


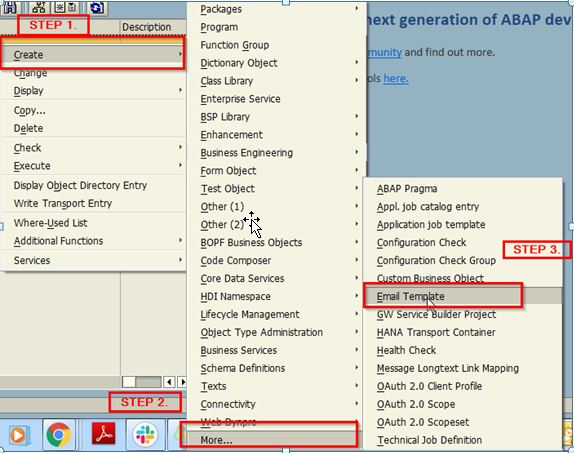
代码基本知识点
代码基本块
严格的来说,基本块是满足下列条件的一组连续指令代码,程序的执行(控制流)只能从基本块的第一条语句(入口语句)进入,从基本块的最后一条语句离开。
int a,b;
a = getchar();
b = getchar();
if (a>b){
a = a*b;
print(a);
}
else {
a = a/b;
print(a);
}
### if/else
代码56行与910行两个代码块有不同的进入条件,下一个执行代码块的选择取决于第4行的判断条件
int a,b;
a = getchar();
b = getchar();
while (a>b){
a = a*b;
print(a);
}
# while
第4行代码while语句包含第5行代码,该行代码与其他行代码分开,执行条件是第4行的判断语句
int a,b,c;
a = getchar();
b = getchar();
for (;a,b;a++){
c = a+b;
}
print(c);
### for
第4行代码for语句包含第5行代码,该行代码与其他行代码分开,执行条件是第4行的判断语句
控制流图CFG
当程序被划分为基本块后,如果将基本块视为一个基本单元节点,基本块之间在程序执行流程上互为前驱和后继的关系可以视为两个基本块村子一条边,则整个程序可以转换为一个有向图,称为控制流图(Control Flow Graph)
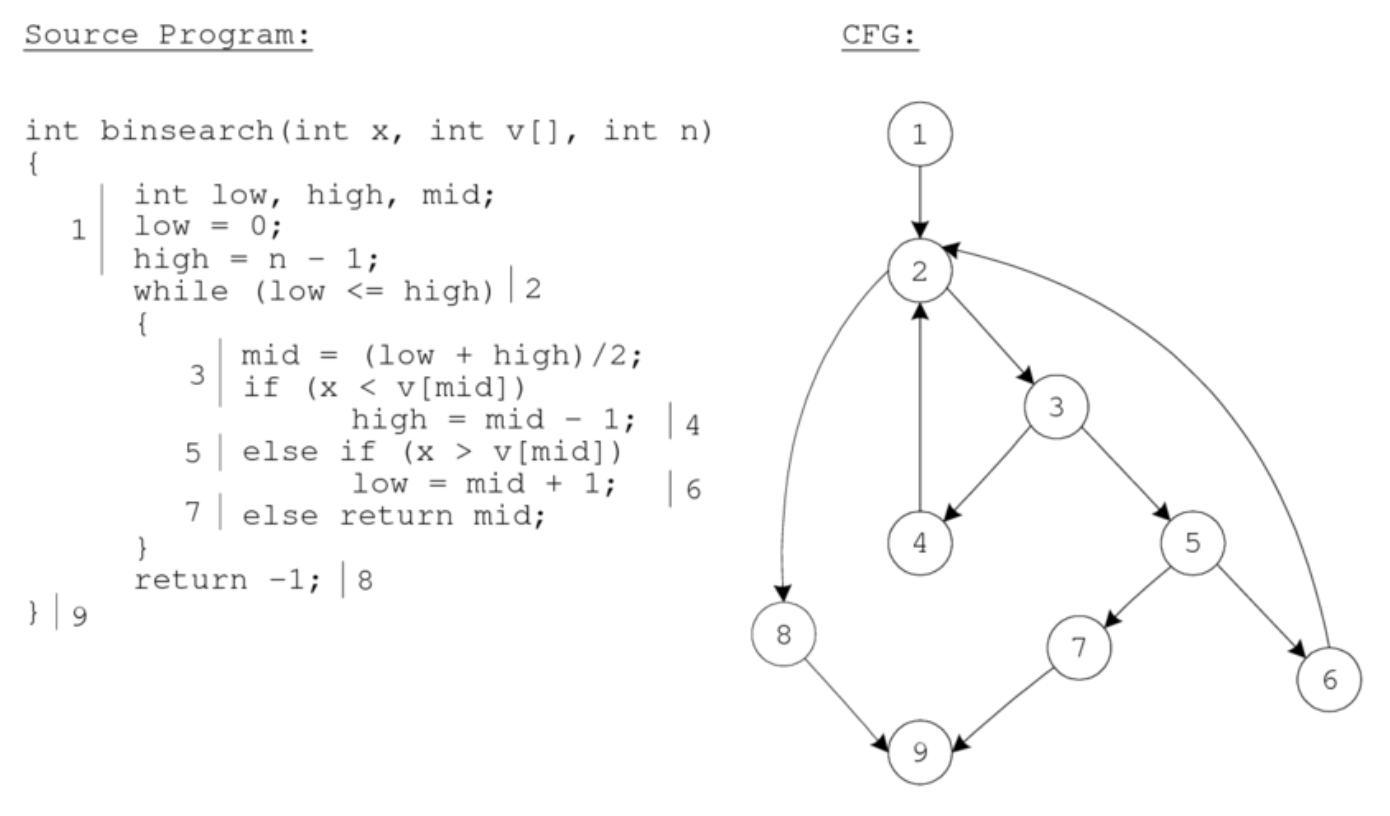
int max(int x, int y){
int tmp = 0; -----0
if (x>y){ -----0
tmp =x; -----1
}
else{
tmp = y; -----2
}
return tmp; -----3
}

节点0是节点1和2的严格直接前必经节点,而节点3是节点1和2的严格直接后必经节点。
根据基本块构造的有向图G可以表示为四元组G = {V, E, Entry, Exit},其中
V是基本块节点的集合
E是基本块之间边的集合
Entry表示入口基本块节点
Exit表示结束基本块节点
程序执行时,从Entry代表的基本块开始执行,沿着控制边遍历执行基本块,最后到Exit代表的基本块时执行结束。
数据流分析
到达与可到达
针对变量x的一个定义语句s,称该语句对变量x的定义到达程序的某个代码位置P,当且仅当在程序控制流图(CFG)中存在从该定义对应的语句到位置P语句的一条路径,并且该路径上没有变量x的其他定义。
称语句s是代码位置P的一个可到达定义。
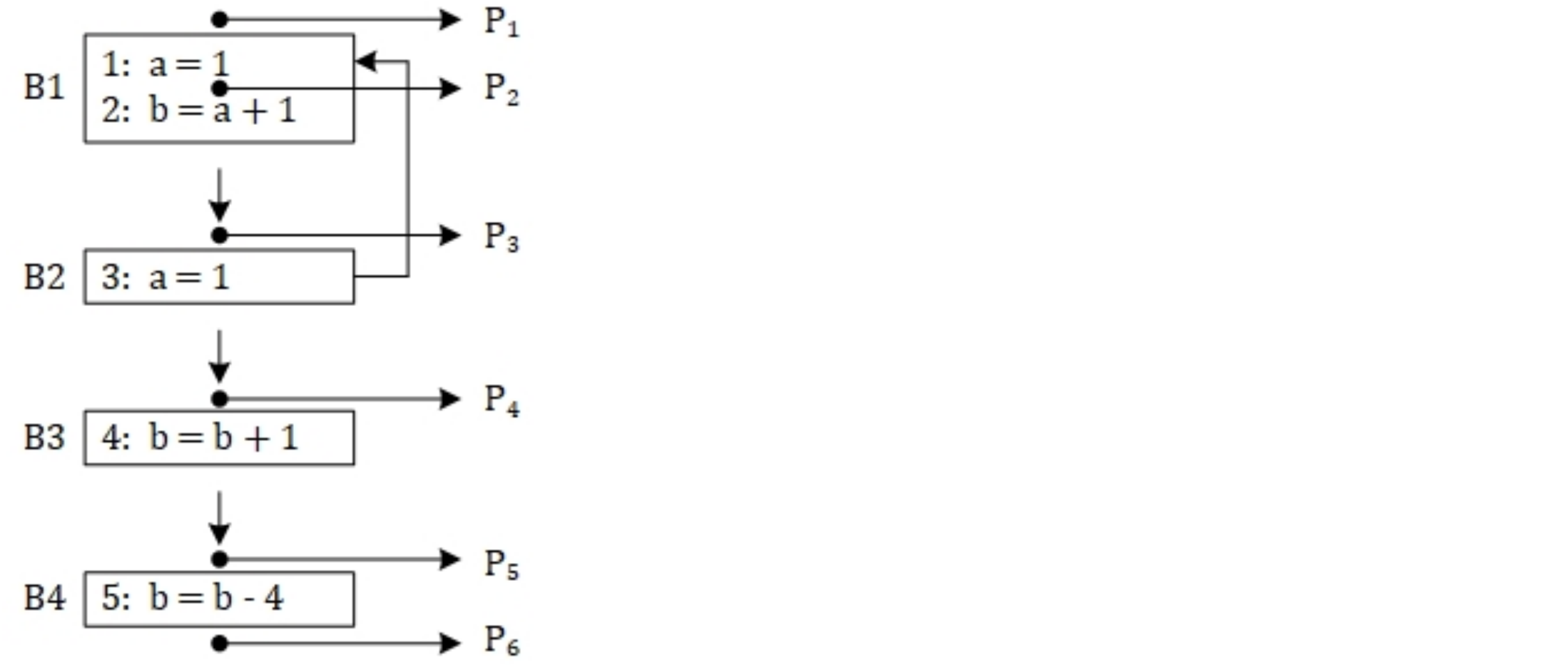
第2条语句对变量b赋值,在该语句执行后变量b的值被算术表达式a+1的值所替代。
另外,每条语句前后都有对应的代码位置标识,分别为P1, P2, P3, P4, P5, P6,程序执行时可能的路径为<P1, P2, P3, P4, P5, P6>或者<P1, P2, P3, P4, P1, P2, P3, P4, P5, P6>。
第二条语句对变量b赋值,在该语句执行后变量b的值被算术表达式a+1的值所替代。
语句3对变量a进行定义,且语句4和5均未对变量a进行定义,那么,语句3就是代码位置P4、P5和P6的一个可到达定义
简单一点来说,一个赋值语句a在他的赋值被更改前运行的所有语句的有一个可到达定义a。
变量定义和引用概念
| 定义 | 概念 |
|---|---|
| Def(x) | 假定某个变量为x,则x有定义集Def(x),表示定义x的所有语句的集合,该集合包含任何使x的值发生变化的语句(例如,简单的或者经过运算后的赋值语句等)。 |
| Use(x) | Use(x)表示变量x的引用集,即,任何使用x的语句的集合。分别将基本块内所有变量的定义集和引用集做并集,即可得到对应基本块的定义集和引用集 |
| Gen(s) | 产生集Gen(s) 表示所有由s给出的变量定义所在的语句构成的集合。 假定某条语句用s表示,s包含的变量定义和引用可以引入 |
| Kill(s) | 杀死集Kill(s) 若s重新定义变量x,而x此前由语句s’定义,则称s消灭定义s’。 所有由s消灭的定义的集合称为s的消灭集。 |
| In(s) | 表示所有在语句s之前仍然有效(没有被消灭)的定义语句的集合。 |
| Out(s) | 表示所有离开语句s的定义语句的集合,添加s产生的语句,同时去掉语句s所消灭的定义语句。 |
程序切片
程序切片通常包括3个步骤
1、程序依赖关系提取
主要是从程序中提取各类信息,包括控制流和数据流信息,形成程序依赖图。
2、切片规则制定
主要是依据具体的程序分析需求设计切片准则。
3、切片生成
主要是依据切片准则选择相应的程序切片方法,然后对提取的依赖关系进行分析处理,从而生成程序切片。
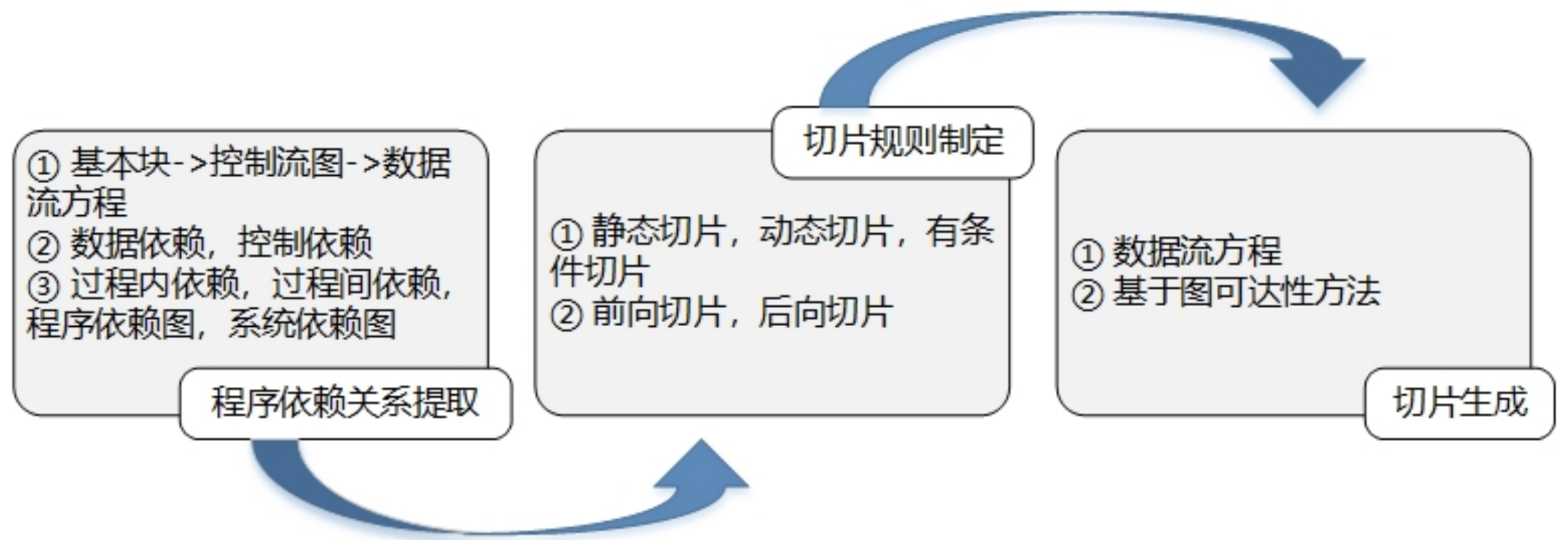
程序切片的分类
按照是否在切片中考虑程序的具体输入,可以划分为静态切片和动态切片。
按照切片要提取的是对关注变量有影响的代码片段还是被关注变量所影响,可以划分为前向切片和后向切片。
按照提取的切片是否为可执行程序,可以划分为可执行的切片和不可执行的切片等。
静态切片
目前,静态程序切片主要有两种方法
基于数据流方程的切片方法
基于程序依赖图可达性的切片方法
静态程序切片方法均是利用数据依赖和控制依赖关系进行分析以获得程序切片。
静态程序切片方法
基于数据流方程的切片方法
基于图可达性算法的切片方法
基于数据流方程进行切片的方法主要是通过迭代计算控制流图中每个节点的相关变量集合,迭代分析语句间的数据依赖关系和控制依赖关系,最终获得每条语句中与切片准则相关的变量的集合。
基于图可达性算法的切片方法
基于图可达性进行切片的方法与图遍历方法基本相同。
首先需要计算出目标程序的控制依赖和数据依赖关系,构建程序依赖图。
然后从切片准则所对应的节点出发,沿着数据依赖边和控制依赖边进行图遍历,所有遍历可达的节点均加入到切片中
这边其实最重要的一步是画出程序依赖图,这是静态切片的关键:
int main(){
int x=0, y, z;
int i = 0;
z = 0;
y = getchar();
for(;i<100;i++)
if(i%2 == 1)
x += y*i;
else
z += 1;
print(x);
print(z);
}

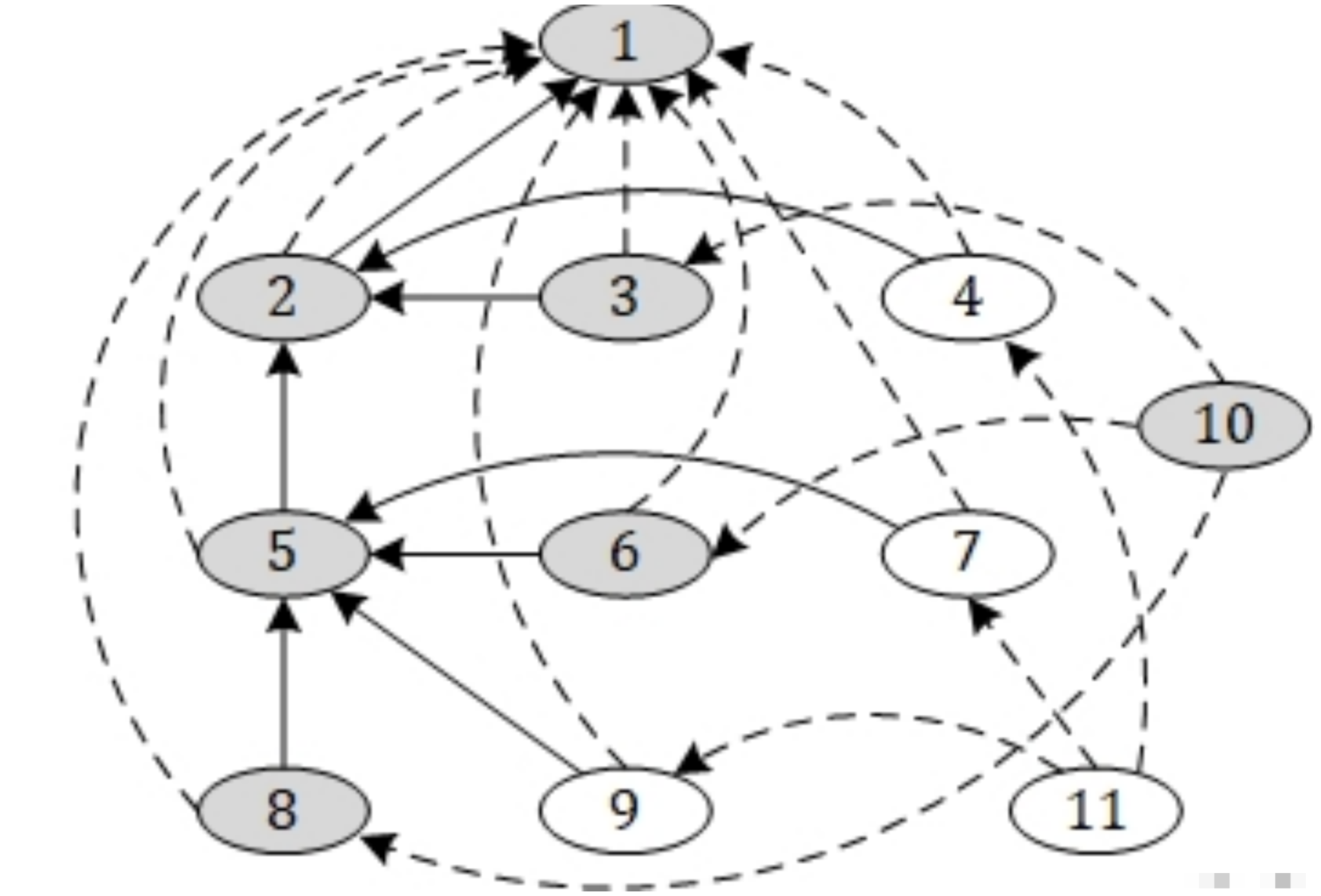
切片举例:
基于依赖图的静态切片示例
针对切片准则<12, {z}>,切片计算从节点print(z);开始进行图遍历。
其中,以灰色填充的节点是遍历得到的节点,节点旁边的圆圈内的数字表示按照深度优先遍历的顺序。
最后得到的针对切片准则的后向切片为{3, 4, 6, 7, 10, 12}。

动态切片
动态切片是一种仅关注在给定某个输入条件下对程序中某点的变量有影响的语句。
动态切片与静态切片的最大差异在于是否考虑了程序输入。
当考虑程序输入时,程序中的某些路径将不可达,从而能够确定程序依赖图的部分节点与切片准则不相关,可以从原始程序依赖图中删除这些节点以缩小图的规模。
与静态切片相比,通常动态切片给出的结果更有针对性,切片规模更小而且精确。
代码片段及其程序依赖图示例
采用静态切片方法中的基于图可达性的切片方法计算其切片,只需要从切片准则对应的节点开始遍历程序依赖图,并提取所有可到达的节点对应的语句
代码片段针对<10, {y}>的静态切片示例
针对切片准则<10, {y}>,静态切片包括节点1、2、3、5、6、8和10。
切片中节点3、6和8是给y赋值的语句,均数据依赖于节点1,分别控制依赖于节点2和5,而节点2和5均数据依赖于节点1,因此,节点1中x的取值至关重要。
假设给定节点1中的x值为1,则节点1、2、5、8可达,而节点3、6不可达,在遍历程序依赖图以获取程序切片时可以忽略节点3和6,最终遍历裁剪后的程序依赖图获得的程序切片为{1, 2, 5, 8, 10}。
动态程序切片方法
基于程序依赖图的动态切片方法
基于动态依赖图的动态切片方法
基于程序依赖图的动态切片方法
基于程序依赖图的动态切片方法是通过裁剪程序依赖图来获得动态切片。
动态切片除了要考虑切片准则以外,还要考虑程序的具体输入。
当程序中某个未指定具体值的变量被赋予某个特定值时,程序运行能够得到一条由执行指令构成的动态执行路径,该执行路径称为执行历史。
执行历史示例
若给N指定一个具体值2,程序动态运行形成的执行历史可以表示为节点编号的序列:<1, 2, 3, 4, 51, 61, 71, 81, 52, 62, 72, 82, 53, 9>。
其中,节点编号有上标表示该节点在执行历史中不止一次出现,上标是其出现次数的递增编号,例如53表示当前是第3次执行语句5。
N = getchar();
z = 0;
y = 0;
i = 1;
while(i<=N){
z = f1(z,y);
y = f2(y);
i++;
}
print(z);

但上述动态切片方法存在的不足:产生的切片不够精确。
任何一个节点(语句)可能依赖于多个其他节点,这些依赖关系需要通过执行历史中的多条执行路径来体现,因此,执行历史中的执行路径虽然无法覆盖该节点与依赖节点之间的全部执行路径,但只要某个节点在执行历史中,则该节点关联的所有边对于图遍历都是有效边,仍然能够通过遍历执行历史没有覆盖的路径,把不相关节点也加入到切片中,导致最终获得的切片过大。
动态依赖图(DDG)
程序依赖图是一种静态表示,无法体现同一语句(节点)的不同次执行的区别。
动态依赖图(Dynamic Dependence Graph, DDG),不但能够表示静态程序依赖关系,同时也能表示程序的动态执行过程。
DDG的构造方法
遍历执行历史,依次为其中每个语句(节点)的每一次出现均创建一个新的节点;
同时,节点之间仅在因为程序执行而导致有实质的控制和依赖关系时才建立一条依赖边。
N = getchar();
i = 1;
while(i <= N){
x = getchar();
if (x<0)
y = f1(x);
else
y = f2(x);
z = f3(y);
print(z);
i++;
}

当N=3,x依次取-4、3和-2时,执行历史为<1, 2, 31, 41, 51, 61, 81, 91, 101, 32, 42, 52, 71, 82, 92, 102, 33, 43, 53, 62, 83, 93, 103, 34>。
在动态依赖图中,3行节点对应于循环的3次执行,重复编号代表该节点所在语句的多次执行。
在前两次循环中,节点8依赖的节点不同
第一次循环时节点8引用的变量y是通过节点6的赋值语句定义的;
第二次循环时是通过节点7的赋值语句定义的。
基于DDG的动态切片计算比较简单,仅需要从切片准则对应的节点开始遍历动态依赖图,将所有可达到的节点都添加到切片中。
例如,针对上述代码片段,当N值为3,x值为-4、3和-2的条件下,针对切片准则<9, {z}, I0>的动态切片为{1, 2, 3, 4, 5, 6, 8, 9, 10}。
切片准则包含两个要素
-
切片的目标变量
-
开始切片的代码位置 严格地说,程序P的切片准则是一个二元组<n, V>,其中n是程序中一条语句的编号,V是切片所关注的变量集合,该集合是P中变量的一个子集。
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。












暂无评论内容