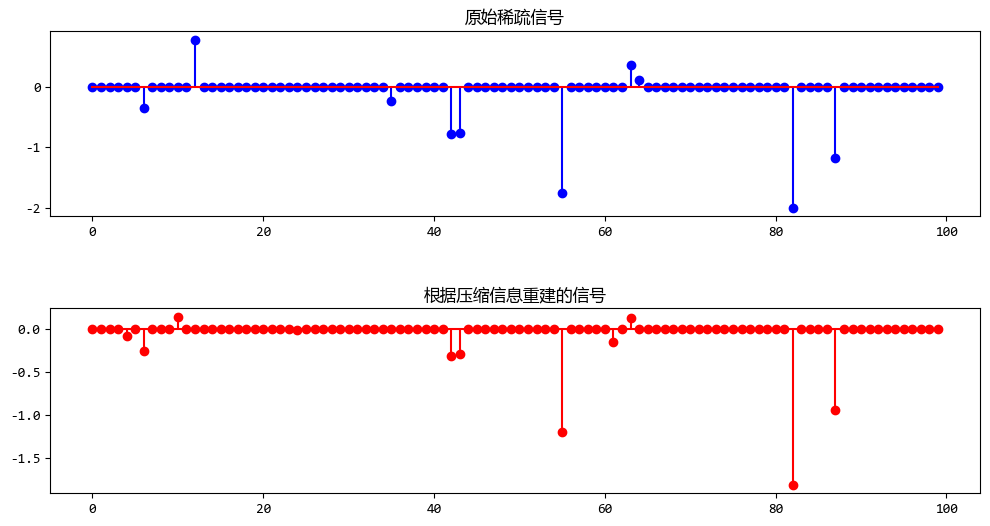
当机器学习遇见压缩感知:用少量数据重建完整世界
在数据处理的世界里,我们常常会遇到这样的问题:数据量太大,存储和传输成本高昂,但又不能丢失重要信息。 这时候,压缩感知(Compressive Sensing,CS)就像一位神奇的“数据魔法师”,能够帮...
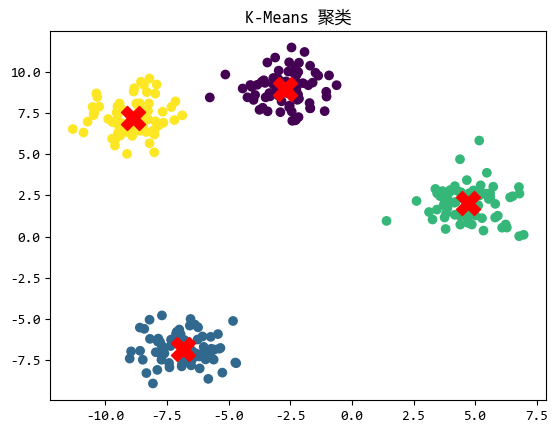
不同数据场景下的聚类算法
在数据分析和机器学习领域,聚类是一种非常重要的无监督学习方法,它可以帮助我们发现数据中的内在结构,将相似的数据点分组到一起。 本文将介绍几种常见的聚类算法,包括原型聚类(如 k-均值、...

概率图模型:机器学习的结构化概率之道
当复杂世界的不确定性遇上图的结构化表达,概率图模型应运而生。 它可以帮助我们理解和建模变量之间的复杂关系。 想象一下,你正在尝试预测明天的天气,你需要考虑温度、湿度、气压等多种因素,...

规则学习:让机器学习像人类一样思考的可解释之路
在机器学习领域,规则学习是一颗独特的明珠--它不像深度学习那样神秘,而是用人类可读的'如果-那么'规则来做出决策。 想象一下医生通过一系列症状判断疾病,或者风控系统根据用户行为拒绝贷款,...
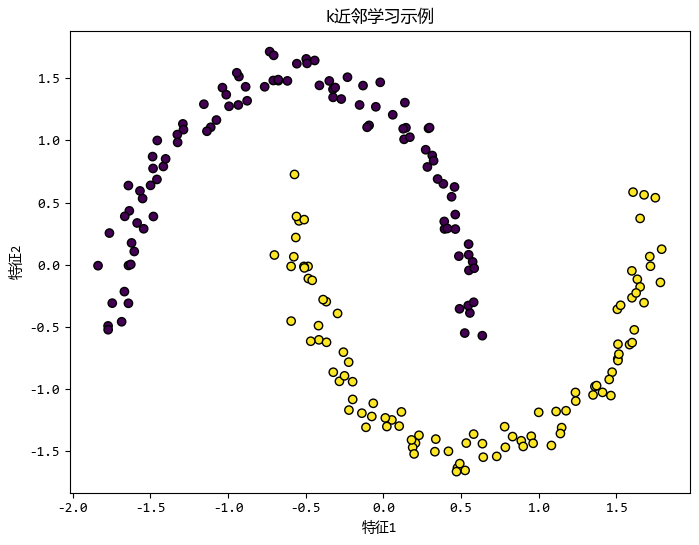
降维技术:带你走进数据的“瘦身”世界
在机器学习和数据分析中,数据的维度常常是一个让人头疼的问题。 想象一下,你面前有一张包含成千上万列特征的表格,每一列都可能是一个重要的信息源,但同时也会让计算变得异常复杂。 这时候,...
