

LAION-5B
提出 CLIP 得分来计算文本图像 embedding 之间的余弦相似度的筛选方法
使用 CLIP 筛选图像文本对,过滤相似度得分低于0.28的数据
DataComp
多模态数据集作为 MM-LLM 发展的关键组成部分,没有得到充分的研究关注。为了弥补这一不足,我们引入了 DataComp,这是一个围绕 Common Crawl 的新的128亿的图像文本对数据集的 benchmark
提供了一个全面的 benchmark 和数据集
比较设计
讲了一些约束
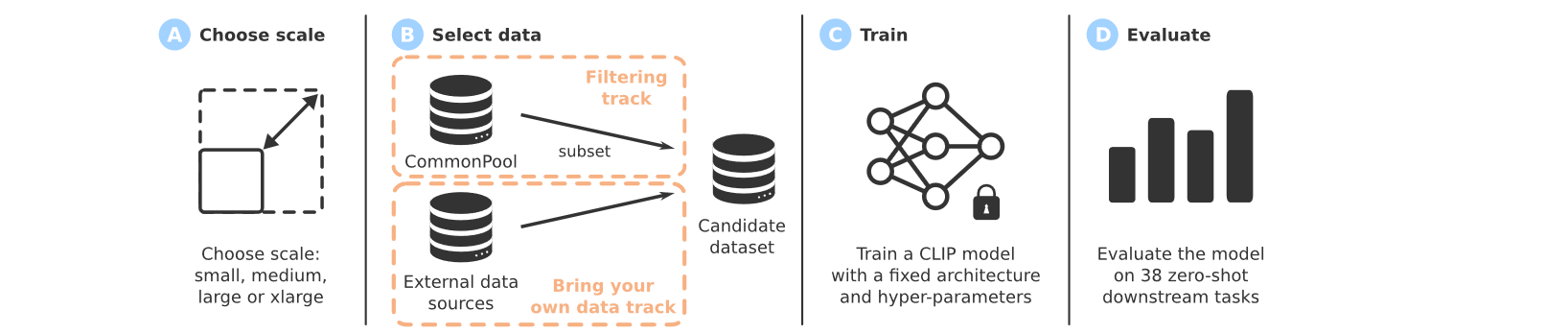
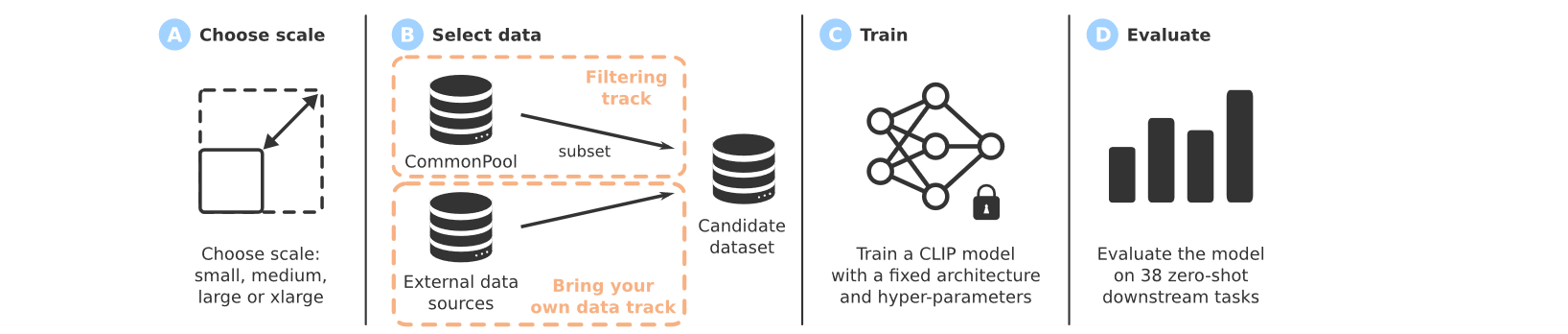
如何得到训练集:① 数据筛选,构建 CommonPool ② 可以使用自带的数据集
提供了四个规模的构建 DataComp 以满足不同需求用户
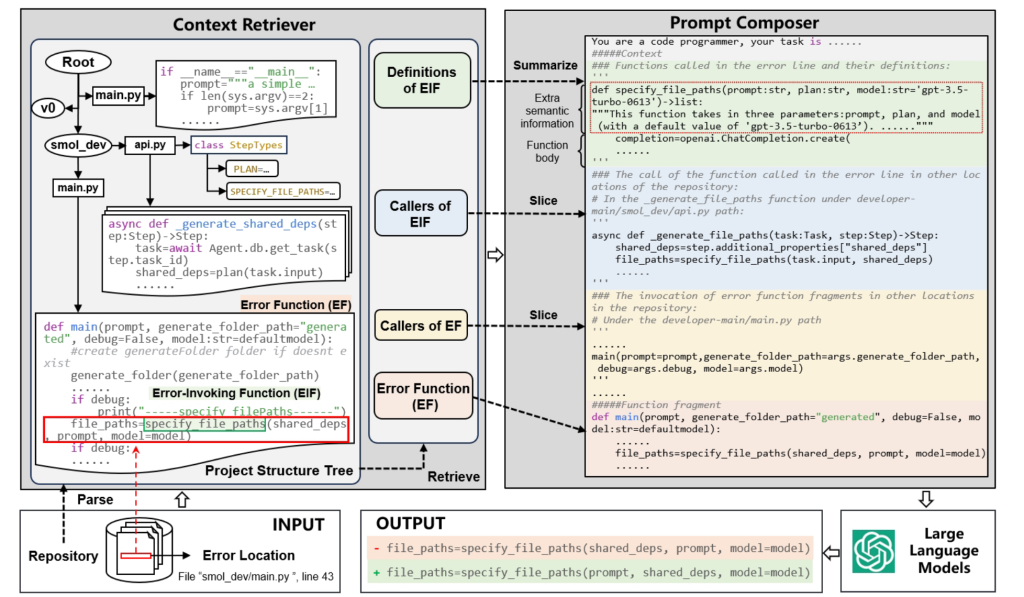
构建 CommonPool
CommonPool 的构建有四个步骤:url 提取和数据下载、NSFW 检测、评估集去重、人脸模糊处理
自带数据(BYOD)
提供了一个单独的 DataComp 轨道,允许自行组合多个数据流
Baselines
进行了众多 filter 方法的 Baseline 实验:① No filtering ② Random subsets ③ Basic filtering ④ CLIP score and LAION filtering ⑤ Text-based filtering ⑥ Image-based filtering
LLaVA
数据
使用 ChatGPT/GPT-4 来将数据转化为 multimodel instrustion-following data
为每一个图像生成三种 mulmodal instruction-following data,对于每种类型,我们首先手动设计一些示例。它们是我们在数据收集过程中拥有的唯一人工注释,并用作上下文学习中的种子示例来查询 GPT-4
三种 data:conversation、deltailed decription、complex reasoning
训练
对于每个图像,我们生成多轮对话数据 $$(X_q1,X_a1,\cdots,X_qT,X_aT)$$,其中 T 是总轮数,将其组成一个序列
评估
利用 GPT-4 作为法官对模型的输出信息进行打分
- 思考:conversation、deltailed decription、complex reasoning 可以继续扩展?例如利用 ChatGPT/GPT-4 增加时间维度的 Caption 等等(能否继续超越 ShareGPT4V?)
LLaVA-1.5
模型改进
与原始模型相比,通过双层 MLP 提高视觉语言连接器的表示能力可以提高 LLaVA 的多模态能力线性投影设计
数据改进
- 进一步包含了额外的面向学术任务的 VQA 数据集,用于 VQA、OCR 和区域级感知,以各种方式增强模型的功能(例如 A-OKVQA 转换为多项选择题,并使用特定的回答格式提示:直接使用给定选项中的选项字母进行回答)
- 进一步扩大了输入图像的分辨率,让LLM能够清楚地“看到”图像的细节,并添加GQA数据集作为额外的视觉知识源
VAS
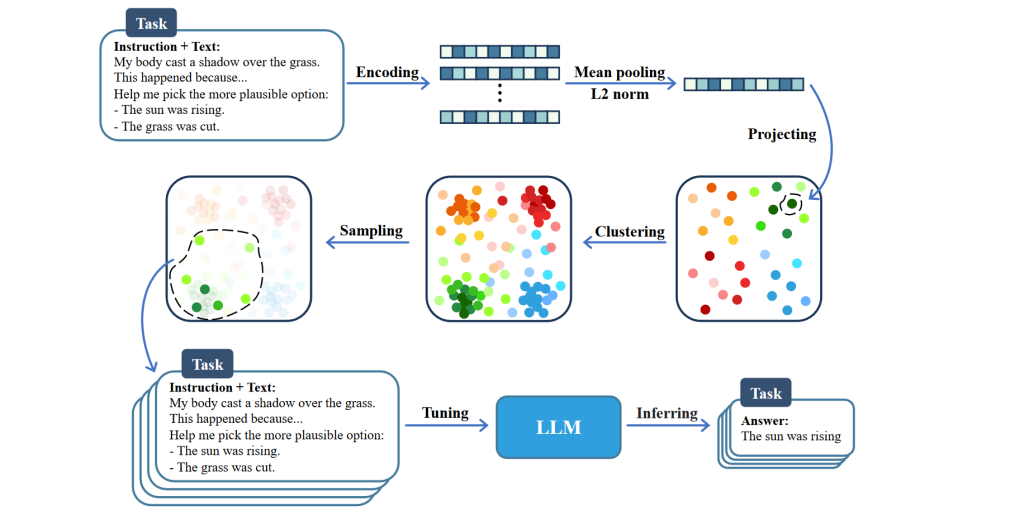
提出了一个新的用来判断数据质量的指标 VAS
VAS 着重考虑高 information
出发点
因为高质量的数据并不总是最具信息性或代表性的。在某些情况下,某些特征可以在比其他特征少得多的样本下轻松学习,因此添加更多具有此类特征的高质量数据很难进一步改进最终模型
我们提出方差对齐评分(VAS),旨在找到训练数据中信息最丰富的子集,其图像-文本对之间的(交叉)协方差与参考分布的(交叉)协方差最一致。
方法
良好的嵌入模型下,方差或交叉方差项是指示信息量的合适标准
采用两阶段方法,其中第一阶段我们删除CLIP分数非常低的样本,然后对剩余数据应用VAS以执行更细粒度的选择。尽可能筛选出 高信息性+高质量 的图像文本对
ShareGPT4V
使用 GPT4-Vision 生成了比 LLaVA 更全面、高质量的caption。设计了特定于数据的提示,同时考虑世界知识、物体属性、空间关系和审美评价等因素
主要是要求 GPT4-Vision 提出相关的知识,所以很全面
来源链接:https://www.cnblogs.com/mianmaner/p/18756584
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。












暂无评论内容