


前言
先投放一波引流,公众号太久没更新了,以后保持更新,至少一周一更新。注意这个是旧版本,并不是流行的R1版本。
最近网上很多私有化部署deepseek的文章,但都是使用工具,对想理解怎么原生态部署、运行的朋友不是很友好,现在开始解析下怎么使用命令行部署deepseek,后续文章会持续更新。
对于私有化部署deepseek,有几个步骤:安装CUDA、安装python相关包、下载模型、运行模型。其中,如果不能安装CUDA就不要搞下去了,基本运行不起来。
检测及安装CUDA
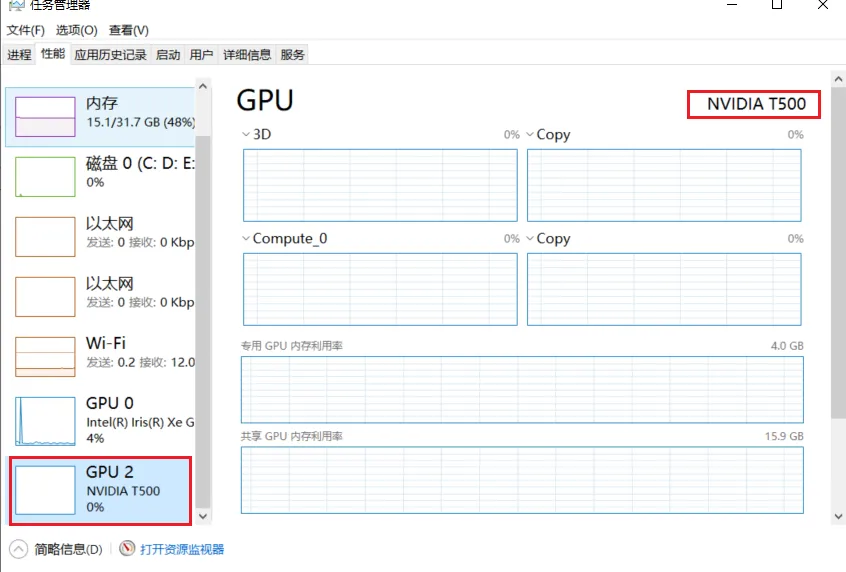
先看看本地有无nvidia的显卡,通过任务管理器查看,本机是有的了
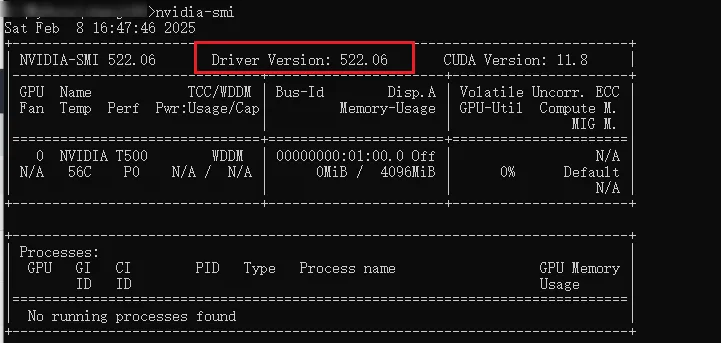
然后确定驱动是否安装或者版本是否够,可以使用 nvidia-smi 命令来查看是否安装了CUDA,如果安装了最好更新到最新版本。需要注意的是驱动与cuda的版本对应得上才能安装,下面讲解下详细步骤。
首先查看本地是否安装及驱动版本
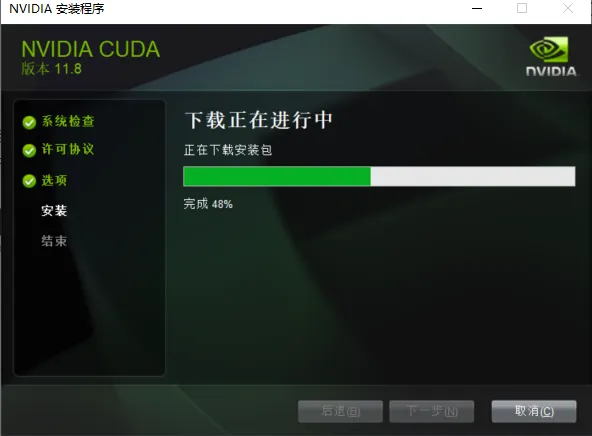
然后到CUDA官网上查看驱动的版本,来下载CUDA的版本
CUDA与驱动版本关系:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
下载对应的CUDA版本:https://developer.nvidia.com/cuda-toolkit-archive
![图片[1]-原生态方式部署及运行deepseek-7b-chat-牛翰网](https://niuimg.niucores.com/wp-content/uploads/2025/03/8689734942040460406.png)
下载安装即可,如本地正在安装CUDA 11.8版本
安装及部署deepseek-7b-chat
上面已经安装好cuda版本了,我们接下来的步骤是安装python、python相关依赖包、下载大模型、运行helloworld。
首先python版本需要3.8以上,python安装网上教程多这里省略。检查python脚本,本地安装时3.12.3接下来安装python所需依赖包

安装python依赖包
# 升级pip python -m pip install --upgrade pip # 更换 pypi 源加速库的安装 pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple pip install fastapi==0.104.1 pip install uvicorn==0.24.0.post1 pip install requests==2.25.1 pip install modelscope==1.9.5 pip install transformers==4.35.2 pip install streamlit==1.24.0 pip install sentencepiece==0.2.0 #如果失败执行 pip install sentencepiece==0.2.0 --only-binary :all: pip install accelerate==0.24.1 pip install transformers_stream_generator==0.0.4
一般没什么问题,主要是设置好加速源。成功后,下载大模型。
下载大模型
我们使用python的modelscope来下载大模型,文件比较大,要耐心等待
首先我们写下面的python代码,可用文本文件保存名字为:download.py
代码描述了通过modelscope工具包来下载大模型。
import torch from modelscope import snapshot_download, AutoModel, AutoTokenizer from modelscope import GenerationConfig model_dir = snapshot_download('deepseek-ai/deepseek-llm-7b-chat', cache_dir='D:/python/deepseek-7b-chat', revision='master')
这里讲解下背景,modelscope中文魔塔,里面有各种大模型、数据集下载,大家可以去看看,这个包也是魔塔写的,下载也是在魔塔网站上通过代码下载。
如果代码下载慢,可以在魔塔上搜索大模型来在浏览器上下载。代码保存后,执行python download.py命令,进行下载,有下载进度

以上进度可能一直卡住,可以在临时目录里面及时查看文件大小:

下载完成后的文件
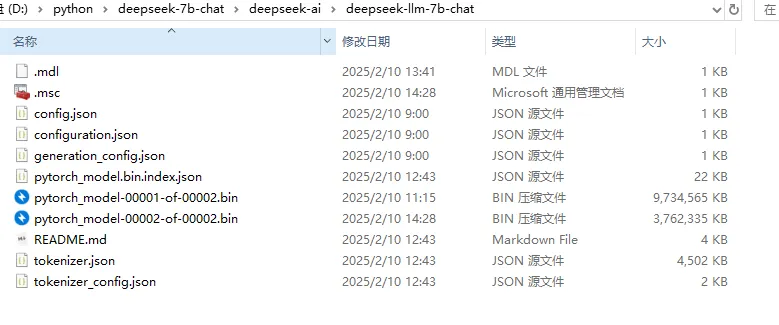
运行大模型
下载完成后,无需安装,直接运行
首先,运行大模型需要知道大模型通过什么来提供对外服务的。大模型对外都是通过python来提供,如果要深入可以了解python关于AI相关的开发包,python的确是这方面最完整的语言。
那么,了解后,我们来写python代码来接入大模型,如下
from fastapi import FastAPI, Request from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig import uvicorn import json import datetime import torch # 设置设备参数 DEVICE = "cuda" # 使用CUDA DEVICE_ID = "0" # CUDA设备ID,如果未设置则为空 CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE # 组合CUDA设备信息 # 清理GPU内存函数 def torch_gc(): if torch.cuda.is_available(): # 检查是否可用CUDA with torch.cuda.device(CUDA_DEVICE): # 指定CUDA设备 torch.cuda.empty_cache() # 清空CUDA缓存 torch.cuda.ipc_collect() # 收集CUDA内存碎片 # 创建FastAPI应用 app = FastAPI() # 处理POST请求的端点 @app.post("/") async def create_item(request: Request): global model, tokenizer # 声明全局变量以便在函数内部使用模型和分词器 json_post_raw = await request.json() # 获取POST请求的JSON数据 json_post = json.dumps(json_post_raw) # 将JSON数据转换为字符串 json_post_list = json.loads(json_post) # 将字符串转换为Python对象 prompt = json_post_list.get('prompt') # 获取请求中的提示 max_length = json_post_list.get('max_length', 1024) # 设置默认最大长度 # 构建 messages messages = [ {"role": "user", "content": prompt} ] # 构建输入 input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt") # 通过模型获得输出 outputs = model.generate(input_tensor.to(model.device), max_new_tokens=max_length) result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True) now = datetime.datetime.now() # 获取当前时间 time = now.strftime("%Y-%m-%d %H:%M:%S") # 格式化时间为字符串 # 构建响应JSON answer = { "response": result, "status": 200, "time": time } # 构建日志信息 log = "[" + time + "] " + '", prompt:"' + prompt + '", response:"' + repr(result) + '"' print(log) # 打印日志 torch_gc() # 执行GPU内存清理 return answer # 返回响应 # 主函数入口 if __name__ == '__main__': mode_name_or_path = 'D:/python/deepseek-7b-chat/deepseek-ai/deepseek-llm-7b-chat' # 加载预训练的分词器和模型 tokenizer = AutoTokenizer.from_pretrained(mode_name_or_path, trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained(mode_name_or_path, trust_remote_code=True,torch_dtype=torch.bfloat16, device_map="auto") model.generation_config = GenerationConfig.from_pretrained(mode_name_or_path) model.generation_config.pad_token_id = model.generation_config.eos_token_id model.generation_config.max_length = 1024 # 设置生成的最大长度 model.eval() # 设置模型为评估模式 # 启动FastAPI应用 # 用6006端口可以将autodl的端口映射到本地,从而在本地使用api uvicorn.run(app, host='0.0.0.0', port=9909, workers=1) # 在指定端口和主机上启动应用
代码不详细解释了,里面有详细的注释。代码实现了从外部命令行,通过读取输入文字来调用大模型API的方式,最后通过大模型输出结果。此段代码只实现了问答和部分上下文的功能,并无训练等。
启动api服务,运行py代码,python api.py
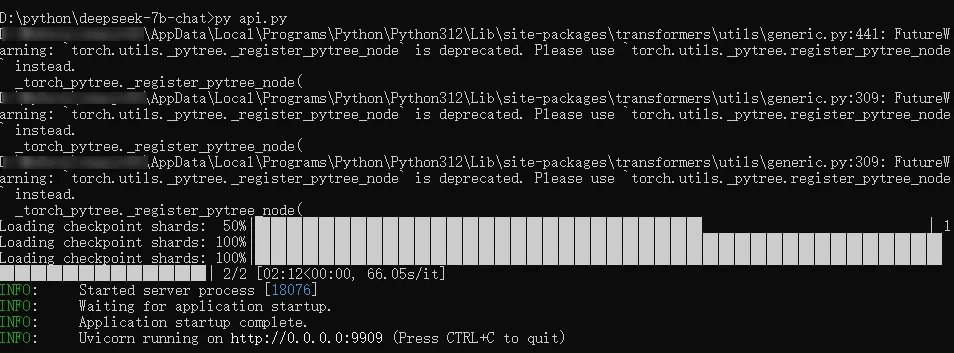
可以看到监听本地9909端口
使用apipost工具,请求成功

控制台数据也有日志打印

备注:以上python代码,为网上参考及AI生成,已经通过本人验证,放心使用。
最后,请关注本人公众号,持续更新相关内容

来源链接:https://www.cnblogs.com/alunchen/p/18752243
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。













暂无评论内容