


前戏
最近论文真的很超级多,而且很多吸睛话题论文:CornerNet-Lite,CenterNet,NAS-FCN等。2019年4月23日,arXiv上放出了很多优质论文:各种顶会paper和顶会“种子”paper。这里为了节省篇幅,Amusi做了论文精选。本文要速递介绍的这三篇论文,Amusi 觉得都是相当具有影响力的paper,相信对你当前的研究会有很大帮助。
本文以论文速递为主,希望对你有点启发。三篇论文缩写如下:
VoteNet (3D目标检测)
NAS-A/B/C (人脸识别)
PoolNet (实时显著性目标检测)
VoteNet
《Deep Hough Voting for 3D Object Detection in Point Clouds》

arXiv: https://arxiv.org/abs/1904.09664
github: None
作者团队:FAIR & 斯坦福
PS:何恺明三作
注:2019年04月23日刚出炉的paper
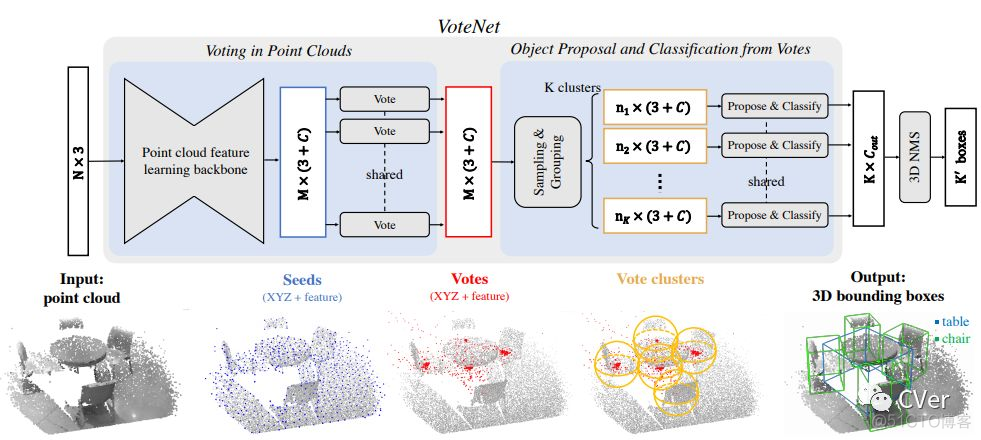
Abstract:当前的3D目标检测方法受2D目标检测严重影响。为了利用2D检测器中的架构,它们经常将3D点云转换为常规网格,或者依赖于2D图像中的检测来提出3D框。很少有人尝试直接检测点云中的物体。在这项工作中,我们回到第一原则,为点云数据构建一个3D检测pipeline,并尽可能通用。然而,由于数据的稀疏性 – 来自3D空间中的2D流形的样本 – 当从场景点直接预测边界框参数时,我们面临一个主要挑战:3D目标质心可能远离任何表面点,因此很难一步准确回归。为了应对这一挑战,我们提出了VoteNet,一种基于 deep point set 网络和Hough投票协同作用的端到端3D物体检测网络。我们的模型在两个大型真实3D扫描数据集上实现了最先进的3D检测,ScanNet和SUN RGB-D具有简单的设计,紧凑的模型尺寸和高效率。值得注意的是,VoteNet通过使用纯粹的几何信息而不依赖于彩色图像,优于以前的方法。
本文算法(VoteNet)流程图
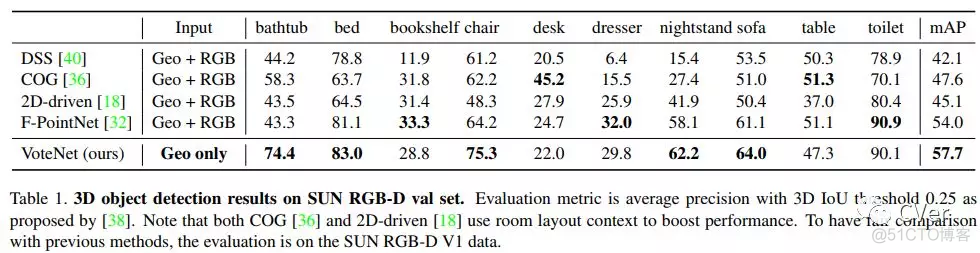
实验结果

NAS-A/B/C
《Neural Architecture Search for Deep Face Recognition》

arXiv: https://arxiv.org/abs/1904.09523
github: None
作者团队:华为(杭研所)
注:2019年04月23日刚出炉的paper
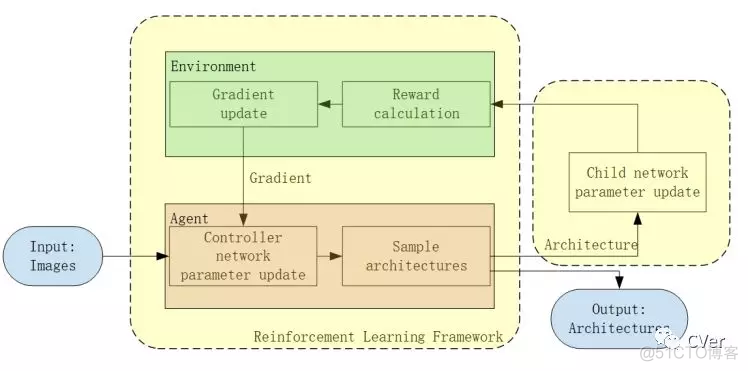
Abstract:随着电子设备的广泛普及,与传统的密码和模式解锁相比,生物识别技术的出现为用户认证带来了显著的便利。在众多生物特征中,面部是一种普遍且不可替代的特征。人脸识别是电子设备宣传的主要功能之一。该领域以前的工作主要集中在两个方向:转换损失函数以提高传统深度卷积神经网络(Resnet)中的识别精度;将最新的损失函数与轻量级系统(MobileNet)相结合,以最低的精度降低网络尺寸。但这些都没有改变网络结构。随着AutoML的发展,神经网络搜索(NAS)在图像分类基准中表现出了优异的性能。在本文中,我们将NAS技术集成到人脸识别中,以定制更合适的网络。我们引用了神经架构搜索的框架,它交替地训练 child and controller 网络。同时,我们通过将评估延迟纳入强化学习的奖励来改变NAS,并利用策略梯度算法以最经典的交叉熵损失自动搜索体系结构。我们搜索到的网络架构在大规模人脸数据集中具有最先进的精度,在MS-Celeb-1M中达到98.77%准确率,目前第 1,在网络规模相对较小的LFW中达到99.89%。据我们所知,本方法是首次尝试使用NAS解决深度识别问题并在此领域取得最佳效果。
NAS流程图
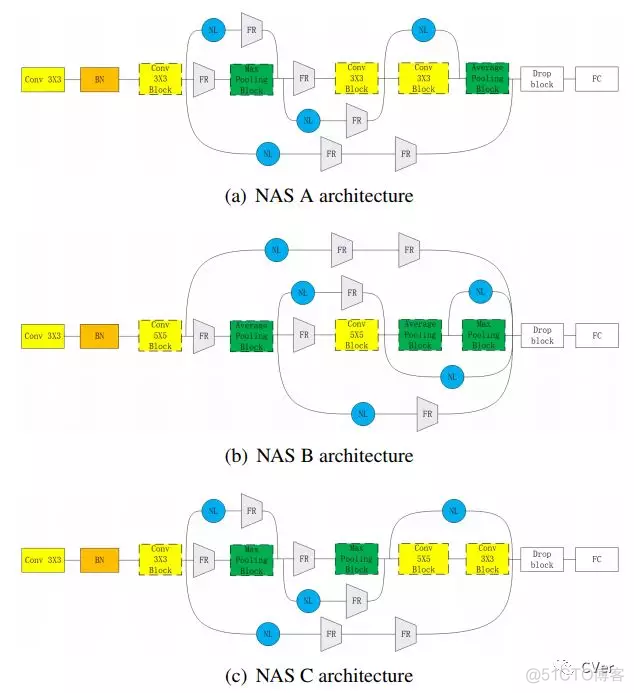
本文算法(NAS-A/B/C)流程图
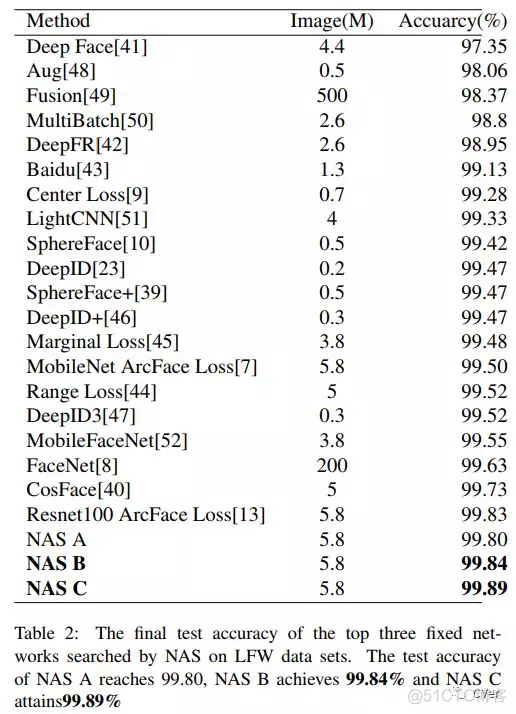
实验结果
NAS C 在MS-Celeb-1M数据集上可达98.77%准确率!

NAS C 在LFW数据集上可达99.89%准确率!
PoolNet
《A Simple Pooling-Based Design for Real-Time Salient Object Detection》

arXiv: https://arxiv.org/abs/1904.09569
github: http://mmcheng.net/poolnet/
作者团队:南开大学&新加坡国立大学&深圳大学
PS:程明明三作
注:2019年04月23日刚出炉的paper
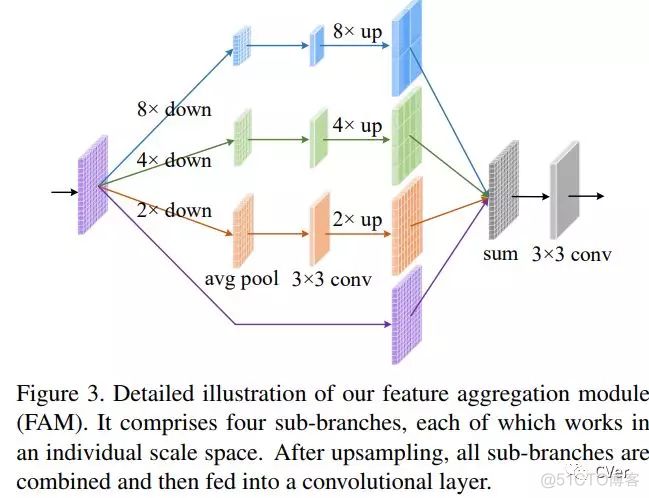
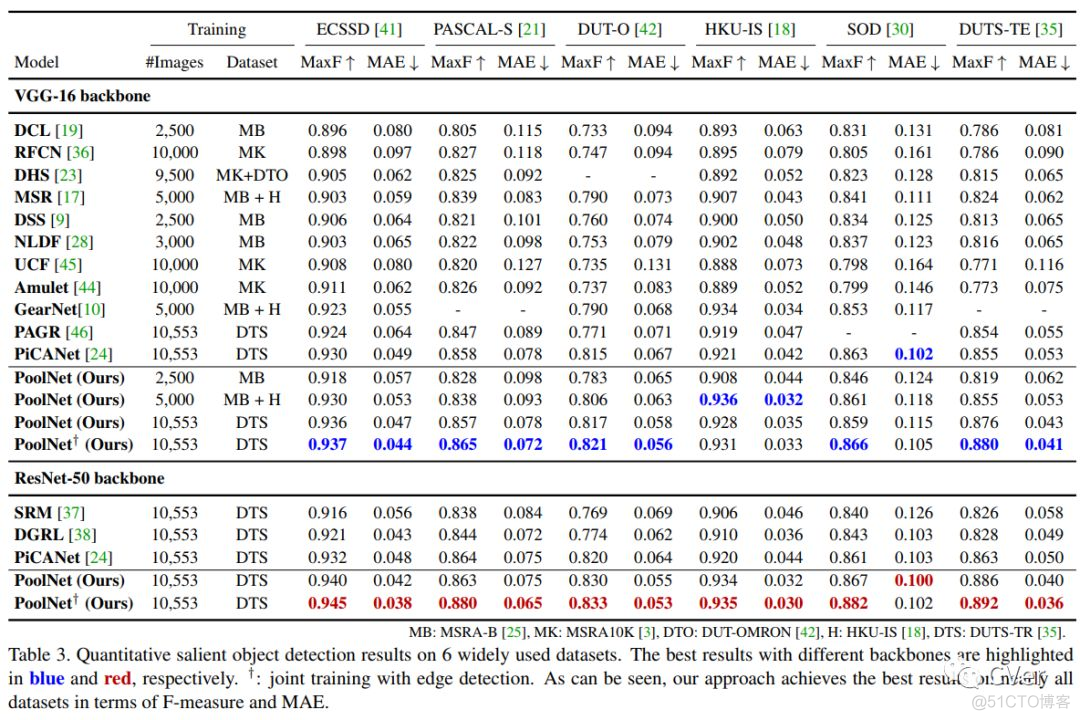
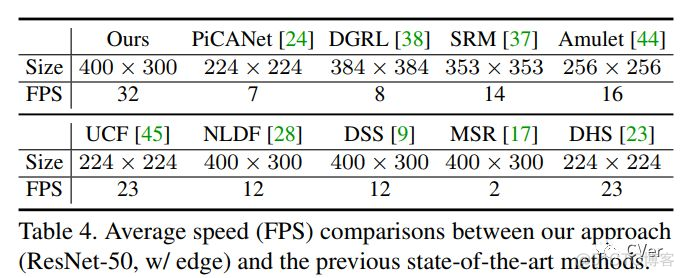
Abstract:我们通过研究如何扩展卷积神经网络中池化(pooling)的作用来解决显著目标检测问题。基于U形结构,我们首先在自下而上的路径上构建全局引导模块(GGM),旨在为不同特征层提供潜在显著目标的位置信息。我们进一步设计了一个特征聚合模块(FAM),使粗级语义信息与自上而下的路径中的精细级别特征完美融合。通过在自上而下路径中的融合操作之后添加FAM,来自GGM的粗略特征可以与各种尺度的特征无缝地合并。这两个基于池化的模块允许逐步细化高级语义特征,从而产生细节丰富的显著性映射。实验结果表明,我们提出的方法可以更精确地定位具有锐化细节的显著对象,因此与先前的现有技术相比显著改善了性能。我们的方法也很快,并且在处理300×400图像时可以以超过30 FPS的速度运行。
本文算法(VoteNet)流程图
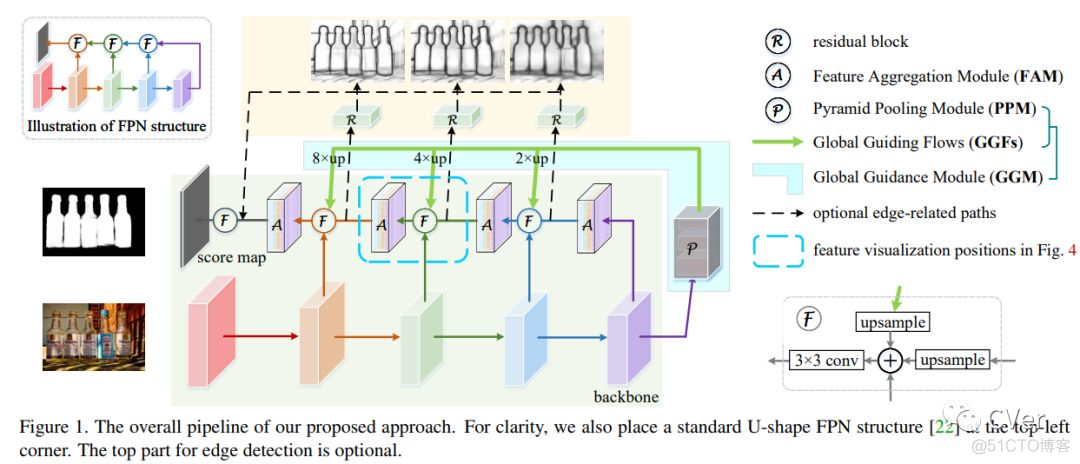
特征聚合模块(FAM)
实验结果
400×300,32 FPS 舒服!

想要了解最新/最快/最好的论文速递、开源项目和干货资料,欢迎加入CVer学术交流知识星球。目前已有410+同学加入,涉及图像分类、目标检测、图像分割、人脸检测&识别、目标跟踪、GANs、学术竞赛交流、Re-ID、风格迁移、医学影像分析、姿态估计、OCR、SLAM、场景文字检测&识别和超分辨率等方向。
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。










暂无评论内容