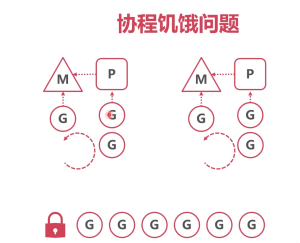


当m在执行某个g的时候,g非常耗时,例如一个for循环,每次循环sleep1分钟,循环1000次。
这个例子看似无聊,却是很难解决的,成功的避开了2个系统切换时机。
如果这个时候,一直执行这个g,别的g就会得不到执行,例如有g是处理用户支付的,这样就会造成收钱不积极。
协程饥饿问题
本地队列
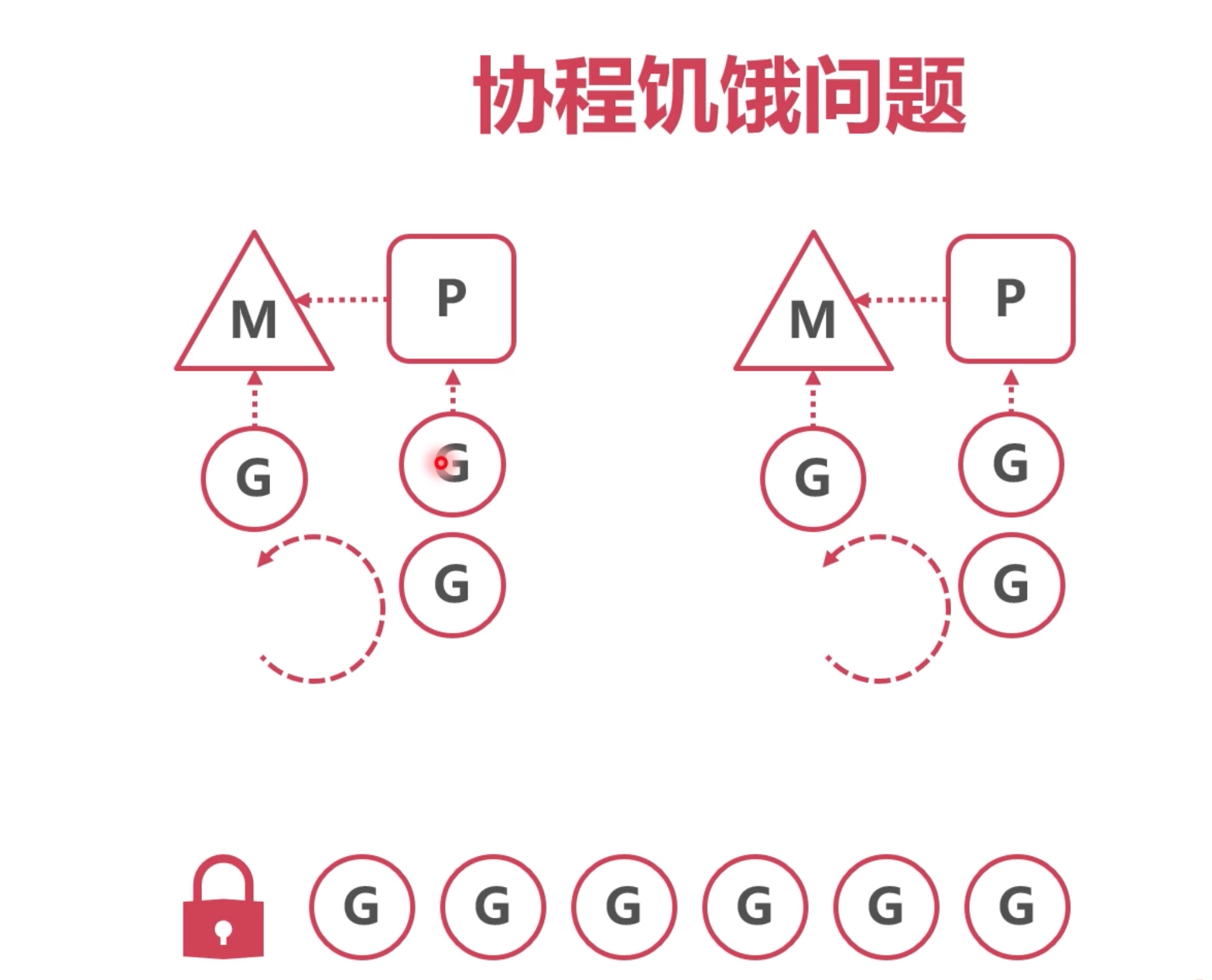
本地队列因为 某个G一直 占着M,导致其他G无法执行。
如果占用时间过长的这个G,能让出来M,让别的G也能执行,本地队列循环的着执行,就能解决这个问题。
全局队列
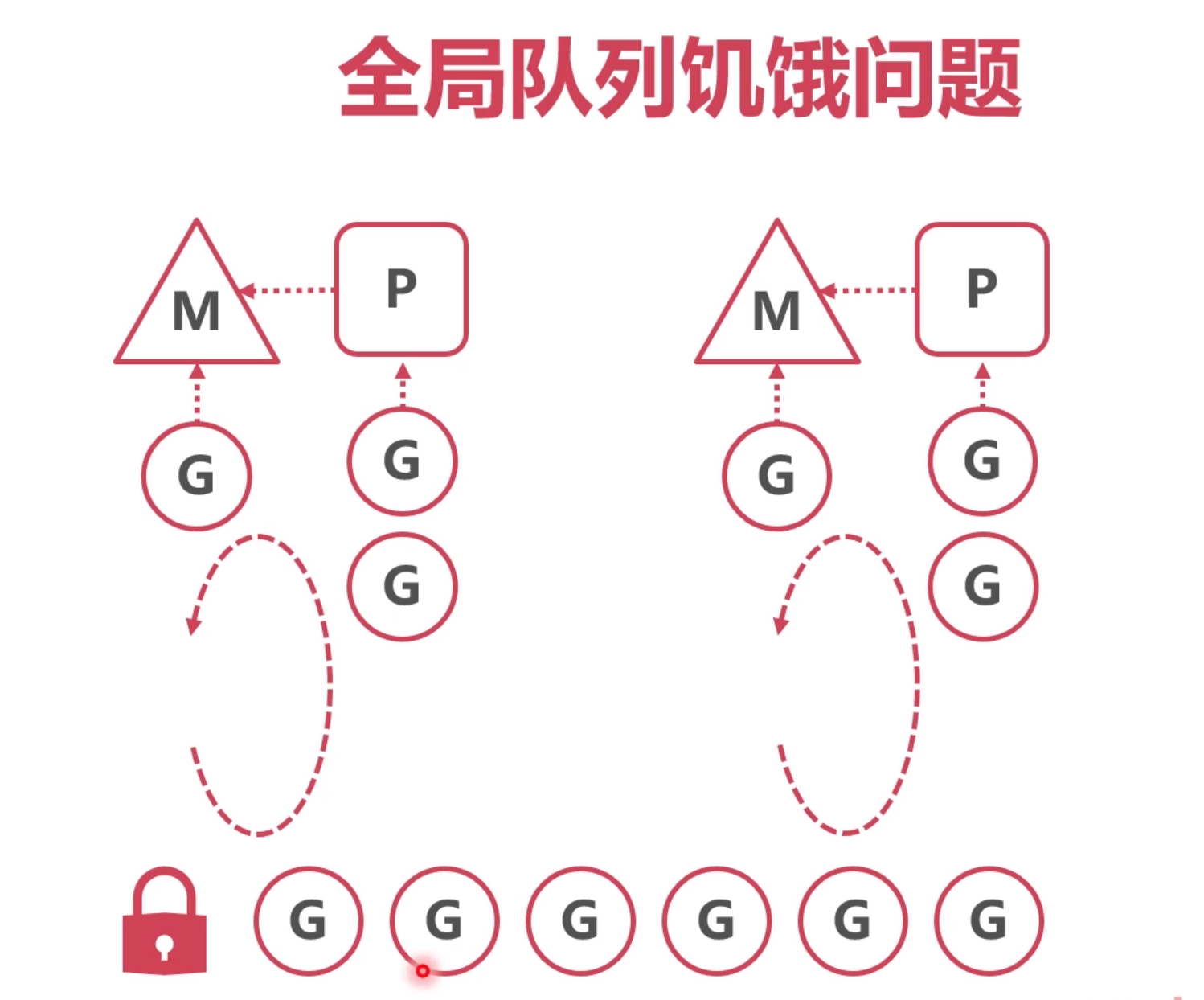
除了本地队列,全局队列也会有这个问题,如果一个新创建的g,放在全局队列中,而现有的p的本地队列都未执行完,则全局队列需要排队很久。
解决办法,每过一段时间,每个本地队列都先来全局队列中取1个,这样就能解决这个问题。
代码实现:
又到了findRunnable()
// Check the global runnable queue once in a while to ensure fairness.
if pp.schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp := globrunqget(pp, 1)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}
这个优先级在 本地队列之前。之前看过 globrunqget()中的逻辑,当max为1时候,就只会取一个。
每61次,就去全局队列中拿一个。
解决办法
协程因为独特的数据结构,能能够暂停的,之前协程的本质有介绍过,暂停后,让别的g也开始循环执行。
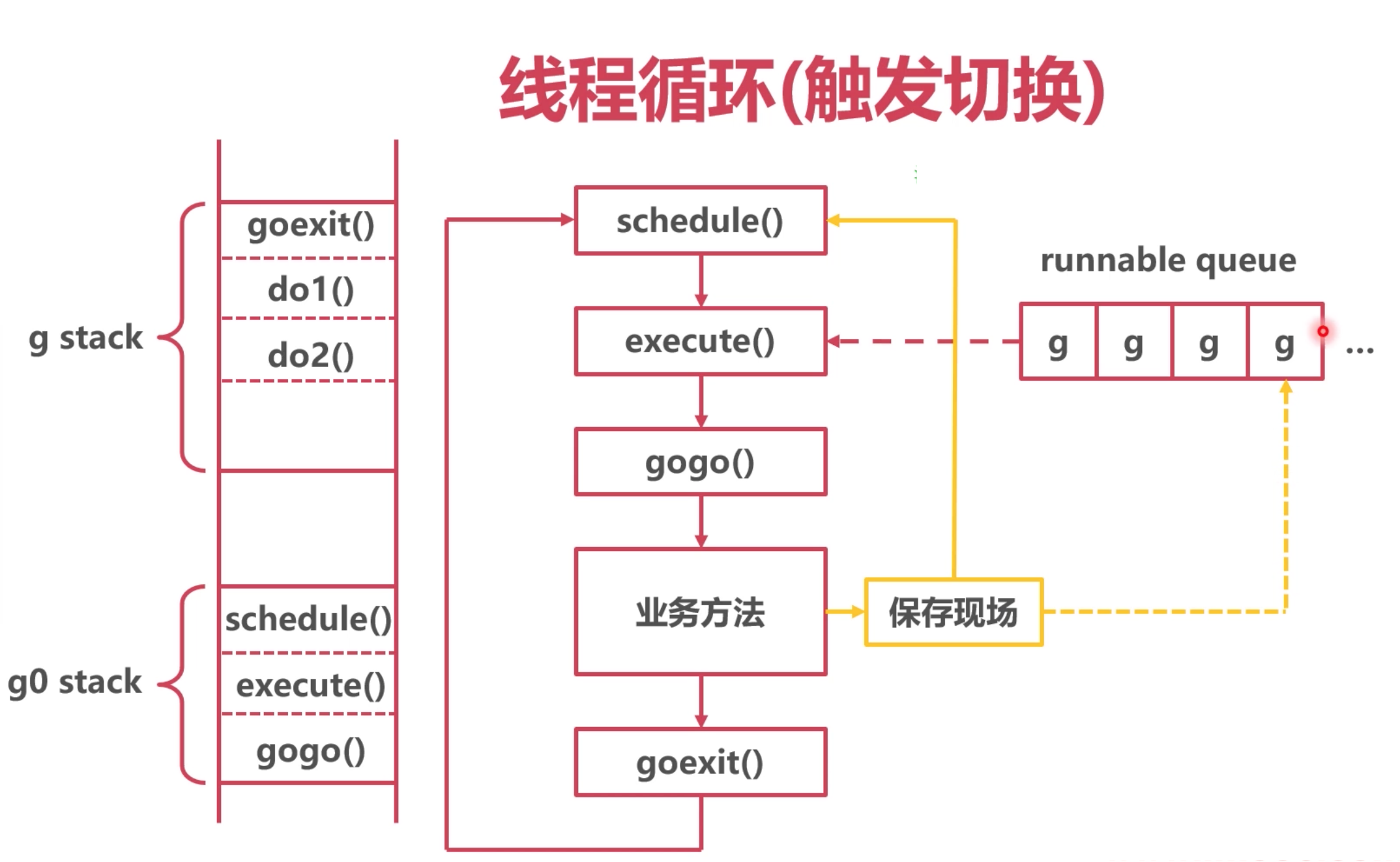
切换时机
主动挂起
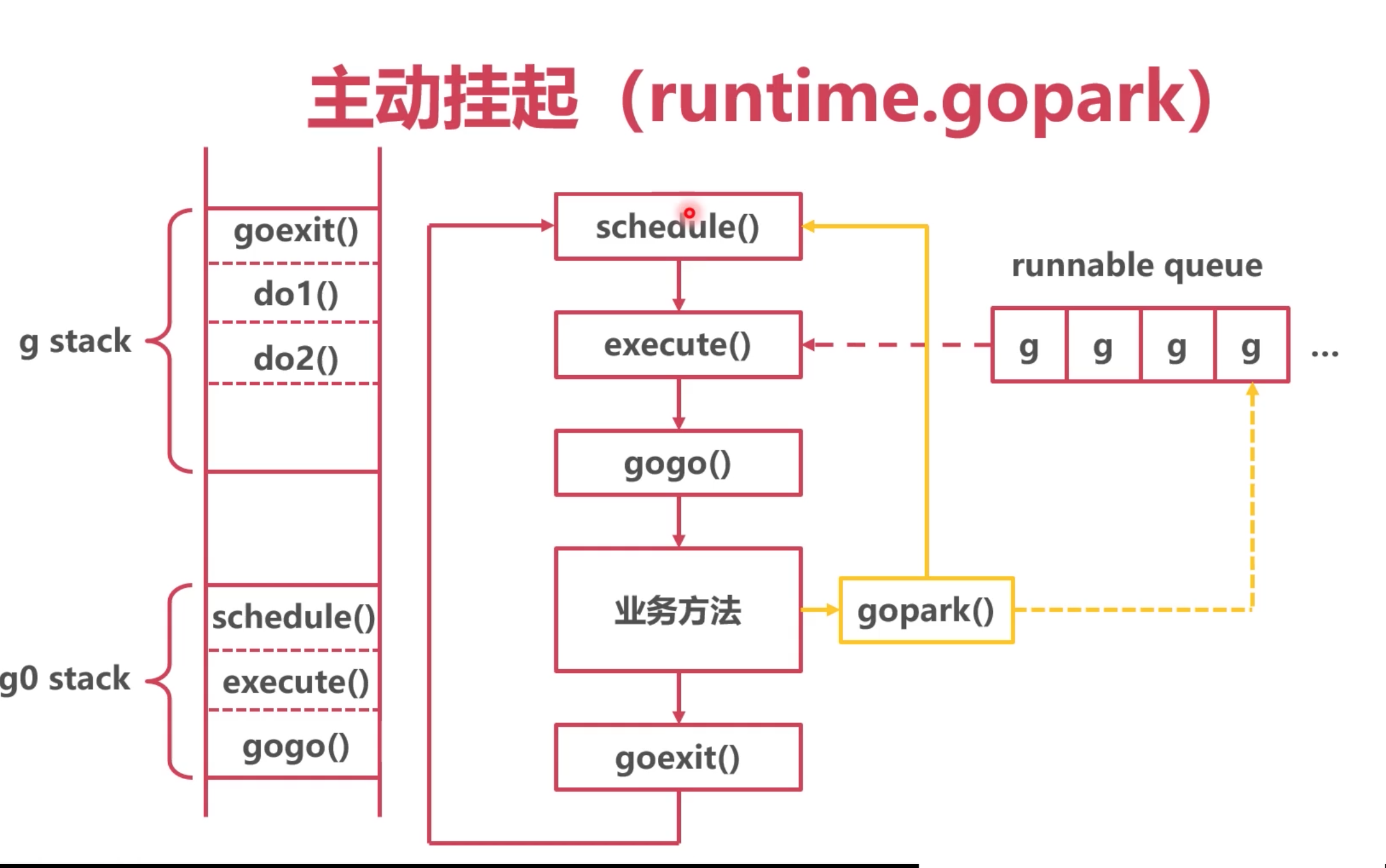
业务方法主动调用gopark 然后,切换协程。
源码在proc.go中
// Puts the current goroutine into a waiting state and calls unlockf on the
// 让当前的 g 进入 waiting的状态
func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceReason traceBlockReason, traceskip int) {
if reason != waitReasonSleep {
checkTimeouts() // timeouts may expire while two goroutines keep the scheduler busy
}
mp := acquirem()
gp := mp.curg
status := readgstatus(gp)
if status != _Grunning && status != _Gscanrunning {
throw("gopark: bad g status")
}
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waitTraceBlockReason = traceReason
mp.waitTraceSkip = traceskip
releasem(mp)
// can't do anything that might move the G between Ms here.
mcall(park_m) // 切换到了 g0栈,前面讲过mcall
}
// park continuation on g0.
func park_m(gp *g) {
mp := getg().m
// 中间还有代码
if fn := mp.waitunlockf; fn != nil {
ok := fn(gp, mp.waitlock)
mp.waitunlockf = nil
mp.waitlock = nil
if !ok {
if traceEnabled() {
traceGoUnpark(gp, 2)
}
casgstatus(gp, _Gwaiting, _Grunnable)
execute(gp, true) // Schedule it back, never returns.
}
}
schedule() //调了这个方法,之前讲过,一旦调用这个方法,就会给m找新的g
}
有个问题:gapark是小写的,程序员在编码中是使用不了的,那怎么让业务主动调用?
系统runtime里面很多方法有去调用,例如
time.Sleep、channel的等待等
系统调用完成时
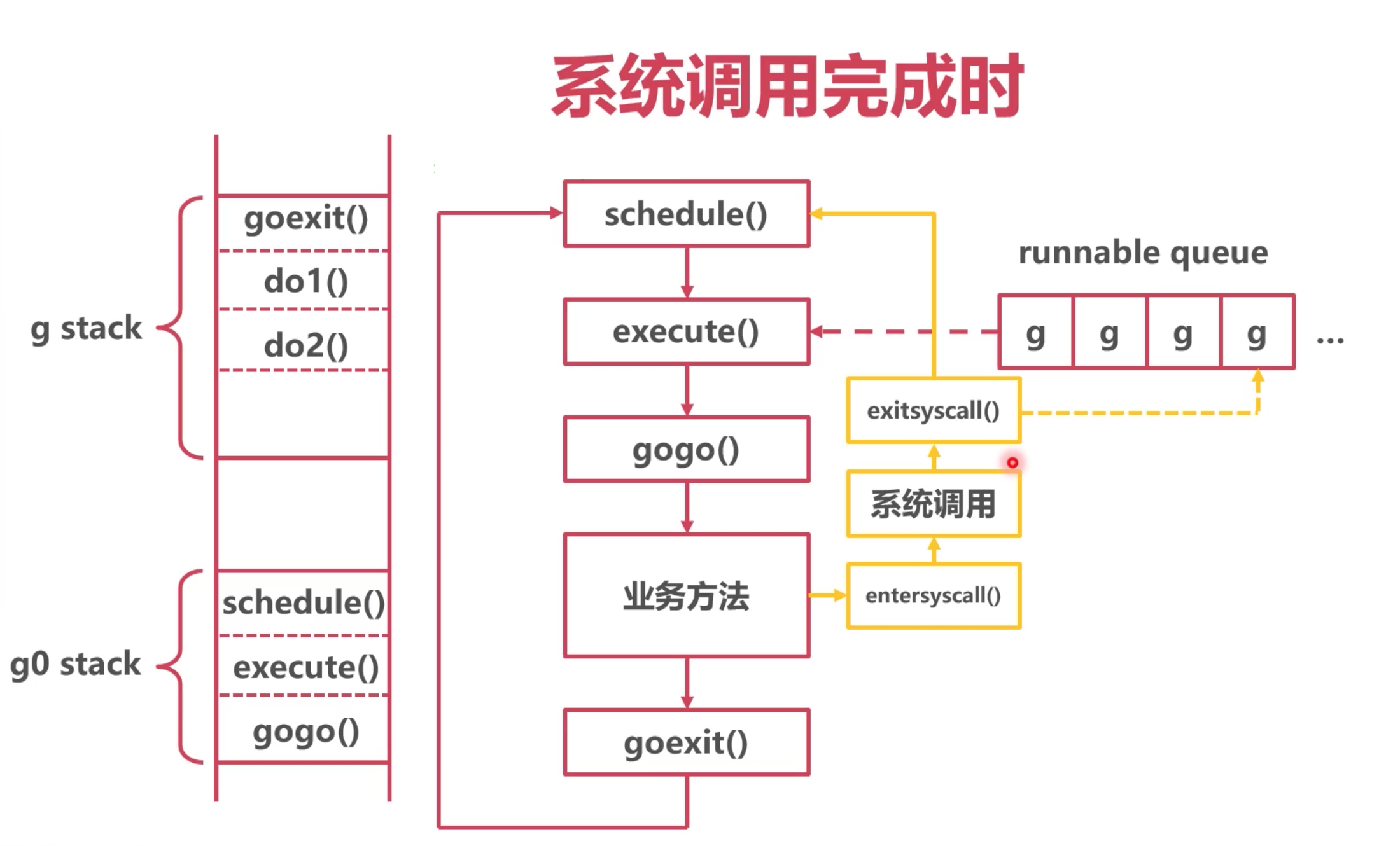
在进行一些系统调用后,例如网络请求等会主动去调这个 exitsyscall() 这个方法,这个方法也会最终走到 schedule()
这个源码在 syscall_aix.go中,因为有好几层函数调用,就不贴出来了。
标记抢占 基于 morestack
1. 系统监控到 Goroutine 运行超过 10ms
2. 将 g.stackguard0 置为 Oxfffffade
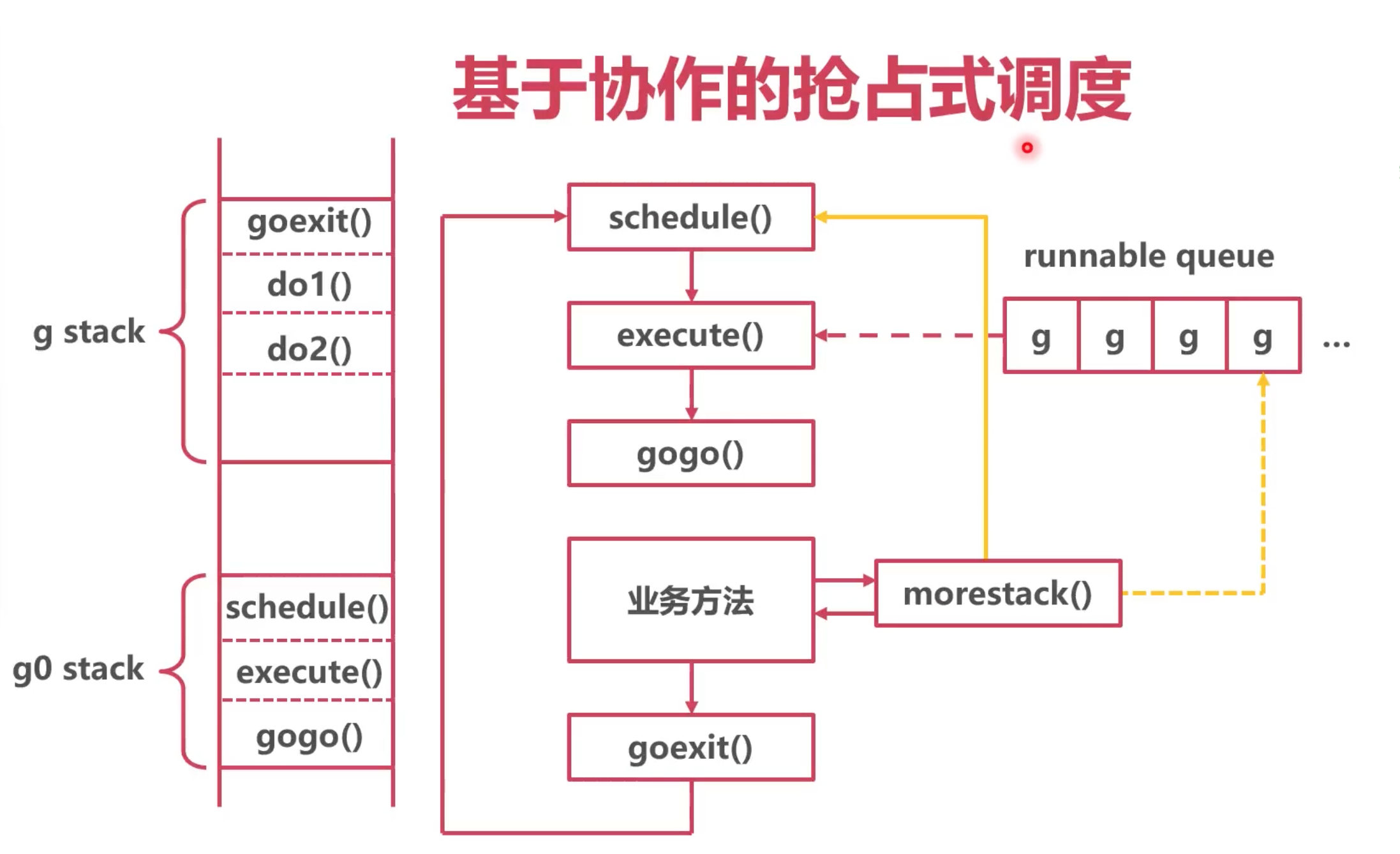
morestack() 方法,在函数跳转时候,会自动调用,本意是检测下新的函数,有没有足够的栈空间。
系统在这个函数中,去做了一部分协程切换的,防止一些 耗时比较久的协程,不去触发上面两种方案。
看下源码:
// Called during function prolog when more stack is needed.
// record an argument size. For that purpose, it has no arguments.
TEXT runtime·morestack(SB),NOSPLIT,$0-0
// 中间很多扩充栈空间的代码
CALL runtime·newstack(SB) // 跟进这个方法
CALL runtime·abort(SB) // crash if newstack returns
RET
// Goroutine preemption request.
// 0xfffffade in hex.
stackPreempt = uintptrMask & -1314
func newstack() {
// 中间还有很多源码
// 抢占标记 如果g的.stackguard0 字段被标记为抢占,就会触发下面的逻辑
stackguard0 := atomic.Loaduintptr(&gp.stackguard0)
preempt := stackguard0 == stackPreempt
if preempt {
// Act like goroutine called runtime.Gosched.
gopreempt_m(gp) // never return
}
}
func gopreempt_m(gp *g) {
if traceEnabled() {
traceGoPreempt()
}
goschedImpl(gp)
}
func goschedImpl(gp *g) {
//删了一些源码,最终调了 schedule
schedule()
}
基于信号的抢占标记
开头那个 for 循环的例子,虽然很无聊,但是去避开了上面那种方案,
1. 不会调用 gopark
2. 不会系统调用
3.不会调用 morestack,因为没有函数调用
这时候,可以使用 信号 来触发协程的切换。
信号量可以在多线程和多进程直接进行通信(管道、共享内存、信号、消息队列一般作为多进程通信方式)。
原理:
操作系统中,有很多基于信号的底层通信方式,例如: SIGPIPE / SIGURG / SIGHUP
线程可以注册对应信号的处理函数
go的实现流程:
注册 `SIGURG`信号的处理函数
`GC`工作时,向目标线程发送信号
线程收到信号,触发调度,`gc`发送 `sigurg` 触发`runtime`的 `doSigPreempt()`
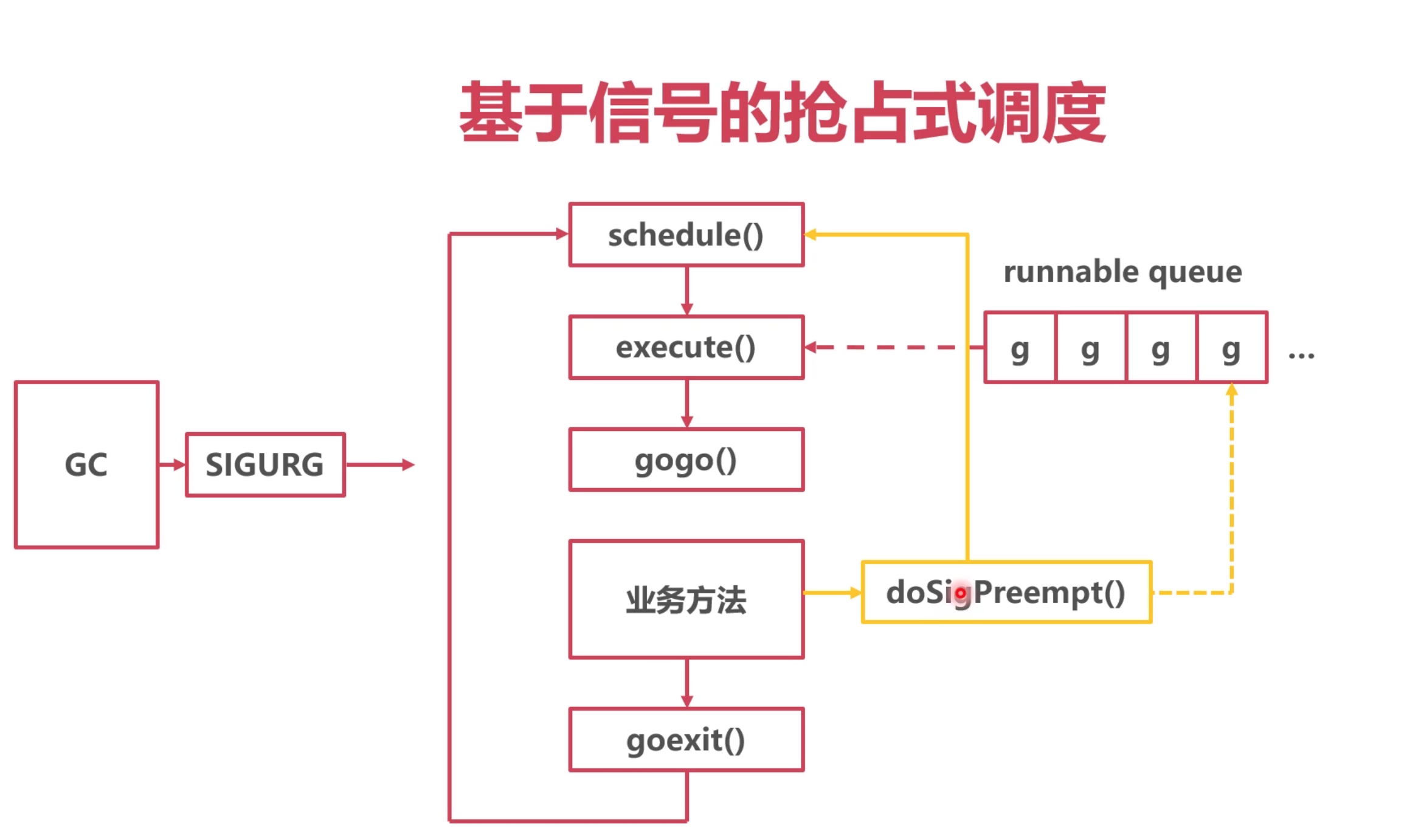
能够猜到 doSigPreempt(), 最终会去调 schedule() 方法。 源码就不贴了。
开发中,协程过多的问题
1. 文件打开数限制
过多协程调用文件读写,会操作系统崩溃。
2. 内存限制
过多协程创建,达到了内存的限制
3. 调度开销过大
过多协程,导致调度器调度复杂度增大
解决办法:
1. 优化业务逻辑
2. 利用 channel 的缓存区
3. 协程池
4. 调整系统资源
2和3都是从控制协程的数量入手,2适合 单个业务场景,3适合全局。
1和4好理解
利用 channel 的缓存区
func do(c chan interface{}) {
fmt.Println("do it")
<-c
}
func main() {
// 利用channel的特性来控制 go协程的个数
ch := make(chan interface{}, 100)
for {
ch <- struct{}{}
go do(ch)
}
}
这种适合在一个场景下适用,不推荐全局使用。
协程池
代表:https://github.com/Jeffail/tunny
原理:类似某些语言的线程池
1.预创建一定数量的协程
2.将任务送入协程池队列
3.协程池不断取出可用协程,执行任务
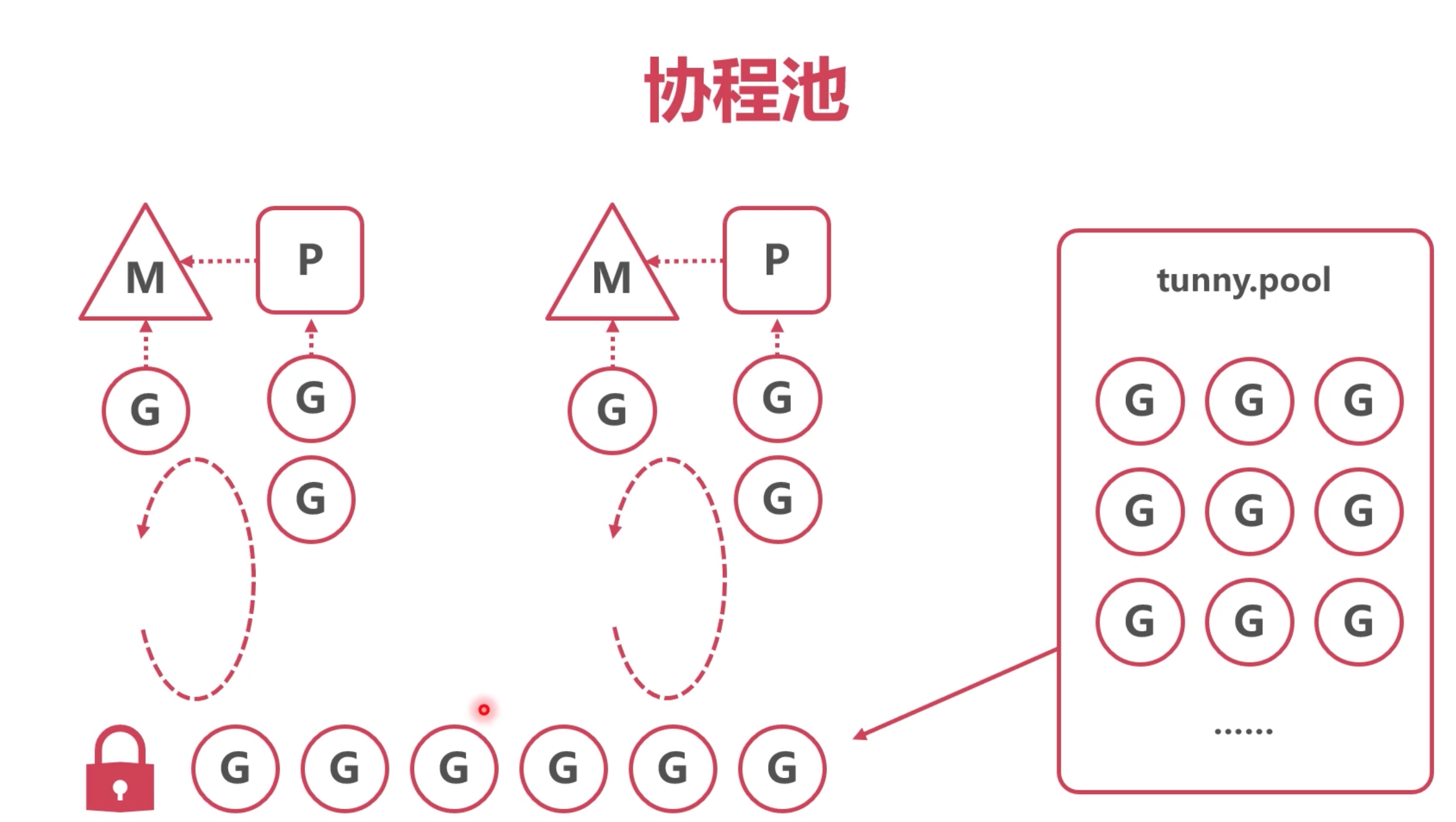
慎用协程池
Go语言的线程,已经相当于池化了
二级池化会增加系统复杂度
Go语言的初衷是希望协程即用即毁,不要池化
到此,go的GMP完结。
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。









暂无评论内容