


java统计单词频率
继上一讲Java用PDFTextStripper来解析pdf文件提取文字 – ivanlee717 – 博客园讲了如何接收和解析pdf之后,我们把pdf文件全部转为了String类型的字符串,那么这一讲聊聊怎么去统计每个词出现的频率。
正则过滤
首先我们需要把单词弄出来,把其他的文字过滤掉。
Pattern pattern = Pattern.compile("\\b[a-z]+\\b");
Matcher matcher = pattern.matcher(s.toLowerCase());
\\b 是一个元字符(metacharacter),表示单词边界。它匹配的是位置,而不是具体的字符。它确保匹配的单词前后是单词边界,即单词的开头或结尾,或者与非单词字符相邻。例如,在字符串 “hello regina” 中,\b 会匹配 h 之前、o 之后、r 之前和 a 之后的位置。
具体来说,\\b 匹配以下几种情况:
- 字符串的开头或结尾。
- 一个单词字符(字母、数字、下划线)紧接在非单词字符(如空格、标点符号等)之后,或反之亦然。
[a-z] 是一个字符类,表示匹配任意一个小写字母(从 a 到 z)。
- [A-Za-z]:匹配任意大小写字母。
- [0-9]:匹配任意数字。
- [a-zA-Z0-9_]:匹配任意字母、数字或下划线(相当于 \w)。
- [aeiou]:匹配任意元音字母。
+是一个量词,表示前面的元素必须出现一次或多次。
量词可以应用于单个字符、字符类或更复杂的表达式。常见的量词包括:
-
*:匹配零次或多次。 -
+:匹配一次或多次。 -
?:匹配零次或一次。 -
{n}:精确匹配 n 次。 -
{n,}:匹配至少 n 次。 -
{n,m}:匹配至少 n 次,最多 m 次。
第二个\\b仍然表示单词边界,但它出现在模式的末尾,确保匹配的单词以单词边界结束。
在设置好匹配规则以后,就要去进行匹配了。matcher(CharSequence input):这是 Pattern 类的一个实例方法,用于创建一个 Matcher 对象。Matcher 对象可以在给定的输入字符串(input)中查找与正则表达式模式匹配的子串。
find():尝试找到下一个与模式匹配的子串。如果找到匹配项,则返回 true,并将匹配位置更新到下一个匹配项的起始位置
group():返回当前匹配的子串。只有在调用 find() 或 matches() 成功后,才能调用 group()。
start() 和 end():分别返回当前匹配项的起始和结束索引。
replaceAll(String replacement) 和 replaceFirst(String replacement):用于替换所有或第一个匹配项。
reset():重置 Matcher,使其从头开始匹配新的输入字符串。
然后我们用一个哈希表来存储每个单词的出现频率。
HashMap<String, Integer> wordCount = new HashMap<>();
while (matcher.find()) {
String word = matcher.group();
if (word.length() > 5) {
wordCount.put(word, wordCount.getOrDefault(word, 0) + 1);
}
}
我们一次来解析查到的每一个步骤。首先如果一直有单词出现,那么match.find()就会一直为true,然后始终在遍历循环。


每一次遍历成功之后都会把单词组在一起返回一个String,循环往复我们就可以把所有单词都遍历一次。
HashMap
getOrDefault(K key, V defaultValue):这是 Map 接口的一个方法,用于获取指定键(key)对应的值。如果该键不存在,则返回提供的默认值(defaultValue)。代码里面我们先查找这个ielts的单词,发现并没有存储,于是设置成0 。
put(K key, V value):这是 Map 接口的一个方法,用于将指定的键值对插入到 Map 中。如果该键已经存在,则更新其对应的值。

运行put方法之后,
while循环结束之后,就形成了一个统计表,然后我们对统计表按照次数排个序。
wordCount.entrySet().stream(): entrySet()是 Map 接口的一个方法,返回一个包含所有键值对的 Set<Map.Entry<String, Integer>>。每个 Map.Entry 对象代表一个键值对。stream()是 Collection 接口的一个方法,用于将集合转换为一个流(Stream)。流是数据的序列化容器,支持各种中间操作和终端操作,可以进行链式调用,从而实现高效的批量数据处理。
filter(Predicate<? super T> predicate):这是 Stream 接口的一个中间操作,用于筛选流中的元素。它接受一个 Predicate 函数式接口作为参数,该接口定义了一个布尔表达式,用于决定是否保留某个元素。entry -> entry.getValue() >= 10是一个 lambda 表达式,表示筛选条件。entry 是当前处理的 Map.Entry<String, Integer> 对象,entry.getValue() 返回该单词的出现次数。这个条件确保只有出现次数大于等于 10 的单词会被保留。
entry -> entry.getValue() >= 10 中的 -> 是 Java 8 引入的 lambda 表达式 的一部分。Lambda 表达式提供了一种简洁的方式来表示匿名函数(即没有名字的函数),通常用于实现函数式接口(即只有一个抽象方法的接口)。在你的例子中,-> 分隔了 lambda 表达式的参数列表和主体部分。
Lambda 表达式的基本语法如下:
(parameters) -> expression或(parameters) -> { statements; }
(parameters):参数列表,可以包含零个、一个或多个参数。如果只有一个参数且类型可以推断出来,括号可以省略。
->:箭头符号,分隔参数列表和表达式或语句块。
expression:单个表达式,其结果将作为 lambda 表达式的返回值。如果需要多条语句,则需要用大括号 {} 包围,并使用 return 语句显式返回值。
大概知道这种表达方式之后,那我们的排序的语法也就清楚了。
sorted(Comparator<? super T> comparator):这是 Stream 接口的一个中间操作,用于对流中的元素进行排序。它接受一个 Comparator 函数式接口作为参数,该接口定义了元素之间的比较规则。
(e1, e2) -> e2.getValue().compareTo(e1.getValue()):这也是一个 lambda 表达式,表示自定义的比较器。e1 和 e2 是两个 Map.Entry<String, Integer> 对象,e1.getValue() 和 e2.getValue() 分别返回它们的出现次数。compareTo 方法用于比较两个 Integer 值。这里的比较规则是按出现次数从高到低排序,因此我们使用 e2.getValue().compareTo(e1.getValue()),即先比较 e2 的值,再比较 e1 的值。
collect(Collector<? super T, A, R> collector):这是 Stream 接口的一个终端操作,用于将流中的元素收集到一个集合中。它接受一个 Collector 对象作为参数,定义了如何将流中的元素聚集在一起。
Collectors.toList():这是 Collectors 类的一个静态方法,返回一个 Collector,用于将流中的元素收集到一个 List 中。最终的结果是一个 List<Map.Entry<String, Integer>>,其中每个 Map.Entry 对象代表一个单词及其出现次数。
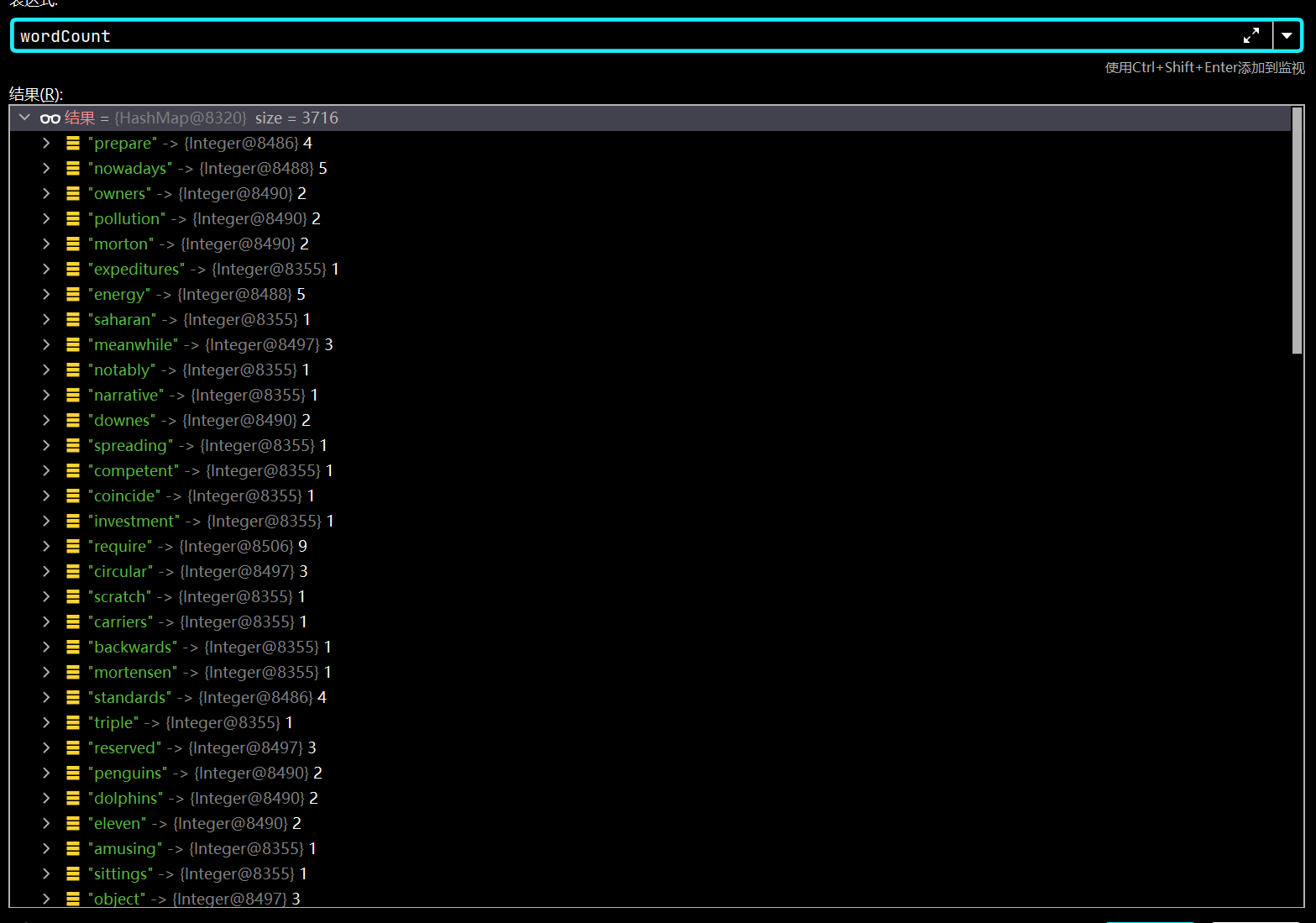
在遍历一遍之后我们可以得到一个这样的键值对现在我们编写排序代码。
List<Map.Entry<String, Integer>> sortedWords = wordCount.entrySet().stream()
.filter(entry -> entry.getValue() >= 10)
.sorted((e1, e2) -> e2.getValue().compareTo(e1.getValue()))
.collect(Collectors.toList());
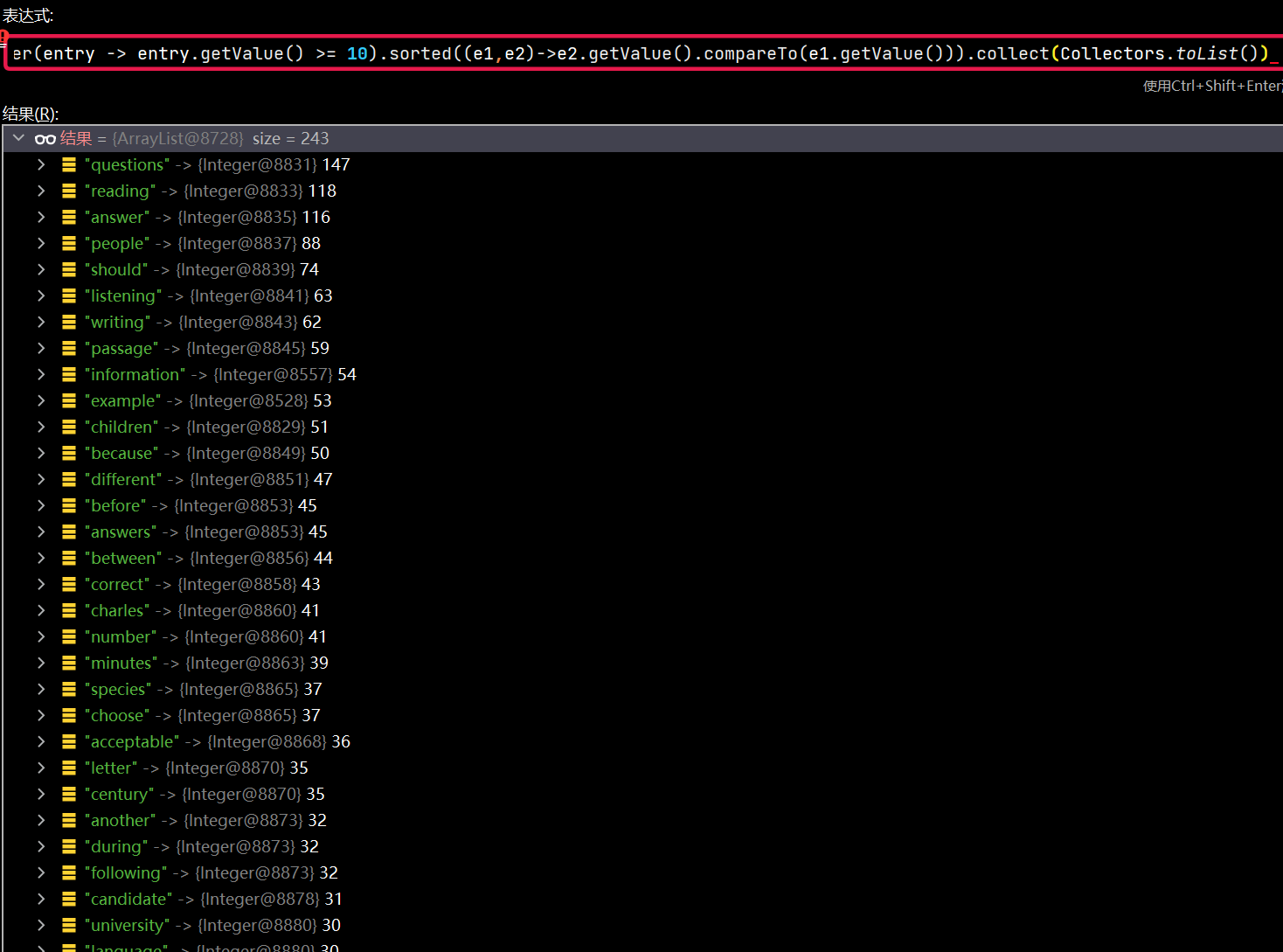
那List<Map.Entry<String, Integer>>这是一个什么类型的数据?
Map.Entry<String, Integer> 与 HashMap 有密切的关系,但它们并不是同一个东西。Map.Entry 是 Map 接口的一部分,而 HashMap 是 Map 接口的一个具体实现类。
- Map.Entry<K, V>
Map.Entry<K, V>:这是 Map 接口中的一个静态内部接口,表示 Map 中的一个键值对(key-value pair)。每个 Map.Entry 对象包含两个部分:
键 (K):类型为 K 的键。
值 (V):类型为 V 的值。
主要方法:
K getKey():返回该键值对的键。
V getValue():返回该键值对的值。
V setValue(V value):设置该键值对的值,并返回旧值。
用途:Map.Entry 通常用于遍历 Map 中的键值对。例如,entrySet() 方法返回一个包含所有键值对的 Set<Map.Entry<K, V>>,你可以通过迭代这个集合来访问每个键值对。- HashMap<K, V>
HashMap<K, V>:这是 Map 接口的一个具体实现类,提供了一种基于哈希表的数据结构,用于存储键值对。HashMap 允许你以键为索引快速查找、插入和删除键值对。
特点:
非线程安全:HashMap 不是线程安全的,如果多个线程同时访问并修改同一个 HashMap,可能会导致数据不一致的问题。如果你需要在多线程环境中使用类似的结构,可以考虑使用ConcurrentHashMap或Collections.synchronizedMap()。
允许一个 null 键和多个 null 值:HashMap 允许一个键为 null,并且可以有多个值为 null。
平均时间复杂度:在大多数情况下,HashMap 的查找、插入和删除操作的时间复杂度为 O(1),即常数时间复杂度。
for (Map.Entry<String, Integer> entry : words) {
String word = entry.getKey();
Function(word);
}
所以如果要遍历一个hashmap类型的东西,一般我们都会把他变成一种List<Map.Entry<String, Integer>>来循环获取,这样也比较方便去调用数据。
来源链接:https://www.cnblogs.com/ivanlee717/p/18616804
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。














暂无评论内容