


为了优化 Java Spark 服务,尝试了各种办法和各种参数组合。
为什么要优化
现网有个spark服务,白天数据量大,积压数据,夜间数据量小,再把积压的数据处理完,虽然达到了平衡,保证了每天的数据能处理完,但白天的数据处理延迟比较大。
数据积压的原因
接手这个服务以来,我一直以为是因为下载图片耗时长导致的数据处理速度慢。这周测试发现,存储图片的时候,判断图片是否存在,不存在则保存图片到本机文件夹,这两个步骤有时耗时几十毫秒,有时甚至耗时十几分钟!
难点
数据处理并行度小了不行,会导致数据处理速度慢;并行度大了也不行,会导致上述两个步骤有概率出现特别慢的情况,从而有概率严重拖慢spark任务;通过测试发现,并行度无论怎么设置,都会有概率出现特别慢的情况。
解决办法
- 通过spark.streaming.kafka.maxRatePerPartition参数和JavaStreamingContext构造函数的batchDuration参数,控制数据流量
- 开启spark推测执行,并设置合适的参数
- 通过redis分布式锁控制并行度
关键代码如下:
spark.streaming.kafka.maxRatePerPartition参数设置:
sparkConf.set("spark.streaming.kafka.maxRatePerPartition", "1");
推测执行参数设置:
sparkConf.set("spark.speculation", "true");
sparkConf.set("spark.speculation.interval", "5s");
sparkConf.set("spark.speculation.quantile", "0.1");
sparkConf.set("spark.speculation.multiplier", "6");
batchDuration参数设置:
JavaStreamingContext jssc = new JavaStreamingContext(jsc, Durations.milliseconds(10000));
Redis分布式锁tryLock定义:
public static boolean tryLock(String key) {
String r = RedisClusterUtil.getJedis().set(redisKeyPre + key, "value", "NX", "PX", 10);
if ("OK".equals(r)) {
return true;
} else {
return false;
}
}
Redis分布式锁tryLock使用
try {
String key = String.valueOf(partitionId % 8);
while (!RedisLock.tryLock(key)) {
Thread.sleep(5);
}
} catch (InterruptedException e) {
log.error("获取Redis锁异常!!!");
}
说明:锁超时释放,没有使用unlock手动释放
优化效果
通过以上方法,降低了判断图片文件是否存在和保存图片这两个步骤出现长耗时的概率和出现长耗时时的耗时时长。
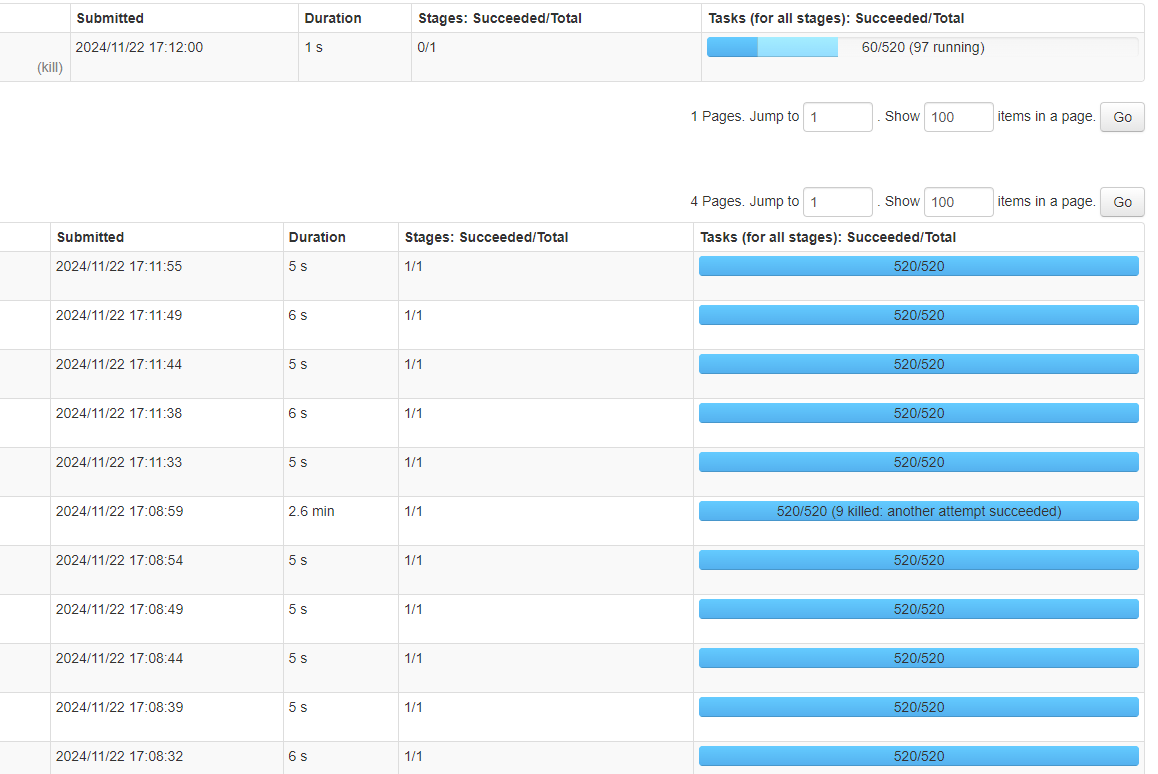
但是依然有概率会出现特别慢的情况。如下图所示:
Spark截图1
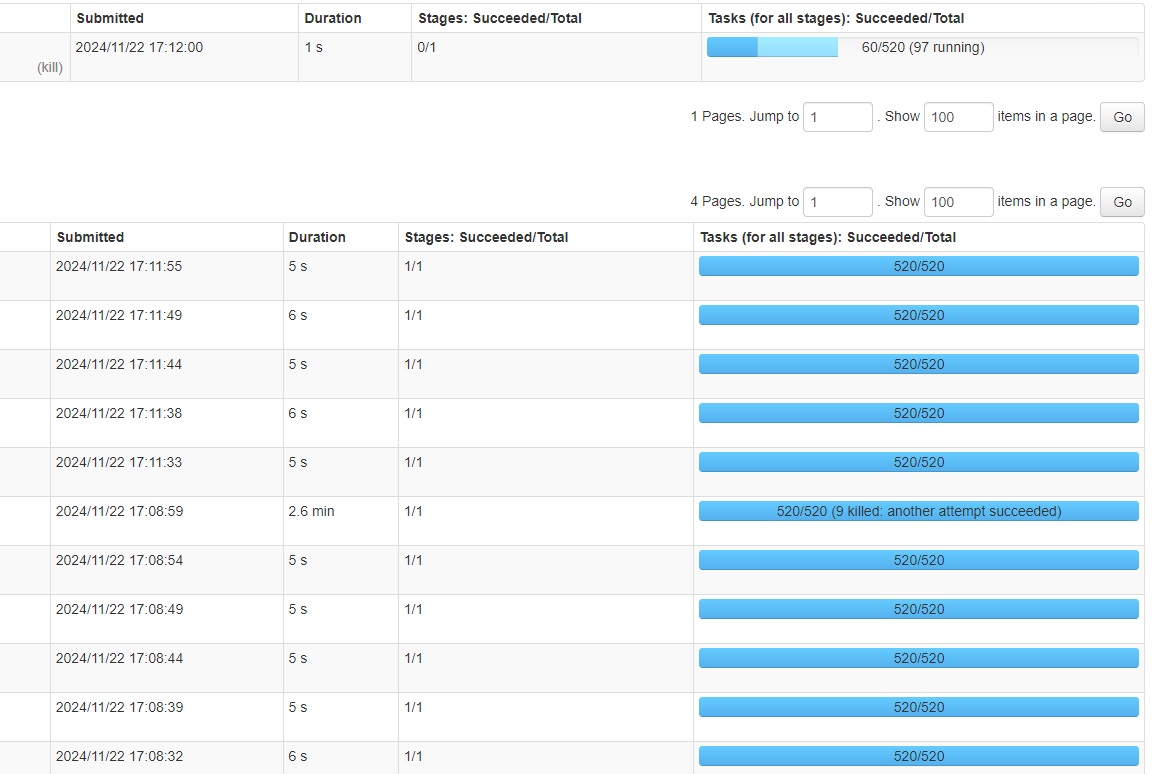
Spark截图2
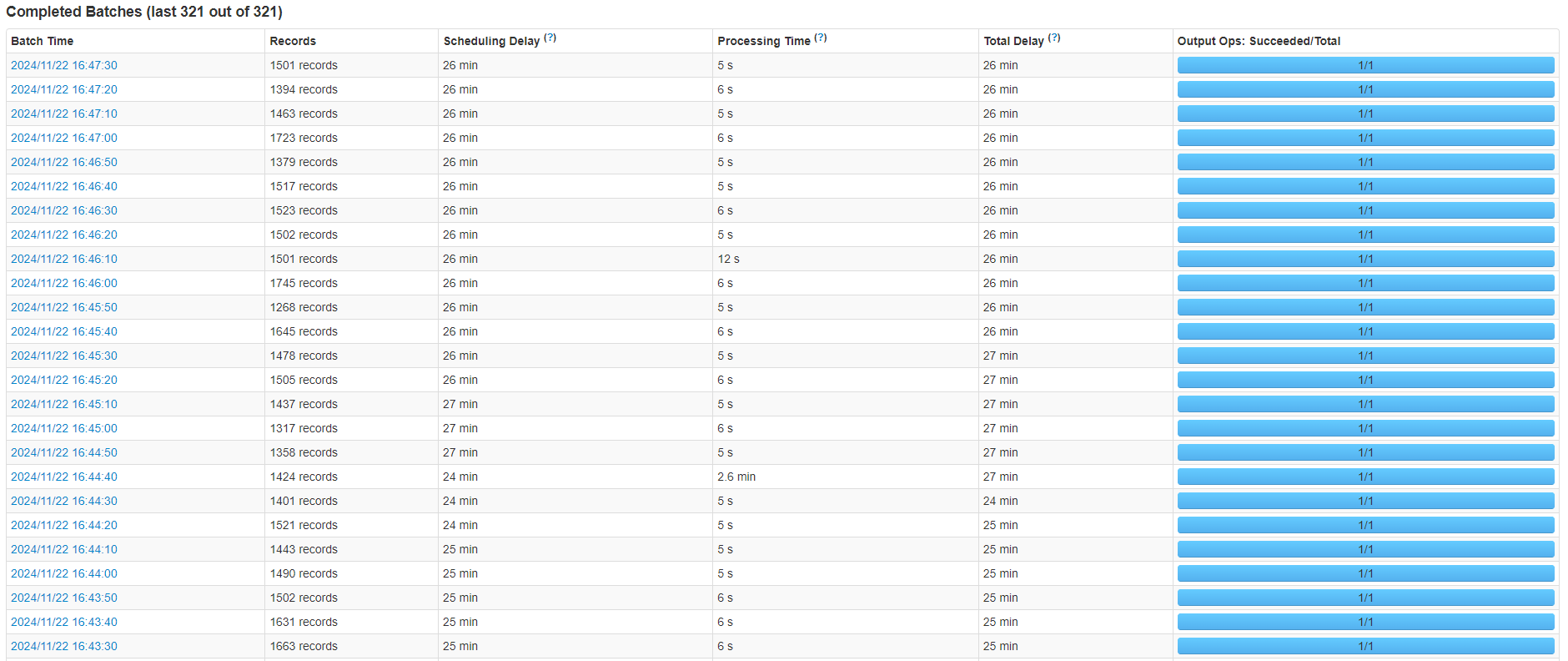
后续
使用SpringBoot多线程单体服务代替Spark后,再也没有数据积压了,出现图片下载失败、新建目录失败的情况几乎没有了,长耗时的情况也几乎没有了
结论:此类存储任务不适合使用Spark服务处理
来源链接:https://www.cnblogs.com/s0611163/p/18554707
© 版权声明
本站所有资源来自于网络,仅供学习与参考,请勿用于商业用途,否则产生的一切后果将由您(转载者)自己承担!
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。
THE END














暂无评论内容