

介绍
爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
本文将使用 Nodejs 编写一个简单的爬虫脚本,爬取一个美食网站,获取菜品的标题和图片链接,并以表格的形式输出。
准备工作
1、初始化项目
首先,确保已安装 Node,然后创建一个新的文件目录,运行以下命令初始化 Node.js 项目
npm init -y
2、安装依赖
使用 axios 库来进行 HTTP 请求
使用 cheerio 库来解析 HTML 内容
使用 node-xlsx 库来将数据写入 Excel 文件
npm install axios cheerio node-xlsx --save
代码实现
1、创建爬虫脚本
在项目根目录下创建一个 crawler.js 文件,并写入以下代码
import axios from "axios";
import cheerio from "cheerio";
// 目标网页的URL,这里使用 下厨房 这个美食网站作为测试
const targetUrl = "https://www.xiachufang.com/category/40076/";
// 请求目标网页,获取HTML内容
const getHtml = async () => {
const response = await axios.get(targetUrl);
if (response.status !== 200) {
throw new Error("请求失败");
}
return response.data;
};
// 解析HTML内容,获取菜品的标题和图片链接
const getData = async (html) => {
const $ = cheerio.load(html);
const list = [];
$(".normal-recipe-list li").each((i, elem) => {
const imgUrl = $(elem).find("img").attr("src");
const title = $(elem).find("p.name a").text();
list.push({
title: title.replace(/[\n\s]+/g, ""),
imgUrl,
});
});
return list;
};
2、以 Excel 表格形式保存数据
import xlsx from "node-xlsx";
import fs from "fs";
// 根据 表头数据 和 列表数据 转换成二维数组
const transData = (columns, tableList) => {
const data = columns.reduce(
(acc, cur) => {
acc.titles.push(cur.header);
acc.keys.push(cur.key);
return acc;
},
{ titles: [], keys: [] }
);
const tableBody = tableList.map((item) => {
return data.keys.map((key) => item[key]);
});
return [data.titles, ...tableBody];
};
const writeExcel = (list) => {
// 表头
const columns = [
{ header: "菜名", key: "title" },
{ header: "图片链接", key: "imgUrl" },
];
// 构建表格数据
const tableData = transData(columns, list);
const workbook = xlsx.build([
{
name: "菜谱",
data: tableData,
},
]);
// 写入文件
fs.writeFileSync("./菜谱.xlsx", workbook, "binary");
};
3、执行
(async () => {
const html = await getHtml();
const list = await getData(html);
await writeExcel(list);
console.log("执行完毕");
})();
运行爬虫
在终端中运行以下命令来执行爬虫代码
node crawler.js
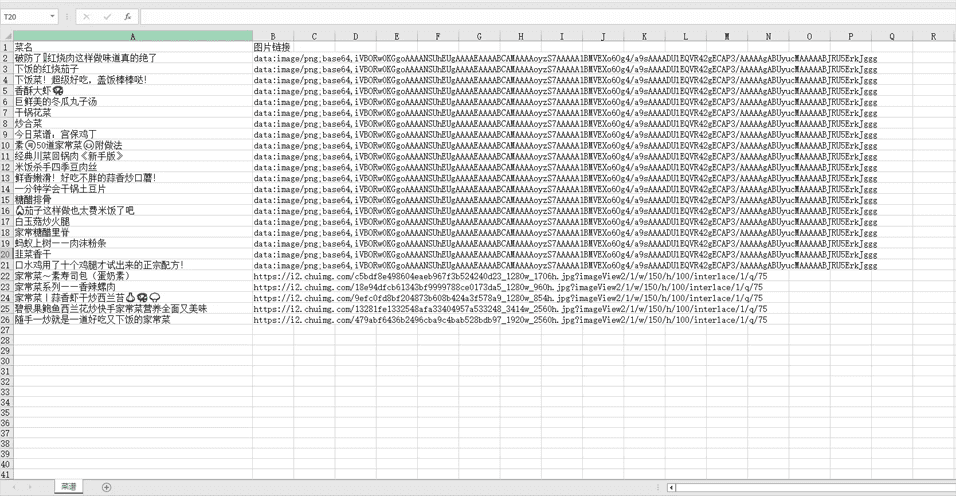
效果图
总结
通过学习这个简单的示例,您可以进一步探索更复杂的爬虫应用,处理更多类型的网页和数据,并加入更多功能来实现您自己的爬虫项目。
到此这篇关于Node.js 实现简单爬虫的示例代码的文章就介绍到这了,更多相关Node.js 爬虫内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
来源链接:https://www.jb51.net/javascript/336362jxl.htm
© 版权声明
本站所有资源来自于网络,仅供学习与参考,请勿用于商业用途,否则产生的一切后果将由您(转载者)自己承担!
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。
THE END












暂无评论内容