


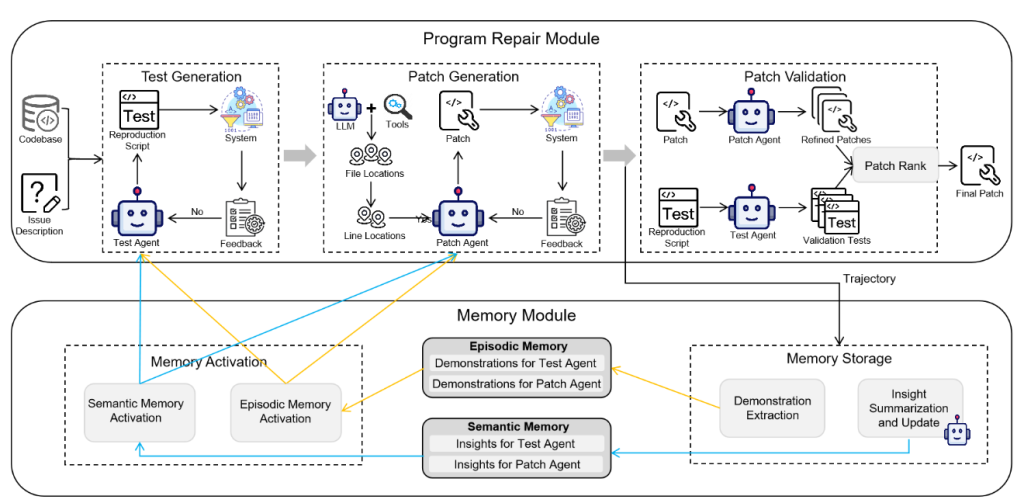
“ExpeRepair: Dual-Memory Enhanced LLM-based Repository-Level Program Repair” 论文笔记
介绍 (1) 发表:Arxiv 6.12 (2) 挑战 主要探讨了基于 LLM 的 APR 的两个主要类别:代理和程序。尽管这两个范式都表现出希望,但它们依然表现出两个重要的局限性: 忽视历史修复经验:现有方法都...
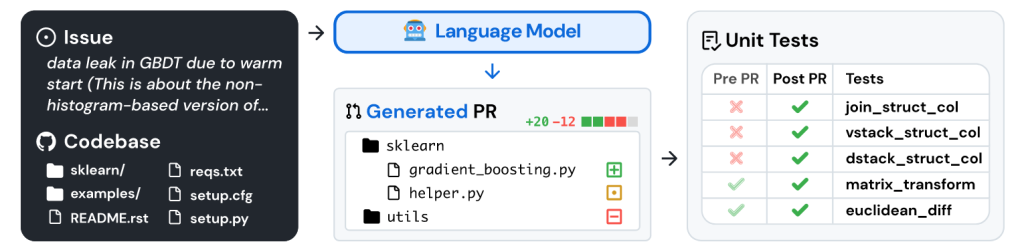
“SWE-bench: Can Language Models Resolve Real-World GitHub Issues” 论文笔记
介绍 (1) 发表:ICLR'24 (2) 背景 现有 benchmarks 已经饱和,无法捕获最先进的语言模型和无法做到的前沿,需要具有挑战性的新 benchmark 来更准确的反映语言模型的现实应用 工作 (1) 数据...
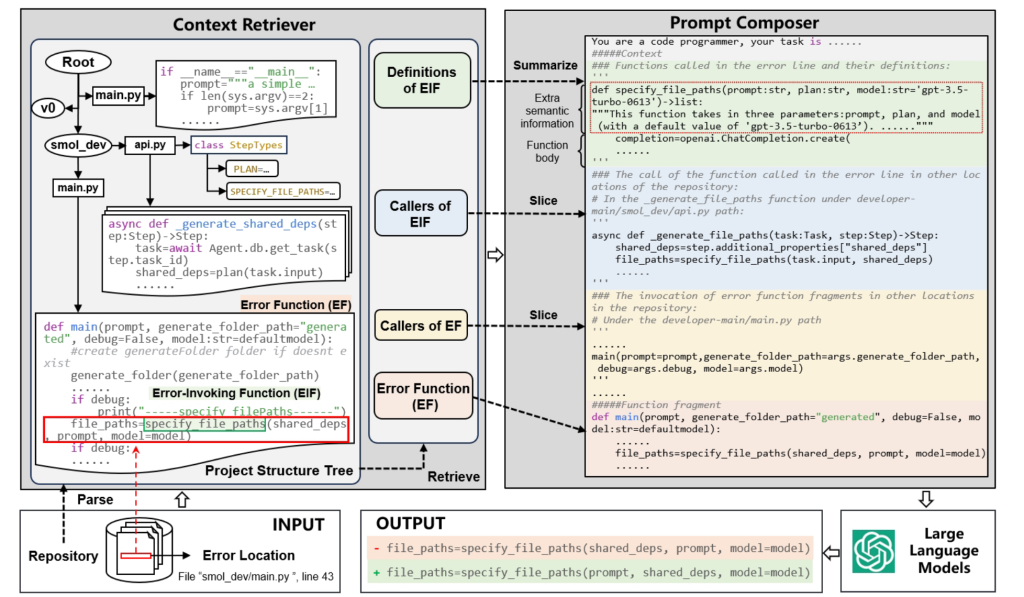
“When Large Language Models Confront Repository-Level Automatic Program Repair How Well They Done” 论文笔记
介绍 (1) 发表:ICSE'24 (2) 背景 APR 任务的这些模型的当前评估仅关注错误所在的单个功能或文件的有限上下文,从而忽略了存储库级上下文中的有价值信息。现有的数据集要么不是在存储库中构建的...

词向量笔记 (CS224N-1)
传统方式 先探讨一个问题,我们怎么获取一个词语有用的含义? 以前常用的NLP解决方法,使用WordNet,这是一个包含同义词和上位词列表的同义词库 传统NLP中,我们用独热向量作为特征,这导致需要...
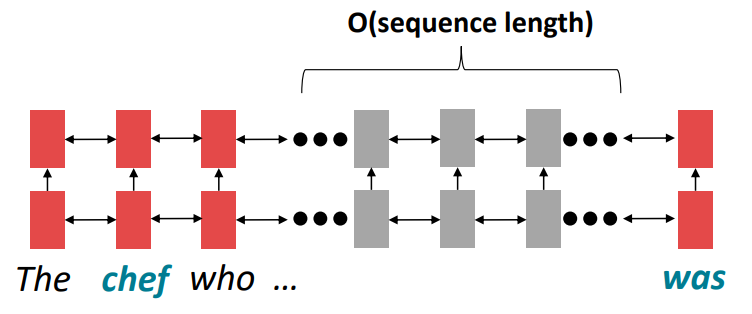
Transformer 笔记 (CS224N-7)
模型回顾 问题:RNN需要经过k步才能对远距离的单词进行交互,例如 这里的was是chef的谓语,二者的关系十分紧密,但是使用线性顺序分析句子会导致如果was和chef的距离较远,它们会难以交互(因为...

MM-LLM 数据侧论文速读
LAION-5B 提出 CLIP 得分来计算文本图像 embedding 之间的余弦相似度的筛选方法 使用 CLIP 筛选图像文本对,过滤相似度得分低于0.28的数据 DataComp 多模态数据集作为 MM-LLM 发展的关键组成部...
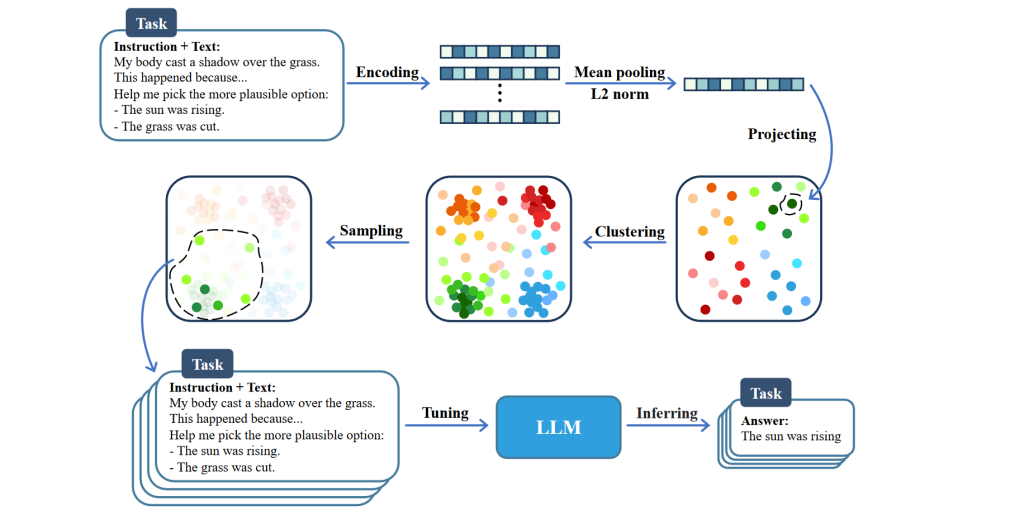
LLM 数据侧论文速读
MAYBE ONLY 0.5% DATA IS NEEDED 更少的数据可以省掉训练时间和训练的成本,并且很容易保证数据的高质量,很简单很直觉的想法 Coreset Selection 目标是使用尽可能少的样本找到一个接近完整数据...

依存结构与依存分析笔记 (CS224N-3)
依存结构 与编译器中的解析树类似,NLP中的解析树是用于分析句子的句法结构。使用的结构主要有两种类型——短语结构和依存结构。短语结构文法使用短语结构语法将词组织成嵌套成分。后面的内容会...
