

Misc
题目链接: https://pan.baidu.com/s/1Q8B8Di17TuB-fjTsj1mR_w?pwd=ziu8 提取码: ziu8
1. No.shArk
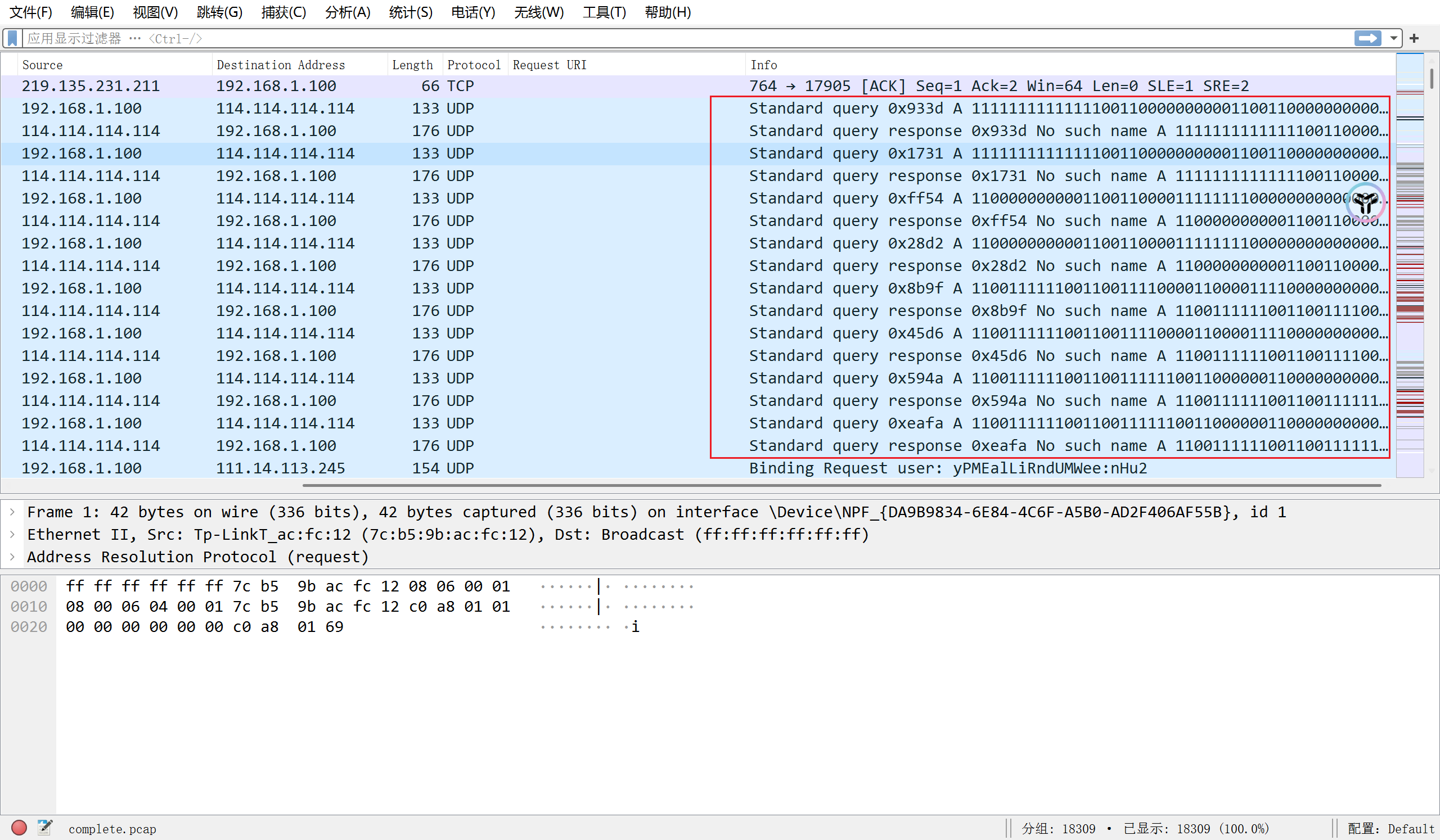
打开流量包发现存在大量的01文本
使用随波逐流工具将01转为图片

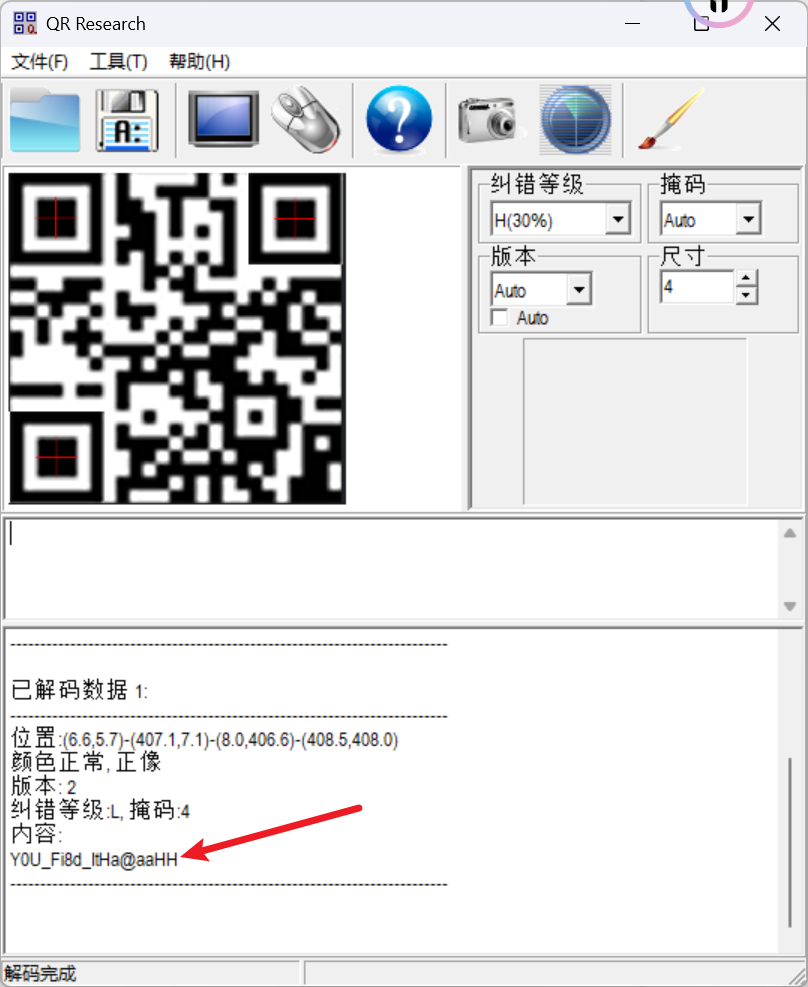
发现是一个二维码, 补充定位块, 扫描得到密码:Y0U_Fi8d_ItHa@aaHH
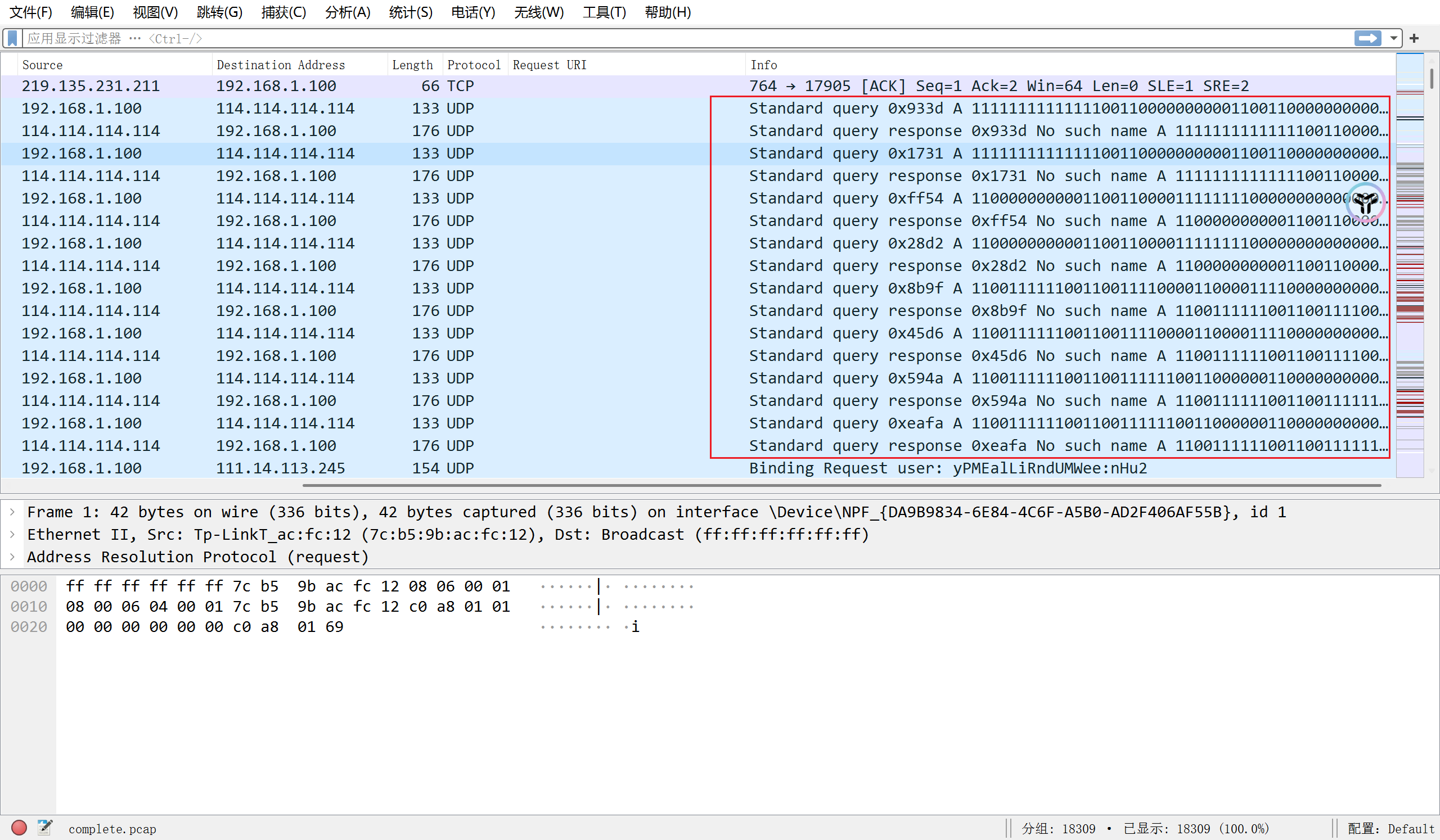
在流量包中选择导出对象HTTP, 保存w1.html, 该文本存在SNOW隐写, 密码为二维码扫出的结果
得到后半段flag, 在导出对象FTP中发现next.jpg, 以及在HTTP中发现一个存在Arnold Cat map变化的202410191641147091.png图片, 都保存下来;
将202410191641147091.png拖入到随波逐流中, 发现存在key
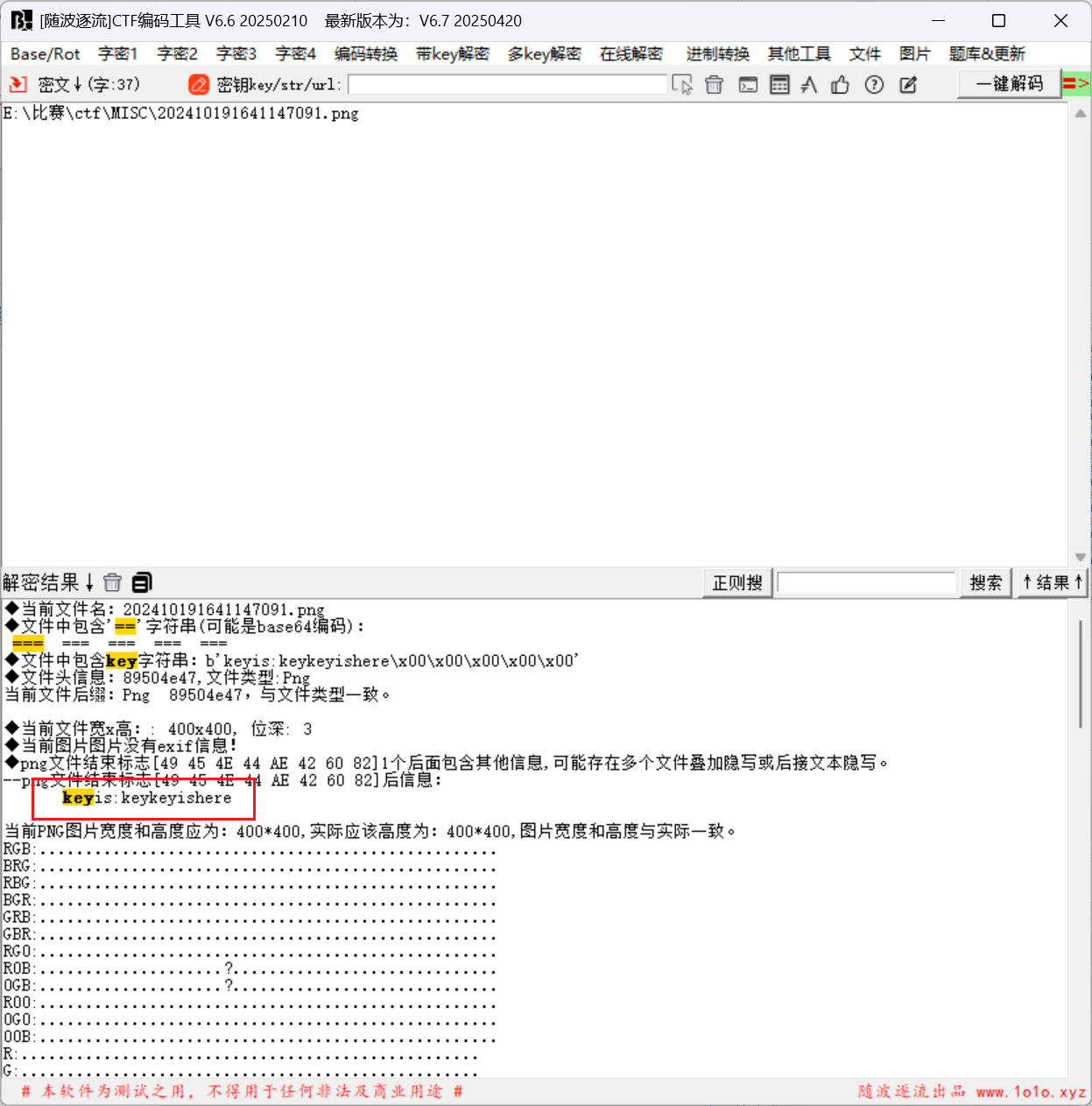
用silenteye解密next.jpg, 密码为: keykeyishere
![图片[1]-2025UCSC CTF之Misc-牛翰网](https://niuimg.niucores.com/wp-content/uploads/2025/05/5649821012504823108.png)
exp
import matplotlib.pyplot as plt
import cv2
import numpy as np
def arnold_decode(image, shuffle_times, a, b):
""" decode for rgb image that encoded by Arnold
Args:
image: rgb image encoded by Arnold
shuffle_times: how many times to shuffle
Returns:
decode image
"""
# 1:创建新图像
decode_image = np.zeros(shape=image.shape)
# 2:计算N
h, w = image.shape[0], image.shape[1]
N = h # 或N=w
# 3:遍历像素坐标变换
for time in range(shuffle_times):
for ori_x in range(h):
for ori_y in range(w):
# 按照公式坐标变换
new_x = ((a * b + 1) * ori_x + (-b) * ori_y) % N
new_y = ((-a) * ori_x + ori_y) % N
decode_image[new_x, new_y, :] = image[ori_x, ori_y, :]
image = np.copy(decode_image)
return image
def arnold_brute(image, shuffle_times_range, a_range, b_range):
for c in range(shuffle_times_range[0], shuffle_times_range[1]):
for a in range(a_range[0], a_range[1]):
for b in range(b_range[0], b_range[1]):
print(f"[+] Trying shuffle_times={c} a={a} b={b}")
decoded_img = arnold_decode(image, c, a, b)
output_filename = f"flag_decodedc{c}_a{a}_b{b}.png"
cv2.imwrite(output_filename, decoded_img, [int(cv2.IMWRITE_PNG_COMPRESSION), 0])
if __name__ == "__main__":
img = cv2.imread("cat.png")
arnold_brute(img, (1, 8), (1, 12), (1, 12))
参考博客: https://www.cnblogs.com/alexander17/p/18551089
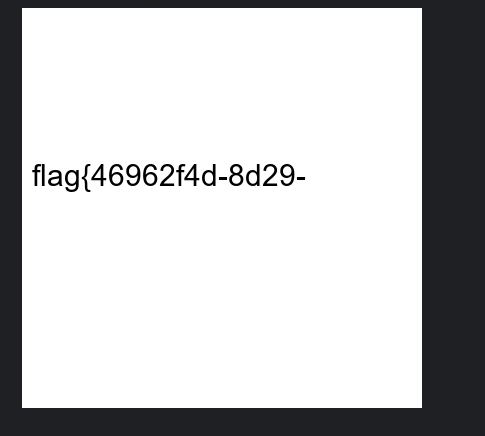
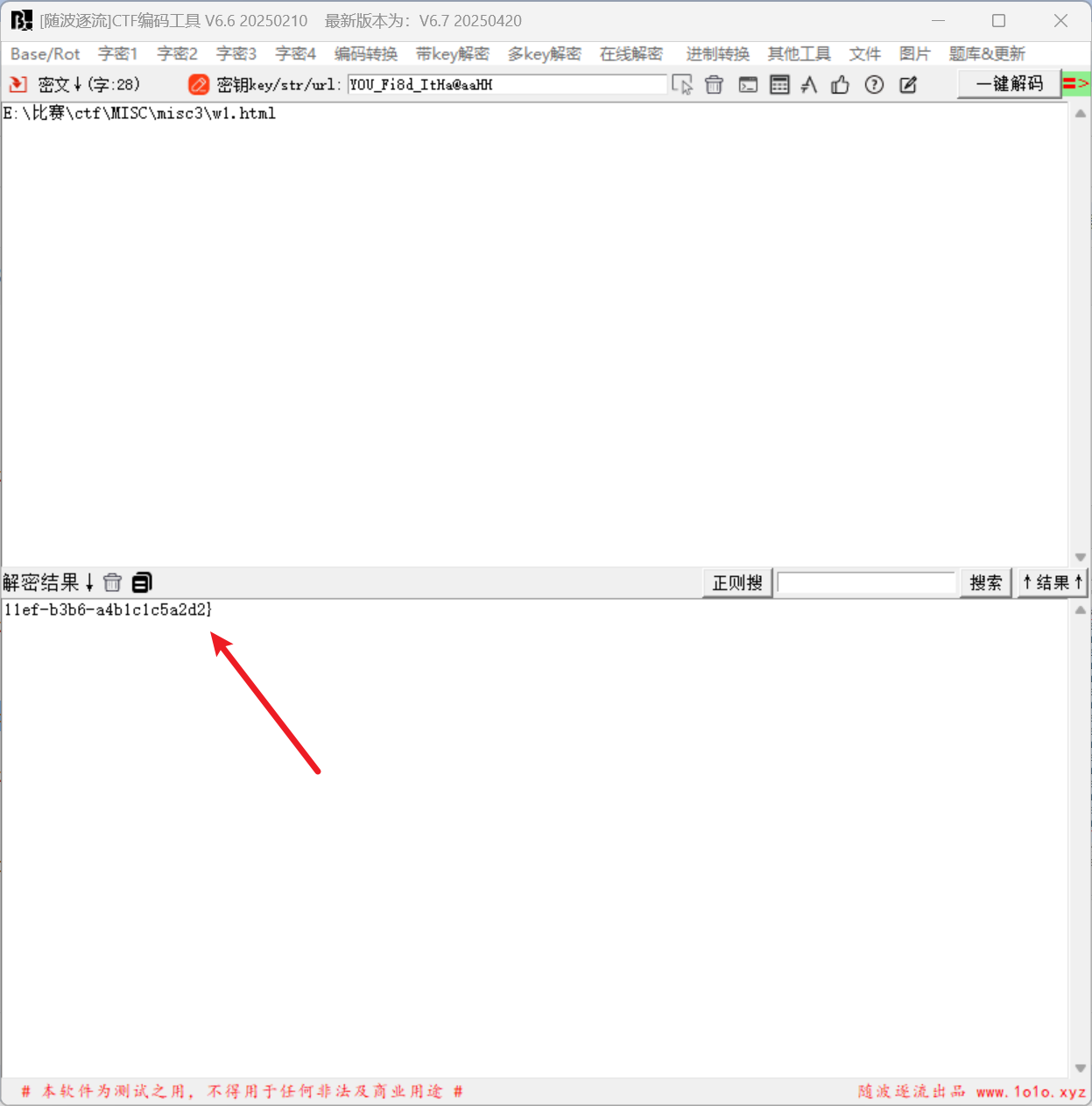
#flag{46962f4d-8d29-11ef-b3b6-a4b1c1c5a2d2}
2. three
该flag分为三部分, 首先看part1, 考察的是图片盲水印, 直接执行工具;
命令: java -jar BlindWatermark-v0.0.3.jar decode -c signwithflag.png res.png
part1: 8f02d3e7

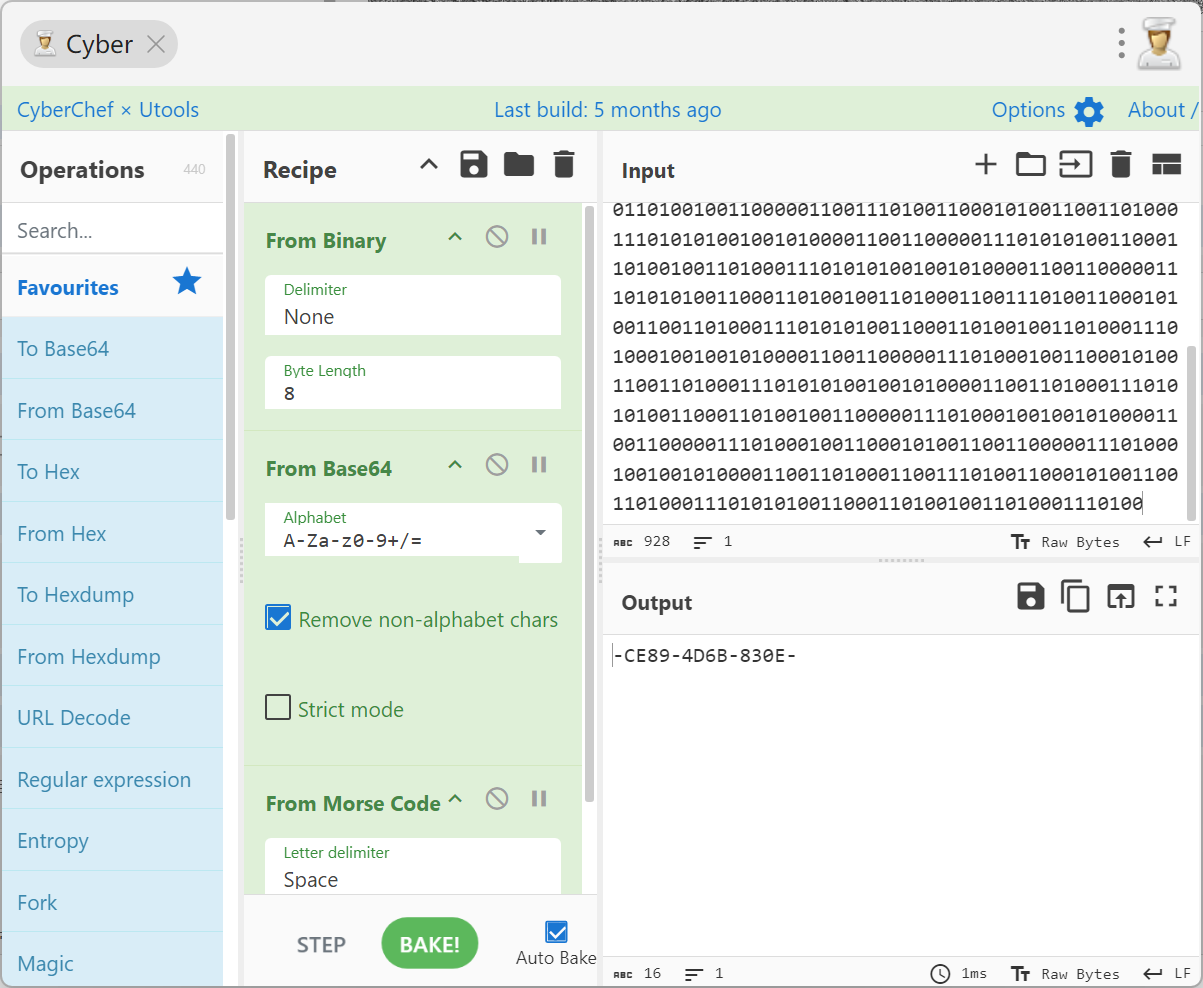
对part2进行解密: bin --> base64 --> morse;
part2: -ce89-4d6b-830e-
part3给了一个压缩包和流量包, 压缩包被加密了, 我们通过分析流量包得到密码字典
![图片[2]-2025UCSC CTF之Misc-牛翰网](https://niuimg.niucores.com/wp-content/uploads/2025/05/7250371950128423485.png)
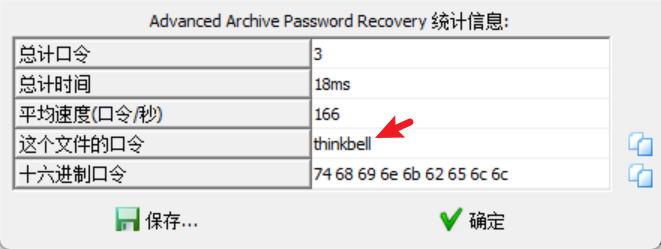
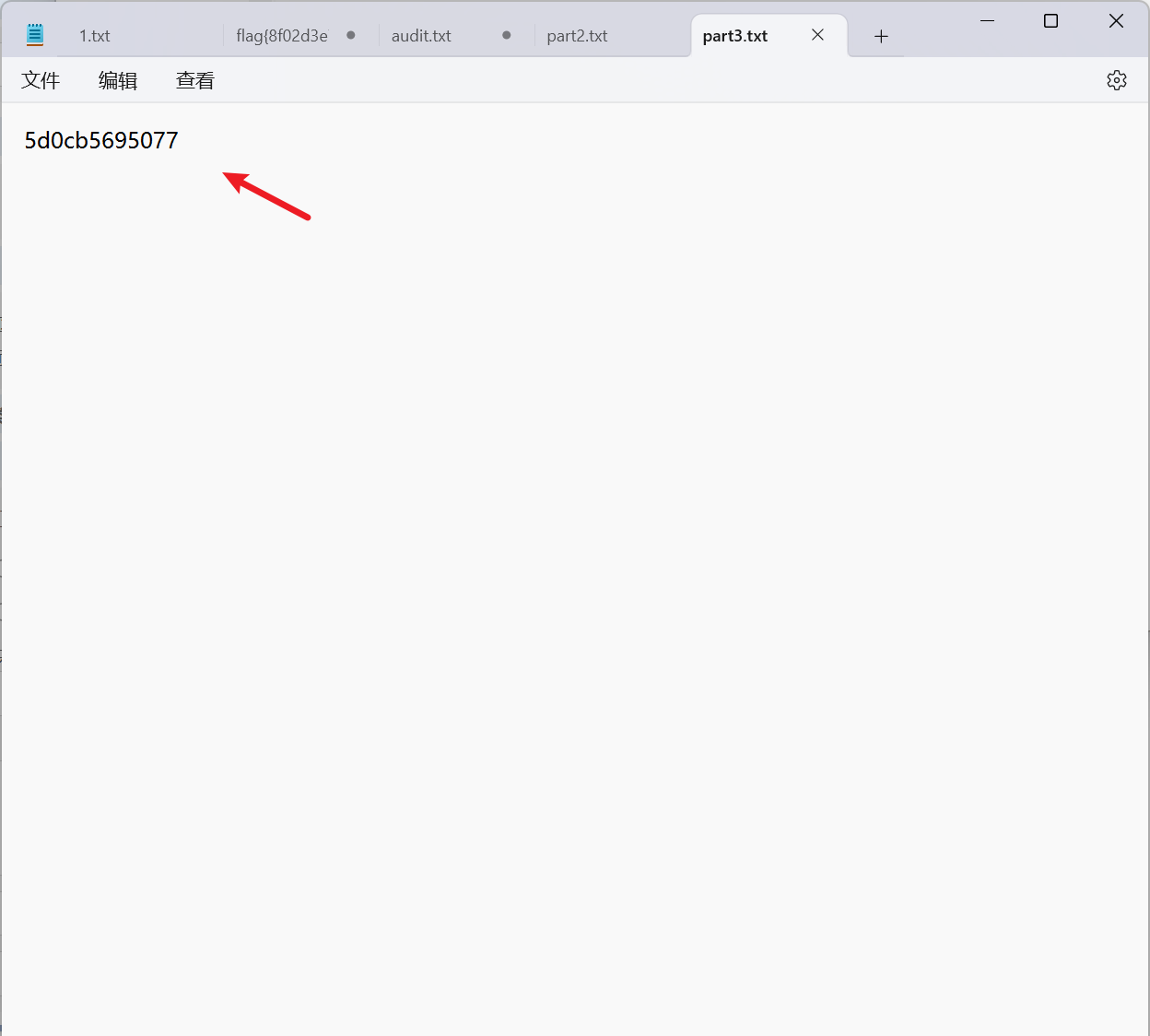
得到压缩包密码为: thinkbell, 打开txt文本得到part3;
part3: 5d0cb5695077
#flag{8f02d3e7-ce89-4d6b-830e-5d0cb5695077}
3. 小套不是套
解压发现有三个文件, 首先看套.zip, 尝试crc爆破
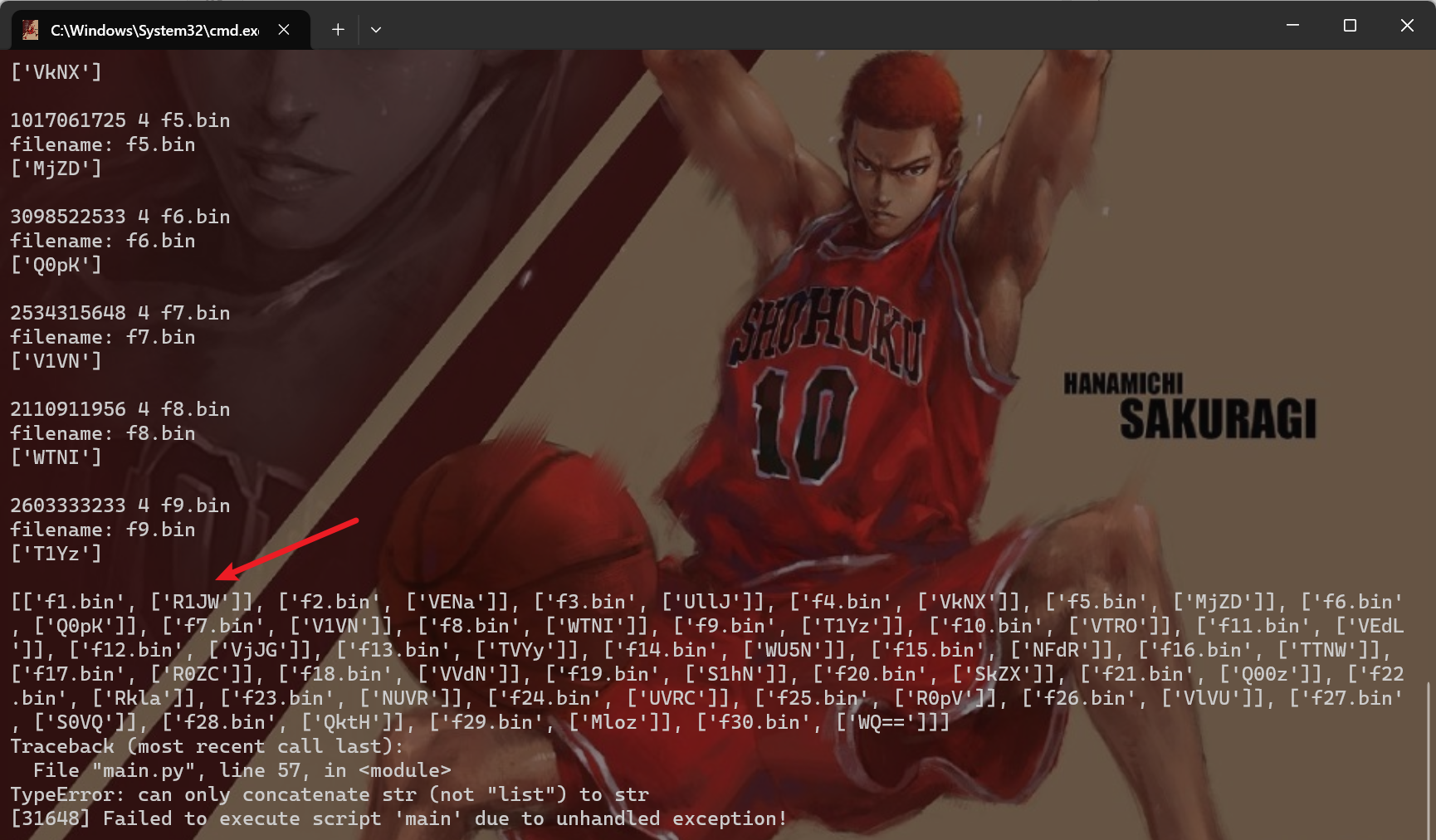
按顺序将字符串拼接起来
R1JWVENaUllJVkNXMjZDQ0pKV1VNWTNIT1YzVTROVEdLVjJGTVYyWU5NNFdRTTNWR0ZCVVdNS1hNSkZXQ00zRklaNUVRUVRCR0pVVlVUS0VQQktHMlozWQ==
进行解密: Key is SecretIsY0u
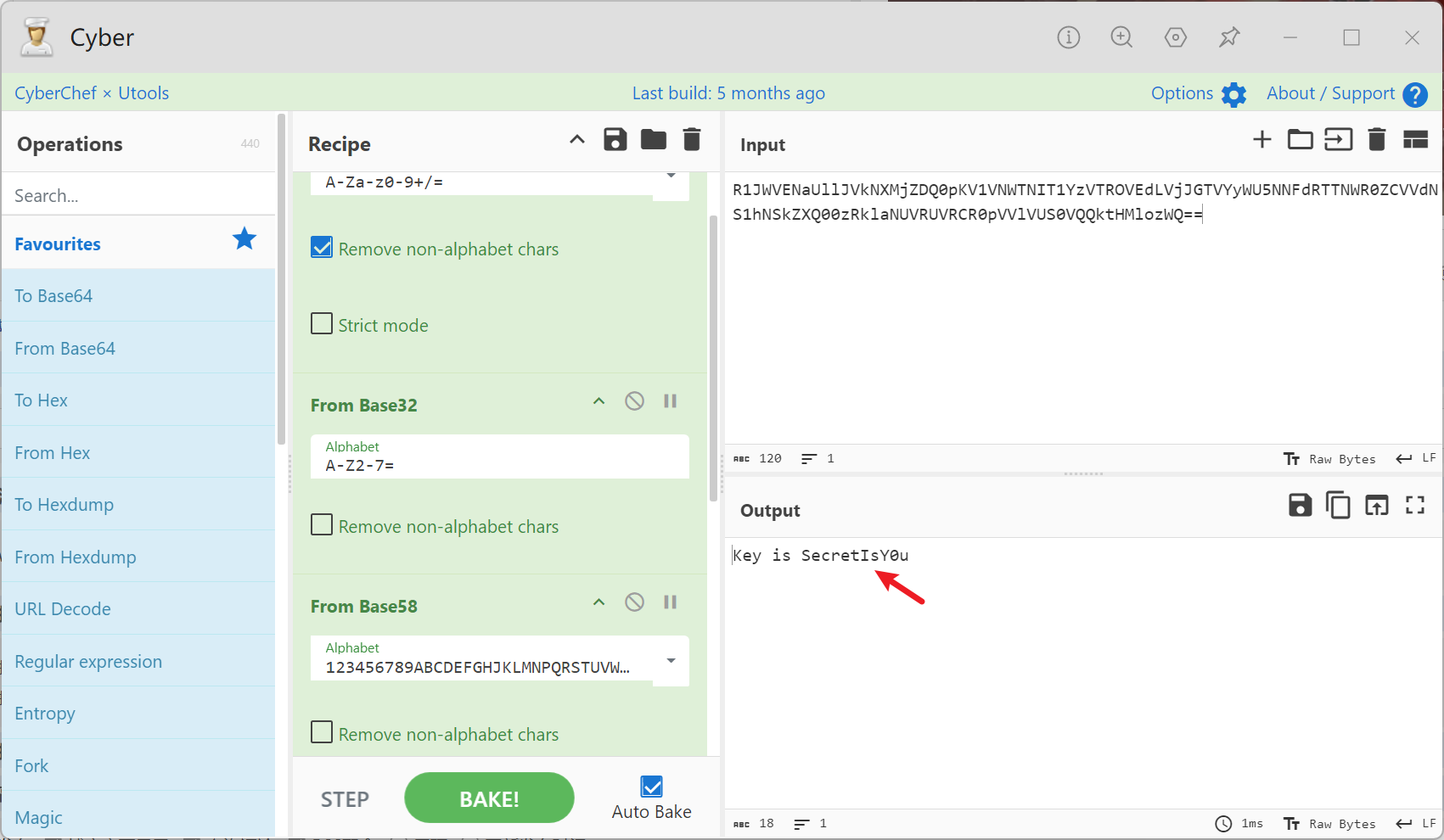
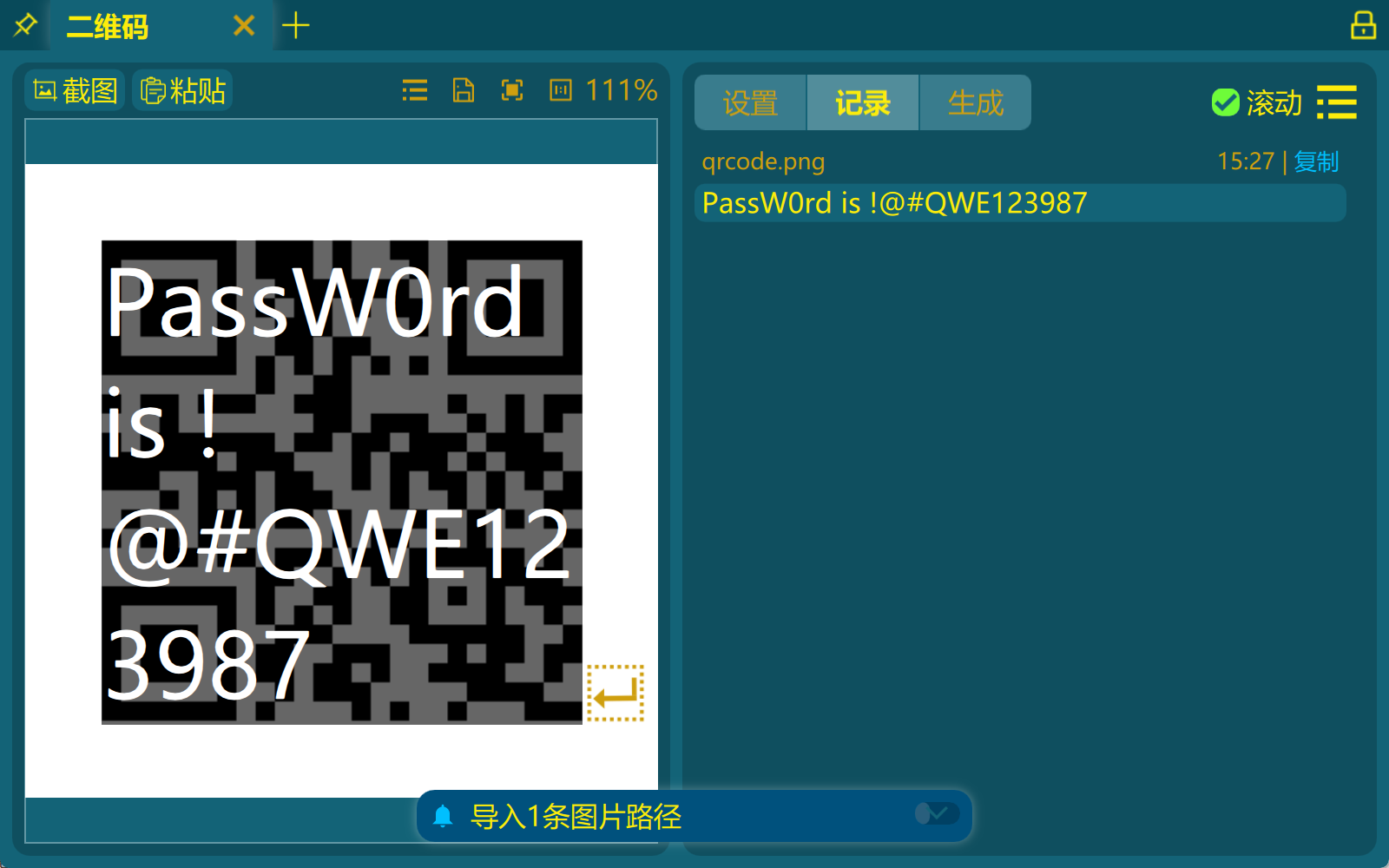
注意该密码不是另一个压缩包的解压密码, 发现存在一个二维码, 扫描结果为: PassW0rd is !@#QWE123987
解压tess.zip, 发现里面还是个压缩包, 存在伪加密
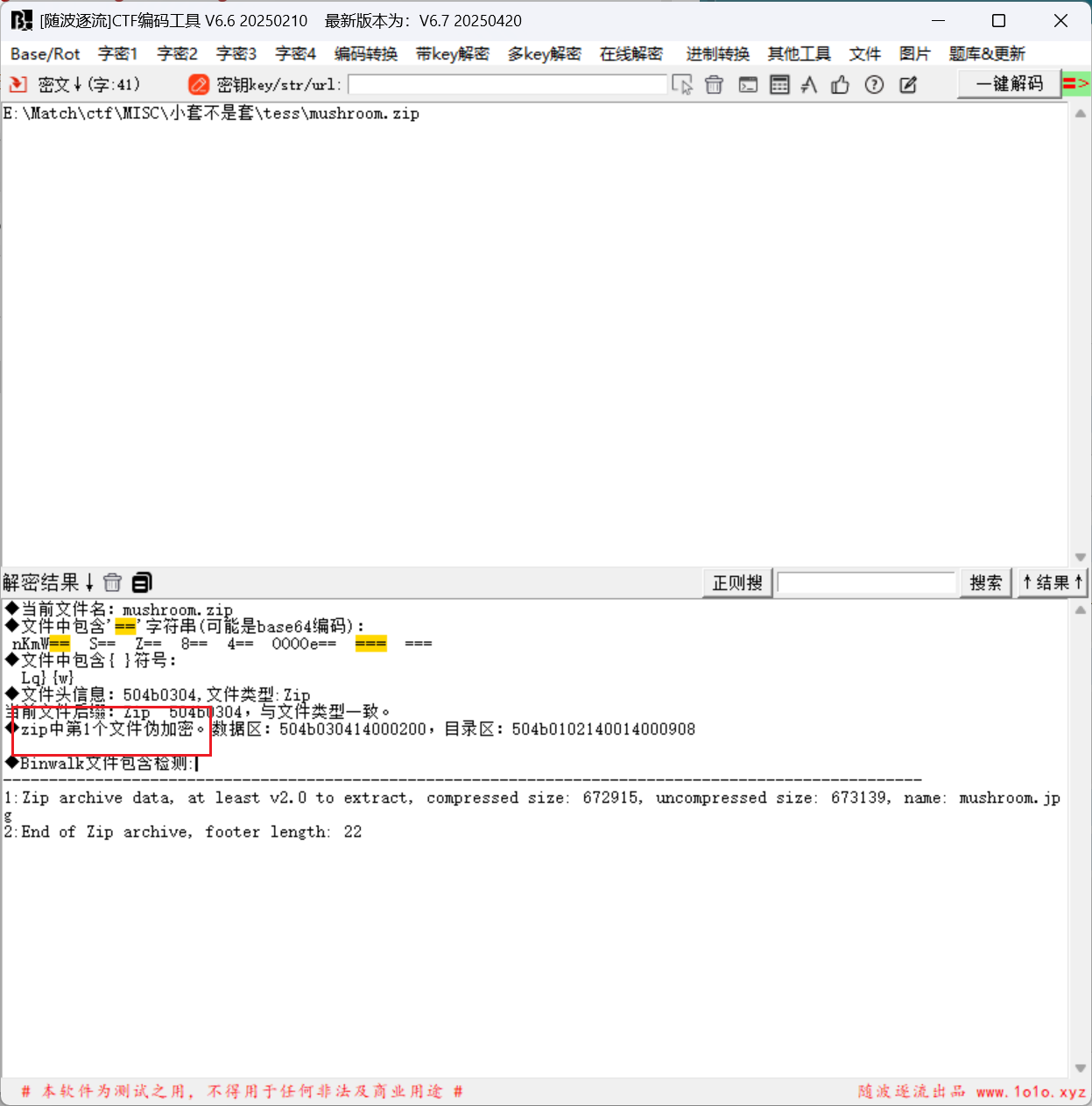
得到一个蘑菇图片, 拖入到010分析, 发现里面还存在一张照片
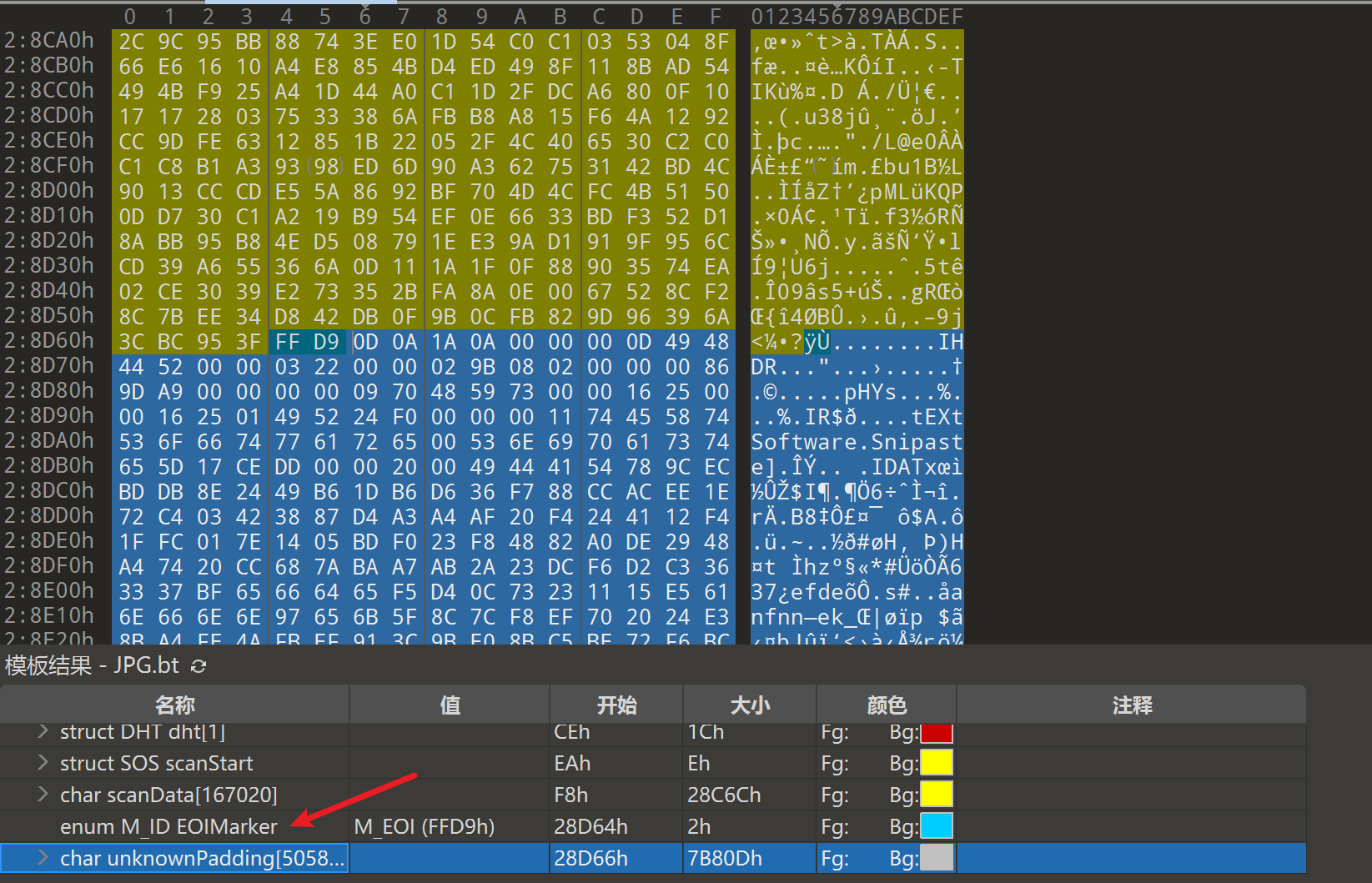
补充一个png文件头89 50 4E 47

发现存在Oursecret的特征
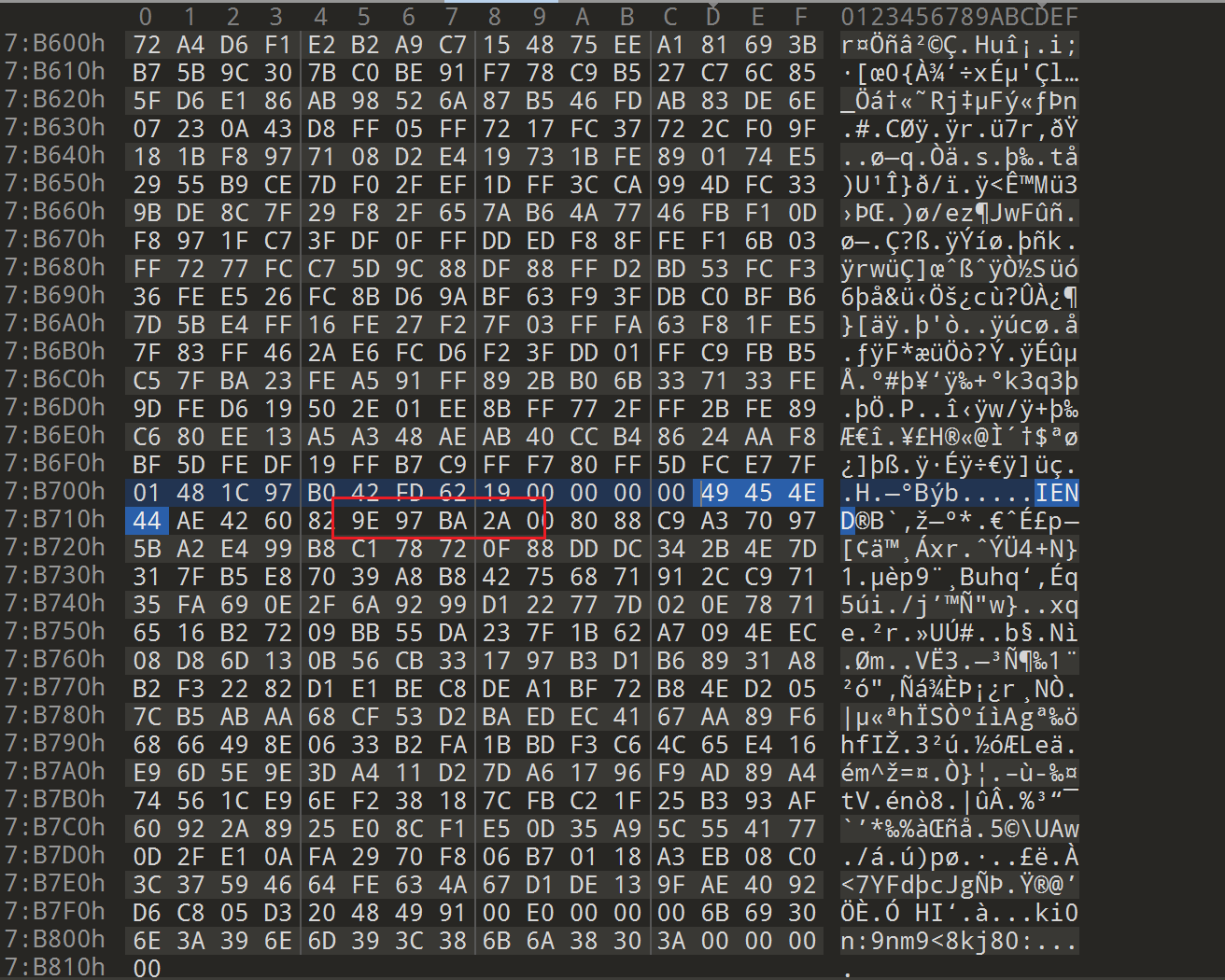
直接用Oursecret工具, 密码为SecretIsY0u, 得到flag
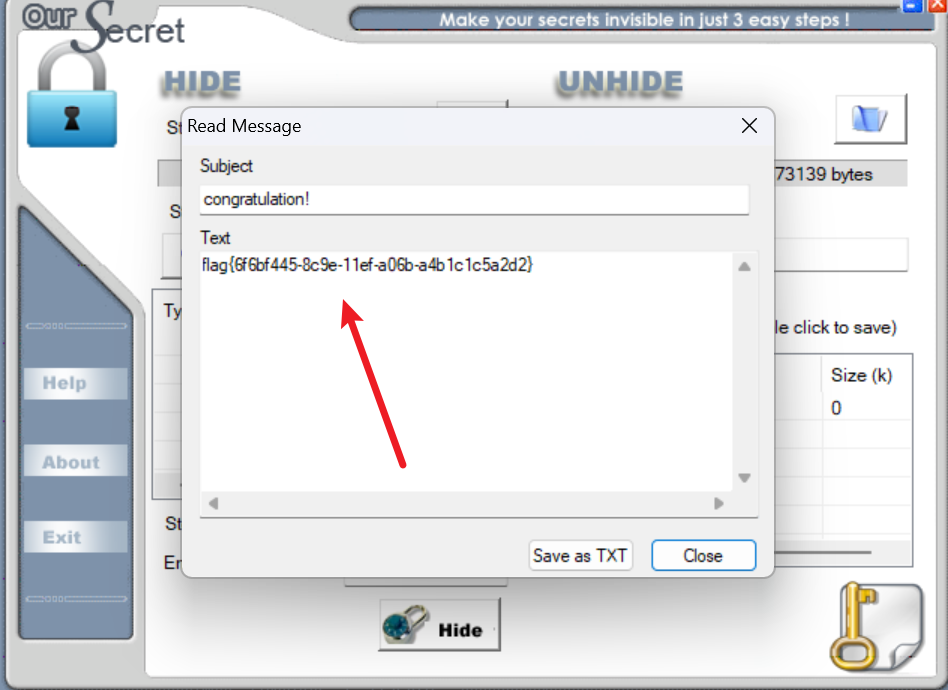
#flag{6f6bf445-8c9e-11ef-a06b-a4b1c1c5a2d2}
4. USB
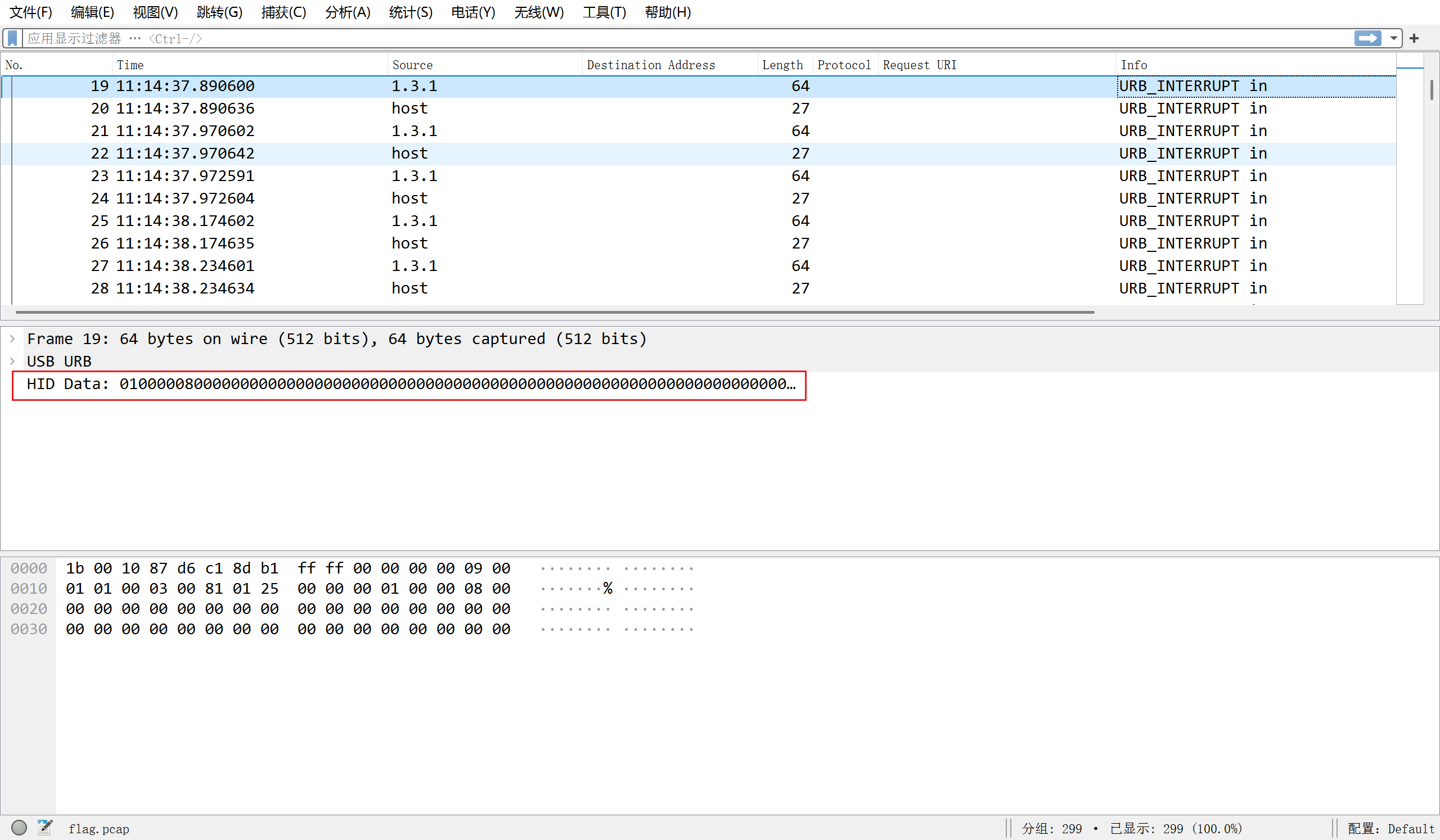
使用tshark工具, 导出上图框选的数据;
命令: tshark -r flag.pcap -T fields -e usbhid.data | sed '/^\s*$/d' > 2.txt
![图片[3]-2025UCSC CTF之Misc-牛翰网](https://niuimg.niucores.com/wp-content/uploads/2025/05/8474845183983524302.png)
exp
normalKeys = {
"04": "a", "05": "b", "06": "c", "07": "d", "08": "e",
"09": "f", "0a": "g", "0b": "h", "0c": "i", "0d": "j",
"0e": "k", "0f": "l", "10": "m", "11": "n", "12": "o",
"13": "p", "14": "q", "15": "r", "16": "s", "17": "t",
"18": "u", "19": "v", "1a": "w", "1b": "x", "1c": "y",
"1d": "z", "1e": "1", "1f": "2", "20": "3", "21": "4",
"22": "5", "23": "6", "24": "7", "25": "8", "26": "9",
"27": "0", "28": "<RET>", "29": "<ESC>", "2a": "<DEL>", "2b": "\t",
"2c": "<SPACE>", "2d": "-", "2e": "=", "2f": "[", "30": "]", "31": "\\",
"32": "<NON>", "33": ";", "34": "'", "35": "<GA>", "36": ",", "37": ".",
"38": "/", "39": "<CAP>", "3a": "<F1>", "3b": "<F2>", "3c": "<F3>", "3d": "<F4>",
"3e": "<F5>", "3f": "<F6>", "40": "<F7>", "41": "<F8>", "42": "<F9>", "43": "<F10>",
"44": "<F11>", "45": "<F12>", "46": "[PRTSC]", "47": "[SCRLK]", "48": "[PAUSE]", "49": "[INSERT]",
"4a": "[HOME]", "4b": "[PGUP]", "4c": "[DEL]", "4d": "[END]", "4e": "[PGDN]", "4f": "→", "50": "←", "51": "↓",
"52": "↑", "53": "[NUM]", "54": "/", "55": "*", "56": "-", "57": "+", "58": "\n", "59": "1", "5a": "2", "5b": "3",
"5c": "4", "5d": "5", "5e": "6", "5f": "7", "60": "8", "61": "9", "62": "0", "63": ".", "64": "\\", "65": "[APP]",
"66": "[POWER]", "67": "="
}
input_file_path = '2.txt' # 替换为你的输入文件路径
try:
with open(input_file_path, 'r', encoding='utf-8') as input_file:
result = [normalKeys.get(line.strip()[6:8], "") for line in input_file]
print(''.join(result)) # 直接打印拼接后的结果
except FileNotFoundError:
print(f"错误:文件 {input_file_path} 不存在!")
except Exception as e:
print(f"发生错误:{e}")
#e<SPACE><DEL>bdfea9b-3469-41c7-9070-d7833ecc6102<SPACE>iss<SPACE>flag<SPACE>q
#flag{ebdfea9b-3469-41c7-9070-d7833ecc6102}
来源链接:https://www.cnblogs.com/tlomlyiyi/p/18840456
© 版权声明
本站所有资源来自于网络,仅供学习与参考,请勿用于商业用途,否则产生的一切后果将由您(转载者)自己承担!
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。
THE END









暂无评论内容