


有时候,我们某个数据表中,可能有几列的数据都是一样的,此时我们可能想查询出这几列数据相同的所有数据行,并保留最新一条,将其他重复的数据删除。
🥇1、ROW_NUMBER函数
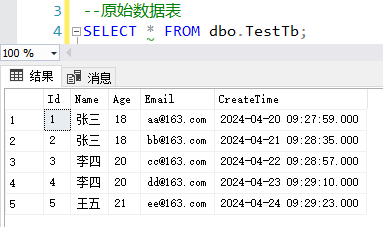
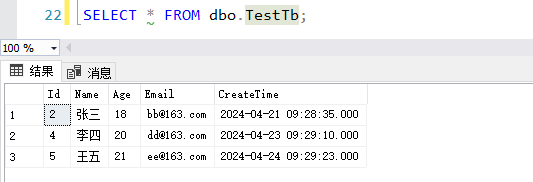
假设我们有如下数据表:
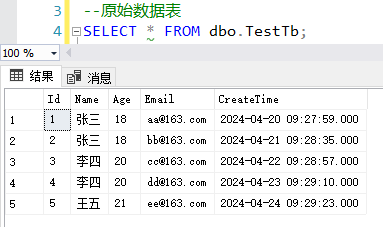
此时我们可以使用ROW_NUMBER函数,根据某几列查询出重复数据的新的排序列,该排序列就是根据某几列重复数据生成的序号(从1开始),如下所示OrderNo就是我们新生成的列:
--根据Name和Age这2个字段进行查询并获得新的列OrderNo(OrderNo就是根据Name和Age重复数据生成的序号,从1开始),同时按照CreateTime降序排列
SELECT *,OrderNo=ROW_NUMBER() OVER(PARTITION BY [Name],Age ORDER BY CreateTime DESC)
FROM dbo.TestTb
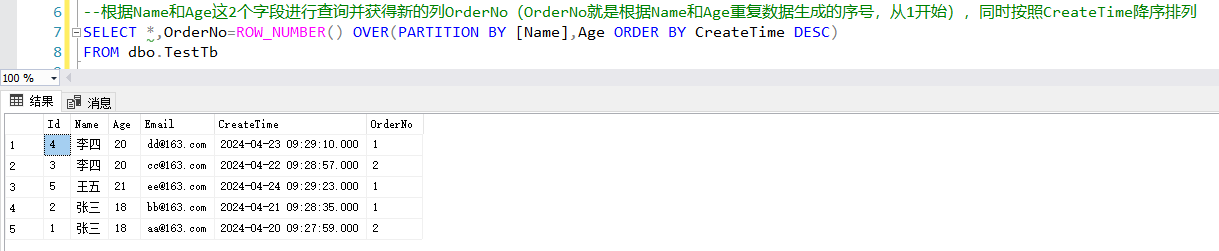
🥈2、删除数据
有了上述代码中的排序列,我们就可以知道,OrderNo的值>1的数据行都是我们需要删除的数据,完整代码如下所示:
--删除表TestTb中字段Name和Age同时重复的数据,并保留最新一条
DELETE FROM dbo.TestTb WHERE Id IN(
--根据Name和Age这2个字段查询出重复的数据
SELECT Id FROM
(
--根据Name和Age这2个字段进行查询并获得新的列OrderNo(OrderNo就是根据Name和Age重复数据生成的序号,从1开始),同时按照CreateTime降序排列
SELECT *,OrderNo=ROW_NUMBER() OVER(PARTITION BY [Name],Age ORDER BY CreateTime DESC)
FROM dbo.TestTb
) Tmp
WHERE OrderNo>1
);
执行删除:
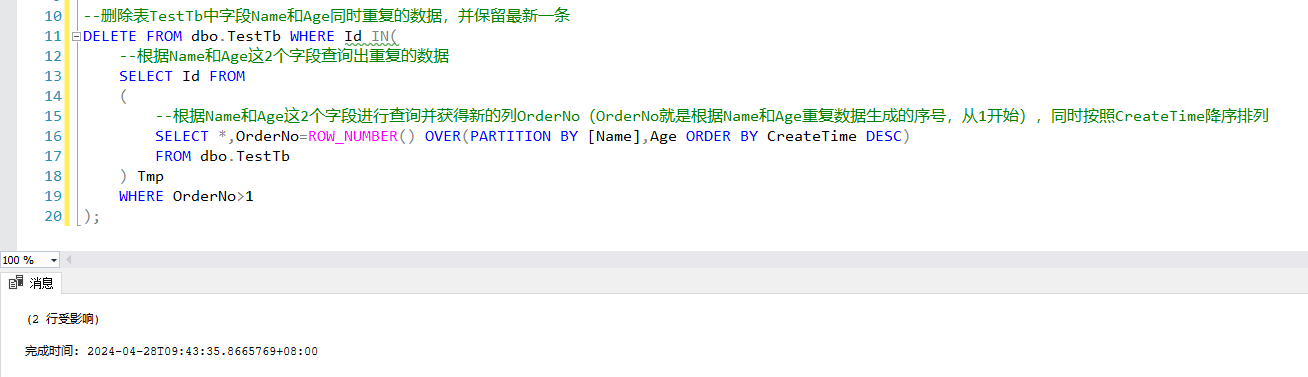
删除后的:
© 版权声明
本站所有资源来自于网络,仅供学习与参考,请勿用于商业用途,否则产生的一切后果将由您(转载者)自己承担!
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。
THE END








![[20230903]完善hide.sql脚本2.txt-牛翰网](https://niuimg.niucores.com/wp-content/uploads/2024/08/20240828182446917.jpg)





暂无评论内容