
Node.js 实现简单爬虫的示例代码
目录 介绍 准备工作 代码实现 运行爬虫 效果图 总结 介绍 爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。本文将使用 Nodejs 编写一个简单的爬虫脚本,爬取一个美食网站,获取...
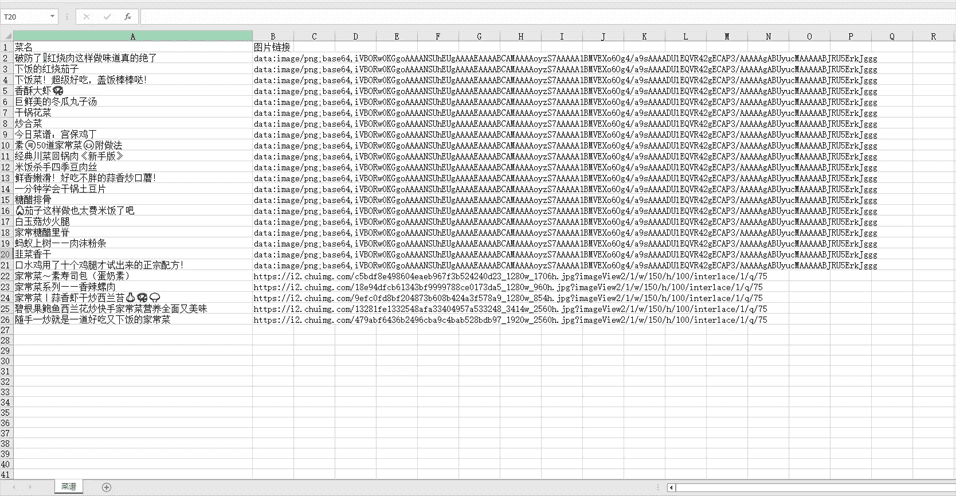
使用ExcelJS快速处理Node.js爬虫数据
目录 什么是ExcelJS ExcelJS的基本使用 安装ExcelJS 创建工作簿 操作单元格 获取单元格 设置单元格值 合并单元格 设置单元格样式 读取和写入数据 读取工作表中的数据 写入数据到工作表中 处理行...

PHP使用puppeteer抓取JS渲染后的页面内容
目录 环境依赖 puppeteer 离线安装Chromium 跳过安装chromium 获取需要下载的chromium版本号 下载对应版本的chromium 解压 spatie/browsershot 使用 总结 最近遇到一个问题,需要爬取js渲...



3protobuf
5OpneCV人脸识别:训练篇

标签云
