

介绍
(1) 发表:ICSE’24
(2) 背景
APR 任务的这些模型的当前评估仅关注错误所在的单个功能或文件的有限上下文,从而忽略了存储库级上下文中的有价值信息。现有的数据集要么不是在存储库中构建的,例如 Quixbugs,要么无法准确恢复存储库级错误的方案,例如 Defects4J。本文研究了流行 LLM 在处理存储库级维修任务中的性能
(3) 贡献
- 介绍了 Repobugs,这是一种新的基准测试,包括来自开源存储库中的 124 个典型的存储库级错误
- 提出了一个简单而通用的存储库级上下文提取方法 RLCE,旨在为存储库级的代码修复任务提供更精确的上下文
数据集构建
数据来自 Github 开源项目的 11 个 Python 库,在数据集构建过程中,Repobugs 的错误是具有丰富编程经验的专家人工制定的
- NRV:上下文函数与主函数之间的返回值数量的不一致
- NP:主函数和上下文功能之间的输入参数数量不一致
- ORV:主函数和上下文功能之间的返回参数顺序不一致
- OP:主函数和上下文功能之间的输入参数顺序不一致
- CRV:从上下文功能返回的值与主函数的要求不一致
- CP:主函数和上下文功能要求之间的输入参数不一致
方法
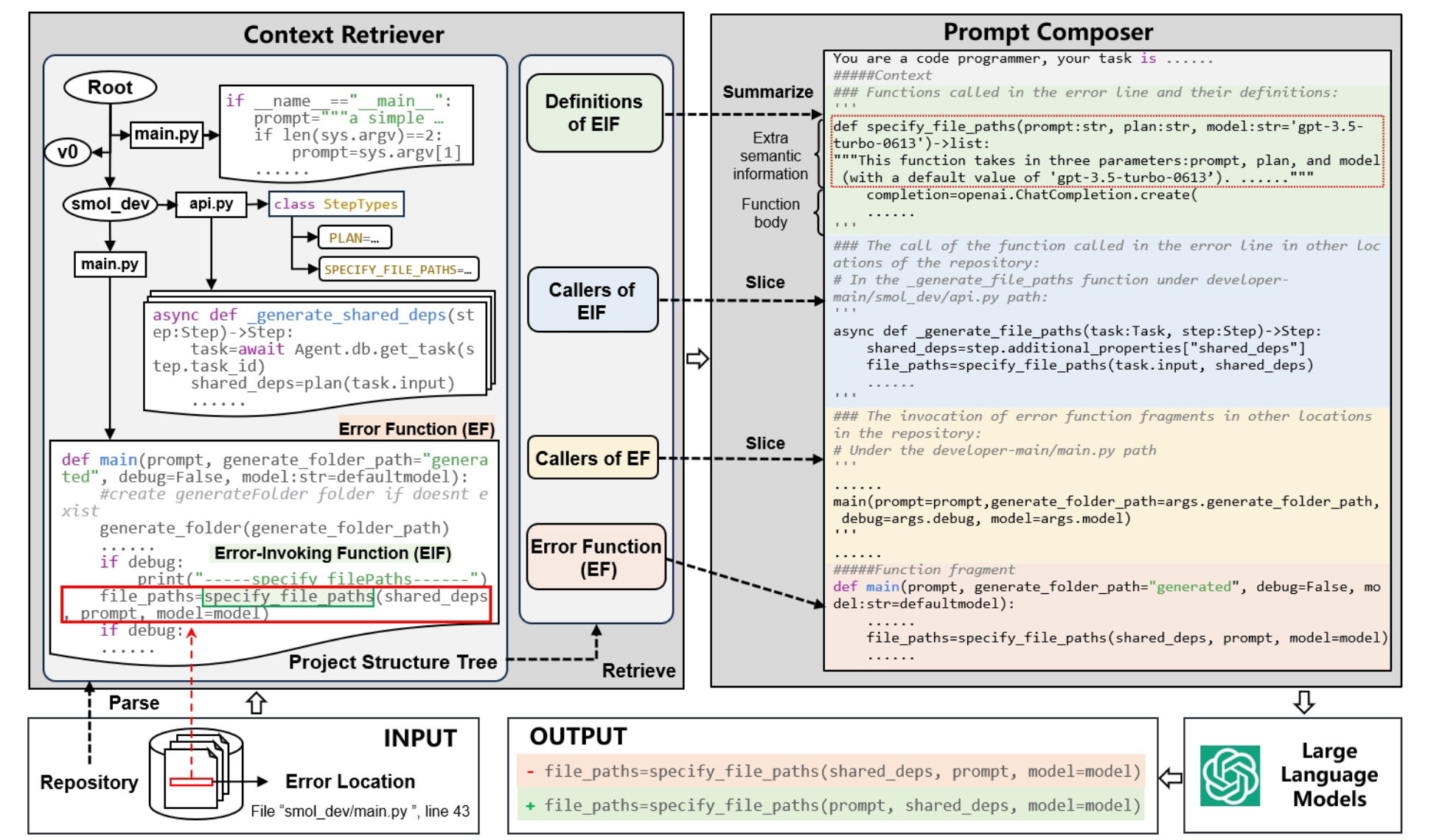
(1) 构建项目结构树
项目结构树源自根节点,其子节点包含子目录和文件,并在存储库的根目录下。文件实体的子节点包括全球定义的变量,类和功能。项目结构树的叶节点仅限于函数节点或变量节点,包括定义函数或变量的代码
(2) 检索代码段
在检索之前,上下文检索工具需要分析和提取错误位置中调用的函数和全局变量,我们将其称为错误的错误函数(EIF)。然后定义了四种类型的上下文源,以确定 Retriver 应在何处从项目结构树中提取代码段:
- EIF:检索包含在存储库范围内提取的错误访问函数的定义的代码段
- Caller of EIF:搜索存储库中遇到错误函数的其他出现(不包括错误位置)以获取包含其调用位置的代码段
- EF:包含错误位置的函数
- Caller of EF:检查错误函数是否在存储库中的其他位置调用,如果是,则检索包含调用位置的代码段
(3) Prompt 构建
验证实验
为了确保评估结果的准确性,我们最终采用了手动评估方法,并由两位在 Python 编程方面拥有超过 5 年经验的专家提供了评估结果,使用了四个不同的指标:Related reply,Correct format,Correct repair,Correct explanation
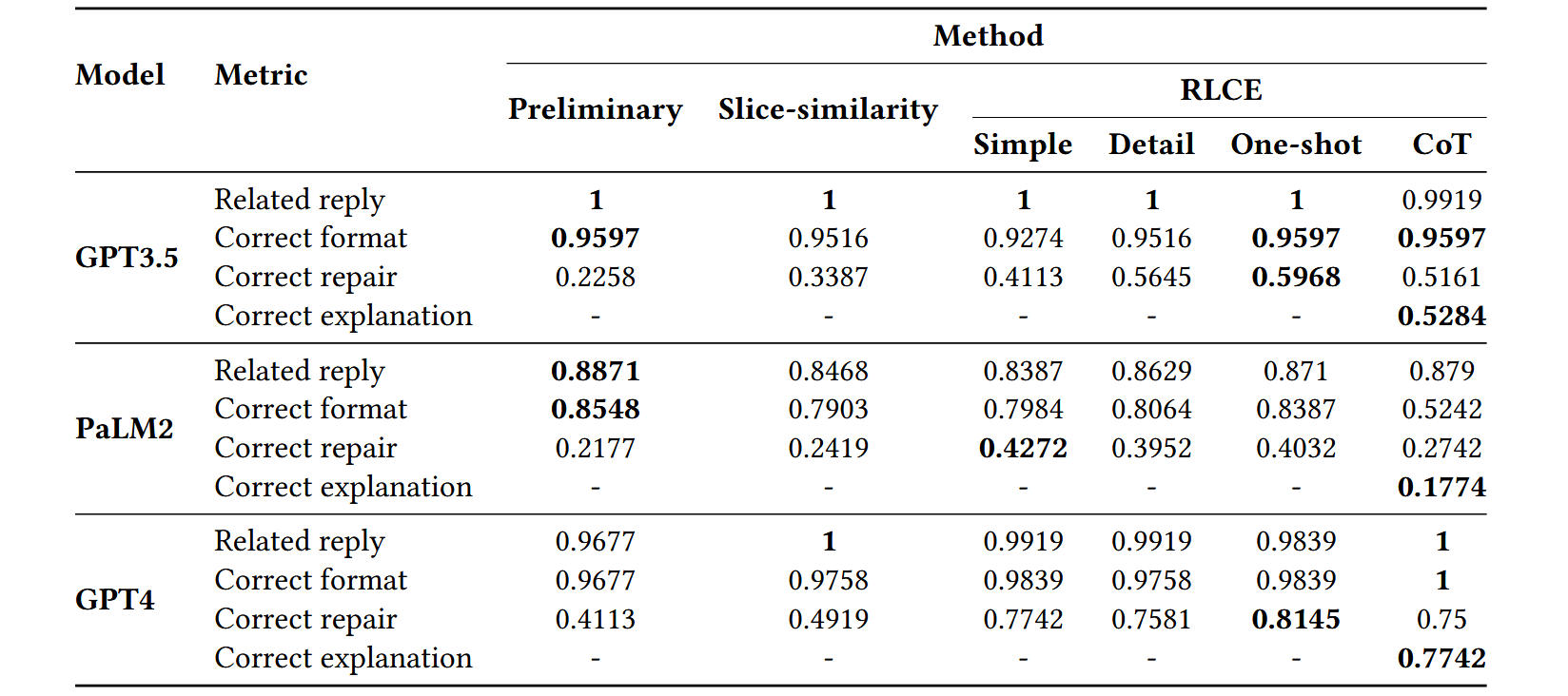
主要还是说明这些 LLM 在 Repobugs 上的修复率与在现有数据集上是不一样的
总结
第一个构建 Reposity-level 的 APR benchmark 的工作
来源链接:https://www.cnblogs.com/mianmaner/p/19025999
© 版权声明
本站所有资源来自于网络,仅供学习与参考,请勿用于商业用途,否则产生的一切后果将由您(转载者)自己承担!
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。
THE END












暂无评论内容