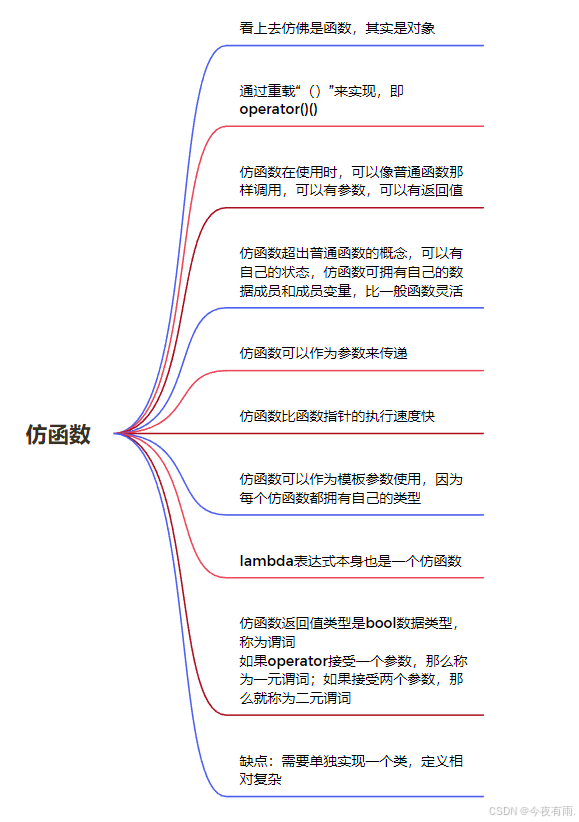


一、仿函数的定义
在C++中,仿函数(Functors)或称为函数对象(Function Objects)是重载了调用操作符operator()的类或结构体,这使得这些类的对象可以像函数一样被调用。仿函数的主要用途是提供一种灵活的方式来定义和操作数据。通过创建自定义的仿函数,你可以将待定的逻辑封装在一个对象中,并在需要时将其传递给算法或容器。
二、仿函数的特性
我们用例子来解释
- 例子一
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
//定义一个仿函数用来比较两个整数
struct CompareInt{
bool operator()(int a,int b) const{
return a<b;
}
};
int main()
{
vector<int> numbers={5,2,9,1,5,6};
//使用STL中的sort算法和自定义的仿函数对vector进行排序
std::sort(numbers.begin(),numbers.end(),CompareInt());
//输出排序后的vector
for(int num:numbers)
{
cout<<num<<" ";
}
cout<<endl;
return 0;
}
在以上这个例子中我们的仿函数结构体中重载了小括号(),传入了两个参数,达到完成比较两个数大小的功能,当我们在主函数std::sort(numbers.begin(),numbers.end(),CompareInt())中,CompareInt看似是一个对象,其实它是一个仿函数,函数的返回值是bool类型的,传入的bool类型的值决定了是升序还是倒序。
- 例子二 仿函数可以封装状态
仿函数 的一个关键特点是它可以封装状态,这意味着它们可以拥有数据成员,这些成员可以在不同的函数调用之间保持状态,以下是一个简单的C++仿函数示例,它包含了一个状态变量(internal_sum),并在每次调用的时候将其与输入参数相加:
#include <iostream>
using namespace std;
//定义一个仿函数类,带有内部状态
class Accumulator{
//构造函数,初始化内部状态
public:
Accumulator(int initial_sum=0) : internal_sum(initial_sum) {}
//重载operator(),使其接受一个整数参数,将其与内部状态相加,并返回结果
int operator()(int value){
internal_sum+=value; //修改内部状态
return internal_sum; //返回累加后的结果
}
//获取当前内部状态
int get_sum() const {
return internal_sum;
}
private:
int internal_sum;//仿函数的内部状态
};
int main()
{
//创建Accumulator类的实例,初始化内部状态为0
Accumulator accumulator;
//使用仿函数来调用它,即使用它跟使用一个函数一样
cout<<"After adding 5:"<<accumulator(5)<<endl;
cout<<"After adding 3:"<<accumulator(3)<<endl;
cout<<"Current sum:"<<accumulator.get_sum()<<endl;
//创建另一个Accumulator实例,初始化内部状态为10
Accumulator accumulator2(10);
//使用这个实例进行累加
cout<<"initial sum 10,after adding 2:"<<accumulator2(2)<<endl;
return 0;
}
在这个例子中,Accumulator类是一个仿函数,它有一个私有的整数成员internal_sum,用于存储累加的值,构造函数允许我们初始化internal_sum的值,我们每调用依次这个仿函数,它就会相应的累加,当然我们创建的第二个累加器的实例对象,它们两个的值互不影响。
- 仿函数可以当参数传递
#include <iostream>
// 定义一个仿函数类
class MyFunctor {
public:
// 重载 operator()
int operator()(int value) const {
return value * 2;
}
};
// 定义一个接受仿函数作为参数的函数
void applyFunctor(const MyFunctor& functor, int value)
{
std::cout << "经过仿函数处理过后的值: " << functor(value) << std::endl;
}
int main() {
// 创建仿函数实例
MyFunctor functor;
// 调用接受仿函数为参数的函数
applyFunctor(functor, 5);
return 0;
}
在以上这个例子中,我们定义了一个仿函数类,里面重载了operator(),使得我们在实例化函数对象时,调用这个
- 仿函数可以作为模板参数
仿函数确实可以作为模板参数使用,因为它们具有自己的唯一类型。模板参数可以接受任何类型,包括类类型,而仿函数就是类类型的一种。下面是一个代码样例,展示了如何使用仿函数作为模板参数:
#include <iostream>
#include <vector>
#include <algorithm>
// 定义一个仿函数类,用于将整数乘以2
class MultiplyByTwo {
public:
// 重载 operator(),实现对传入整数的乘以2操作
int operator()(int value) const {
return value * 2;
}
};
// 定义一个接受仿函数作为模板参数的函数模板
// 该函数模板用于对 vector 中的每个元素应用仿函数进行变换
template <typename Functor>
void transformVector(std::vector<int> &vec, Functor functor) {
// 遍历 vector 中的每个元素,并应用仿函数进行变换
for (auto &item : vec) {
item = functor(item);
}
}
int main() {
// 初始化一个包含整数的 vector
std::vector<int> vec = {1, 2, 3, 4, 5};
// 使用 MultiplyByTwo 仿函数类作为模板参数,调用 transformVector 函数
// 对 vector 中的每个元素进行乘以2的操作
transformVector(vec, MultiplyByTwo());
// 输出变换后的 vector 元素
for (auto item : vec) {
std::cout << item << " ";
}
std::cout << std::endl;
//也可以直接使用lambda表达式作为模板参数
transformVector(vec,[](int value){return value*3;});
//再次输出变换后的值
for (auto item : vec) {
std::cout << item << " ";
}
std::cout << std::endl;
return 0;
}
在这个例子中,transformVector是一个函数模板,它接受一个std::vector和一个仿函数作为参数。这个函数模板使用仿函数来变换vector中的每一个元素。在主函数中,我们首先使用MultiplyByTwo仿函数作为模板参数调用transformVector函数,然后使用一个lambda表达式作为模板参数再次调用transformVector函数。这展示了仿函数和lambda表达式都可以作为模板参数传递给函数模板
- 谓词
在计算机语言中,谓词通常指条件表达式的求值返回真或假的过程
1.一元谓词(Unary Predicate)
一元谓词通常用于判断单个元素是否满足某个条件,以下是一个使用std::remove_if和一元谓词的简单例子,它移除std::vector中的所有偶数
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
// 定义一元谓词函数,检查整数是否为偶数
// 参数:
// - num: 需要检查的整数
// 返回值:
// - 如果 num 是偶数,返回 true;否则返回 false
bool isEven(int num) {
return num % 2 == 0;
}
int main() {
// 初始化一个包含整数的 vector
vector<int> vec{1, 2, 3, 4, 5, 6, 7, 8, 9};
// 使用 std::remove_if 和一元谓词 isEven 移除所有偶数
// std::remove_if 将所有满足条件(即偶数)的元素移动到 vector 的末尾,并返回新末尾的迭代器
// vec.erase 则删除从新末尾到原末尾的所有元素,从而实现移除操作
vec.erase(remove_if(vec.begin(), vec.end(), isEven), vec.end());
// 输出处理之后的 vector 元素
for (auto i : vec) {
cout << i << " ";
}
cout << endl;
return 0;
}
2.二元谓词(Binary Predicate)
二元谓词通常用于比较两个元素,以下是一个使用std::sort和二元谓词的简单例子,它根据自定义的比较规则对vector进行排序:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
// 定义二元谓词函数,用于比较两个整数的大小(降序排序)
// 参数:
// - a: 第一个整数
// - b: 第二个整数
// 返回值:
// - 如果 a 大于 b,返回 true;否则返回 false
bool CompareInt(int a, int b) {
return a > b;
}
int main() {
// 初始化一个包含整数的 vector
vector<int> vec = {3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5};
// 使用 std::sort 和二元谓词 CompareInt 对 vector 进行降序排序
// std::sort 接受三个参数:起始迭代器、结束迭代器和比较函数
// 比较函数 CompareInt 确定了排序顺序为降序
std::sort(vec.begin(), vec.end(), CompareInt);
// 输出处理之后的 vector 元素
for (auto i : vec) {
cout << i << " ";
}
cout << endl;
return 0;
}
在这两个例子中,我分别定义了一个一元谓词和一个二元谓词,一元谓词用于判断单个元素是否为偶数,而二元谓词用于比较两个元素的大小,然后,我们使用这些谓词与标准库算法结合在一起,实现相应的功能。
三、仿函数的相对性能优势
- 通常说仿函数(也称为函数对象或functor)比函数指针执行速度快,这并不是一个绝对的结论。在大多数情况下,它们之间的性能差异是非常小的,甚至在现代的编译器优化下可能几乎无法测量。但是,有几个原因可能会导致在某些特定情况下仿函数相对更快:
- 内联优化:在仿函数作为类成员函数或重载操作符,更有可能被编译器内联(inline),这可以减少函数调用的开销。相比之下,函数指针指向的函数通常不会被内联,除非编译器特别确定这样做是安全的。
- 状态局部性:仿函数可以包含状态(即数据成员),这些状态 可以与其成员函数紧密的存储在一起。这种紧密性可以提高数据访问的局部性,从而提高缓存利用率,进而可能提高性能。
- 类型安全:仿函数可以通过模板和类型系统提供更高级别的类型安全性。虽然这不会直接影响执行速度,但它可以减少因类型错误而导致的运行时开销。
- 无额外的间接引用:函数指针需要额外的简介引用来访问目标函数。虽然这种间接引用在现代处理器上通常是非常快的,但在某些极端情况下,它可能会成为性能瓶颈。
- 编译时优化:由于仿函数是类的实例,编译器可以对它们进行更广泛的优化,例如通过消除虚拟函数调用的开销(如果仿函数没有使用虚函数)或使用特定的类型特定优化。
总结
本文主要介绍了 C++ 中的仿函数,包括仿函数的定义、特性和相对性能优势。仿函数是重载了调用操作符 operator () 的类或结构体,可像函数一样被调用,主要用途是提供灵活方式定义和操作数据。其特性有可封装状态、能当参数传递、可作为模板参数及作为谓词使用。相对性能优势方面,可能比函数指针执行速度快,原因包括内联优化、状态局部性、类型安全、无额外间接引用和编译时优化等。
到此这篇关于一文详解C++仿函数的文章就介绍到这了,更多相关C++仿函数内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
来源链接:https://www.jb51.net/program/338940cqm.htm
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。








暂无评论内容