


Java用本地字典数据库实现英语单词翻译
依赖的准备
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>ExtractWord</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>ExtractWord</name>
<description>ExtractWord</description>
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-boot.version>2.6.13</spring-boot.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<version>${spring-boot.version}</version> <!-- 统一版本 -->
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
持久层
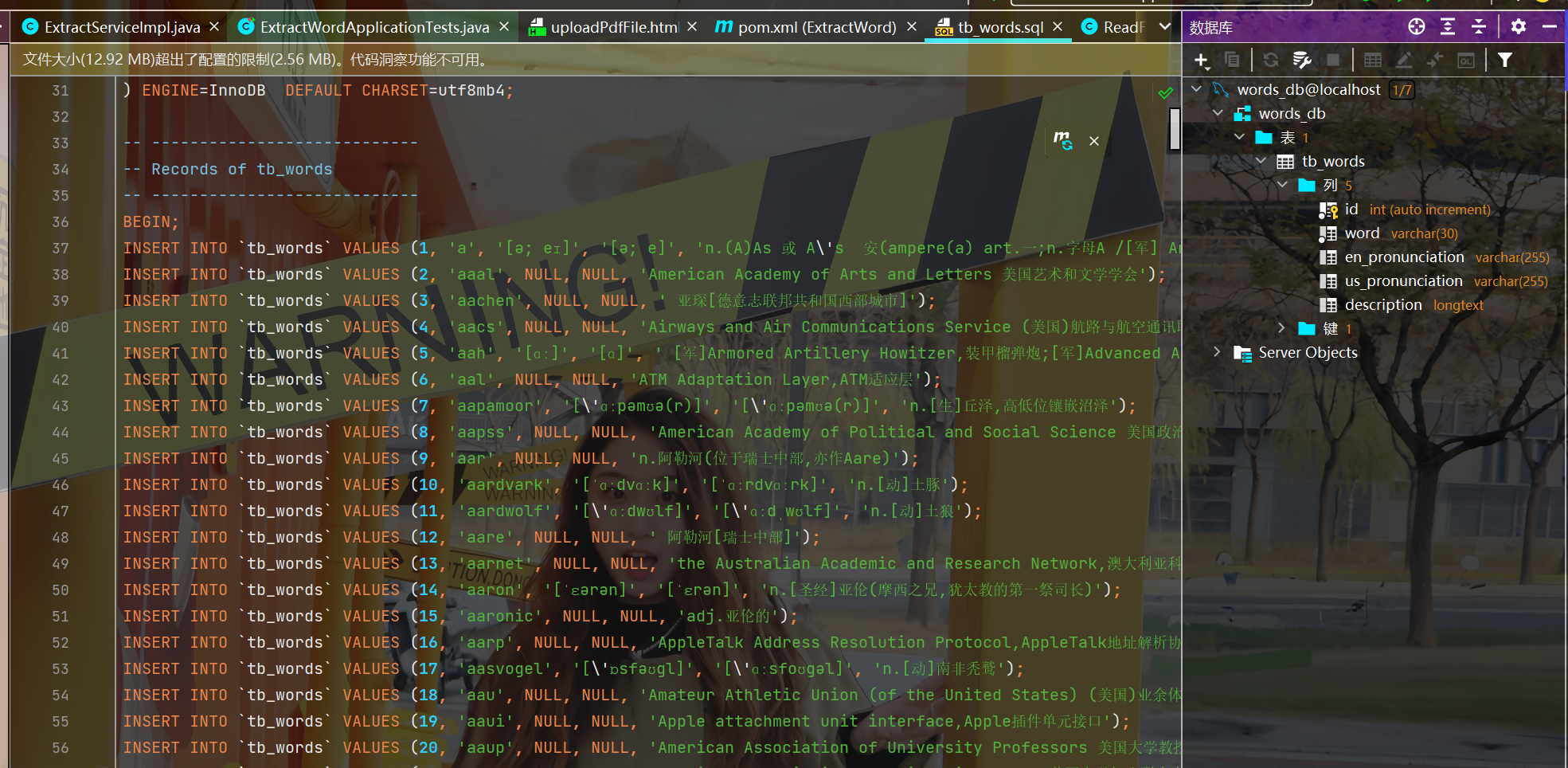
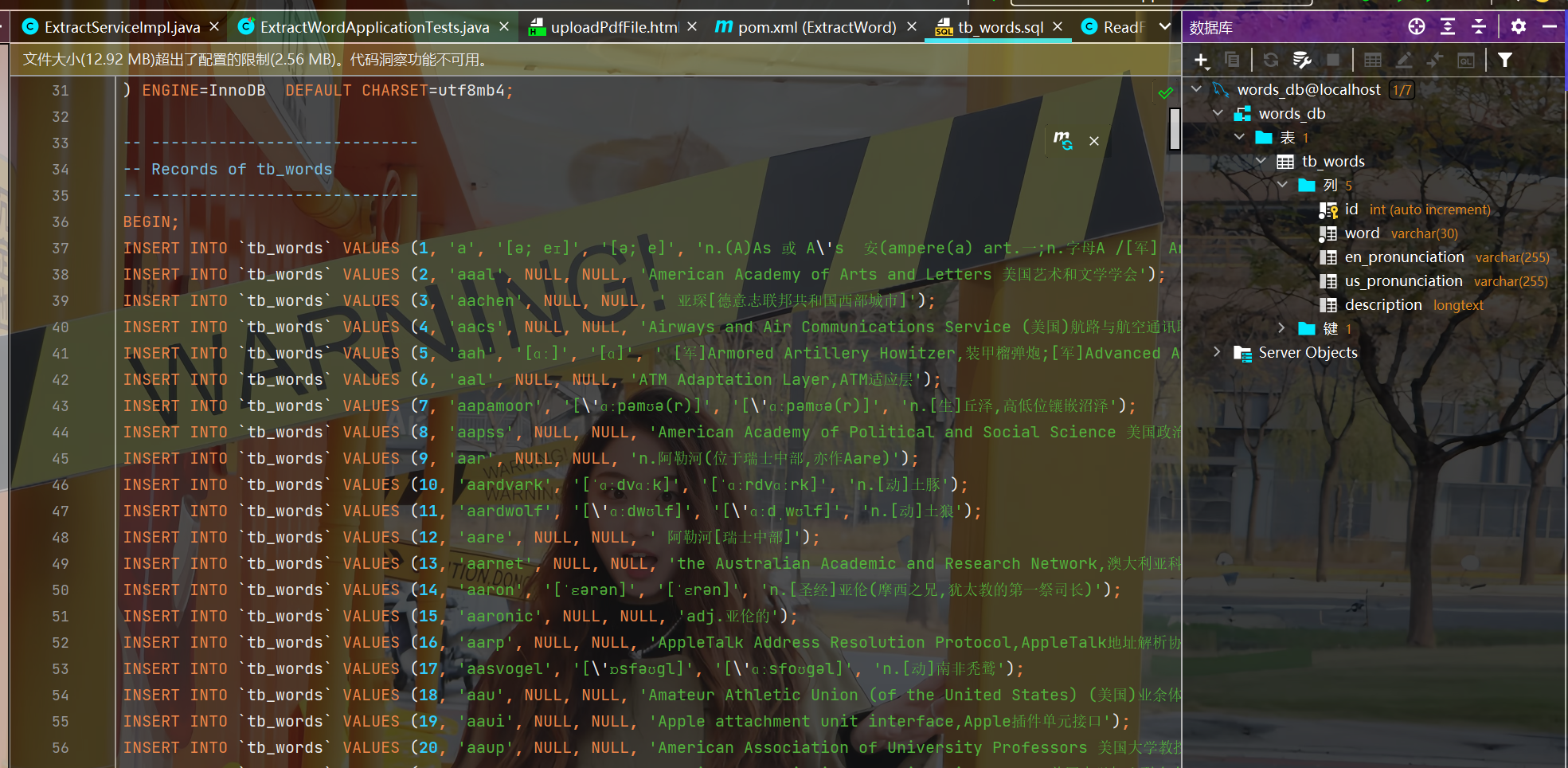
现在我们开始构建持久层数据库的部分。我们先从网上找了一个数据库文件,这个网上很好找的。
package com.example.extractword.entity.model;
import lombok.Data;
@Data
public class WordModel {
private String id;
private String word;
private String enPronunciation;
private String usPronunciation;
private String description;
}
把数据库建好之后的下一步就是要去编写对应的接口类了。
package com.example.extractword.mapper;
import com.example.extractword.entity.model.WordModel;
public interface WordMapper {
WordModel findByWord( String word);
Integer insert(WordModel wordModel);
}
我们目前就设置了两个方法,一个是插入,一个是查询。按理来说我们已经有了字典数据库了,还需要插入什么吗?不过有些时候在一些自动程序里,指不定不要查一些什么词,某个词的衍生词或者词性变换等可能字典里可就没有,那这时候就需要借助别的手段来获取信息然后插入进去。
现在开始写对应的mapper.xml文件。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace属性:用于指定当前的映射文件和哪个接口进行映射,需要指定
接口的文件路径,完整的路径接口-->
<mapper namespace="com.example.extractword.mapper.WordMapper">
<resultMap id="WordModelMap" type="com.example.extractword.entity.model.WordModel">
<id column="id" property="id"></id>
<result column="en_pronunciation" property="enPronunciation"></result>
<result column="us_pronunciation" property="usPronunciation"></result>
</resultMap>
<insert id="insert" useGeneratedKeys="true" keyProperty="id">
INSERT INTO tb_words(word,en_pronunciation,us_pronunciation,description) VALUES (#{word},#{enPronunciation},#{usPronunciation},#{description})
</insert>
<select id="findByWord" resultMap="WordModelMap">
SELECT * FROM tb_words WHERE word = #{word}
</select>
</mapper>
这个写法可以参照我的另一篇文章用一个项目把控制层、业务层、持久层说明白了,每一句话都讲的很清楚 – ivanlee717 – 博客园来对着写。
具体用到插入的时候我们再细讲。
然后在application.properties文件里设置好相关的数据库信息
#指定Mybatis的Mapper文件
mybatis.mapper-locations=classpath:mapper/*.xml
#指定Mybatis的实体目录
mybatis.type-aliases-package=com.example.extractword.entity.model
# 应用服务 WEB 访问端口
server.port=8081
spring.datasource.url=jdbc:mysql://localhost:3306/YOUR_DATABASE?useUnicode=true&characterEncoding=utf-8
spring.datasource.username=root
spring.datasource.password=*****
业务层
public String fetchDataFromDictionary(String word){
try {
WordModel wordModel = new WordModel();
wordModel = wordMapper.findByWord(word);
if (wordModel == null) {
wordModel = fetchWordFromNet(word);
}
DictionaryDto dictionaryDto = new DictionaryDto();
dictionaryDto.setWord(word);
dictionaryDto.setEnPronunciation(wordModel.getEnPronunciation());
dictionaryDto.setUsPronunciation(wordModel.getUsPronunciation());
dictionaryDto.setDescription(wordModel.getDescription());
// Check if pronunciation is available
if ((dictionaryDto.getEnPronunciation() == null || dictionaryDto.getEnPronunciation().isEmpty()) &&
(dictionaryDto.getUsPronunciation() == null || dictionaryDto.getUsPronunciation().isEmpty())) {
return "单词: " + word + ", 发音未找到, 翻译: " + dictionaryDto.getDescription();
}
return dictionaryDto.DToConvertToString();
} catch (Exception e) {
return "单词: " + word + ", 异常: " + e.getMessage();
}
}
主要的逻辑就在这个方法里面。不过这之前要设定好service接口和这个impl实现方法。这里我们引入了dto规范,因为字段比较少,所以他和数据库的内容是完全一样的,但是如果没有返回数据,则说明数据库里没有这个单词,我们就需要借助网络来翻译。这个方法我也已经在Java实现单词的翻译(详解爬虫操作) – ivanlee717 – 博客园这里面说清楚了
package com.example.extractword.entity.dto;
import lombok.Data;
@Data
public class DictionaryDto {
private String word;
private String enPronunciation;
private String usPronunciation;
private String description;
public String DToConvertToString(){
StringBuilder sb = new StringBuilder();
sb.append(word).append(": ");
if (enPronunciation != null && !enPronunciation.isEmpty()) {
sb.append("英式发音: ").append(enPronunciation).append(", ");
}
if (usPronunciation != null && !usPronunciation.isEmpty()) {
sb.append("美式发音: ").append(usPronunciation).append(", ");
}
sb.append("翻译: ").append(description);
return sb.toString();
}
}
这样的话我们就通过find方法找到了单词。
现在再说一下insert方法
WordModel wordModel = new WordModel();
wordModel.setWord(word);
wordModel.setEnPronunciation(En_phoneticElements.first().text().toString());
wordModel.setUsPronunciation(US_phoneticElements.first().text().toString());
for (Map<String, String> result : results) {
String pos = result.get("pos");
String translation = result.get("translation");
combinedResult.append(pos).append(translation).append(" ");
}
wordModel.setDescription(combinedResult.toString().replace("'", "''"));
Integer res = wordMapper.insert(wordModel);
我们把对应的爬取信息存到一个对象里面,按照字段依次插入进去就可以了。
来源链接:https://www.cnblogs.com/ivanlee717/p/18632289
© 版权声明
本站所有资源来自于网络,仅供学习与参考,请勿用于商业用途,否则产生的一切后果将由您(转载者)自己承担!
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。
THE END














暂无评论内容