

介绍
(1) 发表:ICLR’24
(2) 背景
现有 benchmarks 已经饱和,无法捕获最先进的语言模型和无法做到的前沿,需要具有挑战性的新 benchmark 来更准确的反映语言模型的现实应用
工作
(1) 数据集构建
该工作从 Github 上流行的 12 个开源 python 库中收集了约 90000 个 PR,然后进行特定的过滤操作,最终得到了 2294 个任务实例(代码库有数千个文件很大,并且 PR 通常会一次更改多个文件)。为了鼓励数据集的使用,该工作还创建了一个来自 SWE Bench 的 300 个实例的 lite 子集,这些实例已被取样以更独立
后来 OpenAI 对 SWE-bench 做了一些完善操作,对所有 case 进行了人工验证,最后留下了 SWE-bench_Verified 数据集,目前官方榜单以此为准
(2) 模型输入
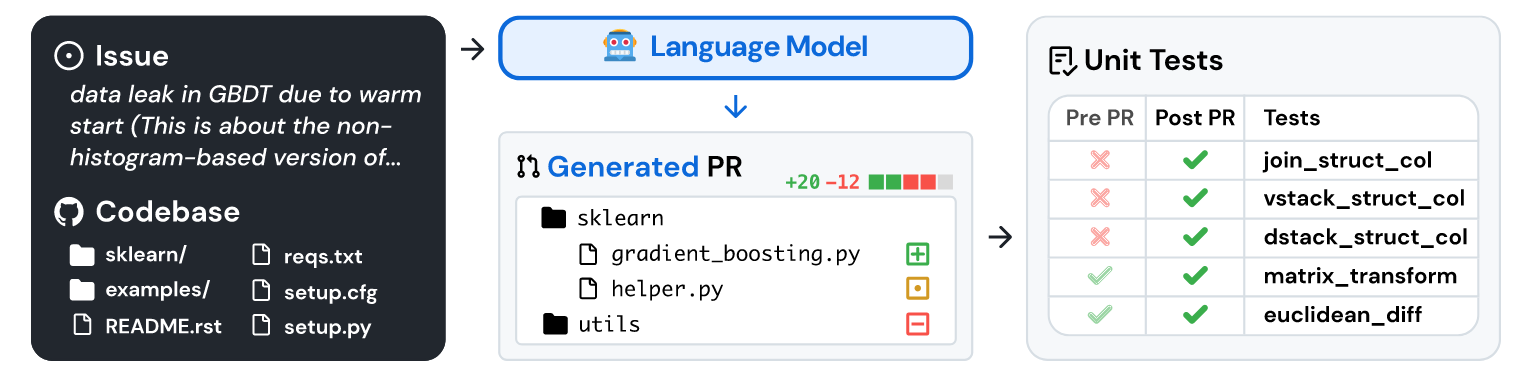
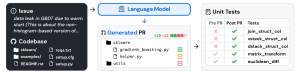
在 SWE-bench 数据集中,对于每个任务实例,输入格式主要是将问题描述和相关的代码文件内容组合在一起提供给模型。这些内容被组织成一种模型能够理解的格式,以帮助模型识别问题并生成解决方案
(3) 检索方式
- 稀疏检索:采用 BM25 算法为每个任务实例检索相关文件作为上下文。实验设置了三种不同的最大上下文限制,在模型的上下文窗口允许范围内,尽可能多地检索文件,并评估模型在不同限制下的性能,最终选取最佳性能结果。实际观察发现,模型在最短上下文窗口下表现最佳
- “Oracle” 检索:直接选择参考补丁在 GitHub 上解决问题时所编辑的文件作为上下文(相当于有已知信息,实际场景中工程师事先往往不知道这些)。几乎一半的实例中,BM25 没有检索到 “Oracle” 上下文中的任何文件
(4) 验证实验
为了更好地评估这些模型的功能,该工作对 Codellama-python 模型进行了有监督的微调(收集了另外 19000 个 PR 作为训练集)
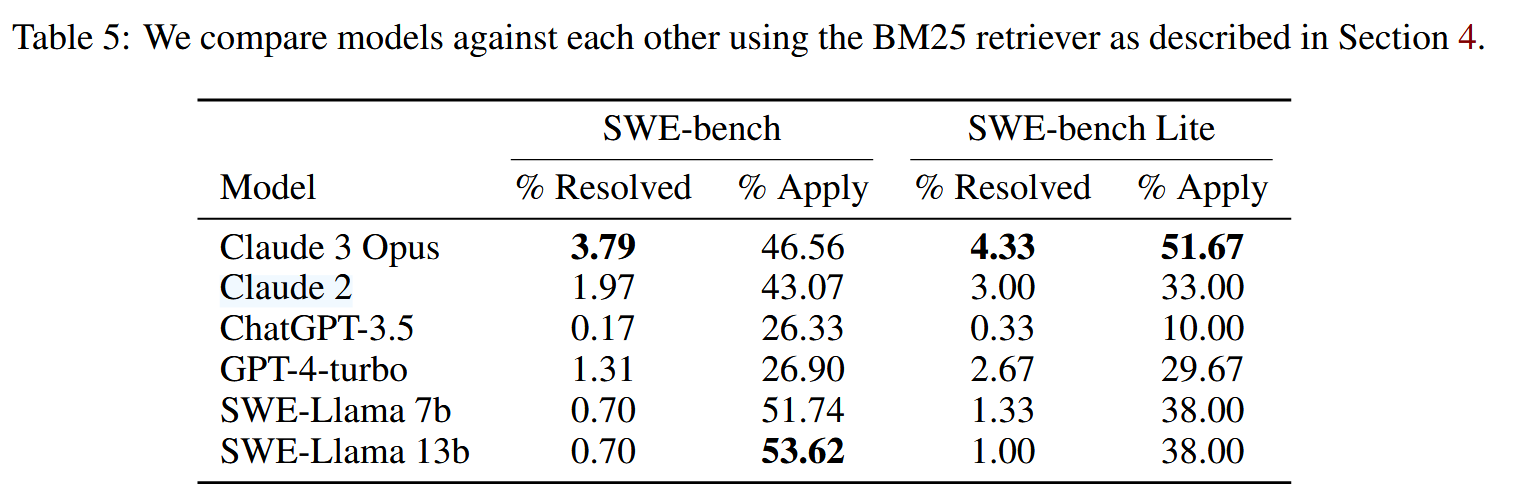
可以看到各个模型的整体表现不佳
总结
LLM 用于软件维护的开创性 benchmark,具有挑战性和实际意义
来源链接:https://www.cnblogs.com/mianmaner/p/19026006
© 版权声明
本站所有资源来自于网络,仅供学习与参考,请勿用于商业用途,否则产生的一切后果将由您(转载者)自己承担!
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。
THE END











暂无评论内容