


title: Alembic迁移脚本:让数据库变身时间旅行者
date: 2025/05/09 13:08:18
updated: 2025/05/09 13:08:18
author: cmdragon
excerpt:
Alembic 是一个用于数据库迁移的工具,通过迁移脚本记录数据库结构的变化,确保不同环境的数据库保持同步。其核心工作原理包括模型扫描、数据库快照和差异分析三个阶段。通过 alembic revision --autogenerate 命令,可以自动生成迁移脚本,对比模型定义与数据库实际结构的差异。高级配置技巧包括自定义上下文配置和处理复杂字段变更。常见错误如数据库版本不一致或字段类型不识别,可通过升级、回滚或添加类型映射解决。最佳实践建议包括及时生成迁移脚本、测试环境保持最新、生产环境变更前备份等。
categories:
- 后端开发
- FastAPI
tags:
- Alembic
- 数据库迁移
- SQLAlchemy
- 自动生成脚本
- 数据库版本管理
- FastAPI
- 数据库模式变更
![图片[1]-Alembic迁移脚本:让数据库变身时间旅行者-牛翰网](https://niuimg.niucores.com/wp-content/uploads/2025/05/202940455634578710.jpeg)

扫描二维码
关注或者微信搜一搜:编程智域 前端至全栈交流与成长
探索数千个预构建的 AI 应用,开启你的下一个伟大创意:https://tools.cmdragon.cn/
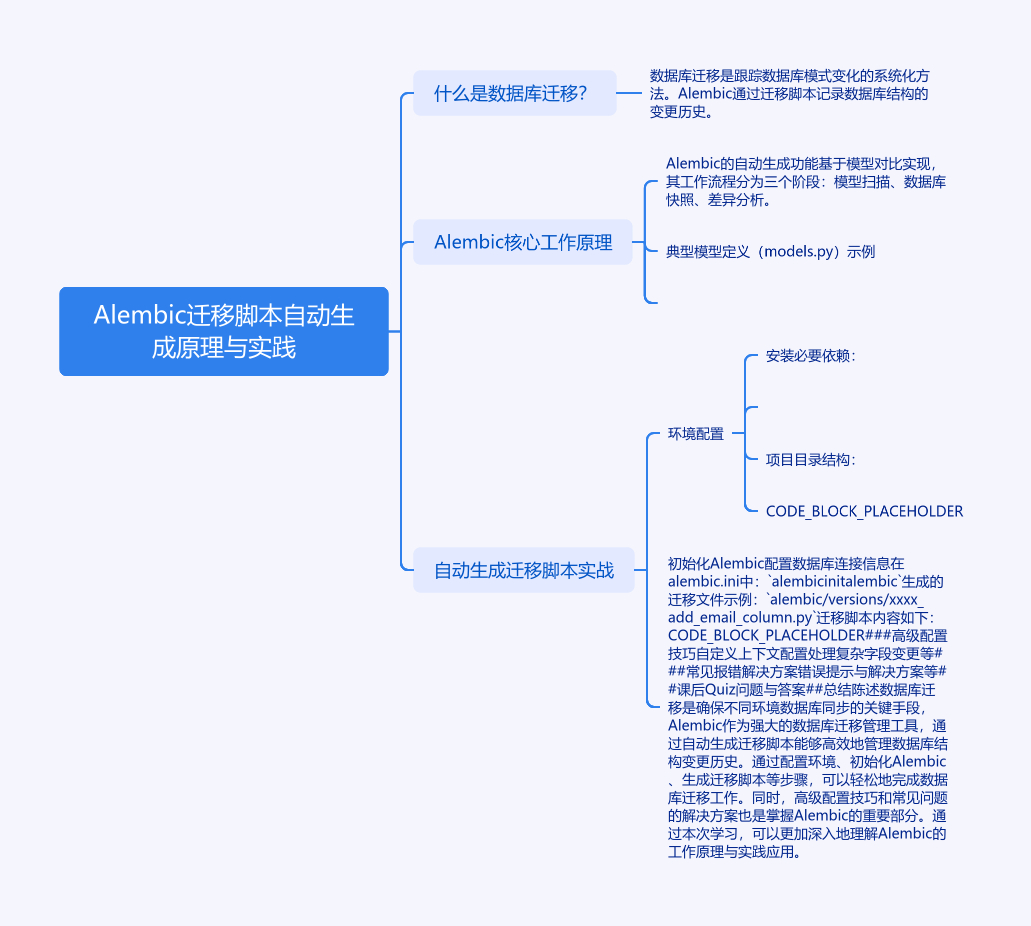
1. Alembic 迁移脚本自动生成原理与实践
1.1 什么是数据库迁移?
数据库迁移(Database Migration)是跟踪数据库模式变化的系统化方法。就像我们使用Git管理代码版本一样,Alembic
通过迁移脚本记录数据库结构的变更历史。当我们在开发过程中修改数据表结构时,通过迁移可以确保不同环境(开发、测试、生产)的数据库保持同步。
1.2 Alembic 核心工作原理
Alembic 的自动生成功能基于模型对比实现,其工作流程分为三个阶段:
- 模型扫描:读取SQLAlchemy的Base类元数据
- 数据库快照:连接目标数据库获取当前结构
- 差异分析:对比模型定义与数据库实际结构的差异
# 示例:典型模型定义(models.py)
from sqlalchemy import Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String(50))
email = Column(String(100)) # 新增字段示例
1.3 自动生成迁移脚本实战
1.3.1 环境配置
安装必要依赖:
pip install alembic sqlalchemy fastapi
项目目录结构:
/project
/alembic
/versions
env.py
alembic.ini
main.py
models.py
1.3.2 初始化Alembic
alembic init alembic
修改alembic.ini配置:
[alembic]
script_location = alembic
sqlalchemy.url = postgresql://user:pass@localhost/dbname
1.3.3 生成迁移脚本
alembic revision --autogenerate -m "add email column"
生成的迁移文件示例(alembic/versions/xxxx_add_email_column.py):
def upgrade():
op.add_column('users', Column('email', String(100)))
def downgrade():
op.drop_column('users', 'email')
1.4 高级配置技巧
1.4.1 自定义上下文配置
在env.py中添加模型导入:
# 修改后的env.py核心部分
from models import Base # 导入模型基类
target_metadata = Base.metadata
def run_migrations_online():
connectable = engine_from_config(
config.get_section(config.config_ini_section),
prefix="sqlalchemy.",
poolclass=pool.NullPool,
)
with connectable.connect() as connection:
context.configure(
connection=connection,
target_metadata=target_metadata,
compare_type=True, # 启用字段类型比对
compare_server_default=True # 比对默认值
)
1.4.2 处理复杂字段变更
当修改字段类型时,建议分步骤操作:
# 迁移脚本示例:安全修改字段类型
def upgrade():
with op.batch_alter_table('users') as batch_op:
batch_op.alter_column('phone',
existing_type=String(20),
type_=Integer(),
existing_nullable=True)
1.5 课后Quiz
问题1:当新增模型类后执行alembic revision --autogenerate没有生成迁移脚本,最可能的原因是?
A. 忘记保存模型文件
B. 模型未正确导入到env.py
C. 数据库连接失败
D. 未安装sqlalchemy
答案:B。Alembic需要正确导入包含Base类的模型定义才能进行元数据比对,如果未在env.py中正确设置target_metadata,会导致无法检测模型变化。
问题2:哪个命令可以查看当前数据库版本?
A. alembic current
B. alembic show
C. alembic history
D. alembic heads
答案:A。alembic current命令显示当前数据库所处的迁移版本。
1.6 常见报错解决方案
错误1:FAILED: Target database is not up to date
alembic upgrade head
原因:存在未应用的迁移版本
解决:执行升级命令更新数据库
错误2:SAWarning: Did not recognize type 'geometry'...
# 在env.py中添加自定义类型映射
from sqlalchemy.dialects.postgresql import JSONB
def include_name(name, type_, parent_names):
if type_ == "geometry":
return False
return True
context.configure(
...
include_name = include_name,
user_module_prefix = 'sa.'
)
原因:使用了数据库特定的字段类型
解决:在env.py中添加类型过滤逻辑
错误3:Can't locate revision identified by 'xxxxx'
alembic history --verbose
alembic downgrade -1
原因:版本链断裂或历史记录不完整
解决:检查迁移历史记录,必要时回滚到有效版本
1.7 最佳实践建议
- 每次修改模型后立即生成迁移脚本
- 测试环境始终执行
alembic upgrade head保证最新 - 生产环境变更前必须备份数据库
- 复杂变更建议分多个迁移步骤完成
- 保持开发、测试、生产环境的数据库版本一致
通过掌握这些核心原理和实践技巧,您可以在FastAPI项目中实现安全可靠的数据库版本管理。下次当您修改模型时,记得用--autogenerate
参数让Alembic自动生成迁移脚本,这将极大提升开发效率并减少人为错误。
余下文章内容请点击跳转至 个人博客页面 或者 扫码关注或者微信搜一搜:编程智域 前端至全栈交流与成长,阅读完整的文章:Alembic迁移脚本:让数据库变身时间旅行者 | cmdragon’s Blog
往期文章归档:
- 数据库连接池:从银行柜台到代码世界的奇妙旅程 | cmdragon’s Blog
- 点赞背后的技术大冒险:分布式事务与SAGA模式 | cmdragon’s Blog
- N+1查询:数据库性能的隐形杀手与终极拯救指南 | cmdragon’s Blog
- FastAPI与Tortoise-ORM开发的神奇之旅 | cmdragon’s Blog
- DDD分层设计与异步职责划分:让你的代码不再“异步”混乱 | cmdragon’s Blog
- 异步数据库事务锁:电商库存扣减的防超卖秘籍 | cmdragon’s Blog
- FastAPI中的复杂查询与原子更新指南 | cmdragon’s Blog
- 深入解析Tortoise-ORM关系型字段与异步查询 | cmdragon’s Blog
- FastAPI与Tortoise-ORM模型配置及aerich迁移工具 | cmdragon’s Blog
- 异步IO与Tortoise-ORM的数据库 | cmdragon’s Blog
- FastAPI数据库连接池配置与监控 | cmdragon’s Blog
- 分布式事务在点赞功能中的实现 | cmdragon’s Blog
- Tortoise-ORM级联查询与预加载性能优化 | cmdragon’s Blog
- 使用Tortoise-ORM和FastAPI构建评论系统 | cmdragon’s Blog
- 分层架构在博客评论功能中的应用与实现 | cmdragon’s Blog
- 深入解析事务基础与原子操作原理 | cmdragon’s Blog
- 掌握Tortoise-ORM高级异步查询技巧 | cmdragon’s Blog
- FastAPI与Tortoise-ORM实现关系型数据库关联 | cmdragon’s Blog
- Tortoise-ORM与FastAPI集成:异步模型定义与实践 | cmdragon’s Blog
- 异步编程与Tortoise-ORM框架 | cmdragon’s Blog
- FastAPI数据库集成与事务管理 | cmdragon’s Blog
- FastAPI与SQLAlchemy数据库集成 | cmdragon’s Blog
- FastAPI与SQLAlchemy数据库集成与CRUD操作 | cmdragon’s Blog
- FastAPI与SQLAlchemy同步数据库集成 | cmdragon’s Blog
- SQLAlchemy 核心概念与同步引擎配置详解 | cmdragon’s Blog
- FastAPI依赖注入性能优化策略 | cmdragon’s Blog
- FastAPI安全认证中的依赖组合 | cmdragon’s Blog
- FastAPI依赖注入系统及调试技巧 | cmdragon’s Blog
- FastAPI依赖覆盖与测试环境模拟 | cmdragon’s Blog
- FastAPI中的依赖注入与数据库事务管理 | cmdragon’s Blog
- FastAPI依赖注入实践:工厂模式与实例复用的优化策略 | cmdragon’s Blog
- FastAPI依赖注入:链式调用与多级参数传递 | cmdragon’s Blog
- FastAPI依赖注入:从基础概念到应用 | cmdragon’s Blog
- FastAPI中实现动态条件必填字段的实践 | cmdragon’s Blog
- XML Sitemap
来源链接:https://www.cnblogs.com/Amd794/p/18868186
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。














暂无评论内容