

MAYBE ONLY 0.5% DATA IS NEEDED
更少的数据可以省掉训练时间和训练的成本,并且很容易保证数据的高质量,很简单很直觉的想法
Coreset Selection
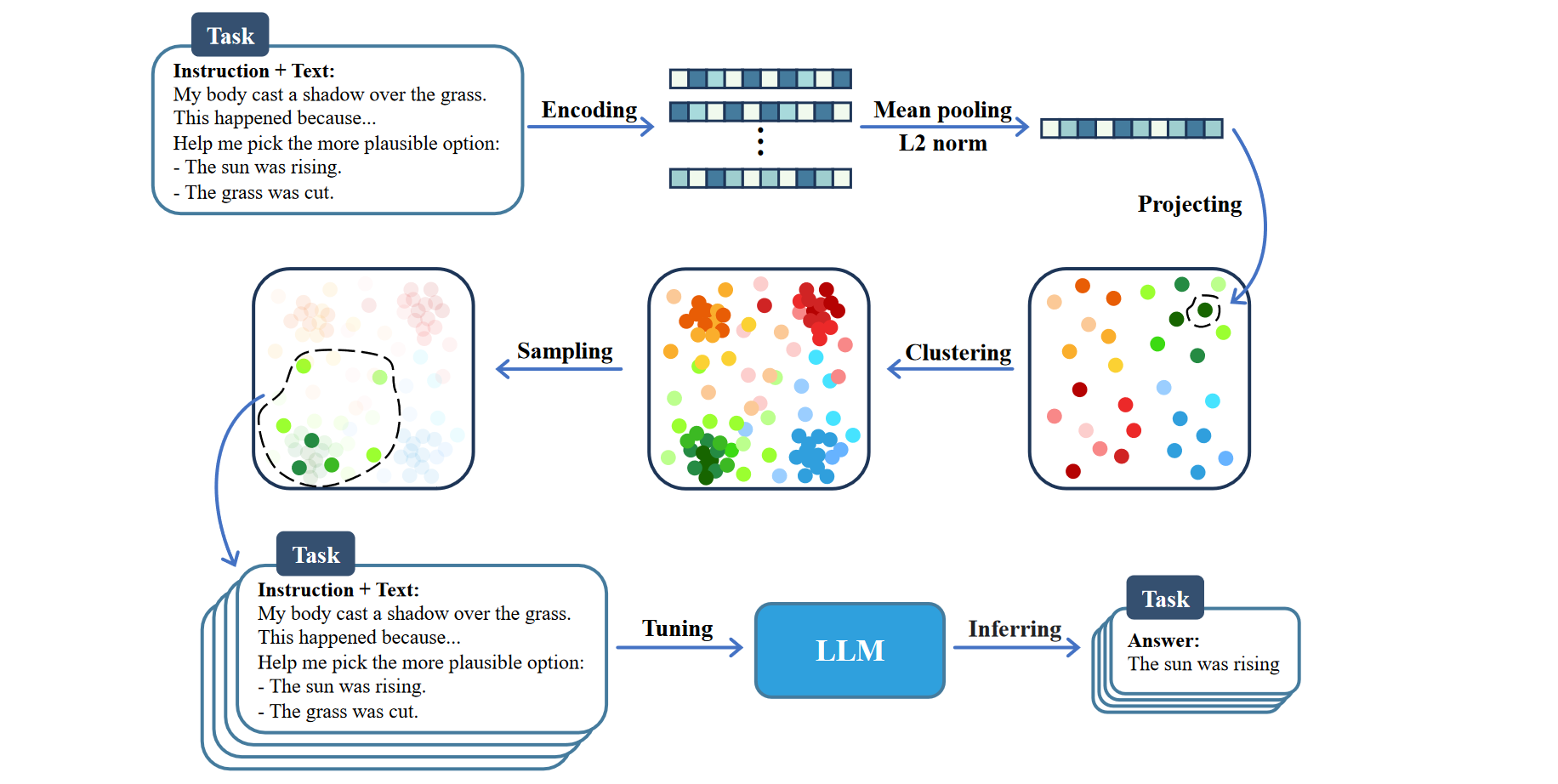
目标是使用尽可能少的样本找到一个接近完整数据集分布的小集合
先通过 Bert 获取 Embedding,然后在高维空间上使用 K-Means 进行聚类,最后使用 KCentergreedy 算法进行采样
只考虑了特定任务 NLI
DEFT
引入了一种新的数据高效微调框架 DEFT-UCS,它利用无监督核心集选择来最大限度地减少微调 PLM 所需的标记数据量,特别是在文本编辑领域
Coreset Selection
先通过 Bert 获取 Embedding,然后在高维空间上使用 K-Means 进行聚类,然后使用 《Beyond neural scaling laws: beating power law scaling via data pruning》提出的方法进行采样
只考虑了文本编辑任务
后面讲了讲 DBase 是指以分层方式采样的初始数据量,还有一些超参数的选择
ALPAGASUS
提出了一种高效、自动且准确的 IFT 数据过滤新策略,得到一个效果更好的 ALPACA 模型
使用 ChatGPT 评估每个输入元组 (指令、输入、响应) 的质量,然后过滤掉分数低于阈值的元组。使用 LLM 过滤器,对更小但经过仔细过滤的 9k 数据子集进行 IFT 生成比原始 ALPACA 更好的模型,即 ALPAGASUS
LIFT
LIFT 从战略上扩大了数据分布,以涵盖更多高质量的子空间并消除冗余,重点关注整个数据子空间中的高质量分段
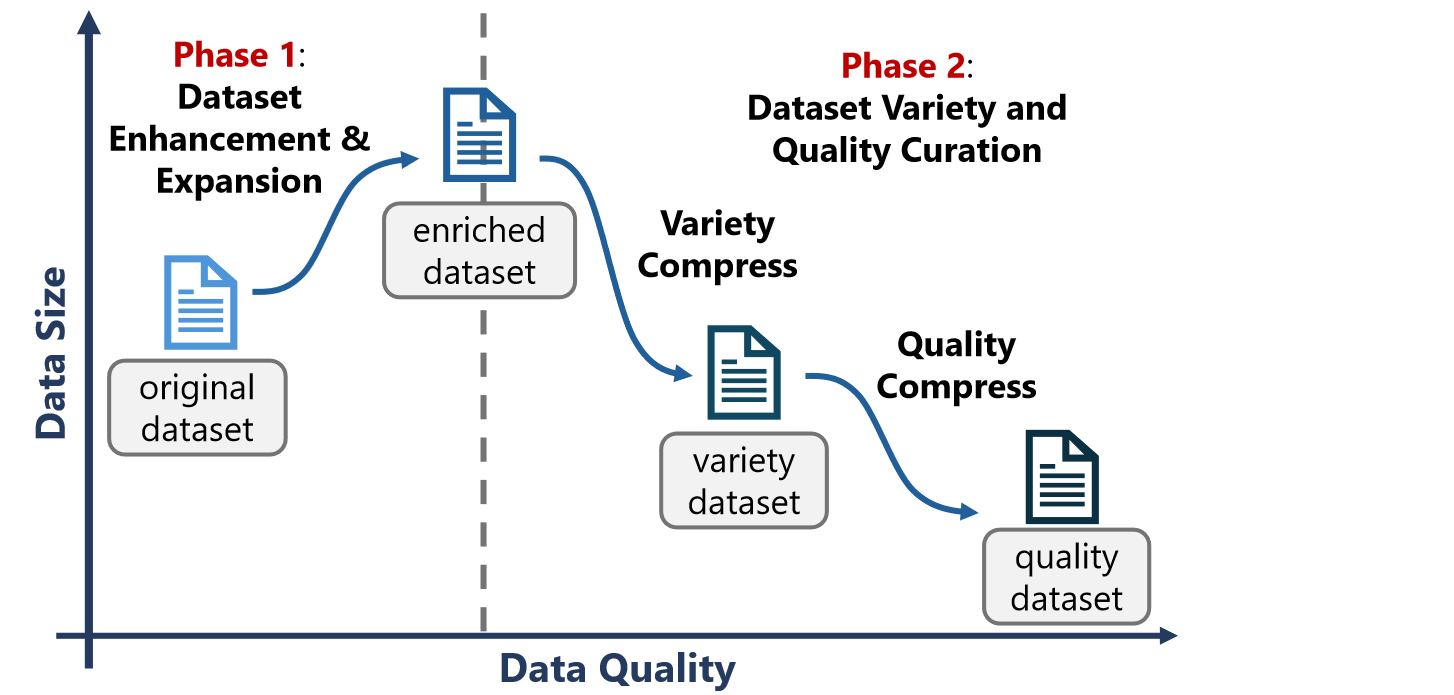
LIFT 包括两个阶段:在 phase1 阶段,扩大数据分布以涵盖更多样化和高质量的子空间,并承认此阶段存在重复。在 phase2 阶段,系统地消除冗余和低质量元素,为最终管理的数据集创建致密分布
第一阶段:使用 GPT-4 充当重写器,根据指定的生成规则生成 instructions
第二阶段:认为聚类方法缺乏通用性,需要事先了解簇的数量,过大过小都不合理。实际上这里用了一个类似于 PCA 的方法降维然后选择行方差最高 20% 的数据来构建多样性的数据集。最后一样使用 GPT-4 进行质量打分(提供一些示例、设置需要分数和详细解释)
DEITA
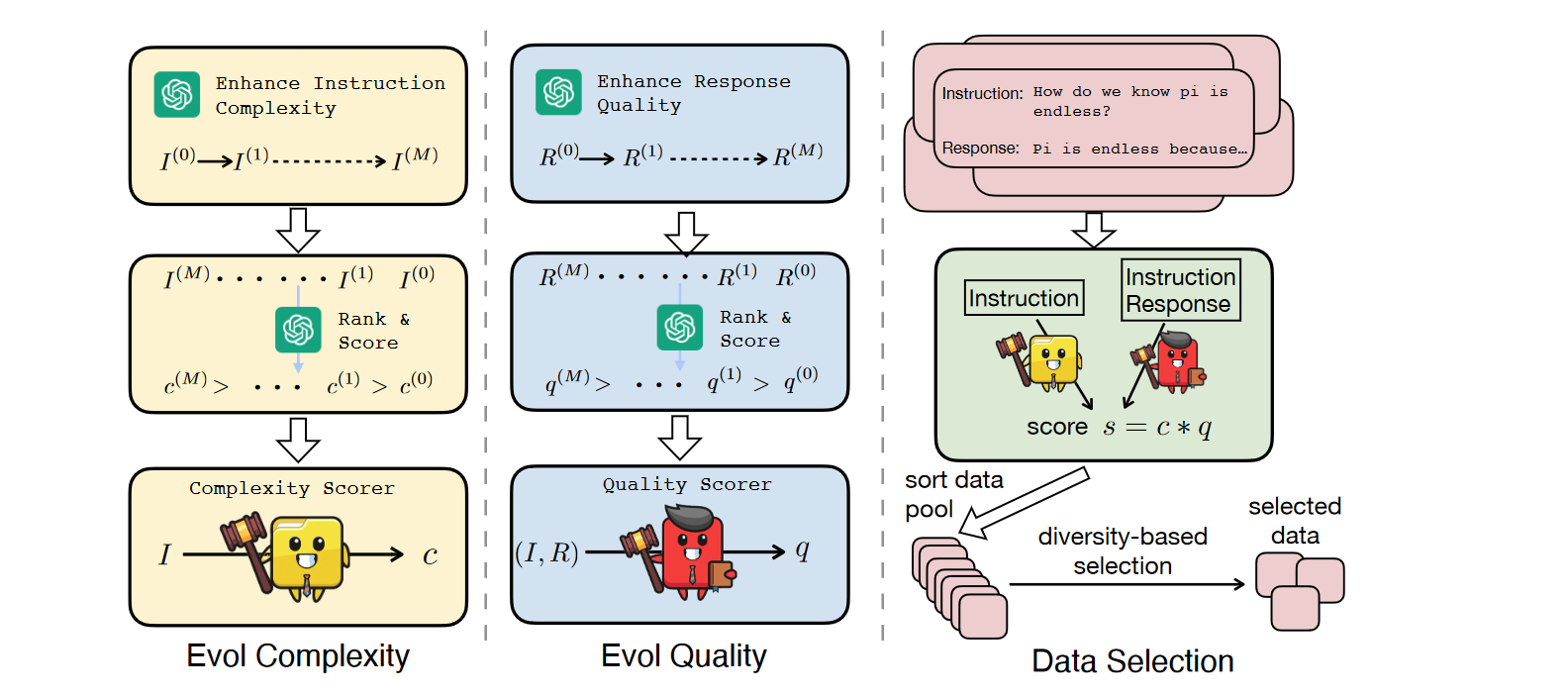
提出了一个新的自动化数据选择策略,这里相较于其他方法挺新颖的一点是分别对复杂性和质量的关注
Evol Complexity:通过添加约束、深化、具体化和增加推理步骤等技术来增强指令复杂性,并要求 ChatGPT 对这些指令的复杂性打分,最后用指令和复杂性得分训练 LLaMA 得到一个复杂性评分器
Evol Quality:同理,得到一个回答的质量评分器
Data Selection:同时考虑复杂性和质量,计算乘积得分,最终选择
除此之外,本文还提出了一个迭代的方法来保证数据多样性。具体理论是不断检查 \(x_i\) 与其最近邻居之间的嵌入距离,如果小于阈值则认为示例 xi 可以增加 S 的多样性
MoDS
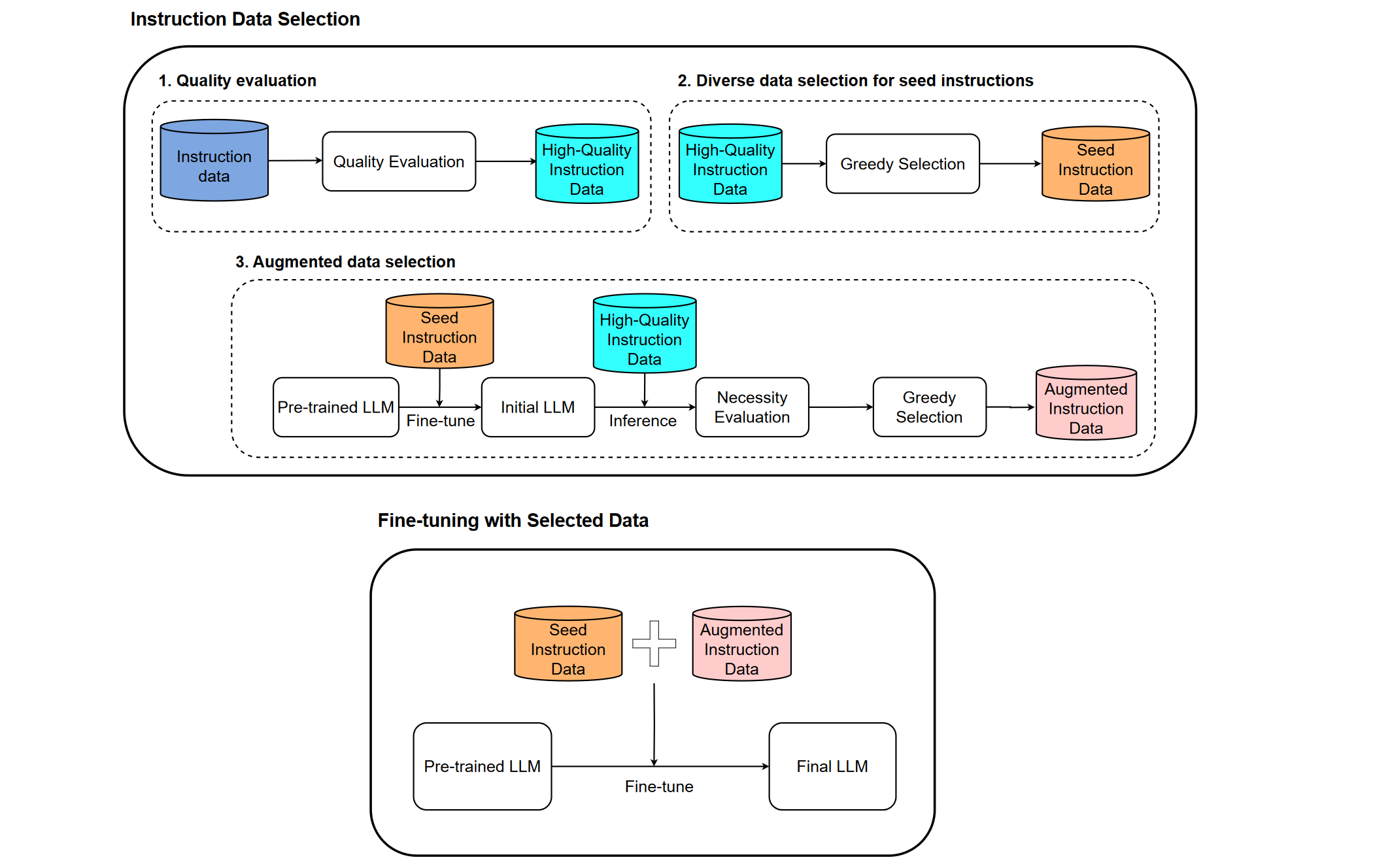
先用质量评估模型 DeBERTa 筛选出高质量的数据,得到 High-Quality Instruction Data
然后使用了一种称为 k-center 贪心算法的方法,从高质量子集中选择数据。这个算法可以选择距离最远的数据点,从而确保选择的指令数据具有多样性和更广泛的覆盖范围(最主要的贡献),得到 Seed Instruction Data
接着先用 Seed Instruction Data 微调出一个初始 LLM 并用其获取 High-Quality Instruction Data 的 response。再用 DeBERTa 进行打分,对分数较低的数据集再 k-center 得到增强数据集
最后合并训练 LLaMA2 得到 SOTA 模型
LoBaSS
创新性引入了学习性的概念,通过比较微调和预训练模型之间的损失差异来衡量数据的学习性
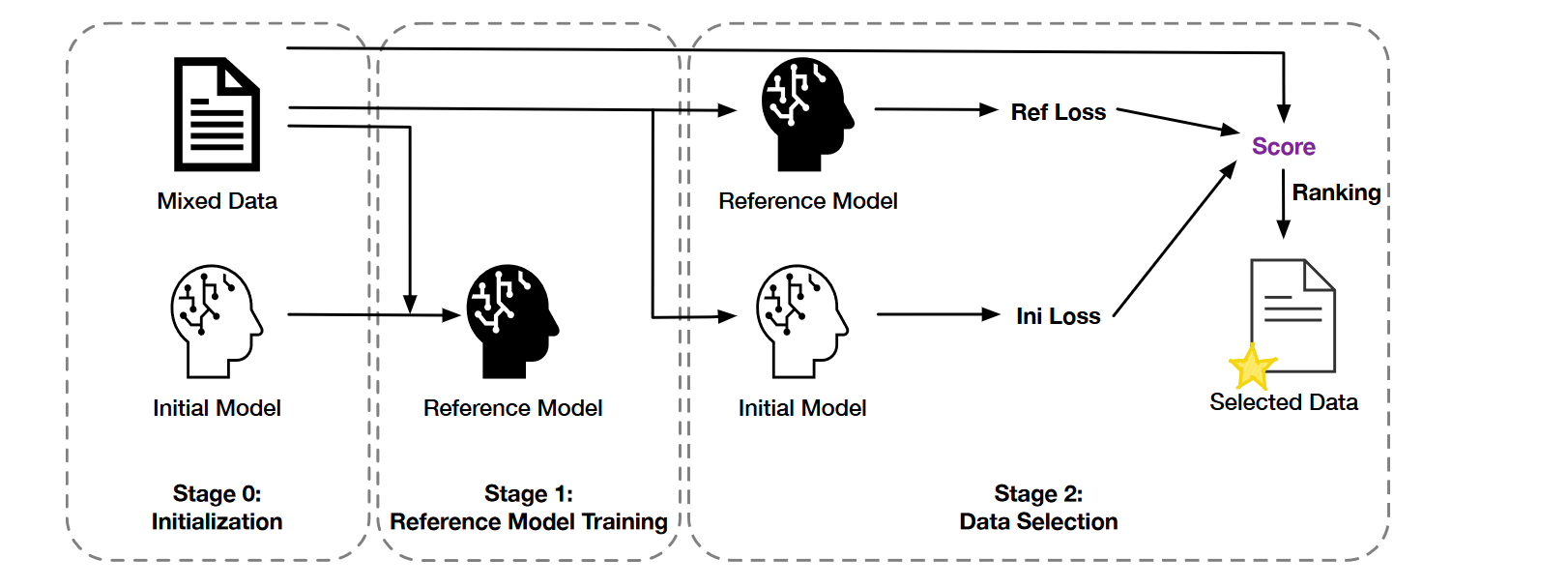
无论数据怎么筛都是要为模型学习服务的,学习性才是我们唯一且必须要考虑的!!!并且用损失差异来衡量数据的学习性也十分的合理
DL on a Data Diet
提出了两个分数梯度归一化(GraNd)和误差L2-归一化(EL2N)分数,可以在训练的早期识别重要的数据

这篇文章有公式推导(还算简明扼要)和实验验证,然后围绕样本和模型这两个部件,给出了两个metric。并且对高剪枝率下的实验的性能做出解释,算是在这个方向上开了一小个坑
NLU on Data Diets
利用 EL2N 指标,将其扩展到 NLU 和时隙分类任务,以及整个训练集的初始微调阶段
用交叉熵损失估计 \(y\),以下是多种情况下的 EL2N 得分,最后通过 EMA 来评估 \(\hat x\)

主要还是提出了 EL2N 在 NLU 上的动态剪枝方法,算是延续上一篇论文开出的坑了
LESS
仅选用 5% 的数据优于使用全部数据,没有另一篇只使用 0.5% 的大胆

准备阶段
使用LoRA(Low-rank Adaptation)技术对预训练的基础模型(例如LLAMA-2-7B)进行参数高效的微调,以减少可训练参数的数量并加速训练过程。
在训练集的一个随机子集上进行N个epoch的预热训练,以适应特定的数据分布,并在每个epoch后保存模型检查点
计算梯度特征
对于每个训练数据点,计算其在预热训练期间的梯度,然后应用随机投影技术将这些梯度投影到低维空间,生成低维梯度特征
将这些低维梯度特征存储在一个梯度数据存储库中,以便后续的数据选择过程可以高效地重用这些特征
数据选择
对于目标任务的验证集(包含少量示例),计算每个子任务的平均梯度特征
使用LESS算法计算每个训练数据点对于验证集的潜在影响,通过评估数据点的梯度特征与验证集特征之间的相似性来打分。根据得分选择最高的一部分训练数据点(例如前5%)作为最终的训练集
目标模型训练
使用选定的数据子集对目标模型进行训练
INSTRUCTION MINING
本文提出了一种通过线性规则筛选高质量数据的方案(有种套娃的感觉),目前验证指令数据的质量的方法大多数采用 GPT+Few Shot 或者 微调+验证的方案,作者认为这种方法代价太大了,提出了一种通过Indicator 过滤数据的方法
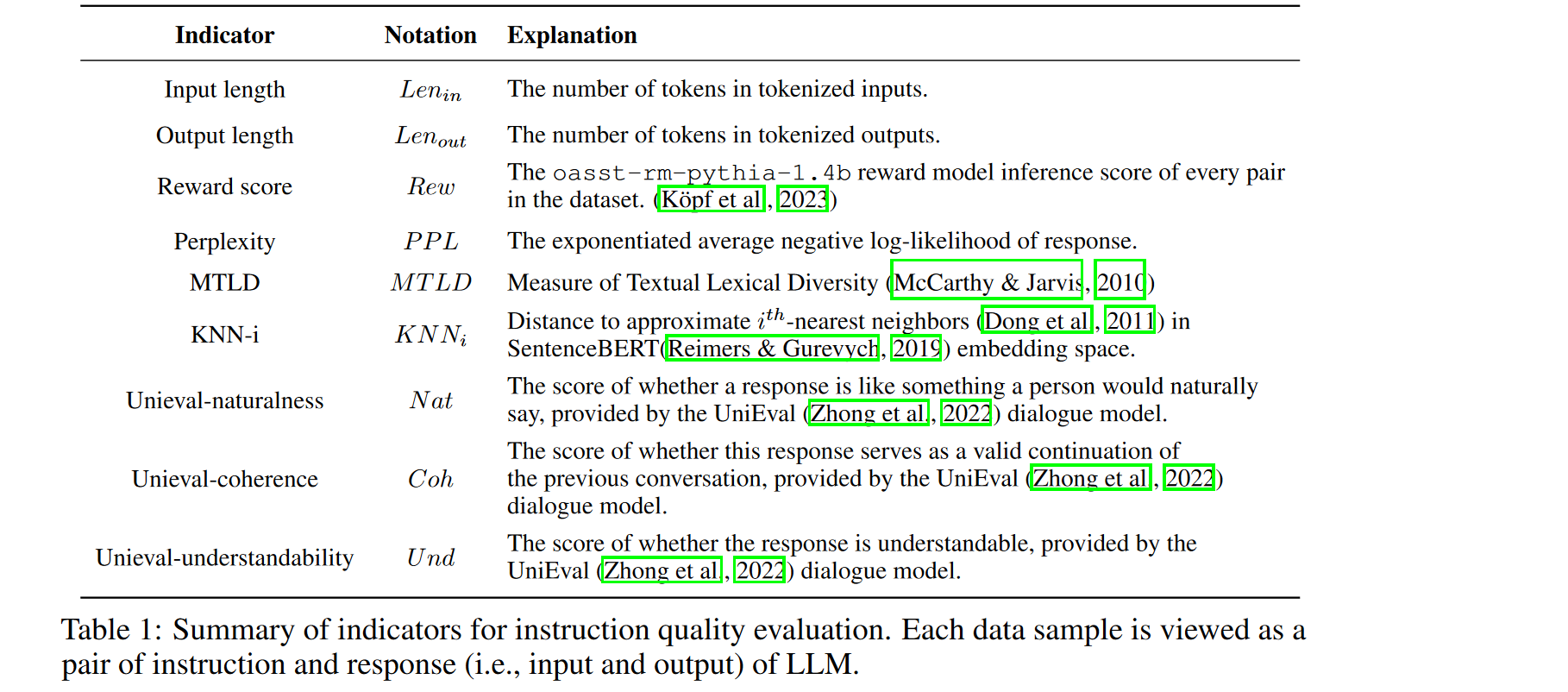
指令数据的质量Q与微调后模型在验证集的损失成正比,然后结合一堆设定的 Indicator 最终计算数据的得分
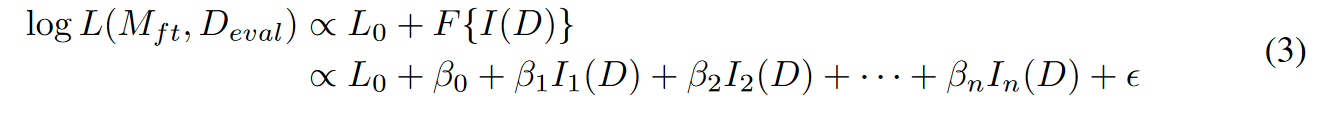
来源链接:https://www.cnblogs.com/mianmaner/p/18756565
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。












暂无评论内容