


- 文章作者:陈亦新
-
0 综述
0.1 发展过程
- 2021.01 DALLE OPENAI 120亿参数
- 2021.05 CogView 清华 支持中文
- 2021.11 NvWa(女娲) 微软+北大 生成图像和比较短的视频
- 2021.12 GLIDE OPENAI
- 2021.12 ERNIE-ViLG 百度 100亿参数+中文
- 2022.04 DALLE2 OPENAI
- 2022/04 CogView2 清华
- 2022/05 CogVideo 清华
- 2022/05 Imagen Google 相对于DALLE2简化,并且效果不相上下
0.2
DALLE2应该是第一个结合了CLIP和扩散模型的论文,里面的作者直接原班人马。
0.3
CLIP可以抓住图片的很鲁棒的特征,包含语义和风格特征。DALLE2包含两个stage的特征:
- a prior that generates a CLIP image embedding given a text caption;
- a decoder that generates an image conditioned on the image embedding.
prior的作用就是把经过CLIP模型得到的text embedding,转换成CLIP的image embedding。相当于是丰富了CLIP的一种用途。训练的groundtruth也是CLIP的给出的image embedding。
decoder就是利用扩散模型把image embedding还原成原始图片。
当然,这里我也自然的提出了思考,为什么不让decoder直接从text embedding转换到image呢?论文中给出了这样的回复:
We show that explicitly generating image representations improves image diversity with minimal loss in photorealism and caption similarity。
0.4 guidance technique
论文中提出了,在2015年以来,采样的方法已经提出,但是保真度一直不如GAN。中间有很多的改进,其中有一个技巧叫做“guidance”,可以牺牲一部分多样性的情况下,大幅度的提高生成图片的保真度。从此和GAN在inception和FID score上都不相上下了。
1 算法
1.1 模型结构
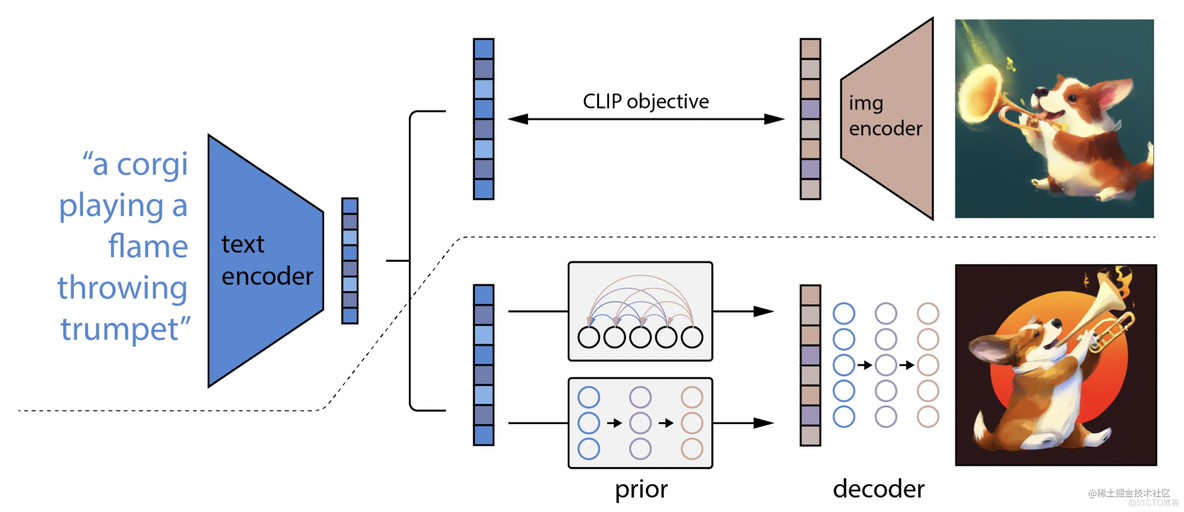
- 上面是CLIP模型的训练,之前的讲解中已经说过了;juejin.cn/post/713863…
- CLIP模型不会进行finetune,是一直freeze的。
- prior发现,先显式的将text embedding转换成image embedding,效果会好很多。
论文中管自己叫做unclip,并不是DALLE2,因为这是从特征到图片的过程,是CLIP的反过程
1.2 生成算法回顾
1.2.1 GAN
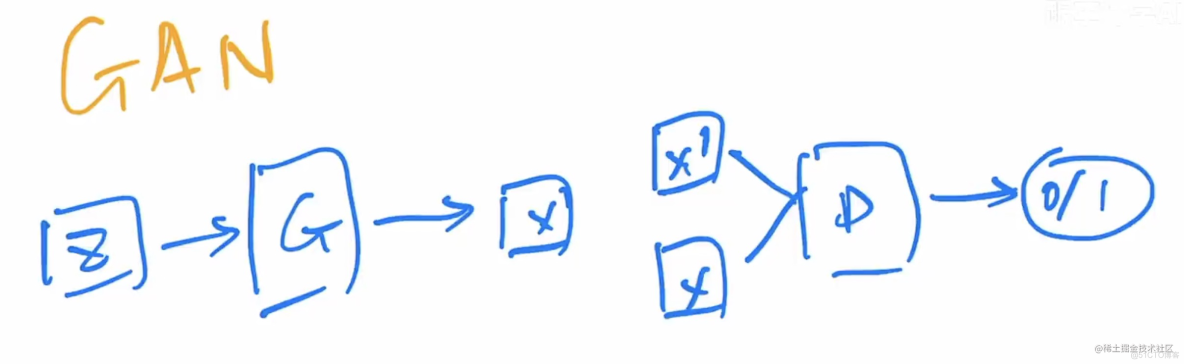
- 保真度高,不稳定,多样性不够。因为GAN的优化目标就是以假乱真的保真度,多样性和不稳定没有保障。
1.2.2 AE / DAE
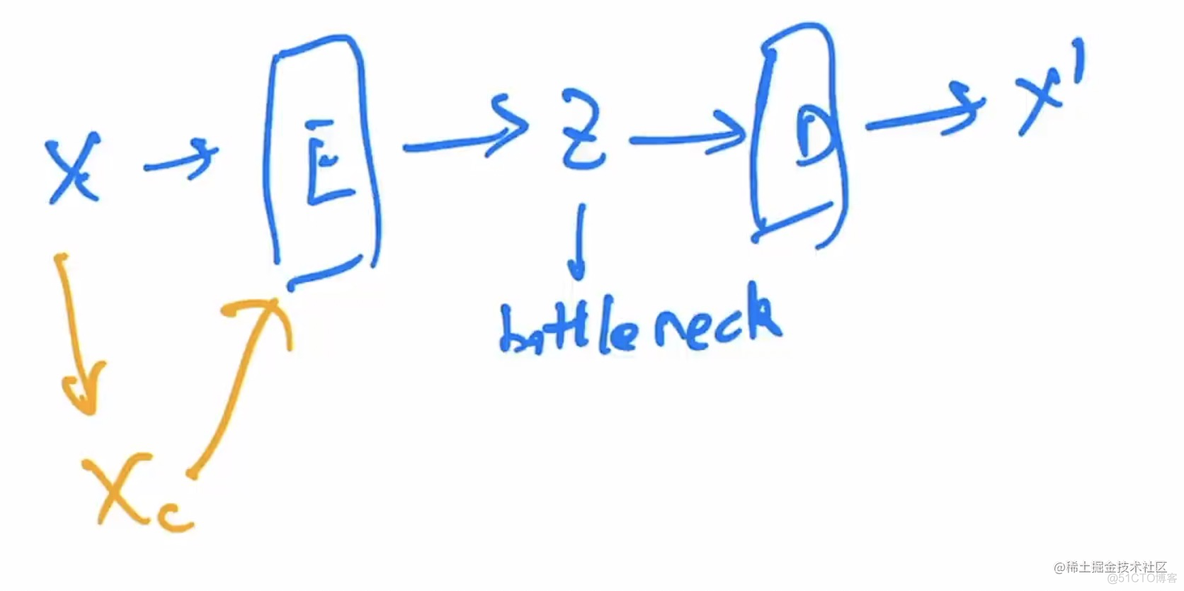
- 目的是重建。目的是学习bottleneck的特征,这里没有采样的概念,所以无法生成。
1.2.3 VAE

- VAE学习概率分布,多样性比GAN好很多。
1.2.4 VQ-VAE
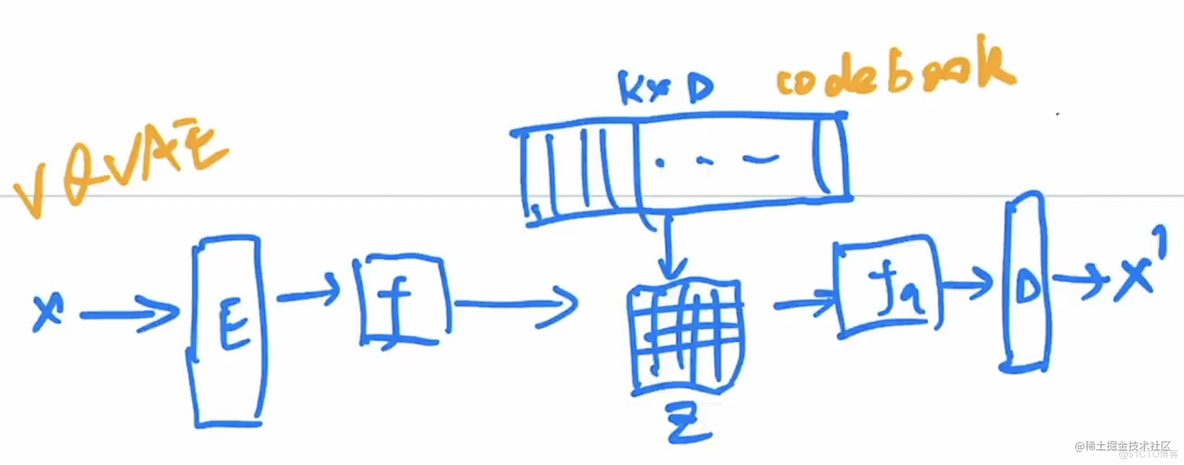
- 8192×512。
- VQ Vector Quantilised
- 我们得到的特征图f是一个wh的特征图,每一个像素的向量和code book里面做对比,然后取出来对应的编号。存成z。BEIT就是借用了VQ-VAE的思路。DALLE也是基于VQ-VAE。
- 需要注意的是,这里没有采样,VQ-VAE类似AE而不是VAE。所以这里训练了一个pixelCNN自回归模型。
1.2.5 DALLE
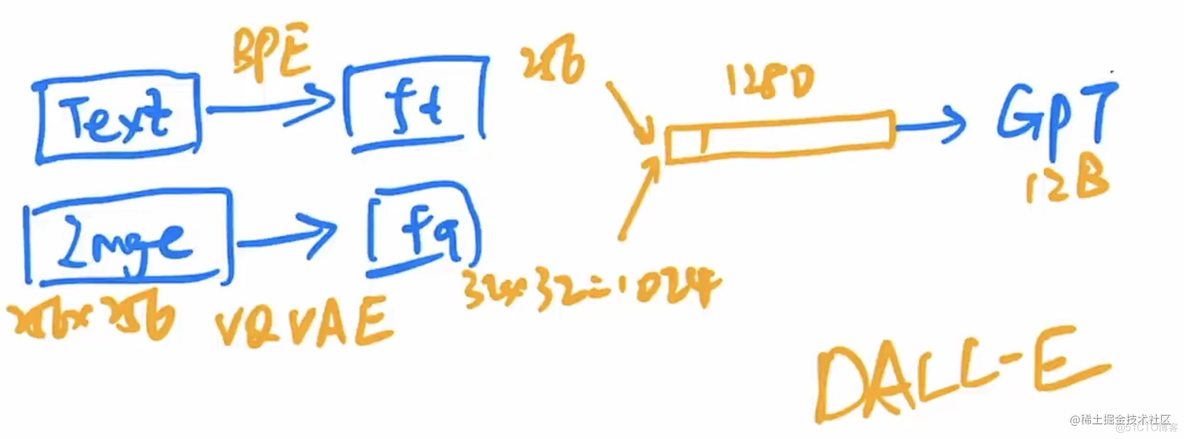
- 文本通过BPE编码(256),Image通过VQVAE编码,然后得到1024的特征,拼接成1280的特征。
- 之前用的pixelCNN自回归模型,那么自回归生成模型GPT更牛逼。
- 然后随机遮住一些,用BERT的方法微调GPT。毕竟就是openAI的看家本领。
- 推理的时候,就只有文本的256的特征,然后用自回归的方法慢慢恢复后面的1280特征。然后放回VG-VAE当中复原即可。所以这也是二阶段的模型。
- 关键是怎么训练GPT的12B的模型参数,大力出奇迹!
1.3 扩散模型回顾
1.3.1 扩散模型
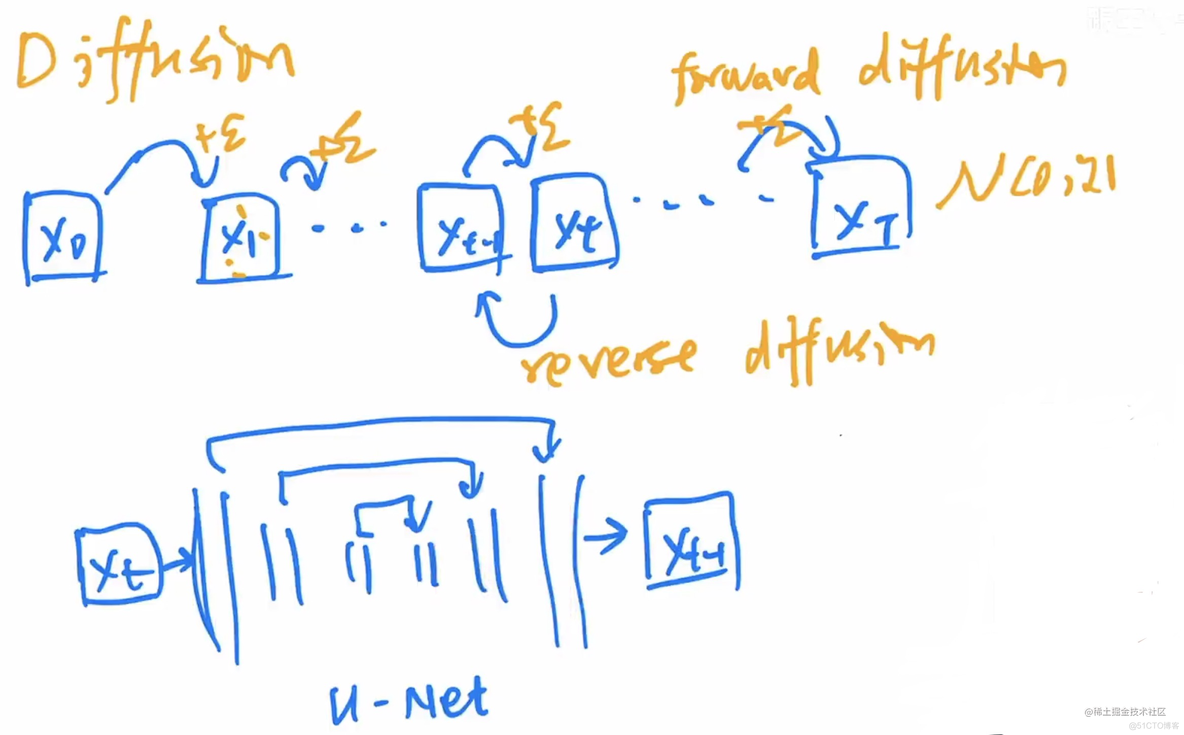
扩散模型常见的用的Unet的结构。
1.3.2 DDPM
因为生成图像发现比较难训练,所以Unet开始预测两个时间戳图像之间的噪音。
1.3.3 improved DDPM
因为DDPM的成功让DALLE的二、三作立刻去研究,提出了improved DDPM。
- 我还没细看,大概就是在beta的schedule上,从线性变成了非线性(余弦?);
- DDPM只学习分布的均值,不学习方差。improved上同时学习
1.3.3 Diffusion betas GAN
- 二、三作继续研究,发现diffusion models的扩展性非常好,数据集越大,那么生成图像的效果就会越好;
- 提出了adaptive group normalization,没细看,就是时间戳t也会作为group normalization的一个参数;
- 使用了guidance的技巧,让扩散模型的反向过程从DDPM的1000可以缩短到25.
2 guidance technique
2.1 classifier guidance technique
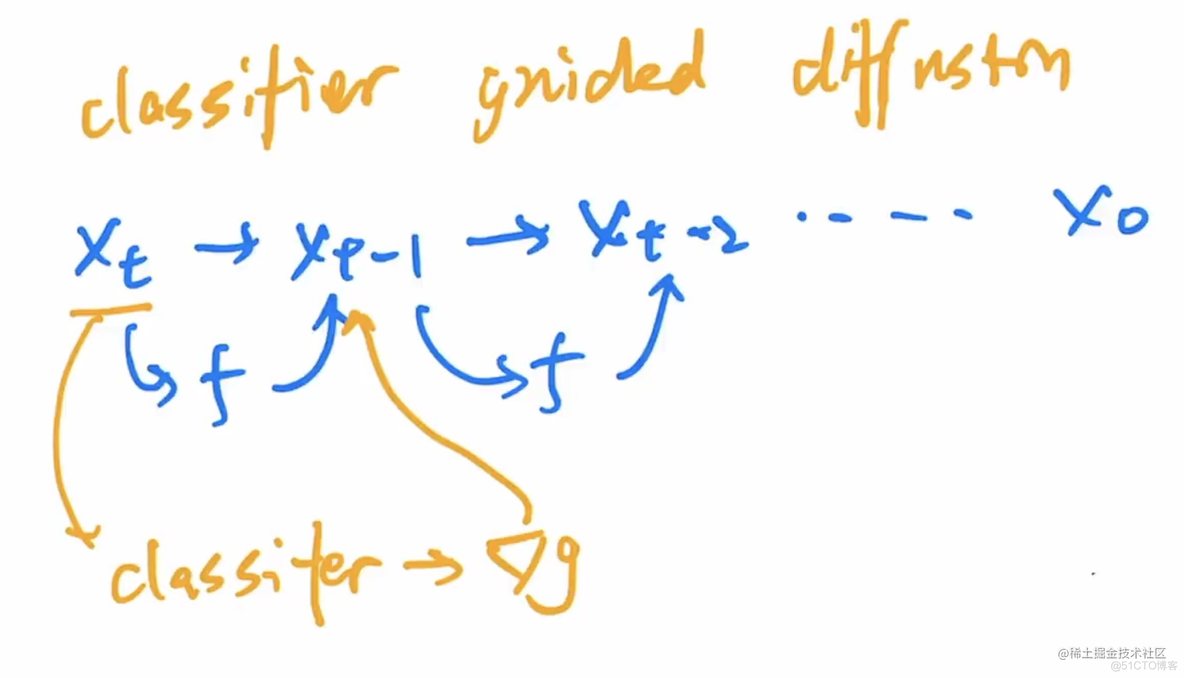
加上图像分类器,一般是加了噪音的imagenet训练的。通过梯度的对diffusion模型的提取进行指导。也因此,首次战胜了BigGAN。最大问题就是,需要另外一个模型,pretrained-model,很麻烦,也不稳定。
2.2 classifier free technique
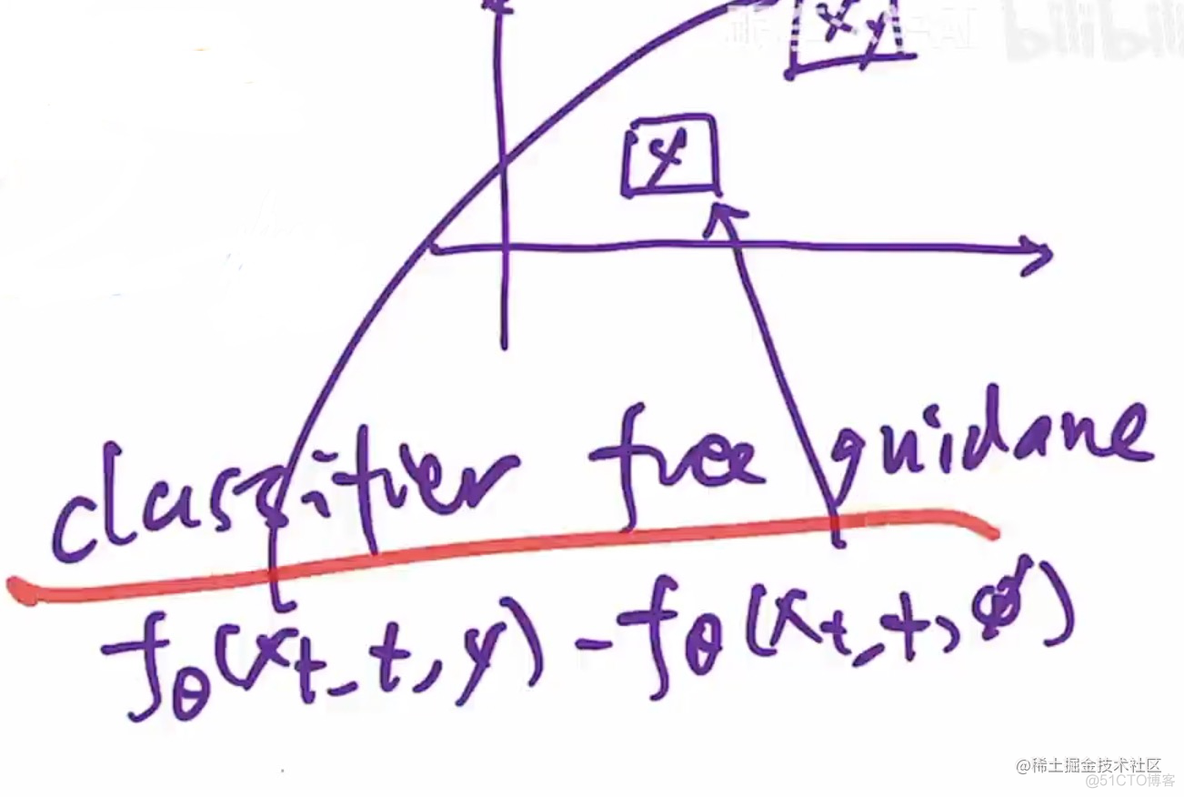
只是指在推理过程中,不用提示。但是训练的时候,会变得更贵。
3 重开模型结构
核心公式:

后者是prior,前者是decoder(GLIDE)。
prior用了两种,autogressive和diffusion prior。后者效率高所以用后者。
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。









暂无评论内容