


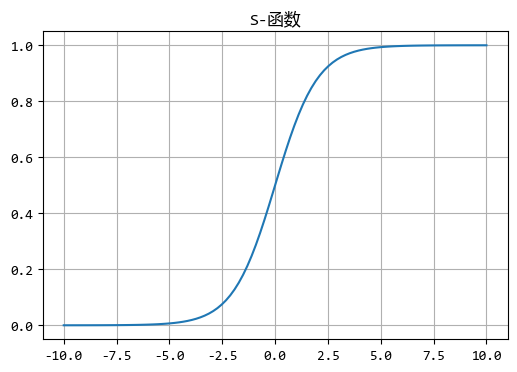
机器学习中的两个重要函数–sigmoid和softmax
机器学习中,常常见到两个函数名称:sigmoid和softmax。前者在神经网络中反复出现,也被称为神经元的激活函数;后者则出现在很多分类算法中,尤其是多分类的场景,用来判断哪种分类结果的概率更...

机器学习中的”食材挑选术”:特征选择方法
想象你要做一道美食,面对琳琅满目的食材,优秀的厨师不会把所有原料都扔进锅里,而是会选择最适合的几种。 在机器学习中,特征选择就是这个挑选过程,从原始数据中选择对预测目标最有用的特征...

聚类是如何度量数据间的“远近”的?
在聚类分析中,距离度量是核心概念之一,它决定了数据点之间的相似性或差异性,从而影响聚类结果的质量。 选择合适的距离度量方法,就像为数据选择合适的“观察视角”,能够帮助我们发现隐藏的...

软间隔:让支持向量机更“宽容”
在SVM中,软间隔是一个重要的概念,它允许模型在一定程度上容忍误分类,从而提高模型的泛化能力。 本文将详细介绍软间隔的定义、与硬间隔的区别、损失函数的作用,最后使用 scikit-learn 进行实...

集成学习常用组合策略:让多个模型“合作”得更好
集成学习通过组合多个学习器的预测结果,达到超越单个学习器的效果。 就像医生会诊时综合多位专家的意见,集成学习的关键在于如何有效整合不同学习器的判断。 这些学习器可以是不同类型的模型,...
机器学习的数学基础–微积分
微积分运算在机器学习领域扮演着至关重要的角色,它不仅是许多基础算法和模型的核心,还深刻影响着模型的优化、性能评估以及新算法的开发。 掌握微积分,不仅让我们多会一种计算方式,也有助于...

稀疏表示与字典学习:让数据“瘦身”的魔法
在机器学习的世界里,我们常常会遇到各种复杂的数据,它们可能包含大量的特征,但其中真正有用的信息却很少。 这就像是在一个杂乱无章的房间里,我们只需要找到那些真正重要的物品,而忽略掉那...
从“朴素”到“半朴素”:贝叶斯分类器的进阶之路
在机器学习分类任务中,朴素贝叶斯(Naive Bayes)因其简单高效而广受欢迎,但它的“朴素”之名也暗示了其局限性。 为了突破这一局限,半朴素贝叶斯(Semi-Naive Bayes) 应运而生。 本文将详细...
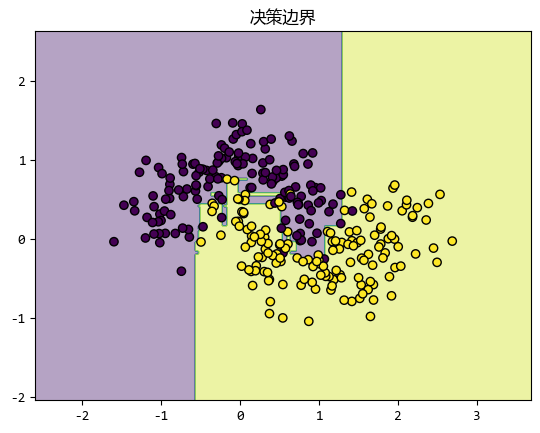
集成学习双雄:Boosting和Bagging简介
在机器学习的世界里,集成学习(Ensemble Learning)是一种强大的技术,它通过组合多个模型来提高预测性能。 集成学习通过组合多个基学习器的预测结果,获得比单一模型更优秀的性能。其核心思想...

同样的数据,更强的效果:如何让模型学会‘互补思维’?
集成学习虽然能够通过组合多个学习器来提高预测性能,然而,如果这些学习器过于相似,集成的效果可能并不理想。 因此,增强学习器的多样性是提升集成学习性能的关键。 多样性带来的优势在于: ...
