



- 字符编码和排序规则
下面的讨论用到W、王和三个字符,以下是这三个字符的各种编码

先看看不带N和带N的字符字面量各用什么编码,用Microsoft SQL Server Management Studio连接SQL SERVER 2022执行下面SQL语句:
select N'W' charact, convert (varbinary (20) , 'W') Not_N, convert (varbinary (20) , N'W') N union all select N'王', convert (varbinary (20) , '王') , convert (varbinary (20) , N'王') union all select N'' ,convert (varbinary (20) , '') , convert (varbinary (20) , N'')
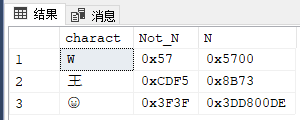
可以确定,带N的是用UTF-16编码,而不带N的不是GB2312就是GBK或GB18030,默认字符类型的编码用的是ANSI,即本机操作系统的活动代码页,可在CMD控制台界面中输入chcp得到代码页编号,再查看CMD控制台的属性即可看到是GBK。
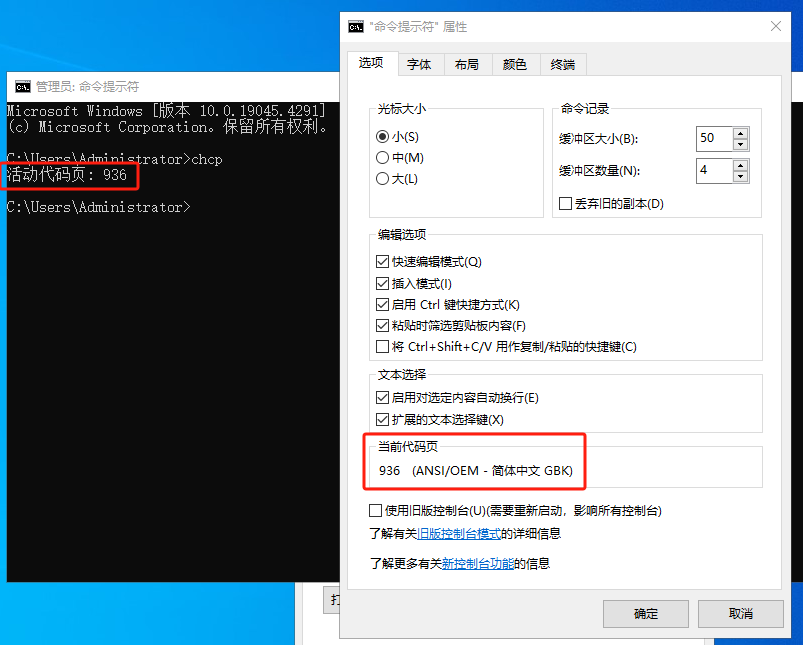
而GBK是没有字符的,所以不带N的无法储存到GBK中,也就无法转换成对应的UTF-16,GBK将无法转换储存的字符一律用3F3F(即两个??问号)来储存。
GBK编码是在GB2312-80标准基础上的内码扩展规范,使用了双字节编码方案,其编码范围从8140至FEFE(剔除xx7F),共23940个码位,共收录了21003个汉字,完全兼容GB2312-80标准,支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,并包含了BIG5编码中的所有汉字。GBK编码方案于1995年10月制定, 1995年12月正式发布,中文版的WIN95、WIN98、WINDOWS NT以及WINDOWS 2000、WINDOWS XP、WIN 7等都支持GBK编码方案。
再看在这个操作系统中建立的实例和数据库默认是什么排序规则
SELECT name, collation_name FROM sys.databases where name='TestDB'; --显示TestDB的排序规则
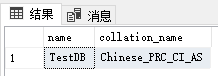 正是这个Chinese_PRC_CI_AS排序规则会使不带N的字符字面量用GBK编码。
正是这个Chinese_PRC_CI_AS排序规则会使不带N的字符字面量用GBK编码。
那问题来了,如果改用带UTF8的排序规则,字符字面量是不是就用UTF-8编码?我们再测试:
--新建排序规则为Chinese_PRC_90_CI_AS_SC_UTF8的数据库
CREATE DATABASE [UtfDB] CONTAINMENT = NONE COLLATE Chinese_PRC_90_CI_AS_SC_UTF8 WITH LEDGER = OFF
GO
--再查询
select N’W’ charact, convert (varbinary (20) , ‘W’) Not_N, convert (varbinary (20) , N’W’) N union all
select N’王’, convert (varbinary (20) , ‘王’) , convert (varbinary (20) , N’王’) union all
select N” ,convert (varbinary (20) , ”) , convert (varbinary (20) , N”)
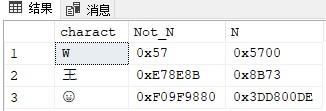
可以看到,不带N的列显示的是UTF-8编码,即数据库设定带UTF8排序规则,则不带N的字符字面量就用UTF-8编码。
- char和varchar类型
根据微软官方文档对char和varchar类型的描述:“字符数据类型 char(大小固定)或 varchar(大小可变)。 从 SQL Server 2019 (15.x) 起,使用启用了 UTF-8 的排序规则时,这些数据类型会存储 Unicode 字符数据的整个范围,并使用 UTF-8 字符编码。 若指定了非 UTF-8 排序规则,则这些数据类型仅会存储该排序规则的相应代码页支持的字符子集。”,也就是说从2019版本开始,char和varchar在设定下可以储存为Unicode了。下面我们用SQL SERVER2022做个测试:
use TestDB
GO
SELECT name, collation_name FROM sys.databases where name='TestDB'; --显示TestDB的排序规则
![图片[1]-SQL SERVER的字符类型使用Unicode-牛翰网](https://niuimg.niucores.com/wp-content/uploads/2024/08/297128546751346492.png)
–这个Chinese_PRC_CI_AS排序规则会使字符字面量用GBK编码。
create table tUnicode(
varc varchar(10), –默认的Chinese_PRC_CI_AS,
varcutf varchar(10) COLLATE Chinese_PRC_90_CI_AS_SC_UTF8 –指定带UTF8的排序规则
)
–插入以下六条记录
insert into tUnicode values(‘W’,N’W’) –英文字母
insert into tUnicode values(‘王’,N’王’) –汉字
insert into tUnicode values(”,N”) –表情字符,其Unicode编码得三个字节表示
insert into tUnicode values(N’W’,N’W’) –英文字母
insert into tUnicode values(N’王’,N’王’) –汉字
insert into tUnicode values(N”,N”) –表情字符,其Unicode编码得三个字节表示
–查看结果
select *,
convert (varbinary (20) , varc) as varc_binary,
convert (varbinary (20) , varcutf) as varcutf_binary
from tUnicode;
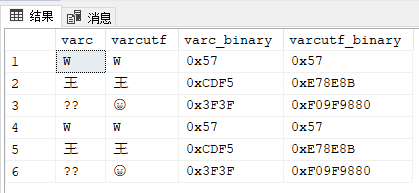
以此看出,varcutf列储存的是UTF-8,而varc列用的GBK储存不了要三个字节才能储存的表情字符。
- nchar和nvarchar类型
根据微软官方文档对char和varchar类型的描述:“字符数据类型 nchar(大小固定)或 nvarchar(大小可变)。 从 SQL Server 2012 (11.x) 起,使用启用了补充字符 (SC) 的排序规则时,这些数据类型会存储 Unicode 字符数据的整个范围,并使用 UTF-16 字符编码。 若指定了非 SC 排序规则,则这些数据类型仅会存储 UCS-2 字符编码支持的字符数据子集。”。文档说从2012版开始对nchar和nvarchar类型做了修改,我们用SQL SERVER 2022版测试一下:
create table tUnicode2( nvar nvarchar(10) , --默认的Chinese_PRC_CI_AS, nvarsc nvarchar(10) COLLATE Chinese_PRC_90_CI_AS_SC, nvar8 nvarchar(10) COLLATE Chinese_PRC_90_CI_AS_SC_UTF8, )
--插入六条记录,插入的nvar列用的是不带N的字符字面量
insert into tUnicode2 values(‘W’,N’W’,N’W’)
insert into tUnicode2 values(‘王’,N’王’,N’王’)
insert into tUnicode2 values(”,N”,N”)
insert into tUnicode2 values(N’W’,N’W’,N’W’)
insert into tUnicode2 values(N’王’,N’王’,N’王’)
insert into tUnicode2 values(N”,N”,N”)
select *,
convert (varbinary (20) , nvar) as nvar_binary,
convert (varbinary (20) , nvarsc) as nvarsc_binary,
convert (varbinary (20) , nvar8) as nvar8_binary
from tUnicode2;
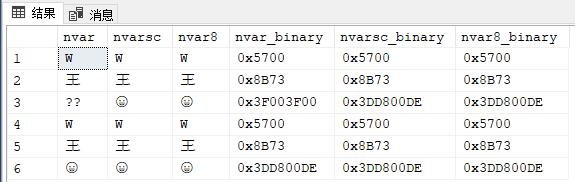
看到王字都是显示UTF-16编码,可以确定,不管用非SC(增补字符)还是用SC甚至UTF-8排序规则,其都是储存UTF-16编码。
- 结论及应用
对于char和varchar类型,若排序规则带UTF8则储存的字符是UTF-8,否则就是ANSI(在我的本机是GBK)。而nchar和nvarchar类型,不管什么排序规则一律是UTF-16。在实际应用中,若要用Unicode编码,建议用nchar和nvarchar类型,不宜用UTF-8的char和varchar类型,因为不方便从数据表定义中查看哪些char和varchar类型的列是UTF-8的,默认的排序规则和设定带UTF8的排序规则在运算时会出现不兼容的错误提示。测试如下:
use TestDB GO create table tUnicode3( varc varchar(10), --默认的Chinese_PRC_CI_AS, varsc varchar(10) collate Chinese_PRC_90_CI_AS_SC, varcutf varchar(10) COLLATE Chinese_PRC_90_CI_AS_SC_UTF8 --指定带UTF8的排序规则 ) GO insert into tUnicode3 values('W','W',N'W') --英文字母 insert into tUnicode3 values('王','王',N'王') --汉字
select *,
convert (varbinary (20) , varc) as varc_binary,
convert (varbinary (20) , varsc) as varsc_binary,
convert (varbinary (20) , varcutf) as varcutf_binary
from tUnicode3;

select * from tUnicode3 where varsc = varc;

select * from tUnicode3 where varsc = varcutf;

这时就不得不用显式转换排序规则:
select * from tUnicode3 where varsc collate Chinese_PRC_90_CI_AS_SC_UTF8 = varcutf and varsc collate Chinese_PRC_CI_AS= varc;
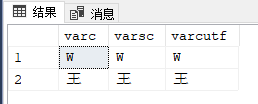
且这种转换会有消耗,查看其执行计划,可以看到使用Convert函数转换:
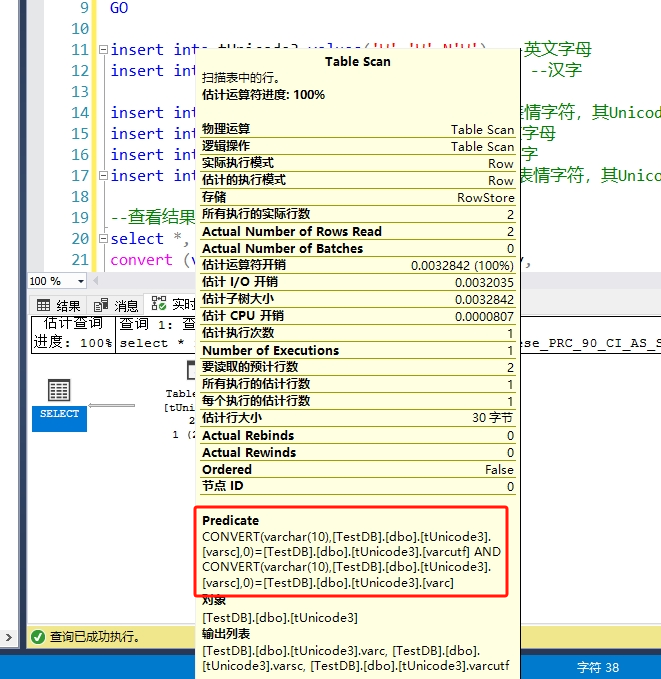
另外,char和varchar类型的ANSI和nchar和nvarchar类型的UTF-16是可以隐式转换的,转换不了就会乱码但不会出错。而UTF-8和UTF-16是完全兼容的,但用这两种编码的字符进行运算时会发生隐式转换。本人以前参与过一个仓储系统的维护,其货品条码主表的条码列用GBK的varchar类型,而引用此列的一些表却用nvarchar类型。虽说条码都是由ASCII码组成,完全兼容GBK和UTF-16,但两种编码的列在关联时会发生隐式转换,会有消耗,而这些SQL执行都很频繁,对系统很有影响。
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。









![[20230903]完善hide.sql脚本2.txt-牛翰网](https://niuimg.niucores.com/wp-content/uploads/2024/08/20240828182449967.jpg)




暂无评论内容