


引言
在现代分布式系统中,消息顺序消费扮演着至关重要的角色。特别是在涉及事务处理、日志追踪、状态机更新等场景时,消息的处理顺序直接影响着系统的正确性和一致性。例如,金融交易系统中,账户间的转账操作必须严格按照发出请求的顺序进行处理,否则可能导致资金不匹配;同样,在构建实时流处理系统时,事件的时间戳顺序可能关系到最终结果的准确性。
然而,在分布式环境中,保证消息顺序消费并非易事。消息队列中的消息可能会因为网络延迟、系统故障、并发处理等多种因素导致乱序。此外,随着系统规模的增长,如何在保证消息顺序的同时,有效提升消息处理的吞吐量和响应时间,成为了一个颇具挑战性的课题。
Apache Kafka作为一个高性能、分布式的消息发布订阅系统,特别关注了消息顺序处理的需求。Kafka采用了分区(Partition)的设计,确保了单一分区内消息的严格顺序。每个分区内部的消息是由一个生产者不断追加的,因此消费者可以从分区的开始位置顺序消费这些消息。此外,Kafka允许用户通过自定义分区策略,依据消息键(Key)将具有顺序要求的消息路由到特定分区,从而在多分区环境下仍然能够相对保证消息顺序消费。与此同时,Kafka也支持灵活的消费者组配置,允许通过控制消费者线程数和消费行为,以在保证顺序的前提下尽可能提高系统处理效率。
Kafka中的消息顺序保证原理
在Apache Kafka中,消息顺序性的保障主要依托于其独特的分区(Partition)机制以及消息键(Key)的使用。
1. 分区(Partition)的作用与消息顺序性的内在关联
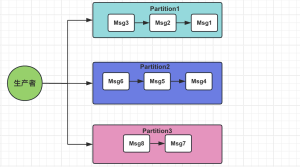
Kafka的主题(Topic)可以被划分为多个分区,每个分区都是一个独立的顺序日志存储。如下图所示,每个分区内部的消息按照其生成的先后顺序排列,形成一个有序链表结构。
当生产者向主题发送消息时,可以选择指定消息的键(Key)。若未指定或Key为空,消息将在各个分区间平均分布;若指定了Key,Kafka会根据Key和分区数计算出一个哈希值,确保具有相同Key的消息会被发送到同一个分区,从而确保这些消息在分区内部是有序的。
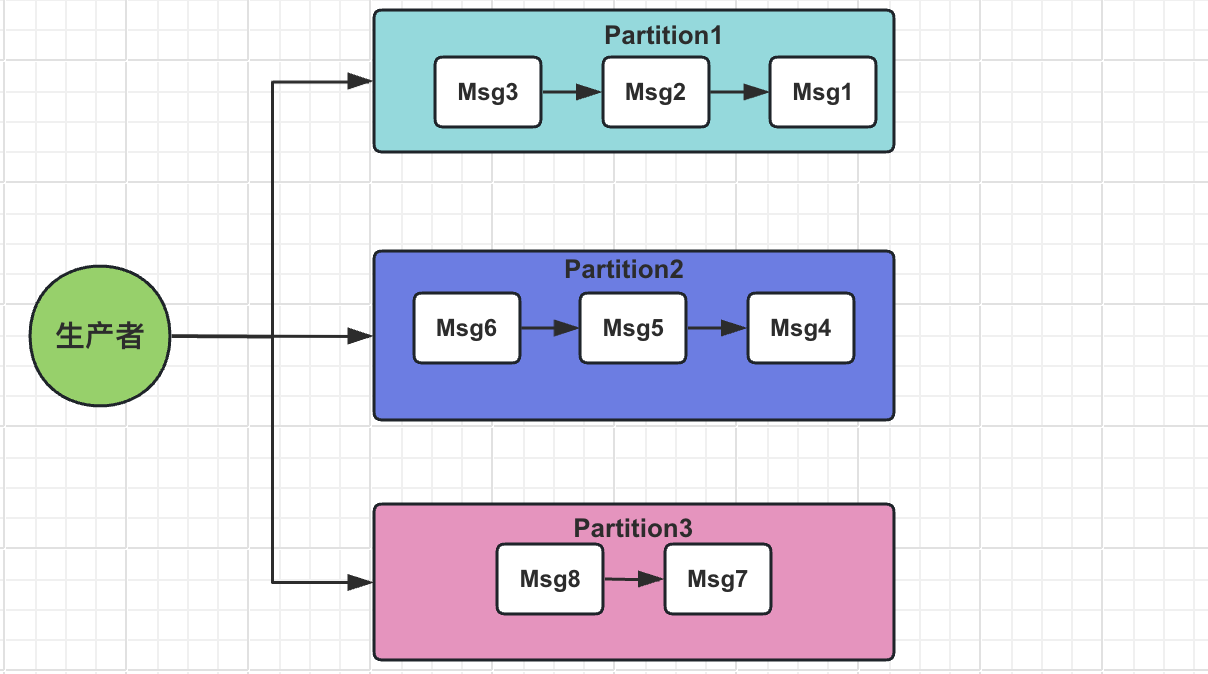
2. 单分区内的消息顺序性保证
在单个Kafka分区中,消息的顺序性得到了严格的保证。新产生的消息总是附加到分区日志的末端,消费者按照消息在分区中的物理顺序进行消费。如下图所示,每个分区内部的消息具有明确的偏移量(Offset),消费者按照递增的Offset顺序消费消息。
3. 利用键(Key)实现消息到特定分区的路由策略
通过为消息设置Key,Kafka可以确保具有相同Key的消息被路由到同一个分区,这就为实现消息顺序消费提供了基础。以下是一个简单的键路由策略的伪代码表示:
public class KeyBasedPartitioner implements Partitioner {
private AtomicInteger counter = new AtomicInteger(0); // 示例中使用一个原子整数作为轮询计数器
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
// 假设key是String类型,可以根据业务需求转换key类型并计算分区索引
if (key instanceof String) {
int partition = Math.abs(key.hashCode() % numPartitions); // 简单的哈希取模分区策略
// 或者实现更复杂的逻辑,比如根据key的某些特性路由到固定分区
return partition;
} else {
// 如果没有key,或者key不是预期类型,可以采用默认的轮询方式
return counter.getAndIncrement() % numPartitions;
}
}
@Override
public void close() {}
@Override
public void configure(Map<String, ?> configs) {}
}
通过上述策略,我们可以根据业务需求将相关联的消息路由到特定分区,从而在该分区范围内保证消息的顺序消费。而在全局层面,需要业务逻辑本身支持消息的局部顺序性,并通过合理设置分区数和消费者数量,兼顾消息顺序与处理效率之间的平衡。
Kafka原生保证消息顺序消费的实现
在Apache Kafka中,原生实现消息顺序消费主要围绕分区(Partition)和消费者组(Consumer Group)机制展开。以下是如何通过Kafka原生功能确保消息顺序消费的具体步骤和示例:
生产者侧:首先,确保消息按照需要的顺序发送到Kafka。若需要全局顺序,所有的消息应被发送到同一个分区。为此,可以通过设置消息键(key)并将所有消息映射到同一个确定的分区上。例如,可以自定义分区器,或者依赖Kafka默认的分区器,后者会基于消息键的哈希值均匀分布到各个分区,但具有相同键的消息会被路由到同一分区。
// 使用默认分区器,确保相同key的消息进入同一分区
Properties props = new Properties();
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
// 不自定义分区器,则使用默认分区器,根据key的哈希值决定分区
KafkaProducer<String, OrderMsg> producer = new KafkaProducer<>(props);
// 发送消息时设置key,确保相同key的消息进入同一分区
producer.send(new ProducerRecord<>("toc-topic", "toc-key", orderMsg));
消费者侧:
消费者组:在消费者组层面,确保每个分区仅被组内一个消费者实例消费,这样才能保证该分区内的消息顺序消费。可通过设置消费者组内消费者的并发度为分区数或小于分区数来达到这个目的。
// 设置消费者组并控制并发度等于分区数
props.put(ConsumerConfig.GROUP_ID_CONFIG, "toc-consumer-group");
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "1"); // 一次只消费一条,增强顺序消费效果
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); // 从头开始消费
KafkaConsumer<String, OrderMsg> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("toc-topic"));
while (true) {
ConsumerRecords<String, OrderMsg> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, OrderMsg> record : records) {
// 按照消费到的消息顺序处理
processMessageInOrder(record.value());
}
// 控制消费速率并提交offset
consumer.commitAsync();
}
只需保证具有相同键的消息顺序,生产者可以通过设置消息键确保这些消息被路由到同一分区。消费者只需在自己负责的分区上按照接收到的顺序处理消息即可。
通过以上方式,Kafka原生支持了消息的局部顺序消费(单个分区内),以及在特定条件下(如通过消息键路由)的全局顺序消费。然而,全局顺序消费可能牺牲系统的扩展性和并行处理能力,因此在实际应用中需要根据业务需求和性能指标做权衡和优化。
而单分区确实能保证消息顺序消费,但是在并发高的业务场景中,处理消息的效率很地下,那么我们如何在保证顺序消费的前提下又要提高处理效率呢?
多分区下的顺序消费策略
多分区顺序消费
在多分区场景下,实现全局顺序消费的一种策略是通过定制分区策略,确保具有顺序要求的消息被路由到特定的分区。这种方式适用于那些需要根据业务标识(如订单ID、用户ID等)保持消息顺序的场景。
借助自定义分区器,可以确保具有相同业务标识的消息被发送到同一分区,从而在单个分区内部保持消息顺序。
public class OrderIdPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 假设key是我们需要排序的订单ID
if (key instanceof String) {
int numPartitions = cluster.partitionCountForTopic(topic);
String orderId = (String) key;
// 这里只是简单示例,实际项目中应根据业务逻辑制定合适哈希算法
int partition = Math.abs(orderId.hashCode()) % numPartitions;
return partition;
} else {
// 若key非字符串类型,可以采用默认分区策略
return DEFAULT_PARTITION;
}
}
}
然后我们注册并使用自定义分区器,确保消息按照业务标识路由到正确的分区。
@Configuration
public class KafkaProducerConfig {
@Bean
public KafkaTemplate<String, OrderMsg> kafkaTemplate() {
Map<String, Object> configProps = new HashMap<>();
// 其他配置...
configProps.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, OrderIdPartitioner.class);
DefaultKafkaProducerFactory<String, OrderMsg> producerFactory = new DefaultKafkaProducerFactory<>(configProps);
return new KafkaTemplate<>(producerFactory);
}
}
异步处理与队列缓冲
为了在多分区环境中既能保证消息顺序消费,又能提高处理效率,在多分区顺序消费的基础上可以引入内存队列(如Java中的BlockingQueue)作为缓冲区,并结合多线程异步处理,提高消费端消费消息的能力。
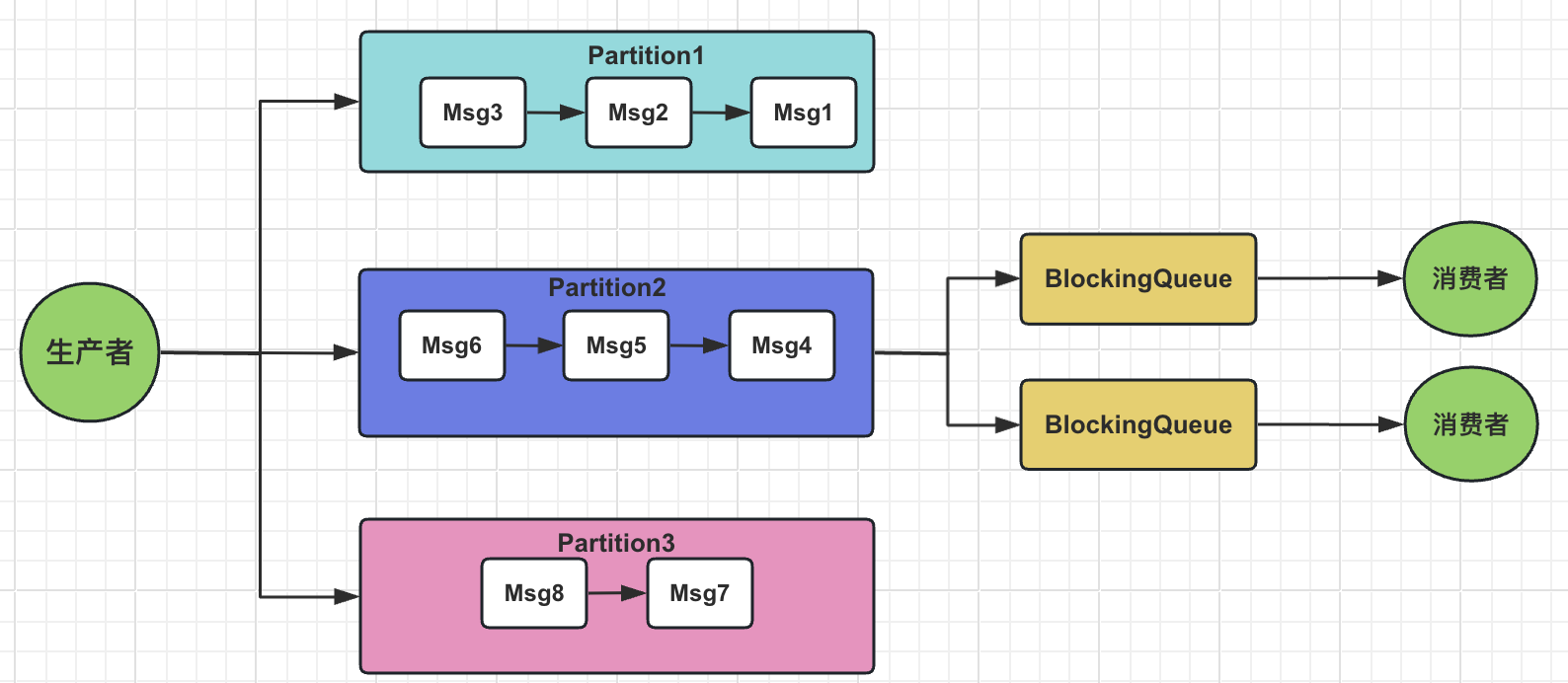
消费者接收到消息后,将消息放入内存队列中:
BlockingQueue<ConsumerRecord<String, OrderMsg>> messageQueue = new LinkedBlockingQueue<>();
@KafkaListener(topics = "your-topic")
public void consumeMessage(ConsumerRecord<String, OrderMsg> record) {
try {
messageQueue.put(record);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
// 错误处理...
}
}
然后,使用线程池消费队列中的消息,确保消息按照放入队列的顺序处理:
ExecutorService executorService = Executors.newFixedThreadPool(NUM_THREADS);
while (true) {
ConsumerRecord<String, OrderMsg> record;
try {
record = messageQueue.take();
executorService.submit(() -> processMessage(record));
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
// 错误处理...
}
}
private void processMessage(ConsumerRecord<String, OrderMsg> record) {
// 按照顺序处理消息
}
// 在应用关闭时,记得关闭线程池
executorService.shutdown();
这种方式,即使在多分区的情况下,系统依然能够保证具有相同业务标识的消息顺序消费,同时通过异步处理和队列缓冲提升了整体的处理效率。然而,这也意味着需要处理好队列溢出、线程同步等问题,以确保系统的稳定性和可靠性。
关于线程池的原理以及使用,请移步:
总结
Apache Kafka在消息顺序消费方面的设计体现了其高度的灵活性和可扩展性。通过巧妙利用分区机制,Kafka能够在单个分区内部提供严格的顺序保证,这为需要消息顺序处理的业务场景提供了坚实的基础。通过自定义分区策略,尤其是利用消息键(Key)实现消息到特定分区的路由,Kafka能够确保具有相同键值的消息保持顺序,这对于很多业务逻辑而言至关重要。
与此同时,Kafka支持消费者组概念,使得一组消费者可以订阅同一个主题,每个分区在同一时刻仅由消费者组中的一个消费者实例消费,从而保证了分区内部消息的顺序消费。通过结合微批处理、批量提交等优化实践,Kafka能够进一步提高消息处理效率,同时兼顾系统性能与消息顺序性。
然而,在实际应用中,尤其是在多分区场景下,完全保证全局消息顺序可能会牺牲一定的系统扩展性和处理性能。因此,在设计和实施消息顺序消费方案时,需要综合考虑以下几个方面:
-
系统性能:通过合理的分区策略和消费者并发度设置,优化资源利用率,提升系统吞吐量。
-
消息顺序性:针对不同业务需求,灵活运用分区和键值策略,保证关键业务流程的消息顺序。
-
系统可用性:设计有效的错误处理与重试机制,确保在发生故障时仍能保持消息的可靠传递,同时不影响正常消息的顺序消费。
Apache Kafka在消息顺序消费领域展现了强大的灵活性和适应性,允许我们在保障消息顺序性的同时,优化系统性能和可用性。在面对实际业务需求时,务必根据具体情况权衡利弊,制定最适合的解决方案,以期在保障业务流程正确执行的同时,实现系统的高效稳定运行。
本文已收录于我的个人博客:码农Academy的博客,专注分享Java技术干货,包括Java基础、Spring Boot、Spring Cloud、Mysql、Redis、Elasticsearch、中间件、架构设计、面试题、程序员攻略等
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。













暂无评论内容