


#DDMPC-for-AV-steering
同济大学 | 用于自动驾驶汽车转向的数据驱动模型预测控制
- 论文链接:https://arxiv.org/pdf/2407.08401
- 项目主页:https://john0915aaa.github.io/DDMPC-for-AV-steering/
摘要
本文介绍了用于自动驾驶汽车转向的数据驱动模型预测控制。随着自动驾驶技术的发展,对车辆控制的要求越来越高,MPC已经成为工业界和学术界广泛研究的主题。现有的基于车辆运动学或者动力学的MPC控制方法存在建模困难、参数众多、非线性强以及计算成本高等挑战。为了解决这些问题,本文提出了一种用于自动驾驶汽车转向的数据驱动MPC控制方法。该方法避免了复杂车辆系统建模的需求,并且以相对较低的计算时间和较小的误差实现了轨迹跟踪。本文通过Carsim-Simulink仿真验证了所提出的算法在特定场景下的控制效果,并且与PID和车辆运动学MPC进行比较分析,证明了所提出算法的可行性和优越性。
主要贡献
本文的贡献总结如下:
1)本文基于自动驾驶汽车的特性,通过修改和设计现有算法,提出了一种用于汽车转向的数据驱动模型预测控制算法;
2)本文通过仿真实验验证了DDMPC应用于自动驾驶汽车转向的可行性,并且通过与其它算法的比较证明了该算法的优越性。
论文图片和表格
总结
本文研究并且实验验证了所提出的用于自动驾驶汽车转向控制的数据驱动MPC算法。实验表明,该算法可以实现稳定的前轮角度控制来跟踪参考轨迹,并且与传统的MPC算法相比,它有效地降低了控制误差和计算时间。
本文今后的工作将着重于增强算法的鲁棒性和实时性,以进一步改进其在各种驾驶条件下的有效性。
#端到端~
“要么拥抱端到端,要么几年后离开智驾行业。”
特斯拉率先吹响了方案更新的号角,无论是完全端到端,还是专注于planner的模型,各家公司基本都投入较大人力去研发,小鹏、蔚来、理想、华为都对外展示了其端到端自动驾驶方案,效果着实不错,非常有研究价值。
为什么需要端到端?
首先我们聊一下当前的主流自动驾驶方案,主要核心部分包括:感知模块、预测模块、规控模块。每个模块相对独立,感知模块给预测模块提供动静态障碍物信息;预测模块为规控模块提供规划的参考,规划再转换为控制指令。从传感器端到控制端,需要多个功能支持,这就不可避免导致了累积误差,一旦碰到问题,需要整个pipeline做分析。而且每个模块的优化,并不能保证整个系统达成最优解。

这个时候,就希望有一种模型能够完成感知信息的无损传递,即从传感器端到输出控制策略端,这也是端到端自动驾驶提出的原因。传统定义上感知和规划模块的对接一般是通过白名单(比如机动车、行人、甚至occ输出的非通用几何障碍物)的检测与预测来完成,是人为定义的规则和抽象。随着产品的迭代,每一次都需要添加各类case,设计各种博弈的策略,从模型训练到工程部署再到逻辑设计,时间和人力成本高昂。
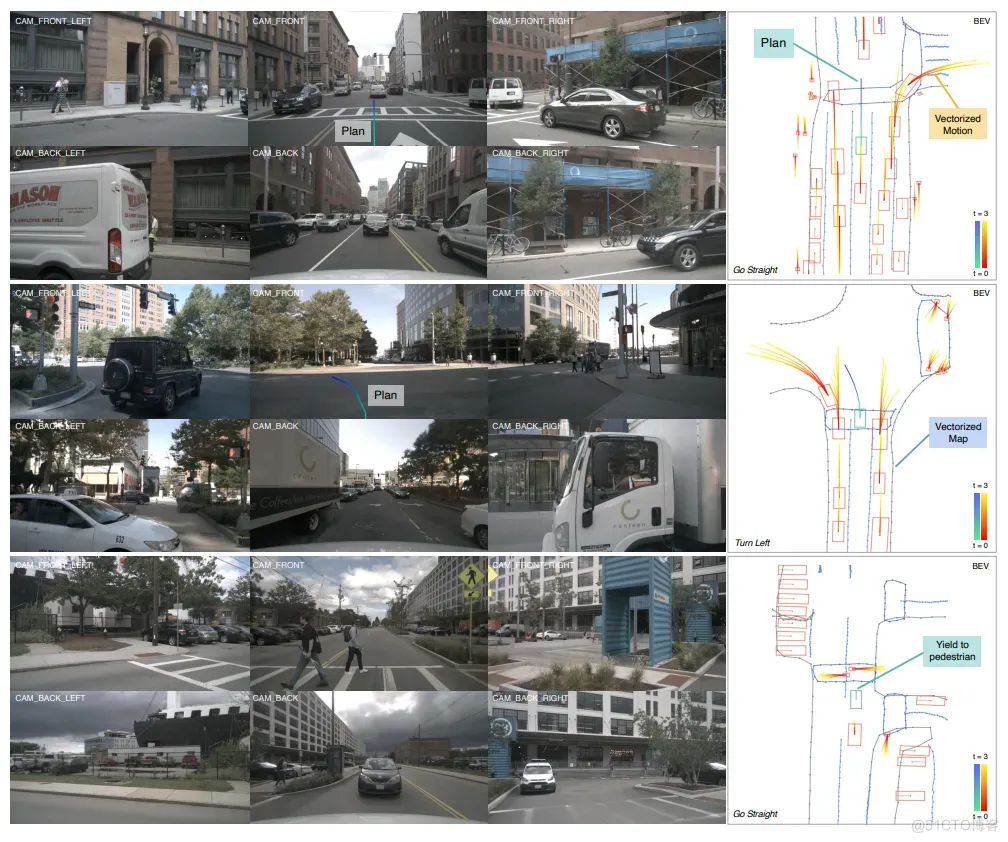
而且这种方式无法罗列所有情况,那么是否可以通过对整个场景的学习抽象,无损的将所有信息传递给PnC部分?这就是我们期望的端到端。端到端核心是优化最终目标且全局可导,作为一个完整的优化任务来看,直接求最优解,而不是先求感知再求规控的最优解。
端到端效果怎么样?
今年各大自动驾驶公司都在预研和落地相关端到端方案,小鹏、蔚来、华为、理想也都对外展示了其端到端方案。由于端到端模型的优势明显,各大自动驾驶公司都在拼命布局揽人,对应岗位薪资水涨船高,某想甚至开出了七位数给到该岗位。
那么各家的端到端自动驾驶效果怎么样呢?先来看看国外的特斯拉:
再来看看国内的UniAD效果:
不得不说,端到端是一个更简约的方法,更具有全场景的优化能力。
端到端有哪些技术栈?
行业里面的端到端主要分为完全端到端方案、专注于planner的端到端方案(包括某鹏的XPlanner)。顾名思义,完全端到端是从传感器直接到规控;而专注于planner的端到端以感知模块的输出作为先验,替换原来以规则作为主要形式的PnC模块。

从传感器到控制策略的(如果把条件再放松下也可以到轨迹输出)完全端到端方案更为简约,但同样面临一个问题,可解释性差。UniAD用分阶段监督的方法逐步提高了可解释性,但训练仍然是个难题。在足够体量和质量的数据群下,效果能够得到保证,泛化性能也不错。

而专注于planner的端到端方案,如果深究的话,只能算狭义上的端到端,但更贴合当下的量产方案和任务,而且可解释性也较高,是目前主机厂和自动驾驶公司优先推行和落地的。
如果从信息输入的角度上来看,又可以分为纯视觉方案(UAD、UniAD这类)
和多模态方案(FusionAD这类),传感器成本不断在下降,多模态方案也一直是行业里面都在关注的点。
端到端的难点在哪里?
端到端的优势非常突出,但仍然有很多难点需要攻克。主要在于数据难定义、数据难制作、网络不好训练、模型不好解释优化、评测定义多种多样!很多公司无法像特斯拉一样获取海量数据,这也是个巨大的瓶颈。今年年中,自动驾驶之心收到了很多同学关于端到端实战相关的需求,虽然我们已经筹备过相关的内容,但早期端到端方案不够成熟,更多是以论文切入。工业界使用的方案关注较少,代码层面上也很少提及。
从基础问题,到当下大热的端到端路径规划
1资本市场狂欢下的机器人产业
以前段时间刚发布了,号称“地表最先进”人形机器人 Figure 02 的初创公司 Figure AI 为例,其背后的资方几乎占据了硅谷的半壁江山。
Figure AI 的背后就除了有大名鼎鼎的Open AI,还有微软、亚马逊、英特尔资本、LG和三星等诸多知名科技巨佬。
国内的云深处(四足机器人公司)前几天宣布完成B+轮融资,作为全球四足机器人五大厂商之一,本次投资方包括华建函数投资、涵崧资管、深智城产投、莫干山高新投资等机构。
光说这几家的名字可能有部分人觉得不熟悉,但他们背后几乎都有国资机构的身影。而且在云深处的这几轮融资中,国资机构可谓是出现得越来越频繁了。
足以可见无论是国内外,资本市场对于机器人产业腾飞的看好,以及政策、股市释放出的诸多利好信号。
2移动机器人技术的发展
路径规划是机器人技术中的关键过程,同时在自动驾驶和物流配送等领域发挥着重要作用。
因此,本次我们重点聊聊移动机器人的运动规划问题。
1、基础问题:训练效率与组合优化
在路径规划中,训练效率和复合优化是两大挑战。
训练效率:在机器学习特别是强化学习应用于移动机器人路径规划时,训练效率是核心挑战之一。算法需要在有限的时间内学习复杂的环境交互,以达到高效导航。研究者通过设计更高效的探索策略、利用迁移学习和多任务学习等方法,来加速模型的收敛,减少训练时间和资源消耗。
组合优化:移动机器人路径规划中的组合优化问题,如寻找最短路径、避开障碍物的同时考虑多目标约束,是一个NP-hard问题。采用启发式算法(如遗传算法、模拟退火、A*搜索等)和混合整数规划方法,可以在保证一定解质量的同时,提高求解速度,实现路径的优化。
关于这一问题,西北工业大学引入了高效渐进策略增强(EPPE)框架,该框架结合了稀疏奖励的优势,旨在为智能体实现全局最优策略,同时提供过程奖励以实时反馈智能体的策略调整。此外,还提出了增量奖励调整(IRA)模型,以逐步增加复合优化部分的奖励权重。支持IRA模型的微调策略优化(FPO)模型在整个过程中逐步调整学习率。
对于他们这项工作有兴趣的朋友,可以在8月13日晚和西北工业大学航空宇航科学与技术专业的赵望同学进行进一步深入探讨(其论文在控制会议上发表并获得杰出论文)。
2、集群规划问题
在移动机器人运动规划中,还有一个经久不衰的问题,那就是集群规划。
在集群规划中,多个移动机器人需要协同工作,完成复杂任务,如搜索与救援、货物运输等。这要求机器人之间有高效的通信机制和协调策略,以避免碰撞、优化整体路径和任务分配。研究重点包括分布式规划算法、多机器人协同策略以及动态环境下的自适应调整。
在传统轨迹优化中考虑避碰可以实现集群的流畅飞行。
然而,在高通信延迟和快速机动时,其难以实现较高的机间避碰频率。集中式轨迹规划可以释放大量算力用于集群感知、定位和决策,而高频率分布式避碰控制则更适用于通信延迟和快速机动的场景。
因此,关于这一问题也值得技术研究人员,深入探讨。
3、端到端路径规划
近年来,端到端(End-to-End)学习在移动机器人路径规划中的应用是一大热点。这种方法直接从传感器输入到行为输出进行学习,无需显式建模环境或规划中间步骤。
其中“端到端控制”是指模型输入传感器数据输出车辆的控制信号。
“端到端路径规划”是指模型输入传感器数据输出规划(预测)的路径点,然后用控制算法将这些点转化成车辆的控制信号。与常规的路径点生成方式不同。
8月份在慕尼黑工业大学主讲自动驾驶相关课程,指导二十多名硕士研究生完成论文研究的周立国老师将就“端到端路径规划”中路径点的链式生成,可以在许多场景下获得较好的规划效果,进行具体分享。
3深入移动机器人运动规划
得益于巨大的潜力市场、广阔的应用领域、政策的大力支持,使得【机器人赛道】这个万亿市场强势开启,其迅猛程度不亚于N年爆火的智能驾驶行业。
因此,本月深蓝学院特意筹办了【移动机器人运动规划】主题月,除了建立交流群供大家探讨之外,还邀请了三位研究不同细化方向的研究人员开设了3场直播交流分享,以期促进国内对于这一主题的研究与了解。
本次内容涵盖:从基础问题的研究(训练效率和组合优化),到经久不衰的集群规划问题,最后落到当下大热的端到端路径规划研究上。开发板商城 天皓智联 TB上有视觉设备哦 支持AI相关~ 大模型相关也可用 whaosoft aiot自动驾驶也可以哦
#OASIS SIM V3.0
AI重塑端到端自动驾驶仿真
亮点1:
独创的AI多智能体对抗技术,可规模化生成CornerCase(长尾场景)
OASIS SIM V3.0版本集成了深信科创独创的AI多智能体对抗行为模型,该模型通过AI技术可自动生成复杂的交通场景和对抗场景,在丁/十字路口场景、行人场景、车道加减等常见测试中,AI多智能体对抗行为模型的对抗有效率可达到≥96%,每发现一个算法bug(缺陷)/issue(问题)用时3-5分钟,显著提升了测试的速度和效率,大幅领先于传统的人工测试方法。

弯道处对抗

超车切入并紧急制动

多车对抗
亮点2:
高精度传感器模型,增强仿真有效性
OASIS SIM V3.0版本基于精确的物理模型,实现了多种传感器的高精度模拟,能够实现传感器采集层、模型层、协议层的全流程仿真。摄像头可模拟长焦、广角、鱼眼、双目等各种镜头类型,仿真畸变、运动模糊、晕光、过曝、脏污、噪声等特性。激光雷达模型通过对扫描特性、传播特性进行物理建模,实现运动畸变、 噪声、强度的模拟,可以仿真不同型号的激光雷达,并生成接近真实雷达的点云数据。

激光雷达仿真

摄像头仿真
亮点3:
兼容第三方软件场景,支持OpenSCENARIO标准格式场景文件导入,通信模块支持OSI接口
OASIS SIM V3.0增加了对部分第三方仿真软件场景文件的兼容性适配,支持导入OpenScenario标准场景文件,并自动转换场景文件信息,以确保场景执行的一致性。用户可以迁移存量场景库,或者从市场购买商业场景库,避免重复工作。
ASAM OSI可以为自动驾驶功能和驾驶模拟的多样性提供框架,允许用户通过标准化接口,连接任何自动驾驶功能和任何驾驶模拟器工具。OSI标准最大的特点是简化了集成性,进而显著增强了虚拟测试的可访问性和适用性。OASIS SIM V3.0在原有通信和接口调用的基础上新增了OSI适配,增加了算法接入、联合仿真、数据存储的便捷性。
亮点4:
实时多传感器仿真,支撑HIL测试
OASIS SIM支持主从架构部署,通过multiple-GPU实现多路摄像头、激光雷达的数据生成,长时间稳定运行,并且灵活扩展。OASIS SIM可与NI、dSPACE等实时系统以及CarSIM、ASM、CarMaker等进行联合仿真,充分支持多传感器配置下的HIL\VIL测试。

OASIS V3.0功能亮点
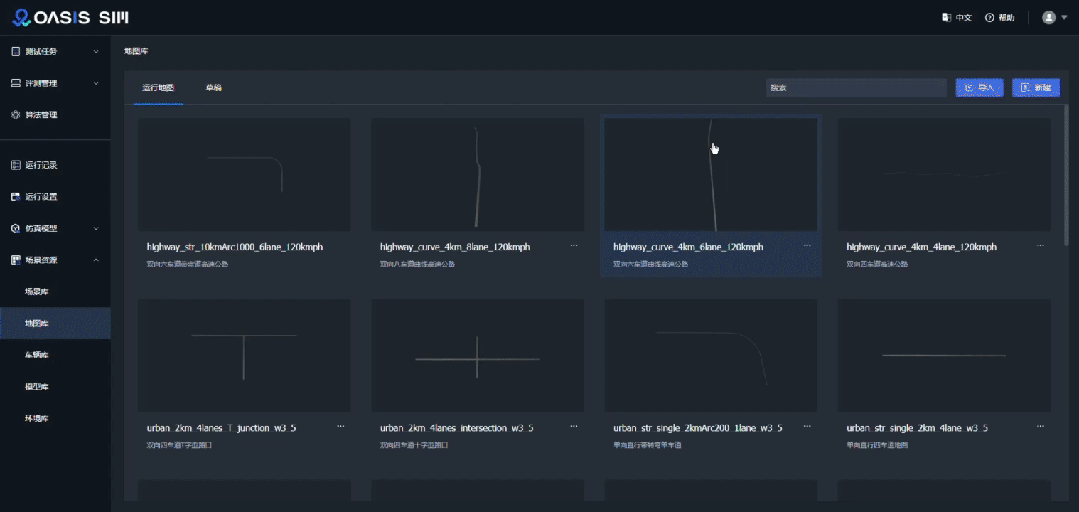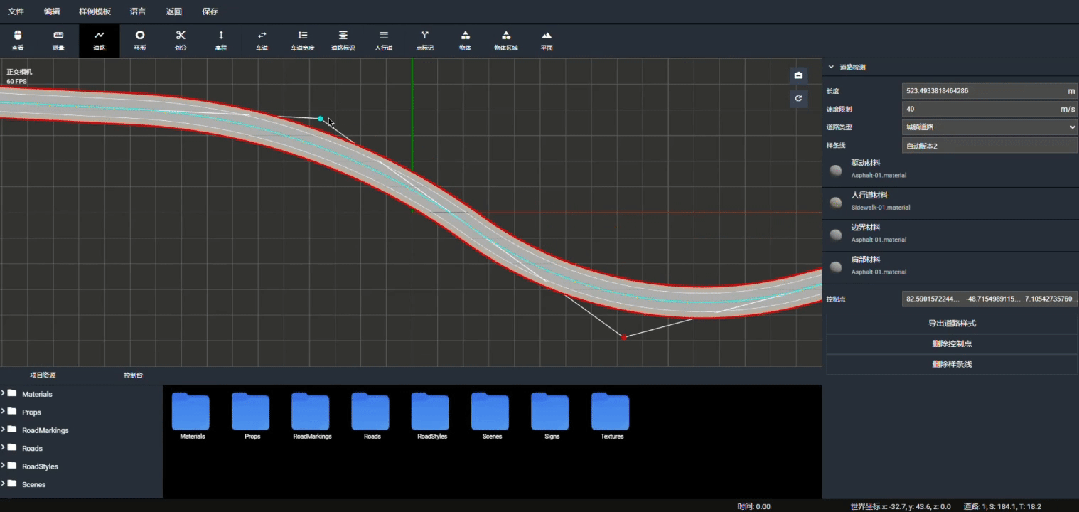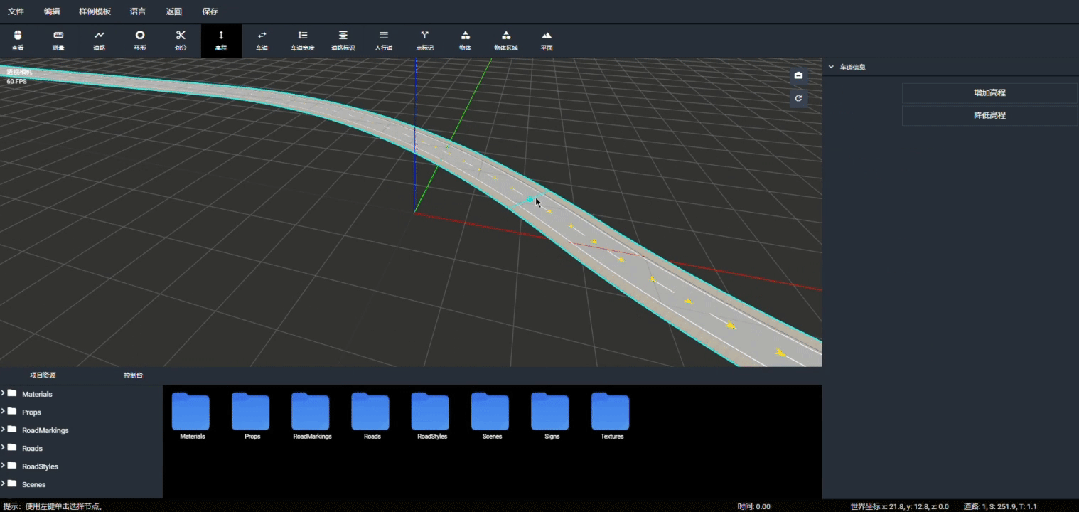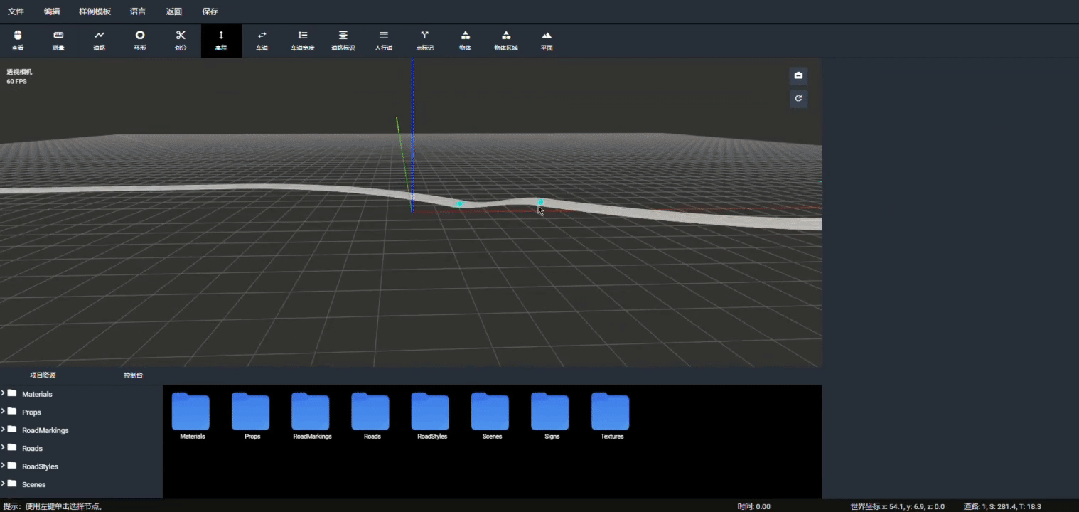
1、新增地图编辑器功能
OASIS SIM V3.0新增地图编辑器模块,支持3D图形化编辑与预览地图,功能包括有:
- 基础道路绘制:绘制直线、曲线、坡度和交叉路口等基础道路元素。
- 车道编辑:支持车道的增减和调整,可以根据仿真需求灵活设置车道数量和宽度。
- 坡度与倾角调整:精确控制道路的高程曲线以及道路倾角,模拟各种地形条件。
- 车道线与道路标识绘制:支持自定义车道线和道路标识,包括实线、虚线、双黄线等,以及各种交通标志和路面标记。
2、程序化场景生成
OASIS SIM V3.0支持直接导入OpenDrive文件,并自动识别和解析道路网络等关键信息自动化生成三维场景,无需复杂的建模和人工编辑,提高了场景构建的速度和效率。
3、新增高效便捷的工作台
工作台集成场景运行控制,快捷入口与运行记录三大功能模块,高效实现仿真场景运行管理与监控,为用户带来更便捷的操作与体验。
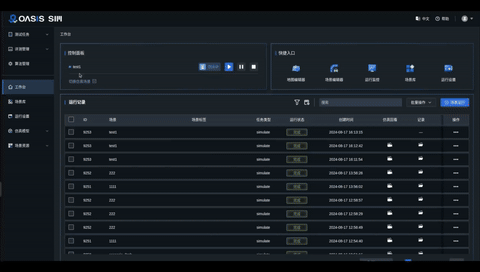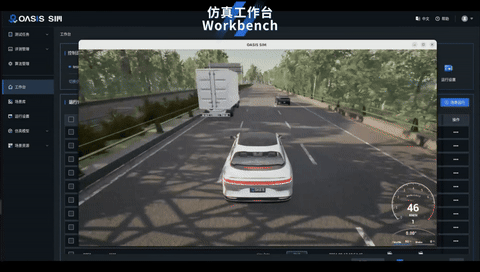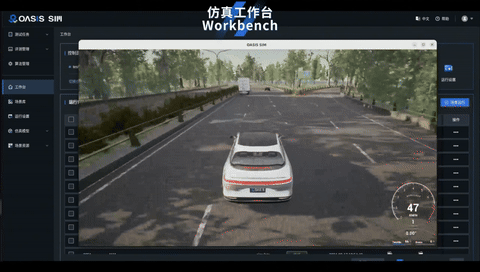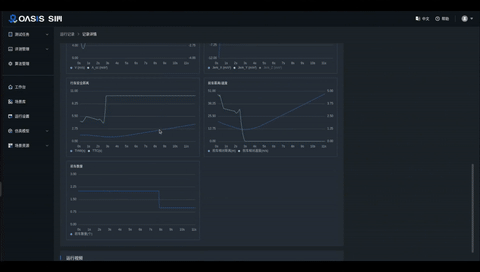
4、高效的测试用例管理与评测管理
为提高仿真场景的测试效率,OASIS SIM V3.0支持多选场景创建测试用例,并对运行结果进行记录,生成测试报告,帮助用户更快速地分析测试结果。平台提供用例的存储与检索功能,可随时查看每个用例的历史运行记录,对信息进行查看与追溯。
SYNKROTRON® OASIS SIM自动驾驶仿真平台,通过不断的技术创新和深入的用户反馈,提升仿真置信度、实时仿真的稳定性、场景生成的多样性、操作体验的友好性以及规模化部署的灵活性。我们致力于提供一款功能全面、可靠易用的仿真软件,支撑SIL/HIL/VIL测试,提高用户的测试效率和有效性,同时降低仿真测试的成本,助力自动驾驶技术的商业化落地。
#MV2DFusion
真正的多模态学习?北航&小米新作内容速览
- 提出了一个名为MV2DFusion的多模态检测框架,全面利用模态特定的目标语义,实现了全面的多模态检测。在nuScenes和Argoverse 2数据集上验证了框架的有效性和效率。
- 该框架能够灵活地与任何模态检测器配合使用,可以根据部署环境选择最合适的检测模型,以实现更好的性能。
- 由于融合策略的稀疏性,框架在远程场景中提供了一个可行的解决方案。
论文信息
题目:MV2DFusion: Leveraging Modality-Specific Object Semantics for Multi-Modal 3D Detection
作者:Zitian Wang, Zehao Huang, Yulu Gao, Naiyan Wang, Si Liu
机构:北京航空航天大学人工智能研究所和小米汽车
原文链接:https://arxiv.org/pdf/2408.05945v1
摘要
随着自动驾驶车辆的发展,对稳定精确的三维目标检测系统的需求日益增长。尽管相机和激光雷达(LiDAR)传感器各自具有其独特的优势——例如相机能提供丰富的纹理信息,而激光雷达则能提供精确的三维空间数据——但过分依赖单一的传感模态常常会遇到性能上的局限。本文提出了一个名为MV2DFusion的多模态检测框架,它通过一种先进的基于查询的融合机制,整合了两种传感器的优势。该框架引入了图像查询生成器来对齐图像特有的属性,并通过点云查询生成器,有效地结合了不同模态下目标的特定语义,避免了对单一模态的偏好。基于这些宝贵的目标语义,能够实现基于稀疏表示的融合过程,确保在多样化的场景中都能进行高效且准确的目标检测。作者所提出的框架在灵活性方面表现出色,能够与任何基于图像和点云的检测器集成,显示出其适应性以及未来发展潜力。在nuScenes和Argoverse2数据集上的广泛评估结果表明,MV2DFusion在多模态3D检测方面达到了最先进的性能,特别是在长距离检测场景中表现突出。
文章简介
自动驾驶车辆的发展极大地推动了对三维目标检测技术的需求。不同的传感器,如相机和激光雷达(LiDAR),基于其成像原理的不同,能够捕获现实世界中物体的不同特征。这些不同模态的固有特性使它们能够从不同的视角区分物体。例如,物体在图像中以富含纹理的像素区域呈现,而在点云中则以一组3D点的形式呈现。近年来,无论是基于相机的检测还是基于激光雷达的检测,都取得了显著的进展。然而,依赖单一传感模态的检测方法存在其固有的局限性。图像缺乏深度信息,无法指示物体的三维位置;而点云则缺少丰富的语义信息,且在捕捉远距离物体时因稀疏性而受限。
为了充分发挥两种传感模态的优势,研究者们提出了多模态融合方法,旨在结合两种模态的优势。当前的多模态融合方法主要分为两大类:特征级融合和提议级融合。特征级融合方法通过构建统一的特征空间,提取不同模态的特征以形成多模态特征体。例如,DeepFusion和AutoAlign利用点云特征查询图像特征,增强了点云特征的表示。BEVFusion将图像和点云特征转换到鸟瞰图(BEV)空间并进行融合。CMT不构建统一的特征空间,而是采用统一的注意力机制来聚合图像和点云特征。尽管特征级融合方法在目标识别和定位方面表现出直观的优势,但它们并未完全挖掘原始模态数据中嵌入的目标先验信息,有时甚至会在融合过程中损害强烈的模态特定语义信息。
与此相对,提议级融合方法利用特定于模态的提议,以最大限度地利用模态数据。例如,F-PointNet将检测到的图像边界框转换为截头锥体,以便从点云中提取物体。FSF和SparseFusion首先分别从图像和点云中生成提议,然后将它们统一为基于点云的实例表示,以进行多模态交互。然而,在这些方法中,表示往往会偏向于某一模态,如在FSF中相机提议主导了多模态融合过程,而在SparseFusion中,图像提议实质上被转换为与点云提议相同的表示。
为应对这些挑战,本文提出了一个名为MV2DFusion的多模态检测框架。该框架扩展了MV2D以纳入多模态检测,采用目标即查询的设计,便于自然地扩展到多模态环境。作者重新设计了图像查询生成器,使其更贴合图像模态的特性,引入了不确定性感知的图像查询,以保留图像中的目标语义,并继承了丰富的投影视图语义。通过引入点云查询生成器,作者还能够获取来自点云的目标语义,并将其与图像查询结合。然后,通过注意力机制进行融合过程,从而轻松地整合来自两种模态的信息。
本文提出的框架设计精心,充分利用了模态特定的目标语义,不受特定表示空间的限制。此外,它还允许集成任何类型的图像检测器和点云检测器,展示了框架的通用性和扩展性。得益于融合策略的稀疏性,作者的框架也适用于远程场景,避免了内存消耗和计算成本的二次增长。通过最小的修改,该框架还可以轻松地结合基于查询的方法,有效利用历史信息,如StreamPETR。作者在nuScenes和Argoverse 2等大规模三维检测基准上评估了作者提出的方法,实现了最先进的性能。
作者的贡献可以概括为:
- 提出了一个框架,全面利用模态特定的目标语义,实现了全面的多模态检测。在nuScenes和Argoverse 2数据集上验证了框架的有效性和效率。
- 该框架能够灵活地与任何模态检测器配合使用,可以根据部署环境选择最合适的检测模型,以实现更好的性能。
- 由于融合策略的稀疏性,框架在远程场景中提供了一个可行的解决方案。
总结来说,作者的方法在多模态三维检测方面取得了进步,提供了一个既稳健又多功能的解决方案,充分利用了相机和激光雷达两种传感模态的优势。
详解MV2DFusion
概述
图 1 展示了 MV2DFusion 的整体流程。该模型接收 个多视角图像和点云数据作为输入,并通过独立的图像和点云网络主干提取各自的特征。利用这些特征,模型分别应用 2D 图像检测器和 3D 点云检测器,得到各自的检测结果。然后,基于这些特征和检测结果,生成图像查询和点云查询,这些查询随后输入到融合解码器中。在解码器中,查询会整合两种模态的信息,进而生成 3D 预测结果。以下各节将详细描述每个部分的详细信息和设计原则。

图1. 提出的MV2DFusion框架结构。该模型接收多视图图像和点云作为输入,通过独立的图像和点云主干网络提取模态特征。同时,应用基于图像的2D检测器和基于点云的3D检测器于这些特征上,得到各自的检测结果。然后,根据模态特征和检测结果,由各自的查询生成器生成图像查询和点云查询。最终,这些查询和特征输入到融合解码器中,在查询更新后整合两种模态的信息,形成3D预测。
利用模态特定的目标语义
作者设计了一种融合策略,它能够在不偏向任何单一模态的情况下,挖掘并融合不同模态中的原始信息。具体来说,作者不是在 3D 空间中直接表示和融合整个场景,而是通过提取并融合各自模态的目标语义来进行多模态 3D 检测。这种策略不仅保留了每种模态的独特优势,而且通过稀疏性降低了计算成本和内存使用。
来自模态特定专家的目标提议
首先,作者分别对图像和点云模态采用独立的网络主干进行特征提取。图像模态通过带有特征金字塔网络(FPN)的图像主干网络,从多视角图像中提取出特征集合 。这些特征集合捕捉了图像中丰富的纹理信息,为2D检测任务奠定了基础。对于点云模态,点云主干网络则提取点云数据的体素特征 ,这些特征直接反映了物体在三维空间中的几何形状和分布。在特征提取阶段,图像分支和点云分支独立运作,没有进行信息交互,这样做的目的是为了保留每种模态信息的独特性质。
基于这些特征,作者进一步利用模态特定的检测专家来识别和生成目标提议。在图像分支中,作者可以使用任意结构的2D检测器,包括基于锚点或无锚点的检测器,以及两阶段或一阶段的检测策略。这些检测器为每张图像生成一组2D边界框集合 ,每个边界框由其在图像上的坐标 定义。而在点云分支中,作者采用稀疏检测器直接在体素上操作,这些检测器能够处理稀疏的三维数据,并生成一组3D边界框 ,每个边界框由其在三维空间中的位置和尺寸 定义。
通过这种独立且互补的方法,作者能够有效地整合来自不同模态的信息,为多模态3D检测任务提供了丰富的特征表示和精确的目标提议。这种策略不仅保留了每种模态的独特优势,而且通过稀疏性降低了计算成本和内存使用,为实现高效和准确的3D检测提供了可能。
从专家系统中提取目标级语义
尽管两种检测结果都为识别目标提供了宝贵的线索,但它们的表现形式本质上是不同的。基于点云的3D检测在3D空间中呈现,而基于图像的2D检测则在投影的2D空间中呈现。这种巨大的领域差异导致直接融合这些信息变得困难。在本文中,作者提出从检测结果中提取目标级语义信息,而不是直接融合原始的检测结果。
由于点云通常沿着目标表面分布,它们擅长准确捕捉目标的形状和姿态。但与点云不同,图像中无法直接推断出目标的3D姿态。相反,目标在图像平面中的分布可以作为3D定位的线索,考虑到投影原理。另一方面,图像像素可以描述具有丰富纹理的目标,即使在远处点云可能无法捕捉到目标的地方。
考虑到这些不同的特点,作者采用目标查询的形式来编码每种模态的目标级语义,然后可以无缝集成多模态信息。在现代基于变换器的检测框架中,每个目标查询通常由两部分组成:内容部分和位置部分。在获得基于图像的检测结果 和基于点云的检测结果 后,作者根据边界框和相应的模态特征构建目标查询。作者将在以下部分详细描述每种模态的目标查询生成过程。
点云目标查询的生成
在基于点云的3D检测中,检测结果直接在三维空间中给出,为此作者采用了表示目标实际位置的中心点 作为查询的位置部分。对于查询的内容部分 ,作者融合了外观和几何特征。点云查询由以下公式定义:
点云查询生成器的详细过程如图2所示。
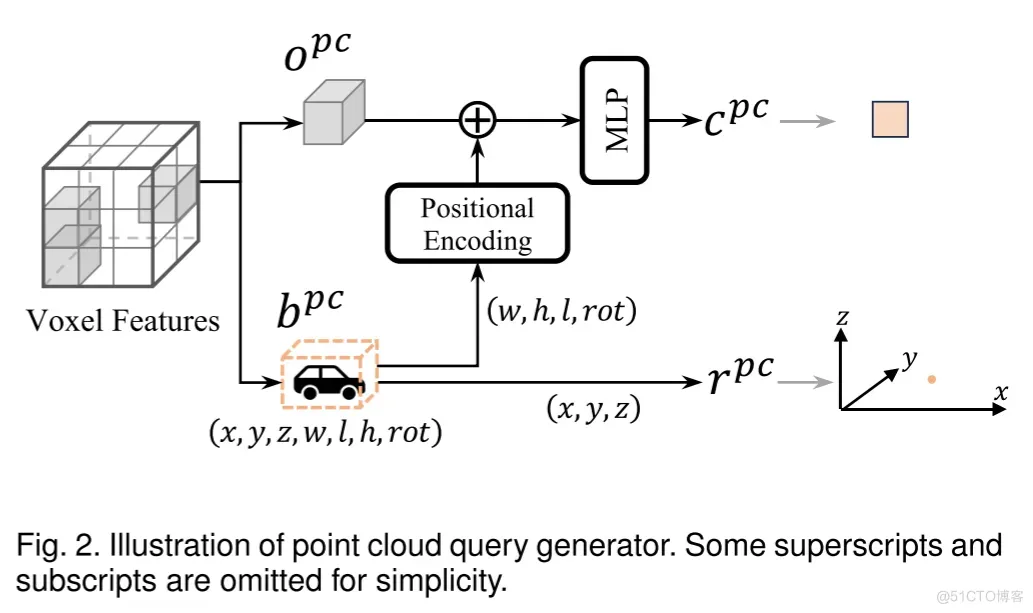
图2. 点云查询生成器的说明图。为简化起见,省略了一些上标和下标。
外观特征 的具体形式依赖于所使用的检测器类型。例如,在基于中心点的检测器中,外观特征是每个体素网格内的值;在两阶段检测器中,则是感兴趣区域(RoI)特征。在作者的实现里,使用的是一个稀疏点云的3D检测器,因此外观特征 即为体素特征,这些特征直接用于生成预测结果。几何特征则被视为目标的物理属性,例如大小和航向角,这些在检测结果 中有明确的表示。内容部分 的计算公式如下:
这里的 表示正弦位置编码,它负责将低维向量转换成高维特征以便于处理。
图像目标查询的生成
生成图像查询的一种直观方法是使用基于图像的3D检测器,并将检测到的目标实例转换为图像查询。这样,作者可以方便地获得与点云查询格式一致的图像查询,从而促进多模态之间的信息融合。然而,由于不同模态之间的固有差异,强制它们采用相同的查询格式可能会影响性能。特别是,从图像中估计深度存在一定的不确定性,这可能会导致3D预测出现较大的误差,进而影响图像查询的特征质量和定位准确性。为了解决这个问题,作者引入了一种新颖的基于2D检测的不确定性感知图像查询。
对于第个摄像机视图生成的查询,其内容部分是包含了几何信息的兴趣区域(RoI)外观特征。至于位置部分,作者不采用以往工作中的估计目标中心,而是保留图像中深度估计的不确定性。具体来说,作者通过概率分布而非确定值来表示查询位置。这些分布通过分类分布来建模,包括个采样位置及其对应的概率。
第个摄像机视图的图像查询表示为。所有摄像机视图的图像查询聚合为:
采用这种不确定性感知的图像查询表示,作者可以对目标位置做出初步估计,并减轻由相机到世界坐标系投影带来的误差。具体的处理流程如图3所示。
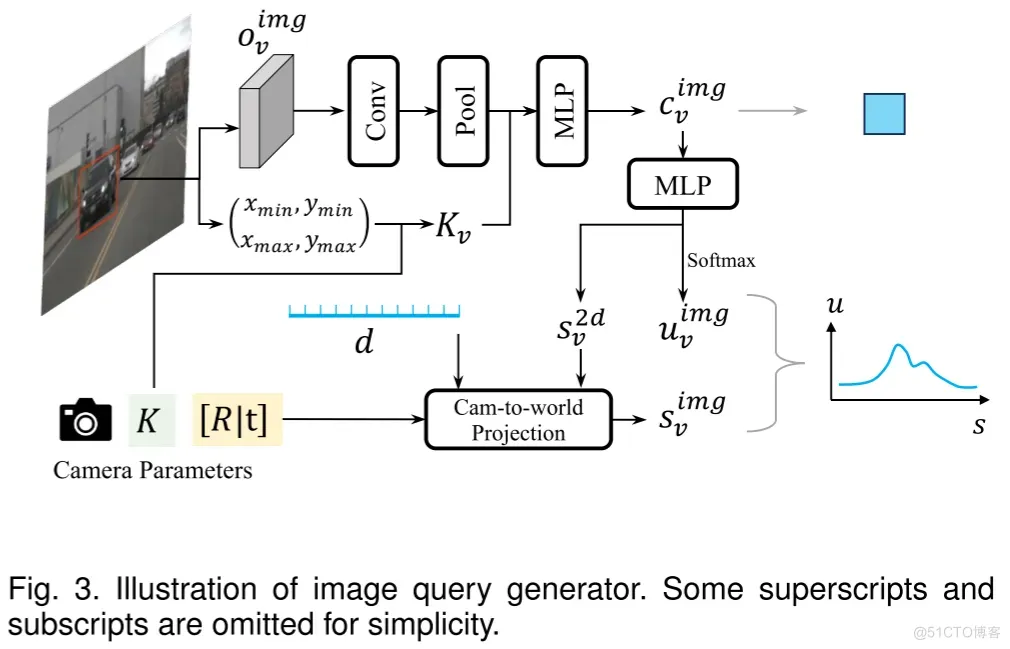
图3. 图像查询生成器的说明图。为简化起见,省略了一些上标和下标。
给定第个图像的2D检测结果和图像特征图,图像查询生成器首先通过RoI-Align提取RoI目标外观特征:
此外,作者还引入了相机内参矩阵以补充RoI-Align过程中丢失的几何信息。原始的相机内参矩阵表示为:
然后,作者定义从相机坐标系到第个2D边界框的投影的等效相机内参矩阵:
其中,。
图像查询的内容部分由外观特征和几何信息参数化:
至于位置部分,作者在预定义的深度范围内均匀采样得到深度集合。然后预测一组2D采样位置和相应的概率:
通过2D采样位置和深度值,作者可以得到3D采样位置,通过相机到世界坐标系的投影。
注意,基于分布的编码格式虽然与LSS有相似之处,但它实际上并没有将查询特征分布到3D空间中。这种编码方式不仅节省了计算资源和内存,而且在深度预测不准确时提高了模型的鲁棒性。此外,它还为后续进一步细化位置提供了机会,这将在后续部分进行讨论。
融合模态信息
本节介绍如何融合不同模态的信息以提升检测性能。作者借鉴了检测变换器(Detection Transformer, DETR)的思想,采用解码器结构进行模态信息融合和结果预测。该解码器包含L层,每层由自注意力模块、交叉注意力模块、层归一化、前馈网络和查询校准层组成。作者将点云查询 和图像查询 结合作为解码器的输入。初始输入查询表示为 ,经过第l层后的查询表示为 。
以下是各模块的详细描述:
自注意力机制
如公式(1)和公式(3)所述,模态查询具有不同的表达形式,即 和 。为使它们能够与标准的自注意力层兼容,作者保留了内容部分,并把位置部分转换成一致的表示形式。作者采用了位置编码(Positional Encoding, PE)方法和不确定性感知位置编码(Uncertainty-Aware Positional Encoding, U-PE)方法,分别为每种模态生成了位置编码 和 :
在位置编码(PE)中, 是从中心点
其中 SinPos 表示正弦位置编码。在不确定性感知位置编码(U-PE)中,作者先将 转换成基础位置编码 ,然后通过门控操作将概率分布 融合进
这里的 Flat() 是指展平操作, 表示元素级的乘法,σ 是 Sigmoid 函数。根据多头注意力(Multi-Head Attention, MHA)的标准表示 ,自注意力可以表达为:
其中 是 和 连接起来的位置编码,
跨模态注意力
尽管在自注意力层中仅通过查询间的信息交换已经能够得到相当不错的预测结果,实验表明,在变换器解码器中加入跨模态注意力层可以进一步带来性能上的提升,尽管这会使得模型的复杂度增加。跨模态注意力层的核心目标是整合各自模态特有的有用特征,以此来更新查询,这一过程在图4中有所展示。
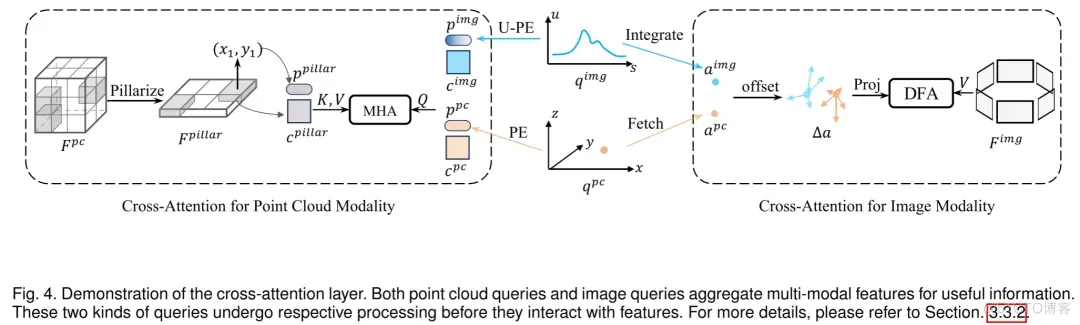
图4. 交叉注意力层的演示。点云查询和图像查询聚合多模态特征以获取有用信息。这两种查询在与特征交互之前各自经过处理。
对于图像特征的处理,作者采用了基于投影的可变形注意力机制。具体操作是,首先确定每个查询的锚点。对于点云查询,其锚点直接对应于它们的三维空间位置 。而图像查询的锚点 是根据概率分布 对采样位置 加权平均后得到的。对于第
基于投影的可变形注意力的计算方法如下:
在这个公式中,注意力权重 和偏移量 是根据内容部分 预测得到的。 代表采样点的总数, 表示从世界坐标系到相机坐标系的投影,而 代表查询的模态(可以是图像或者点云)。对于点云特征,如果模型接受的是BEV(鸟瞰图)形式的点云特征,可以采用类似的可变形注意力操作来实现信息交换。在当前实现中,点云特征 由稀疏体素构成,形成了一个完全稀疏的模型。在这种情况下,作者使用标准的多头注意力机制来聚合点云特征。通过柱状化(例如,沿高度方向进行平均池化)处理 以生成内容部分 。柱特征的位置编码 根据BEV位置
查询校准
通过参考其他查询和模态特征,每个查询能够对其代表的目标做出更加精确的描述。由于不同模态的特性差异,作者认为图像查询的位置信息相对不够可靠,而点云查询的位置信息则更为准确。为此,作者在每个解码器层之后对图像查询进行校准,利用更新后的特征来精细化图像查询的位置,并减少由于不确定性带来的影响。在这个过程中,仅对概率分布 进行细化,而保持采样位置 不变。具体来说,最新的概率分布
查询校准层的操作将会影响到位置编码 以及锚点 。
模型输出
经过最终解码层的处理,作者得到了目标查询 ,随后通过分类头和回归头对其进行处理,以产生模型的最终输出。具体来说,作者利用上下文特征 来计算分类得分 :
对于回归目标,作者关注的是目标的位置、尺寸、旋转以及在需要时的速度(包括 坐标、 表示的宽度、长度和高度,以及旋转角 和速度向量 )。回归过程基于上下文特征 和锚点
其中,
时序信息的利用
为了增强模型对时序信息的捕捉能力,作者采用了一种高效的基于查询的时序融合方法,该方法的计算成本极低。具体实施策略是,作者维护了一个大小为 的历史查询队列 来记录历史信息。在完成当前帧的预测任务后,作者将得分最高的 个目标查询加入到 中,使得这个队列能够反映过去 帧的历史数据。历史查询队列 随后被整合到自注意力层的处理中。首先,作者利用时间延迟 、自我姿态 以及速度
这里的 是一个小型网络,负责对相关的时间信息进行编码。变换后的查询
损失函数
在作者的MV2DFusion框架中,模态特定的查询生成器能够与任何类型的基于图像的2D检测器和基于激光雷达的3D检测器无缝配合。这些检测器可以无需任何结构或损失函数的修改即可集成进作者的模型。它们预先训练好,以提供动态查询的优良初始化,并可在训练阶段与作者的模型联合训练。在此,作者将基于图像的2D检测器的原始损失函数记作 ,基于激光雷达的3D检测器的原始损失函数记作 。对于融合解码器层的输出,作者继承了DETR中目标分配和损失函数的设计理念。作者采用匈牙利算法[62]来进行标签的分配,并使用焦点损失进行目标分类,以及L1损失进行边界框回归。最终的3D目标检测损失可以表示为:
除了目标检测的标准损失之外,作者还为图像查询生成器引入了额外的辅助监督,以改进深度估计。对于第 幅图像预测的2D边界框 以及从真实3D边界框投影得到的2D边界框 ,作者首先计算它们之间的成对交并比(IoU)矩阵 ,定义为 。如果2D区域 成功地与目标 匹配,那么由图像查询生成器输出的深度分布 将受到目标深度 的辅助损失
这里的CELoss代表交叉熵损失。MV2DFusion的总体损失函数整合了上述所有损失,表示为:
各种损失项的权重
实验分析
数据集
nuScenes
作者在 nuScenes 数据集上开展实验,该数据集包含1000个场景。每个场景均配备由6个摄像头捕获的RGB图像,实现了360度的水平视场,同时结合了激光雷达数据。数据集中涵盖了10个不同类别的140万个3D边界框。作者依据数据集提供的评价指标进行性能评估,包括平均精度均值(mAP)和nuScenes检测分数(NDS)。
Argoverse2
作者在 Argoverse 2(AV2)数据集上进行了大量远程检测实验,以证明作者模型在远程检测任务上的优势。AV2是一个大规模数据集,感知范围可达200米,区域大小为400米×400米。该数据集共包含1000个序列,其中700个用于训练,150个用于验证,150个用于测试。每个序列通过7个高分辨率摄像头以20Hz的频率和1个激光雷达传感器以10Hz的频率记录。AV2在评估中除了使用平均精度(mAP)指标外,还采用了综合检测分数(CDS),该分数综合了AP和定位误差。
实现细节
MV2DFusion 默认使用 Faster R-CNN 结合 ResNet-50 作为基于图像的2D检测器,以及 FSDv2 作为基于点云的3D检测器。在基于图像的2D检测中,作者限制每张图像最多检测60个目标,而在基于点云的3D检测中,允许最多检测200个目标。作者保留了模态检测器的原始流程和超参数,以凸显作者方法的通用性。融合解码器共包含6层。所有实验在8个 Nvidia RTX-3090 GPU 上进行。所有模型均采用 AdamW 优化器进行训练,权重衰减设为0.01,并采用余弦退火策略,初始学习率设为
在 nuScenes 验证集上的实验中,输入图像分辨率设为1600×640,体素尺寸为(0.2, 0.2, 0.2)。作者使用了 nuImages 的预训练权重用于基于图像的检测器,以及 nuScenes 的预训练权重用于基于点云的检测器。为了防止过拟合,作者将基于点云的检测器冻结。整个模型在 nuScenes 训练集上训练了24个周期。在 nuScenes 测试集上的实验中,作者将基于图像的检测器更换为 Cascade R-CNN 结合 ConvNeXt-L,并在 nuScenes 训练集和验证集上训练整个模型48个周期,以获得更好的性能。
对于 AV2 数据集,输入图像分辨率设为1536×1184,体素尺寸为(0.2, 0.2, 0.2)。作者使用了 nuImages 的预训练权重用于基于图像的检测器,以及 AV2 的预训练权重用于基于点云的检测器。整个模型在 AV2 训练集上训练了6个周期。
与现有方法的比较
作者将 MV2DFusion 与其它最先进方法进行了比较。在 nuScenes 测试集和验证集上的结果分别展示在表1和表2中,而 AV2 验证集上的结果展示在表3中。
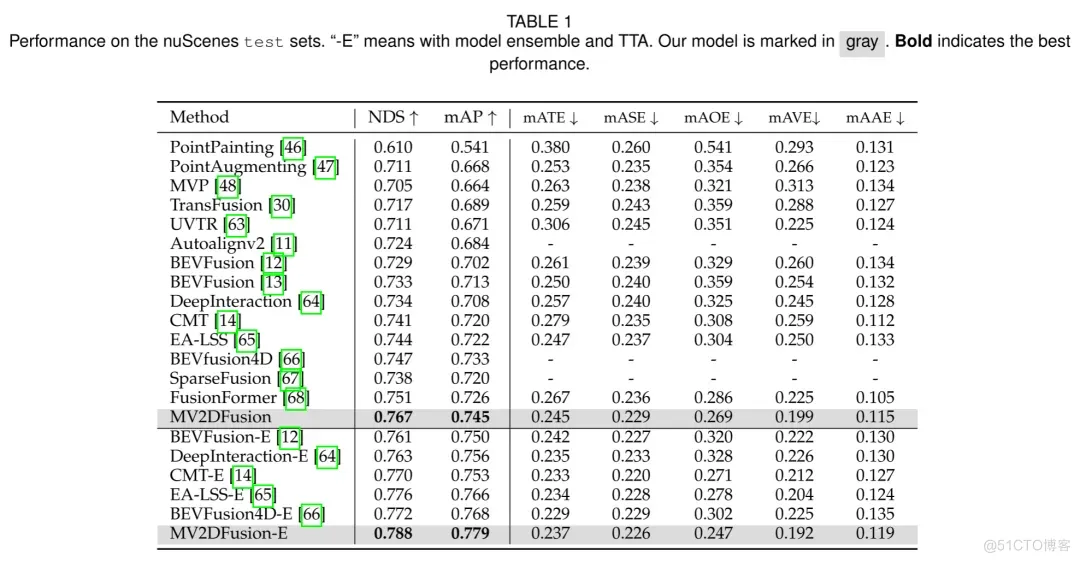
表1. nuScenes测试集上的性能对比。”-E”表示模型集成和测试时增强。作者的模型以灰色标出,加粗表示最佳性能。
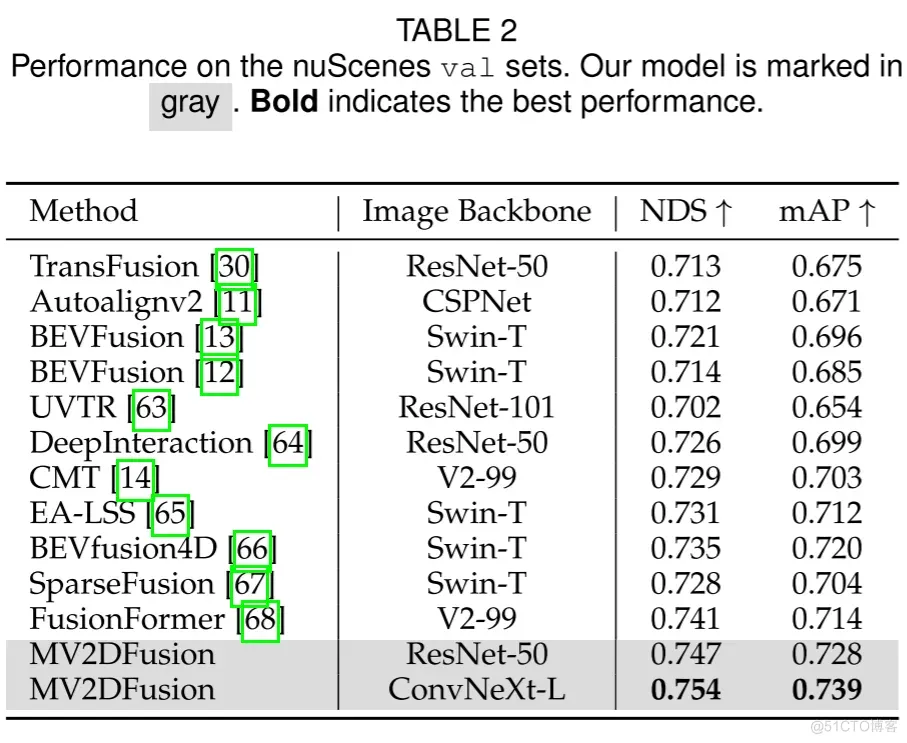
表2. nuScenes验证集上的性能对比。作者的模型以灰色标出,加粗表示最佳性能。
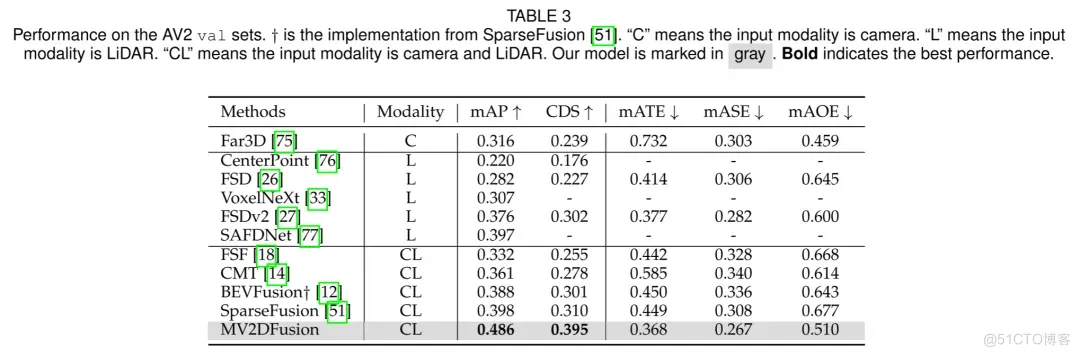
表3. AV2验证集上的性能对比。†表示SparseFusion 的实现。”C”表示输入模态为相机,”L”表示输入模态为激光雷达,”CL”表示输入模态为相机和激光雷达。作者的模型以灰色标出,加粗表示最佳性能。
在 nuScenes 测试集上,作者的单模型方法达到了76.7%的 NDS 和 74.5%的 mAP,超越了所有先前的方法。与 FusionFormer相比,作者在 NDS 上提高了 1.6%,在 mAP 上提高了 1.9%。此外,与稀疏结构的 SparseFusion相比,作者在 NDS 上提高了 2.9%,在 mAP 上提高了 2.5%。在模型集成的情况下,作者的模型达到了 78.8%的 NDS 和 74.5%的 mAP,位列所有解决方案之首。这些结果展示了作者的模型在多模态3D检测性能上的显著优势。
在 nuScenes 验证集上,作者的模型使用 ResNet-50 作为主干网络,达到了 74.7%的 NDS 和 72.8%的 mAP。当使用 ConvNeXt-L作为主干网络时,性能提升到了 75.4%的 NDS 和 73.9%的 mAP。值得注意的是,即使使用了较弱的 ResNet-50主干网络,作者的模型也已经超越了当前的最先进水平。
在 AV2 数据集上,作者的方法达到了 48.6%的 mAP 和 39.5%的 CDS,显著超过了先前的方法。与基于激光雷达的最先进方法 FSDv2相比,作者的模型在 mAP 上提高了 10.6%,在 CDS 上提高了 9.3%。与多模态方法 SparseFusion相比,作者的性能提升了 8.8%的 mAP 和 8.5%的 CDS,并且在 mATE、mASE 和 mAOE 指标上也有显著的改进,证明了作者的方法在远程场景中的优越性能。
消融研究
本节中,作者在 nuScenes 验证集和 AV2 验证集上对 MV2DFusion 进行了消融研究。实验默认在 nuScenes 数据集上进行,除非另有说明。
图像分支的灵活性
MV2DFusion 兼容任何类型的2D和3D检测器。为了验证图像分支的灵活性,作者在表4中展示了不同检测器、不同图像分辨率和不同主干网络的实验结果。作者测试了三种2D检测器,包括单阶段检测器 YOLOX、双阶段检测器 Faster R-CNN和多阶段检测器 Cascade R-CNN。#2 至 #4 行展示了不同2D检测器的实验结果,证明了作者的框架能够适应不同类型的2D检测器。此外,通过比较 #1 和 #2 行,可以观察到更大的图像分辨率可以带来性能上的提升。从 #4 行和 #5 行的比较中可以看出,使用更强大的图像主干网络可以进一步提升性能,这表明在多模态环境中利用图像信息的重要性。
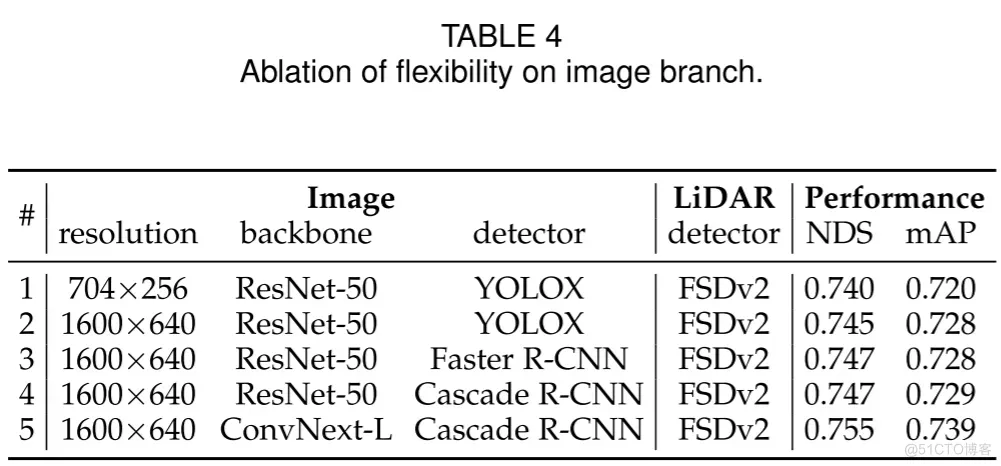
表4. 图像分支灵活性的消融研究。
激光雷达分支的灵活性
在表5中,作者比较了不同激光雷达检测器在模型分支上的表现。作者实验了包括两个稀疏检测器 FSDv2和 VoxelNeXt,以及一个密集BEV检测器 TransFusion-L在内的主流基于点云的3D检测器。实验结果表明,这些不同的激光雷达检测器都能很好地适应作者的框架,其中 FSDv2和 TransFusion-L的表现略优。为了与作者提出的稀疏融合策略相适应,作者选择 FSDv2 作为默认的基于点云的检测器。

表5. 激光雷达分支灵活性的消融研究。
模态鲁棒性消融研究
模态鲁棒性是融合方法在模态传感器失效时维持性能的关键特性。在表6中,作者验证了模型的模态鲁棒性。#1 行列出了在训练和评估中同时使用激光雷达和相机时的结果,这是作者的默认设置。#2 和 #3 行展示了在评估中缺少一种模态传感器的情况下的结果,尽管模型是使用两种模态训练的。相比之下,#4 和 #5 行展示了在训练和评估中使用相同模态传感器的情况下的结果。#2 和 #3 行的性能与 #4 和 #5 行相比有显著下降,这表明在传感器失效时存在较大风险。为了缓解这个问题,作者可以在训练中混合使用不同模态,即随机从[相机、激光雷达、相机和激光雷达]中选择输入模态,概率分别为[0.2, 0.1, 0.7]。如 #6 和 #7 行所示,在这种情况下,即使缺少激光雷达或相机传感器,模型仍然能够保持合理的性能。这些结果表明,通过增加单模态训练样本,可以有效地提高模态鲁棒性。将 #8 行与 #1 行进行比较,混合模态训练也在多模态场景中略微提升了性能。

表6. 模态鲁棒性的消融研究。”C”表示相机作为输入模态,”L”表示激光雷达作为输入模态,”CL”表示相机和激光雷达同时作为输入模态。
模态查询的消融研究
在本消融研究中,作者探讨了模态查询的不同表述方式对于模型性能的影响,结果详见表7。作者首先检验了在nuScenes和AV2数据集上,查询表述方式如何影响模型的表现。在图像查询中,作者沿用了MV2D中的点表达方式,即每个图像查询通过一个估算出的3D中心点来表示。在nuScenes数据集上,分布表达方式相较于点表达方式在NDS上提升了0.4%,在mAP上提升了0.3%,如表中的#1和#4行所示。而在AV2数据集上,分布表达方式的优势更加明显,CDS提升了2.2%,mAP提升了2.4%,如#5和#6行所示。这种性能上的显著提升可以归因于在长距离感知任务中,图像深度估计的困难性增加,此时点表达方式可能带来较大的误差。
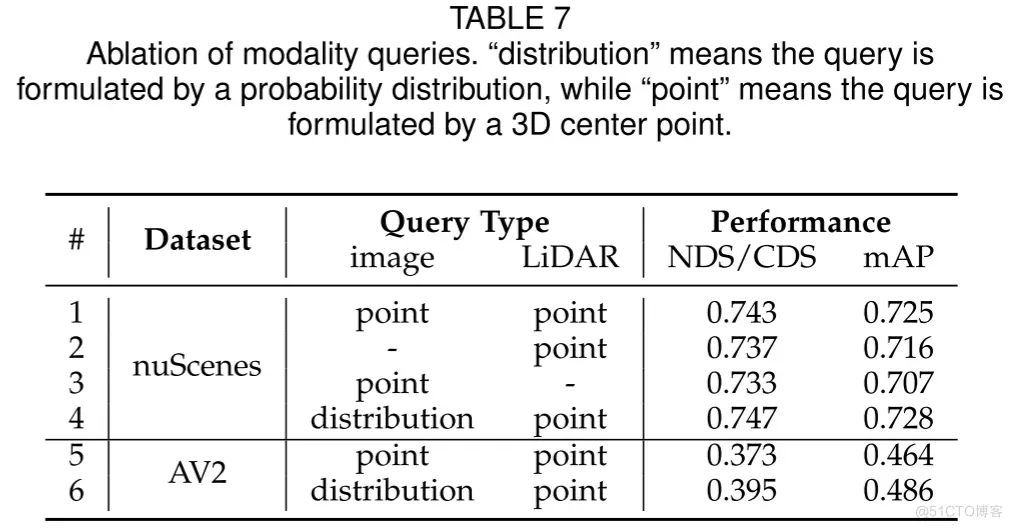
表7. 模态查询的消融研究。”distribution”表示查询通过概率分布制定,”point”表示查询通过3D中心点制定。
此外,作者还评估了仅使用单一模态查询(即只有点云或只有图像查询)时的性能。结果表明,与使用两种模态查询相比,仅使用单一模态查询会导致性能下降,如表中的#1至#3行所示。这一发现证实了不同模态查询在提升整体检测性能方面的重要作用。通过这些消融实验,作者得出结论,有效的模态查询设计对于多模态3D检测框架的性能至关重要,而合理的模态融合策略可以显著提升模型对不同感知任务的适应性和鲁棒性。
解码器结构的消融研究
在本部分消融研究中,作者探讨了解码器结构对模型性能的影响,详细结果见表10。作者首先在#1至#4行中考察了不同层数的解码器对结果的效应。观察结果表明,总体上随着解码器层数的增加,模型的准确度也随之提升。但当比较3层与6层解码器时,性能的增加相对较少,这暗示了在超过3层之后,额外的层数对性能提升的贡献有所降低。

表10. 解码器结构的消融研究。
作者还评估了解码器中跨注意力层的作用,如#4行与#5行所示。移除跨注意力层会导致模型的NDS性能下降0.7%,mAP性能下降1.3%,这一发现强调了跨注意力层在增强解码器性能方面的重要性。尽管如此,即使在没有跨注意力层的情况下,模型依然能够维持74.0%的NDS和71.5%的mAP,这表明即使仅依赖于查询级别融合,作者的框架也能够实现可观的性能,从而证明了多模态查询设计的效率和鲁棒性。
历史信息的消融研究
在表11中,作者展示了历史信息对模型结果影响的消融研究。第1行结果未考虑历史信息。当作者纳入前6帧的历史信息时(第2行),NDS和mAP分别显著提升了1.6%和1.7%。第2行与第3行的对比揭示了增加历史查询数量可以进一步提升性能。特别是,扩展到12帧的历史信息,能够带来额外的0.2% NDS和0.3% mAP的性能增益,这表明模型能够从更丰富的历史信息中获益。
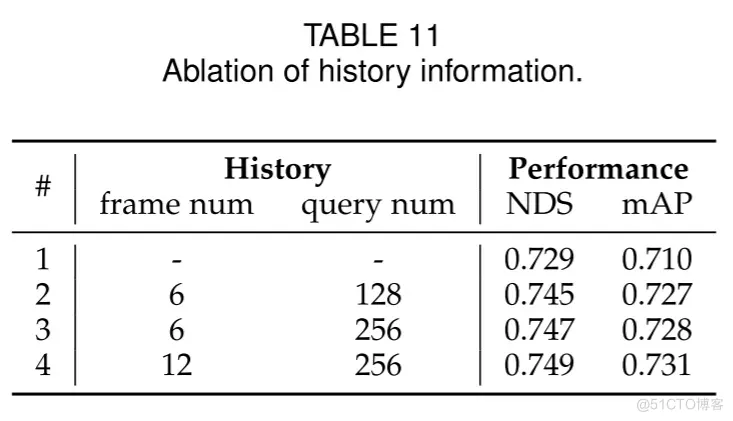
表11. 历史信息的消融研究。
内存成本比较
在表8中,作者对比了在nuScenes和AV2数据集上,作者的方法与传统的特征级融合方法BEVFusion的内存消耗情况。为了更全面地展示作者方法的效率,作者还实现了采用BEVPool V2技术的BEVFusion版本,该技术能显著加快视图变换过程。所有统计数据都是基于验证集的平均值。
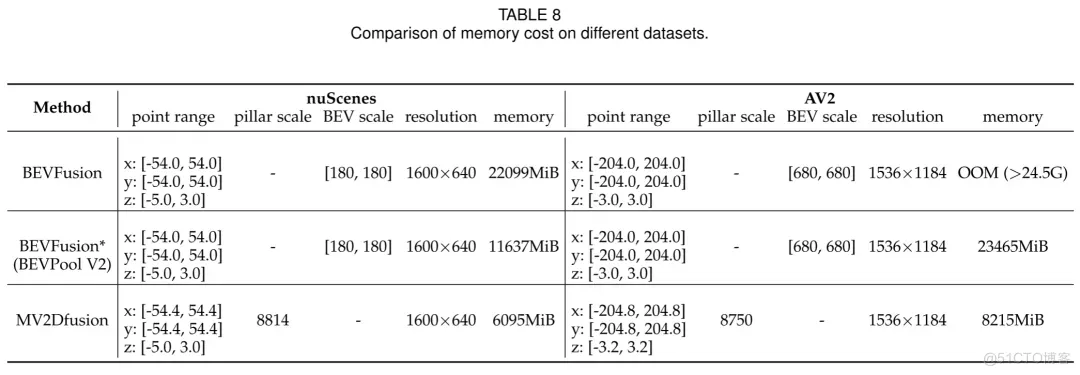
表8. 不同数据集上内存成本的比较。
作者的模型在点云分支中仅产生稀疏的柱状特征,相较于BEVFusion的密集BEV网格特征,其特征规模更小。具体来说,与使用BEVPool V2技术的BEVFusion相比,作者的模型内存需求仅为其一半左右。在AV2这样的长距离数据集上,作者的柱状特征规模远小于BEVFusion的密集BEV特征规模。在保持相同分辨率的情况下,BEVFusion的内存消耗超过了24.5GB,而采用BEVPool V2的BEVFusion需要23.4GB的内存。相比之下,作者的模型仅需8.2GB的内存,大约是BEVFusion采用BEVPool V2版本内存成本的35%。这些结果证明了作者稀疏融合策略在内存消耗上的巨大优势。
推理速度测试
在表9中,作者评估了在两种不同配置下的推理速度:一种是nuScenes数据集的小分辨率图像和短感知范围,另一种是AV2数据集的大分辨率图像和长感知范围。测试的FPS是在批量大小为1的情况下进行的,并基于验证集的平均值。在nuScenes数据集上,尽管作者的模型与采用BEVPool V2的BEVFusion在点范围和图像分辨率上相近,作者的推理速度仍快于BEVFusion 25%(5.5 FPS对比4.4 FPS)。在资源需求更高的AV2数据集上,作者的稀疏模型显示出更显著的速度优势,在这种长距离感知场景中,作者的FPS是BEVFusion*的两倍(2.0 FPS对比0.9 FPS)。

表9. 不同数据集上推理速度的比较。
定性结果
作者通过图5展示了查询的可视化,以直观地理解模态特定的目标语义的互补性。真实目标以位于其中心的红色三角形表示。点云查询以蓝色圆圈表示,位于每个目标的中心点 。图像查询以橙色线段表示,线段的位置指示采样位置 ,颜色的饱和度反映了概率分布 。可视化结果表明,尽管在3D空间中查询较为稀疏,但它们仍然倾向于围绕物体分布,使得能够准确识别物体。此外,这些查询展示了它们在定位物体方面的不同能力:图像查询能够识别一些由于点云稀疏而未能检测到的物体(例如,在较远距离处)。同时,点云查询包含的3D信息有助于在拥挤场景中准确定位和区分物体,即使在图像查询难以实现这一点时。
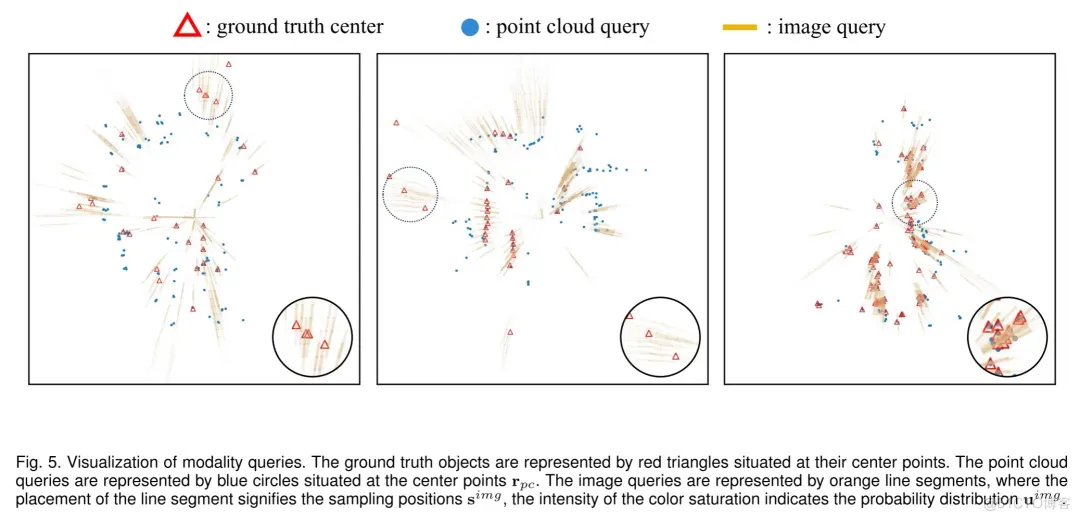
图5. 模态查询的可视化。真实目标以位于其中心的红色三角形表示,点云查询以位于中心点 的蓝色圆圈表示,图像查询以橙色线段表示,线段位置指示采样位置 ,颜色饱和度反映概率分布 。
为了验证作者的查询校准设计,作者计算了图像查询位置与匹配的真值(Ground Truths)之间的均方误差(MSE),如图6所示。观察到随着解码器层的深入,MSE逐渐减小,这表明作者的查询校准能够逐步细化图像查询的位置。
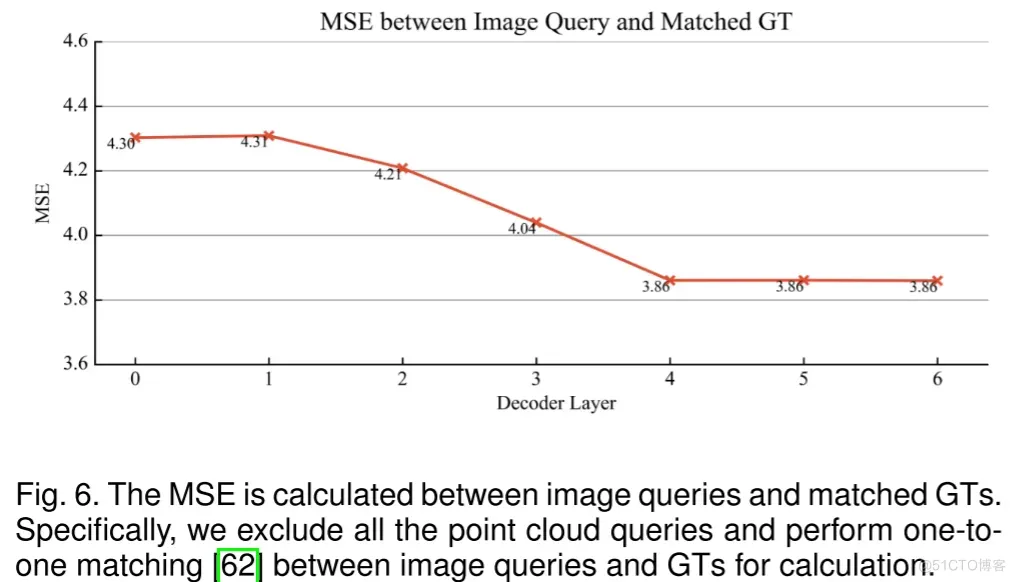
图6. 计算图像查询与匹配的真实目标(GTs)之间的均方误差(MSE)。特别地,作者排除了所有点云查询,并在图像查询和GTs之间进行一对一匹配以计算MSE。
此外,作者在图7中展示了在nuScenes验证集上的预测结果可视化。可以看出,MV2DFusion能够检测到包括行人、车辆、障碍物、交通锥等在内的多种物体。

图7. nuScenes验证集上的预测结果可视化。

结论
本文提出了MV2DFusion,这是一个先进且高效的多模态目标检测框架。继承了前作MV2D将目标视为查询的核心理念,MV2DFusion进一步引入了针对不同模态特性设计的目标检测器,用以生成针对性的目标查询。随后,框架利用一个交叉注意力解码器,整合了来自激光雷达和图像数据的特征,以预测最终的检测结果。这种设计不仅保证了与多种图像及激光雷达检测器的兼容性,还因其融合过程的稀疏性,使得模型能够适应长距离的检测任务。作者在nuScenes和Argoverse 2等多个数据集上对框架进行了广泛的验证,证明了其相较于当前最先进方法的卓越性能。作者期望MV2DFusion的设计能够为多模态目标检测框架在学术研究和实际应用中的进一步发展做出贡献。
#Panacea++
升感知多项任务性能!自动驾驶全景可控视频生成
自动驾驶领域对高质量标注视频训练数据的需求日益增长。基于早期Panacea工作,本文提出了Panacea+,一个强大且普遍适用的框架,用于生成驾驶场景中的视频数据。在之前的工作Panacea的基础上,Panacea+采用了一种多视角外观噪声先验机制和超分辨率模块,以增强一致性并提高分辨率。广泛的实验表明,Panacea+生成的视频样本极大地促进了不同数据集上的多种任务,包括nuScenes和Argoverse 2数据集上的3D目标跟踪、3D目标检测和车道检测任务。这些结果充分证明了Panacea+是自动驾驶领域一个有价值的数据生成框架。
领域背景介绍
在自动驾驶领域,鸟瞰图感知方法近年来引起了广泛的研究兴趣,在包括3D目标检测、地图分割、多目标跟踪和3D车道检测等关键感知任务中展现出显著潜力。通常,基于视频的BEV感知方法,如StreamPETR,在这些感知任务中,特别是需要理解视频序列中物体时间一致性的跟踪任务中,往往比基于图像的方法表现出更好的性能。为了实现优越的性能,这些基于视频的方法通常需要大规模、高质量的视频数据进行训练。然而,在实际场景中,获取此类数据面临着巨大挑战。传统的手动数据收集过程不仅成本极高,而且由于安全方面的考虑,还缺乏数据多样性。例如,在极端天气条件下收集数据几乎是不可能的。
鉴于上述问题,许多研究集中于合成可行的样本来扩充现有的自动驾驶数据集。一些努力集中在根据布局生成图像数据上。其它方法则解决了更为复杂的视频数据合成任务,以支持更先进的基于视频的感知方法。例如,MagicDrive 、DriveDreamer 和 Wovogen 都是基于鸟瞰图(BEV)布局序列生成视频样本的。之前的工作Panacea ,一个基于扩散模型的视频生成模型,也针对这一具有挑战性的任务。它能够根据鸟瞰图布局序列和文本控制信号,生成与驾驶场景对齐的高保真度多视角视频,有效地促进了检测任务中的感知模型性能。
然而,在变得更加实用之前,Panacea仍有改进的空间。在实际应用中,具有高时间一致性的合成训练数据至关重要,特别是对于依赖时间建模的任务(如跟踪)而言。在这方面,Panacea仍有增强的潜力。此外,已有研究表明,使用高分辨率数据训练感知模型可以显著提升性能。然而,Panacea目前生成的样本分辨率相对较低,为256×512。使用这样的合成数据来增强感知模型会限制其潜在性能的上限。
本文介绍了Panacea+,这是Panacea的增强版。Panacea+旨在将Panacea转变为一个更强大、更实用的数据生成框架,专为自动驾驶应用而设计。在Panacea结构的基础上,Panacea+集成了多视角外观噪声先验以增强一致性,并引入了超分辨率模块以实现更高分辨率的合成,如图1所示。Panacea+包括一个两阶段视频生成模型,该模型首先合成多视角图像,然后从这些图像中构建多视角视频。为了实现有效的多视角和时间建模,Panacea+采用了分解的4D注意力机制。在训练和推理过程中,引入了多视角外观噪声先验以增强一致性。为了实现可控生成,Panacea+通过ControlNet将鸟瞰图(BEV)布局作为控制信号进行集成。此外,在生成模块之后级联了一个超分辨率模块,以提高生成样本的分辨率。这些设计使Panacea+能够合成高质量、标注完善的多视角视频样本。
此外,在多个任务和数据集上进行了广泛的实验以进行全面验证。Panacea+被应用于nuScenes 和Argoverse 2 数据集,并在包括3D对目标跟踪、3D目标检测和车道检测在内的任务上进行了评估。这些实验结果表明,来自Panacea+的视频样本显著促进了感知模型的训练,在当前一代方法中达到了最先进的性能(SOTA)。卓越的性能验证了Panacea+对自动驾驶的重要价值。
综上所述,本文的主要贡献如下:
介绍了Panacea的改进版,名为Panacea+,这是一个数据生成框架,包括一个两阶段视频生成模块,该模块具有分解的4D注意力和多视角外观噪声先验,以实现一致性的生成,以及一个ControlNet以实现可控性。此外,还采用了超分辨率模块进行高分辨率合成。这种先生成低分辨率样本再扩展到高分辨率的成本效益高的框架,对于增强基于鸟瞰图(BEV)的感知模型非常有效。
除此之外,还进行了全面的评估以验证Panacea+的有效性。在广泛的设置下进行了大量实验,涵盖了多个数据集和任务。在当前的方法中,Panacea+精化了感知模型,在跟踪任务中达到了42.7的AMOTA,在检测任务中达到了53.8的NDS,均达到了最先进的性能。这些卓越的结果表明,Panacea+是一个强大且普遍适用的自动驾驶生成框架。
Panacea+方法介绍
1)预备知识:潜在扩散模型
扩散模型(DMs)通过学习迭代地去噪正态分布噪声ϵ来近似数据分布p(x)。具体来说,DMs首先通过等式1中的固定前向扩散过程构建扩散输入xt。其中,αt和σt代表给定的噪声计划,t表示扩散时间步。然后,训练一个去噪模型ϵθ来估计从扩散输入xt中添加的噪声ϵ。这是通过最小化均方误差来实现的,如等式2所示。一旦训练完成,DMs就能够通过迭代采样xt,从随机噪声xT ∼ N(0, I)中合成新的数据x0,如等式3所示。其中,µθ和Σθ是通过去噪模型ϵθ确定的。
潜在扩散模型(LDMs)是扩散模型的一种变体,它在潜在表示空间内运行,而不是在像素空间内,从而有效地简化了处理高维数据的挑战。这是通过感知压缩模型将像素空间图像转换为更紧凑的潜在表示来实现的。具体来说,对于图像x,该模型使用编码器E将x映射到潜在空间z = E(x)。然后,可以通过解码器D将潜在代码z重构回原始图像x,即x = D(z)。LDMs的训练和推理过程与传统DMs密切相似,如等式1-3所述,只是将x替换为潜在代码z。
2)生成高质量多视角视频
模型利用一个多视角视频数据集进行训练。每个视频序列包含T帧,表示序列长度,V个不同视角,以及高度和宽度的维度H和W。Panacea+建立在Stable Diffusion(SD)之上,SD是一个强大的预训练图像合成潜在扩散模型。虽然SD模型在图像生成方面表现出色,但由于序列中不同视角和帧之间缺乏约束,其直接应用无法生成一致的多视角视频。为了同时建模时间一致性和空间一致性,采用了基于分解的4D注意力机制的UNet来同时生成整个多视角视频序列。联合扩散输入z的结构维度为H×(W×V )×T×C,其中C表示潜在维度。这个多视角视频序列是通过将帧在其宽度方向上拼接而成的,这与其固有的全景特性一致。图3(a)展示了Panacea+的整体训练框架。此外,为了获得更好的一致性,采用了多视角外观噪声先验。除了基于4D注意力的UNet之外,还使用了两阶段生成管道来大幅提升生成质量。此外,为了探索高分辨率训练对感知任务的有效性,我们将超分辨率模块集成到整体框架中。这样,我们的框架就能够合成高分辨率、高质量的视频数据,从而为感知任务提供强有力的支持。
分解的4D注意力:分解的4D注意力旨在同时建模视角和时间一致性,同时保持计算效率。它受到近期视频表示学习探索的启发,将原本内存密集型的4D联合注意力分解为更高效的结构。分解的4D注意力选择性地保留了最关键的部分:相邻视角之间的注意力和空间对齐的时间块之间的注意力。这导致了两个注意力模块——跨视角注意力和跨帧注意力——与现有的单视角空间注意力并存。
图3(b)详细展示了分解的4D注意力机制。单视角注意力保留了Stable Diffusion(SD)模型中原始空间自注意力的设计,如等式4所示。为了增强跨视角一致性,引入了跨视角注意力。观察表明,相邻视角之间的相关性至关重要,而非相邻视角之间的相关性则相对不那么重要,可以忽略不计。这种跨视角注意力如等式5所示。跨帧注意力借鉴了VLDM[36]的设计,专注于空间对齐的时间块。这一组件对于赋予模型时间感知能力至关重要,这是生成时间上连贯视频的关键因素。
两阶段pipeline:为了提升生成质量,进一步采用了两阶段训练和推理pipeline。通过绕过时间感知模块,模型还可以作为多视图图像生成器运行,从而为两阶段视频生成提供统一的架构。在训练过程中,首先训练一组专门用于多视角图像生成的权重。然后,如图3所示通过将条件图像与扩散输入拼接在一起来训练第二阶段视频生成的权重。这个条件图像仅与第一帧集成,而后续帧则使用零填充。值得注意的是,在第二阶段训练中,使用真实图像作为条件,而不是生成的图像。这种方法使训练过程在效率上与单阶段视频生成方案相当。
在推理过程中,如图4所示,首先使用第一阶段的权重来采样多视角帧。随后,使用第二阶段的权重,基于最初生成的帧来生成多视角视频。这种两阶段pipeline显著提高了视觉保真度,这一结果可归因于空间和时间合成过程的分解。
多视角外观噪声先验:为了全面增强时间一致性和视角一致性,采用了Microcinema中提出的多视角外观噪声先验方法。鉴于Panacea+是一个两阶段方法,框架允许将视频的第一帧作为条件输入来生成后续帧。为了确保后续帧与条件帧之间在内容和外观上的更好一致性,以及提高不同视角之间的一致性。将多视角第一帧图像的特征集成到后续帧的联合噪声中。设[x1, x2, …, xN]表示视频中N个多视角帧的噪声,其中xi是跨多个视角添加到第i帧的联合噪声,且是从高斯分布N(0, I)中随机采样的。如果是第一帧的潜在特征,则训练噪声是:
其中λ是控制第一多视图帧特征量的系数。
3)生成可控驾驶场景视频
在提出的用于推动自动驾驶系统发展的“Panacea+”模型中,合成样本的可控性成为了一个关键属性。“Panacea+”集成了两类控制信号:一类是粗粒度的全局控制,包括文本属性;另一类是细粒度的布局控制,涉及BEV(鸟瞰图)布局序列。粗粒度的全局控制使得“Panacea+”模型能够生成多样化的多视角视频。这是通过将CLIP编码的文本提示集成到UNet中实现的,该方法类似于Stable Diffusion中使用的方法。得益于Stable Diffusion的预训练模型,“Panacea+”能够根据文本提示合成特定的驾驶场景。
“Panacea+”的细粒度布局控制有助于生成与标注相一致的合成样本。使用BEV(鸟瞰图)布局序列作为条件。具体来说,对于一个持续时间为T的BEV序列,将其转换为透视视图,并提取控制元素作为目标边界框、目标深度图、道路图和相机姿态嵌入。图3(d)展示了这一过程,使用不同颜色表示的不同通道来描绘这些分割元素。这产生了具有19个通道的布局控制图像:其中10个用于深度,3个用于边界框,3个用于道路图,3个用于相机姿态嵌入。然后,我们使用ControlNet框架将这些19通道的图像集成到UNet中。
值得注意的是,相机姿态本质上代表了方向向量,该向量由相机的内参和外参推导而来。具体来说,对于相机截锥空间中的每一点,可以通过内参矩阵和外参矩阵(如等式7所示)将其投影到3D空间中。
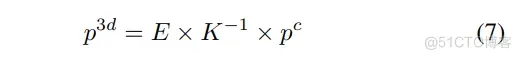
在这里,(u, v) 表示图像中的像素坐标,d 是沿着与图像平面正交的轴方向的深度,而 1 是为了方便在齐次形式下进行计算而添加的。我们选取两个点,并将它们的深度分别设置为 d1 = 1 和 d2 = 2。然后,可以通过以下方式计算对应相机光线的方向向量:
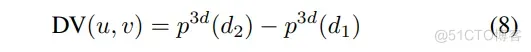
我们通过除以向量的模长来规范化方向向量,并乘以255以简单地将其转换为RGB伪彩色图像。
实验结果对比
1)数据集和评估指标
对Panacea+的生成质量和可控性进行了评估,并评估了其在nuScenes数据集和Argoverse 2数据集上对自动驾驶的益处。
nuScenes数据集。nuScenes数据集是一个公开的驾驶数据集,包含来自波士顿和新加坡的1000个场景。每个场景是一个20秒的视频,包含约40帧。它提供了700个训练场景、150个验证场景和150个测试场景,每个场景都有6个摄像头视角。这些摄像头视角相互重叠,覆盖了整个360度视野。
Argoverse 2数据集。Argoverse 2数据集是一个公开的自动驾驶数据集,包含1000个场景,每个场景长度为15秒,标注频率为10Hz。它被分为700个训练场景、150个验证场景和150个测试场景。这些数据来源于7个高分辨率摄像头,覆盖了360度视野。我们使用10个类别来评估它。
生成质量指标。利用逐帧的FID和FVD来评估合成数据的质量。其中,FID反映了图像质量,而FVD是一个时间感知指标,它同时反映了图像质量和时间一致性。
可控性指标。Panacea+的可控性通过生成的视频与条件化的鸟瞰图(BEV)序列之间的一致性来展示。为了证实这种一致性,在nuScenes和Argoverse 2数据集上评估了感知性能。对于3D目标跟踪任务,采用了如AMOTA、AMOTP和MOTA等指标。对于3D检测,在nuScenes数据集上使用了nuScenes检测分数(NDS)、平均精度(mAP)、平均方向误差(mAOE)和平均速度误差(mAVE),在Argoverse 2数据集上则使用了复合检测分数(CDS)和mAP。StreamPETR,一种最先进的基于视频的感知方法,是我们评估nuScenes的主要工具。对于Argoverse 2,使用Far3D作为我们的评估模型。对于车道检测,使用MapTR评估mAP。为了评估生成样本的可控性,使用预训练的感知模型将生成数据的验证性能与真实数据的验证性能进行比较。将训练集扩充作为性能提升策略的可能性进一步反映了Panacea+的可控性。
2)实施细节
基于Stable Diffusion 2.1实现了我们的方法。使用预训练权重来初始化UNet中的空间层,在两阶段训练过程中,第一阶段的图像权重优化了56k steps,第二阶段的视频权重优化了40k steps。对于推理,使用配置了25个采样步骤的DDIM采样器。扩散模型以256×512的空间分辨率生成视频样本,帧长为8。然后,超分辨率模块将帧在空间上放大到512×1024。训练时的外观噪声先验系数为0.05,推理阶段为0.07。为了评估,在nuScenes上使用StreamPETR进行3D检测和跟踪,其基于ResNet50骨干网络。在Argoverse 2上使用Far3D进行目标检测,也以ResNet50为骨干网络。对于车道检测,使用以R18为主干网络的MapTR。
3)量化分析
生成质量:最初采用定量指标FVD和FID来评估生成的多视角视频的质量和保真度,并将它们与自动驾驶领域图像和视频合成的最先进(SOTA)方法进行比较。如表I所示,与所有SOTA方法相比,我们的方法获得了最佳的FVD和FID分数。与图像合成方法相比,尽管我们的任务是更具挑战性的视频生成,但我们的FID仍然具有优势。例如,比MagicDrive高出0.7分。与BEVGen和BEVControl相比,也展现出显著优势。此外,与视频合成方法相比,方法也表现出色。提出的方法专注于合成具有出色时间一致性的视频样本,因此,FVD可以有效地反映样本一致性的质量。可以观察到,与前作Panacea相比,Panacea+的FVD提高了36分,表明时间一致性得到了改善。与其他SOTA方法相比,我们的方法也表现良好。例如,FVD分数比SubjectDrive低21分。与这些视频合成方法相比,在FID方面也具有优势。例如,在FVD方面略优于Drivedreamer-2,同时在FID方面实现了显著更优的改进,这表明视频的高质量。
可控性:利用预训练的StreamPETR来评估生成样本的可控性。在真实和合成的nuScenes验证集上测试了检测指标NDS。通过比较它们的相对性能,测量了生成样本与鸟瞰图(BEV)布局的一致性。这种一致性程度反映了视频合成的可控性。从表II中可以看出,由Panacea+合成的验证集达到了34.6的NDS,这相当于真实数据集NDS的74%。这表明生成的视频样本中有很大一部分与BEV控制信号保持一致。此外,与Panacea相比,提高了2.5分。这证明了生成视频可控性的提高,从而带来了在一致性方面的益处。因此,我们的合成数据样本有可能为下游任务,特别是与时间动态紧密相关的任务(如自动驾驶中的跟踪)提供更大的帮助。
自动驾驶任务的增强:鉴于我们的最终目标是辅助自动驾驶系统,将生成的样本用作感知模型的训练资源。为了确保验证的完整性,在多个下游任务上进行了实验,包括3D目标跟踪、3D目标检测和车道线检测。在这些任务中,跟踪最能反映时间一致性的重要性。所有的实验都使用了一个仅使用真实数据集训练的基线模型。然后,在训练过程中引入了等量的合成数据,以评估其带来的好处。
3D目标跟踪任务性能。如表III所示,在512×256的分辨率下,使用Panacea+生成的样本进行训练,获得的AMOTA为34.6,比仅使用真实数据训练的基线高出3.5分,代表了性能的显著提升。此外,与Panacea相比,0.9分的提升表明Panacea+确实增强了视频的一致性。此外,还探索了更高分辨率的影响,并观察到在1024×512的分辨率下,绝对性能峰值达到42.7,这比同分辨率下的基线高出5.1分,比512×256分辨率下的基线高出12.6分。这不仅表明具有更高分辨率的合成样本更有效地辅助了跟踪任务,还证明了我们的合成数据在更高的基线水平上实现了优异的相对性能。与最先进的方法相比,从表V中可以看出,Panacea+在跟踪任务中实现了最佳性能,作为合成高分辨率、高质量视频样本的整体模型,它超越了以前的方法。例如,它在AMOTA方面比DriveDreamer-2高出11.4分。这一显著优势凸显了Panacea+在生成高保真视频样本方面的卓越能力,这些样本不仅在质量上出类拔萃,还显著提升了自动驾驶中的跟踪能力。
在表V中,与当前最优方法(SOTA)的比较也展示了Panacea+的卓越性能。我们实现了53.8的MAP,超越了所有当前的自动驾驶场景生成方法。这一成就凸显了Panacea+的有效性。对于Argoverse 2数据集,还对用于3D目标检测的增强数据集训练进行了评估。从表VI可以看出,CDS和mAP分别提高了1.1和0.9个点。这表明我们的生成模型在不同数据集上也是有效的。
车道检测任务的表现。通过将道路地图控制信号集成到我们的合成样本中,显著提升了车道检测任务的性能。我们利用合成数据在nuScenes数据集上训练了先进的感知模型MapTR。如表VI所示,我们实现了6.0个点的显著改进。这一大幅提升突显了我们的模型在车道检测方面的卓越能力,表明其有可能显著改善现有感知模型的性能。
4)量化分析
生成质量。如图5所示,Panacea+展示了从鸟瞰图(BEV)序列和文本提示中生成逼真多视角视频的能力。生成的视频表现出显著的时间一致性和跨视角一致性。我们展示了八个连续帧中的所有视角,以充分展示视频样本。可以看出,Panacea+成功地合成了高质量样本,同时保持了时间一致性和视角一致性。
自动驾驶的可控性。我们从两个方面展示了Panacea+的可控性。首先是粗粒度的文本控制。图6展示了属性控制能力,展示了如何通过修改文本提示来操纵天气、时间和场景等元素。这种灵活性使我们的方法能够模拟各种罕见的驾驶场景,包括极端天气条件如雨雪,从而显著增强数据的多样性。此外,图7展示了车辆和道路如何与BEV布局精确对齐,同时保持优异的时间一致性和视角一致性,展示了Panacea+的细粒度可控性。
一些结论与限制
Panacea+是一个强大且多用途的数据生成框架,用于为驾驶场景创建可控的全景视频。该框架中融入了一个分解的4D注意力模块,以确保时间一致性和跨视角一致性,并采用多视角外观噪声先验来进一步增强一致性。此外,还采用了一种两阶段策略来提高生成质量。Panacea+擅长处理各种控制信号以生成带有精确标注的视频。此外,Panacea+还集成了一个超分辨率模块,以探索高分辨率对感知模型的好处。通过在不同任务和数据集上进行的大量实验,Panacea+已证明其能够生成有价值的视频,服务于广泛的鸟瞰图(BEV)感知领域。
局限性:Panacea+仍有很大的探索空间。目前,实验依赖于从现有数据集的标注信号中合成的视频。在未来,可以与模拟器集成或开发生成控制信号的方法。此外,由于计算成本相对较高,未来的探索可以集中在采用更高效的计算方法上。此外,模型扩展方面还有进一步研究的潜力,特别是对于使用transformer结构的扩散模型,这目前是一个有前景的方向。
#SCP-Diff
生成质量提升80%!清华AIR提出SCP-Diff:真假难辨的驾驶场景生成新方案
近日,来自清华大学智能产业研究院(AIR)助理教授赵昊老师的团队,联合梅赛德斯-奔驰中国,中国科学院大学和北京大学,提出了一种根据语义图生成对应图像的新方法。研究重点关注图像生成中的Semantic Image Synthesis (SIS) 任务,解决了之前方法生成图像质量较低,和语义图不够符合的问题。团队给出了“Noise Prior”的解决方案,在Diffusion推理过程中对噪声加入先验信息,这一方法简单有效,在Cityscapes,ADE20K和COCO-Stuff数据集上取得了State-Of-The-Art的结果,并且将Cityscapes数据集上的FID值从44.5提升到10.5。
论文题目:
SCP-Diff: Spatial-Categorical Joint Prior for Diffusion Based Semantic Image Synthesis
作者:Huan-ang Gao, Mingju Gao, Jiaju Li, Wenyi Li, Rong Zhi, Hao Tang, and Hao Zhao
1 背景介绍
Semantic Image Synthesis (SIS) 任务,是给定一张语义图,目的生成高质量的并且和这张语义图相符的图像。在自动驾驶和具身智能场景中,该任务有很重要的意义,可以让用户生成符合特定摆放要求的图像。然而,现有的方法大多是基于生成对抗网络 (Generative Adversarial Network, GAN) 的,这些方法生成的图像质量较低,不足以投入到实际应用中去。
随着Diffusion等模型的出现,生成式模型生成图像的质量得到的进一步的提升。其中以ControlNet为代表的方法,可以使得用户对生成的图像内容进行控制(比如生成符合某张语义图的图像),然而这些方法生成的图像会出现质量较差和与用户输入的控制不相符的情况,即和所期望的生成图像还有一定的差别。为了探究这个问题,我们做了一系列的实验,发现生成图像和所期望图像的差别的主要不是来源于微调过程,而是来源于训练过程和推理过程中使用的噪声分布不匹配。
为了解决训练和推理使用的噪声分布不匹配的问题,我们针对SIS任务,在推理阶段引入了空间噪声先验和类别噪声先验,使得ControlNet,FreestyleNet等以diffusion为基础的方法可以不需要重新微调即可生成更高质量的图像。通过简单地引入噪声先验,我们在Cityscapes,ADE20K和COCO-Stuff三个数据集上的SIS任务上的指标均取得了State-of-The-Art (SoTA) 的结果。如图1和图2所示。图1(b)中我们对真实图像和生成图像做了随机打乱,在本文的最后会公布哪一张是真实图像。图2对比了OASIS,ControlNet和我们方法的生成结果,我们方法的生成质量明显高于另外两种方法。

图1:Cityscapes上的实验结果

图2:ADE20K上的实验结果
2 先验知识与观察
2.1 先验知识
给定一张语义图 ,和代表语义图的高和宽,语义图的每个像素代表语义标签。Semantic Image Synthesis (SIS) 任务目标是设计一个函数,输入是语义图,输出是符合该语义图条件的RGB图像。
现有的State-Of-The-Art的方法ControlNet,在训练过程中,目标是从一个时间步的加噪的图像还原出原始图像。在时间步时刻,去噪模型可以表示为:
其中是图像经过VQGAN编码后得到的结果,,代表时间步t的累积缩放乘积。模型以等条件作为输入,预测,形式化表示为,这里代表对输入的文字的编码,代表语义图。在ControlNet模型中,一个不可训练的分支使用Stable Diffusion预训练好的权重,用来处理 , 和。同时,ControlNet复制Stable Diffusion的编码器部分用来处理,这两个分支通过零卷积层进行连接。ControlNet的损失函数定义为:
在推理过程中,ControlNet从标准正态分布采样出一个,然后从到执行反向去噪过程:
经过T步反向去噪过程后,我们能得到,经过一个VQGAN解码器后就可以得到图像。
2.2 ControlNet实验观察
简单地通过微调ControlNet会出现一些质量不好的结果,比如会出现一些奇怪的子结构,和语义图不够符合等。为了调研为什么会出现这种现象,本文在ADE20K上做了相应的分析实验,如图三所示。图三中的FID表示了生成图像和ADE20K真实图像之间的差别,棕色虚线代表ControlNet直接从标准正态分布采样然后经过步反向去噪过程的结果。黑色的折线代表从采样然后经过步反向去噪过程的结果,其中定义为:
我们可以看出,当时,从进行步的反向去噪生成的图像,要比从进行步的反向去噪生成的图像的FID有显著地降低。这个分析实验揭示出了之前很接近的假设是不可靠的。因此引入”噪声先验“对于提升以Diffusion为基础的方法在SIS任务上的性能有着重要的意义。
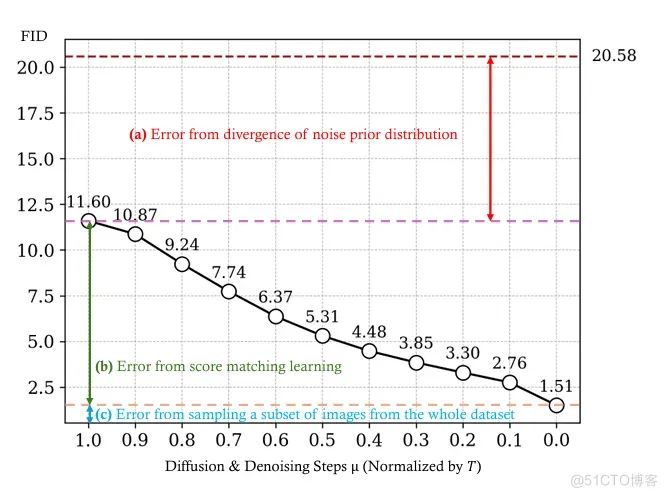
图3:ADE20K上的分析实验结果
3 方法
本文的方法分为两个部分:第一部分是噪声先验的准备,这一部分首先计算相应训练集图像经过VQGAN编码得到的特征图的均值和方差来构建类型噪声先验和空间噪声先验;第二部分是利用我们刚才得到的噪声先验进行推理,得到高质量的生成图像。
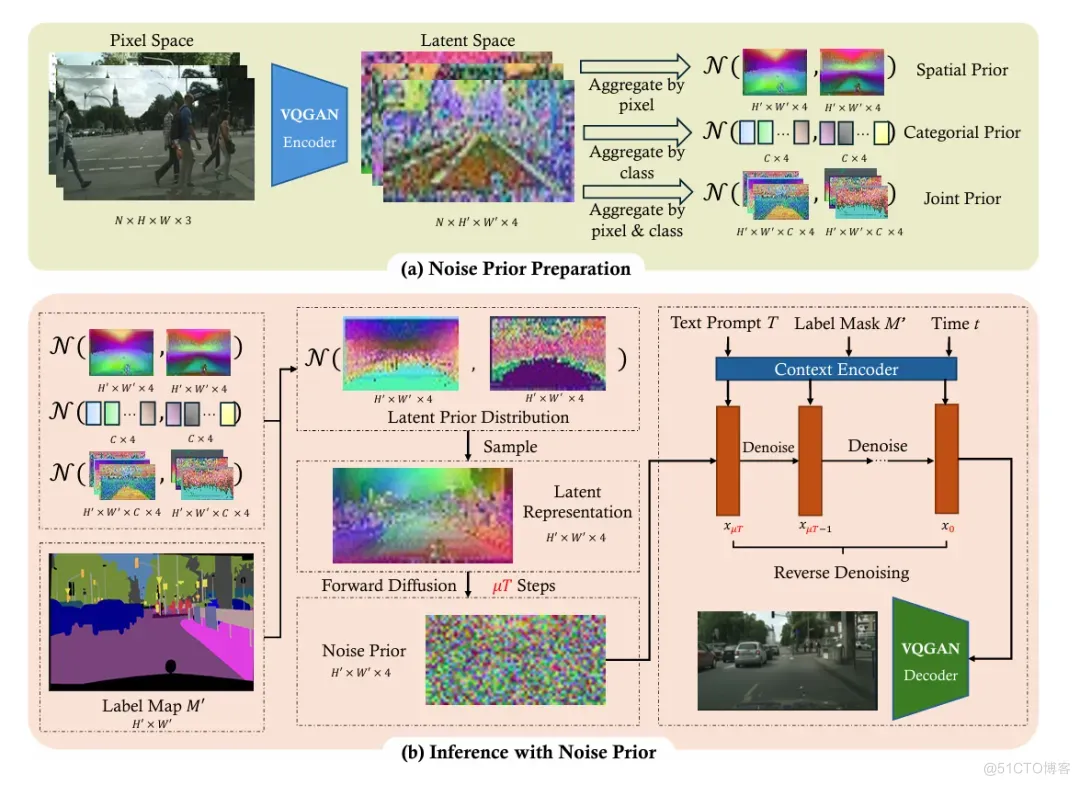
图4:SCP-Diff方法概览
3.1 空间噪声先验和类别噪声先验
给定数据集中的N张latent images和他们对应的语义图 ,我们的目标从中得到噪声先验,使得其和训练过程中得到的噪声分布一致,从而减小推理过程中的误差。
3.1.1 空间噪声先验
我们假定每一个对最后学习到的训练噪声都有相等的影响,我们定义空间噪声先验:
其中 表示Hadamard乘积。为了简化问题,我们不对空间tokens之间的相关关系进行建模,而是将每个位置的spatial tokens当作独立的边际分布。在推理过程中。我们获取从时刻开始去噪的噪声可以从下面分布中采样:
我们从该分布中采样的噪声经过步反向去噪过程后,经过一个VQGAN解码器即可得到高质量图像。
对于空间先验的作用,本文进行了一个案例研究,如图5所示。从图中分析可知,使用空间先验的模型在构建场景布局时表现出更广泛的感受野,而使用普通先验的模型则迅速将注意力集中在狭窄的局部区域。这种差异揭示了为什么使用空间先验的模型能够生成完整的场景,并且减少了奇怪的子结构,而使用标准正态分布的模型的输出则更像是根据相似形状的模板进行裁剪和粘贴对象。
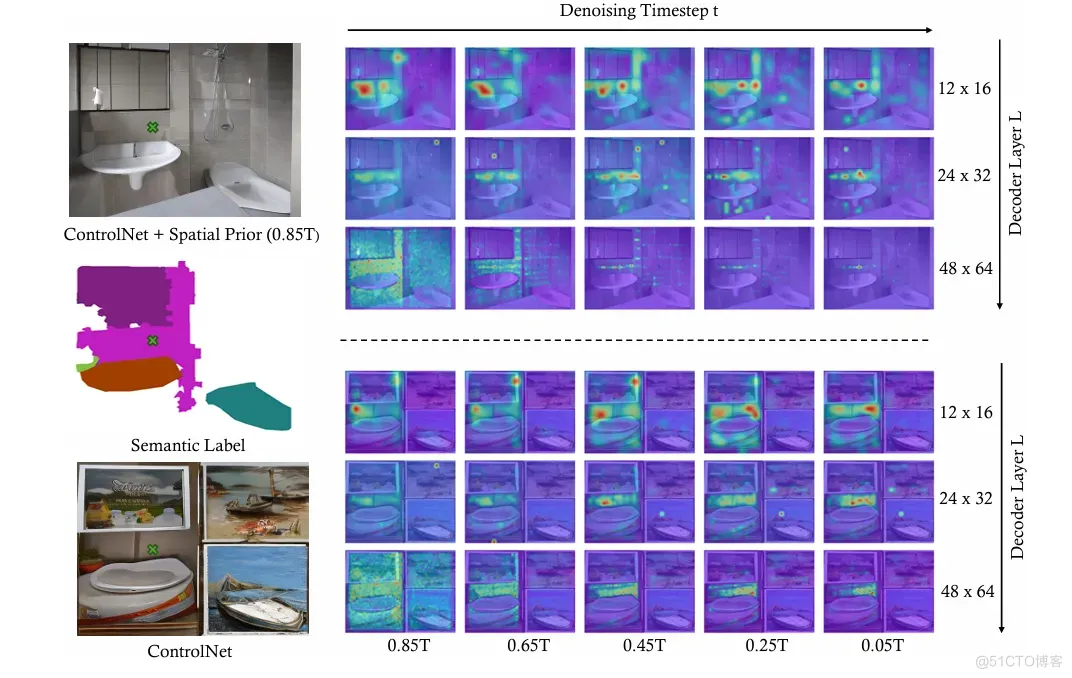
图5:Spatial Prior的Case Study
3.1.2 类别噪声先验
尽管空间先验的方法在全局关注整个场景方面取得了成功,但在融入类别信息方面仍显不足。比如上图2中,会在天空中生成不符合语义类别标签的建筑物。本文认为这是空间噪声先验和ControlNet的控制分支有一定程度的不兼容导致的(因为空间噪声先验融合了不同类型模式的先验)。这种不匹配会沿着去噪轨迹累积,使得去噪过程进一步地偏离预定轨迹。
因此,我们引入了基于类别的噪声先验。首先,我们通过最近邻下采样语义图到。接下来,对于N张reference images,我们为其个类别中的每一类各自创建了一个独立的集合,每个集合中包含维度为的tokens。接下来,我们为每一类计算其tokens的均值和方差,得到:
的定义和上面的是一样的。
为了证明类别噪声先验的作用,本文进行了一个案例研究,如图6所示。我们发现从类别噪声先验开始反向去噪过程可以在图像中物体形成阶段增强对语义标签的理解能力,比如图6(b)中图像生成中我们使用“Tree”类别来query score map,加入类别噪声先验的方法会将更多的注意力放到“Tree”真正应该在的区域,而不会像ControlNet一样分散。

图6:Categorial Prior的Case Study
3.2 联合先验
为了融合空间噪声先验和类别噪声先验的优点,我们提出了联合先验(Joint Prior)。联合先验的计算过程可以表示为,对于N张reference图像,我们用不同的几何来存储在特定位置特定类别的先验信息,具体的,对于,,,,我们可以得到:
当给定对应的sample size过小时,我们认为估计是不准确的,我们使用类别先验。的定义同空间先验。
3.3 反向去噪步数的影响
在理想情况下,去噪时间步长的系数需要进行仔细地调整。较小的意味着向计算出的先验中注入较低水平的噪声,从而减少所需的去噪步骤数量,并加快推理过程。然而,在联合先验的框架下,由于我们将来自不同空间位置和类别的编码标记视为独立变量而忽略它们之间的相关性,需要更多的自注意力机制来逐步将边际统计转变为联合建模,因此需要更多的去噪步骤 。我们在实验中也对的值做了一系列的消融实验,具体可见4.3.1。
4 实验
4.1 实验设置
我们在Cityscapes,ADE20K和COCO-Stuff三个数据集上进行了实验。为了评估我们生成的图像,我们使用了(1)平均交并比(mean Intersection-over-Union, mIoU)和像素准确率(Pixel Accuracy, Acc)来评估我们生成的图像和语义图的相符程度。(2)Fréchet inception distance(FID)来衡量生成图像的质量(3)LPIPS和MS-SSIM来衡量生成图像的丰富性(4)用户测试(User Study)来衡量我们的生成结果。
我们使用张图像来计算噪声先验。对于Cityscapes和ADE20K数据集,他们各自的噪声先验被应用在已经在这两个数据集微调好的ControlNet的推理过程中。微调过程在A100 80G GPUs上进行,使用的batch size大小为,使用的学习率微调步,原始Stable Diffusion的解码分支中的参数在微调过程中也会进行调整。对于COCO-Stuff数据集,我们将我们的方法应用在已经微调好的FreestyleNet模型中,我们使用官方提供好的checkpoint。
4.2 主实验结果
4.2.1 不同类型的噪声先验的比较
我们定性和定量地比较了不同噪声先验对于SIS生成效果的影响,结果如表1和图7所示。其中Normal Prior代表从标准正态分布进行反向去噪过程。表1显示,联合先验在图像质量(FID)和与提供的语义图的一致性(mIoU 和 Acc)方面,优于ControlNet所使用的标准正态分布先验。其中mIoU 提升了 2.78,FID 显著降低了12.82。仔细观察生成的图像可以发现,尽管 ControlNet相较于 OASIS 更擅长生成边缘柔和且模糊效果较少的图像,但它在场景布局组织方面表现不佳,往往无法正确地和提供的语义图对齐,例如将建筑物错误地放置在天空区域。相比之下,我们提出的联合先验解决了这些问题,显著提升了图像的真实感。
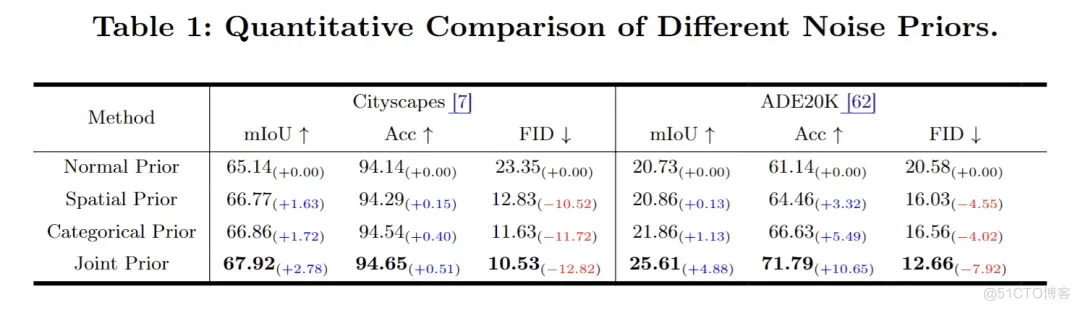
表一:不同噪声先验的实验结果

图7:不同噪声先验的实验结果
4.2.2 和SoTA模型的比较
与SIS领域的最新进展相比,我们提出的联合先验(或 SCP-Diff)有显著地效果提升。如表2所示,ControlNet 通过将生成建模的重点从像素空间转移到隐空间,已经显著超越了早期的方法,得益于其合成高分辨率图像的能力。我们的方法通过解决扩散模型推理过程中,使用的噪声分布和实际不同的问题,进一步放大了这一优势,从而在 Cityscapes和 ADE20K 数据集上取得了SoTA结果。在COCO-Stuff 数据集上,我们将提出的联合先验应用于FreestyleNet方法上,也取得了 FID 值降低 3.1的性能提升。
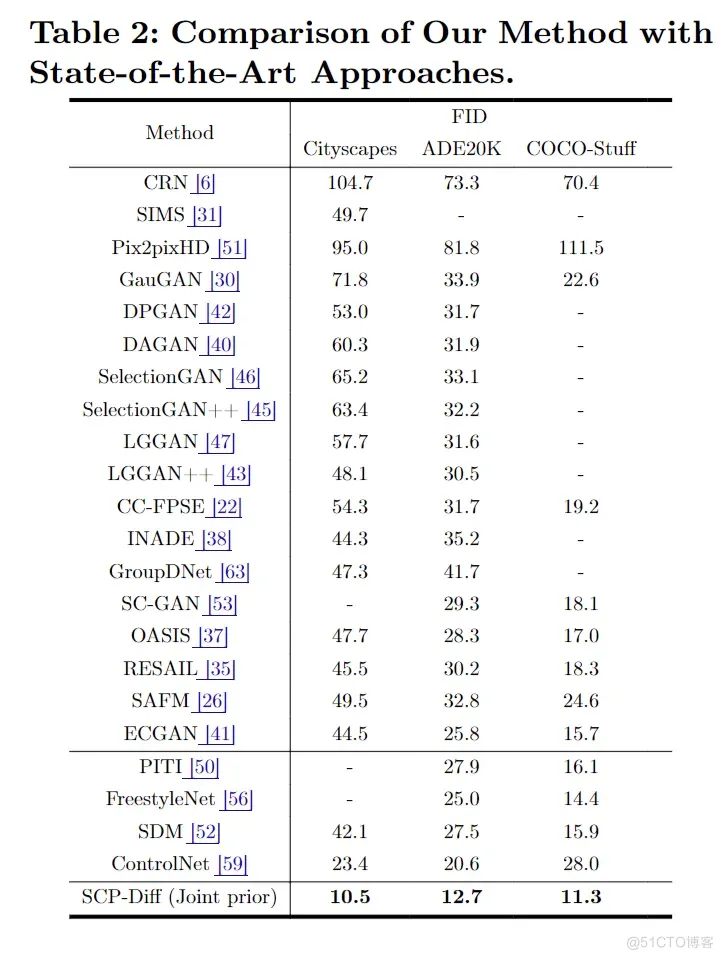
表二:和SoTA方法的对比
4.3 消融实验结果
4.3.1 对去噪步数的研究
通过减小中的,其中 μ,我们可以优化传统上耗时的Stable Diffusion的采样方法。如第3.3节中所讨论的,我们进行了实验观察 对生成结果质量的影响。从图8可以看出,对于两个数据集,最佳的 选择在之间。图8中两条曲线中观察到的趋势模式相似,表明在应用噪声先验时具有一定的稳健性。
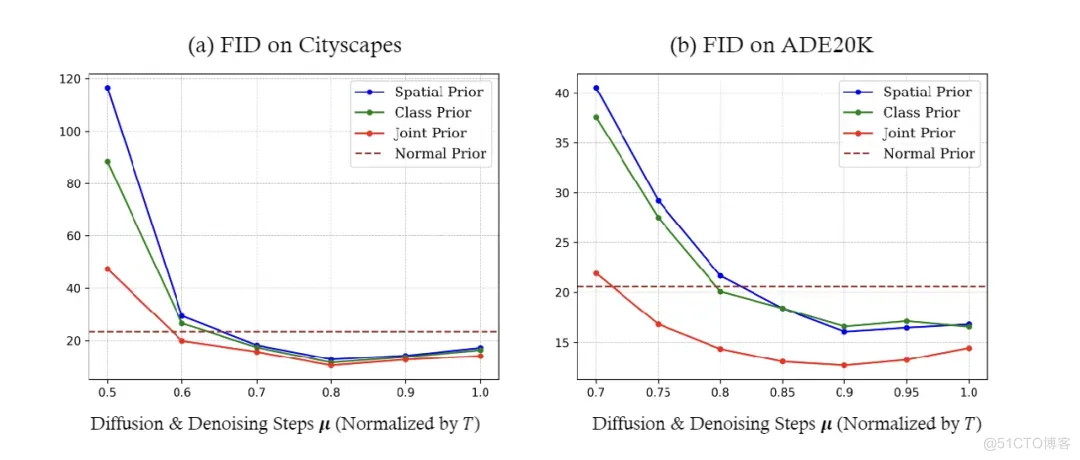
图8:对去噪步数的研究
4.3.2 对生成图像的多样性的研究
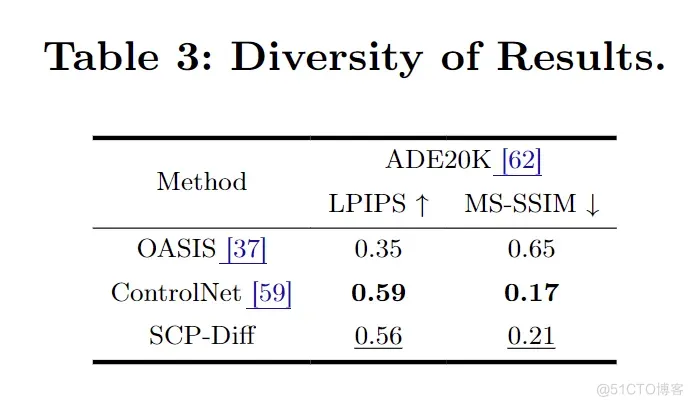
参考 OASIS的方法,我们通过分析从同一标签图生成的一组图像(称为一个批次)中的变化来判断生成图像的多样性,我们使用 MS-SSIM 和 LPIPS 来作为评估指标。在实验中,我们为每个标签图生成20张图像,计算这些图像之间每对之间的平均指标,然后将这些分数在所有标签图上取平均。从表3的结果可以看出,我们的联合先验相比ControlNet的多样性评分略有降低。这一结果是可以预见的,因为在推理过程中引入先验本质上是在多样性与提高质量之间寻求平衡。
表三:生成图像多样性的研究
4.3.3 对Reference Images数量的研究
为了研究Refercence Images数量的影响,我们在图9中进行了消融实验。图9中显示,随着样本数量的增加,FID逐渐降低。即使参考图像的数量有限,FID分数仍显著低于原始ControlNet。此外,为了检验样本多样性是否有帮助,我们使用CLIP图像编码器(ViT-B/32)对10,000张图像进行编码,并在特征空间内进行最远点采样。我们选择了距离最大的100张图像,并使用这些图像来计算联合先验。图9中的散点图显示,图像的多样性确实有助于最终图像质量的提升。

图9:Reference Images数量的研究
4.3.4 User Study
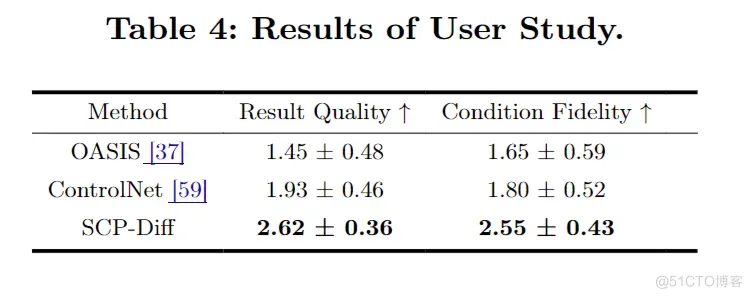
参考 ControlNet的方法,我们进行了User study,邀请参与者分别对由三种方法生成的500组图像(见表4)进行排名,依据“显示图像的质量”和“与给定语义标签的一致性”两个标准进行评价。我们采用平均人类排名(AHR)作为衡量用户偏好的指标,参与者在1到3的范围内对每个结果进行评分,3分为最佳。根据表4中的平均排名,用户明显更倾向于我们方法生成的结果。
表四:User Study结果
5 总结
在本文中,我们通过引入推理噪声先验,解决了在微调ControlNets用于语义图像合成(SIS)任务时的图像质量较低与和语义图不一致的问题。我们的SCP-Diff表现出很好的性能,在Cityscapes,ADE20K和COCO-Stuff数据集上都实现了SoTA。我们希望我们的工作和高质量生成的图像能够为研究界的未来工作提供灵感。
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。












暂无评论内容