


- 符号大全
- Python下载
- Python Gitee笔记
- 安装选择自定义,最好是盘符根下创建python目录,目录(文件夹)名不能有中文。
- 设置环境变量:右键此电脑-属性-高级系统设置-环境变量-上边是用户环境变量,下面是系统环境变量。
- 在系统变量中找到Path-双击或者点编辑
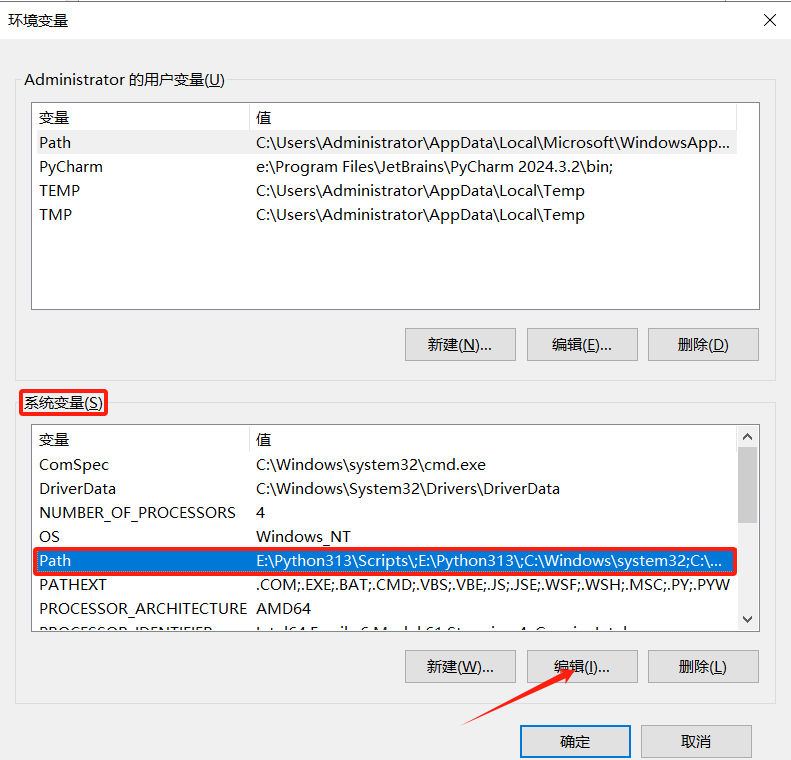
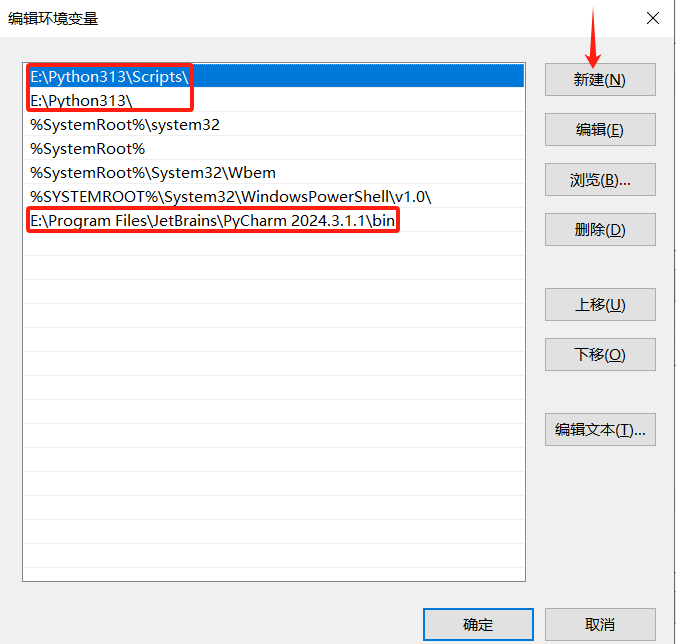
- 点击新建,把X:\python3.x.x和X:\python3.x.x\Scripts路径复制上去。然后一路的确定即可。
设置环境变量是为了在CMD命令中或是编程时可任意调用Python命令,不会提示出错。
注:安装Python和Pycharm的时候,记得把Path选项打上勾,就会自动配置好环境变量了。
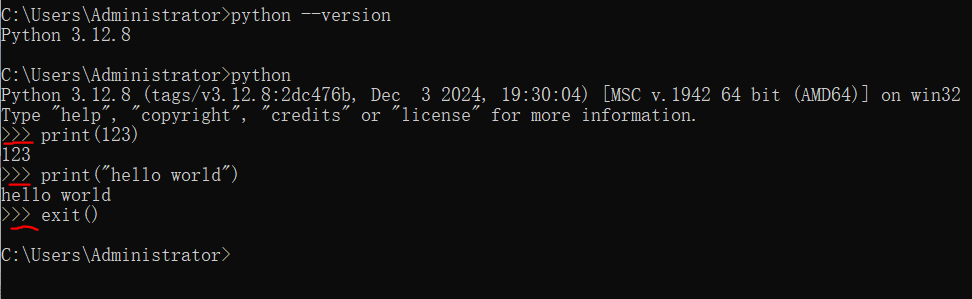
命令:
- 版本号:python –version
- 交互式状态:>>>
- 打印/显示:print()
- 退出交互式状态:exit()
交互式并不是最常用的,未来最常用的还是文件式来进行编程。就是把一堆python的编程和指令写到一个.py的文件中,我们称之为python的源代码文件。可以用python解释器来重复运行程序。
编写python代码用PyCharm来编写。网上有激活工具。它是python的一种IDE(Integrated Development Environment),即集成开发环境。也就是专门来开发python程序的一个桌面软件。
PyCharm快捷键:
注释:Ctrl+/ 复制:Ctrl+D 向下换行:Shfit+Enter 向上换行:Ctrl+Alt+Enter 移动代码:Ctrl+Shift+方向键 删除:Ctrl+Y 查找Ctrl+Shift+F 格式化(优化)代码:Ctrl+Alt+L 查看函数官方的帮助文档:Ctrl+Shift+I
注释和变量:
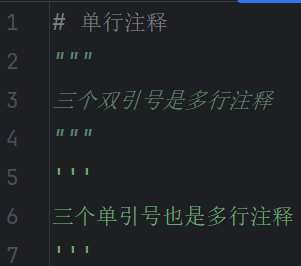
- 单行注释:#
- 多行注释:””” “””或是”’ ”’ 引号中间写注释。
Pycharm中#单行注释颜色更改:
File→Settings(Ctrl+Alt+S)→Editor→Color Scheme→Language Defaults→Comments→Line Comment
定义变量和使用:
- 格式:变量名 = 值
- 使用:变量名
变量名不可以随便使用,需要满足标识符的命名规则。它是Python中定义各种名字的时候的统一规范。
1.标识符
- 由数字、字母、下划线组成
- 不能数字开头
- 严格区分大小写
- 不能使用内置关键字,也叫做保留字
import keyword #import 导入模块
print(keyword.kwlist) #print() 打印/输出结果为
| and | as | assert | async | await |
| class | continue | def | del | break |
| elif | else | except | while | with |
| False | finally | for | from | global |
| if | import | in | is | lambda |
| None | nonlocal | not | or | pass |
| raise | return | try | True | yield |
自动输入print()的小窍门。直接写要输出的代码,写好后直接在后面输入.p就会出现P相关的函数(功能),如果没出现,就再往后输入,直到看到,选择好回车。
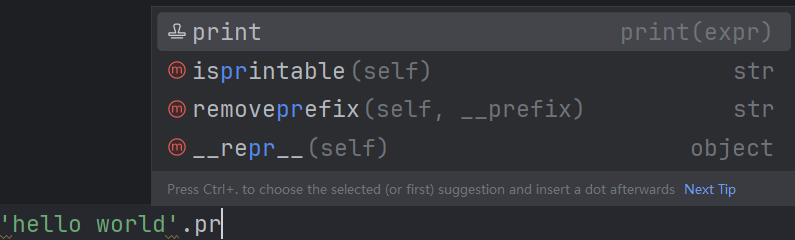
注意:代码第一次运行时,要先点击鼠标右键点“RUN”才会显示结果,直接点右上角的运行按钮是不会显示结果的。
变量的数据类型:
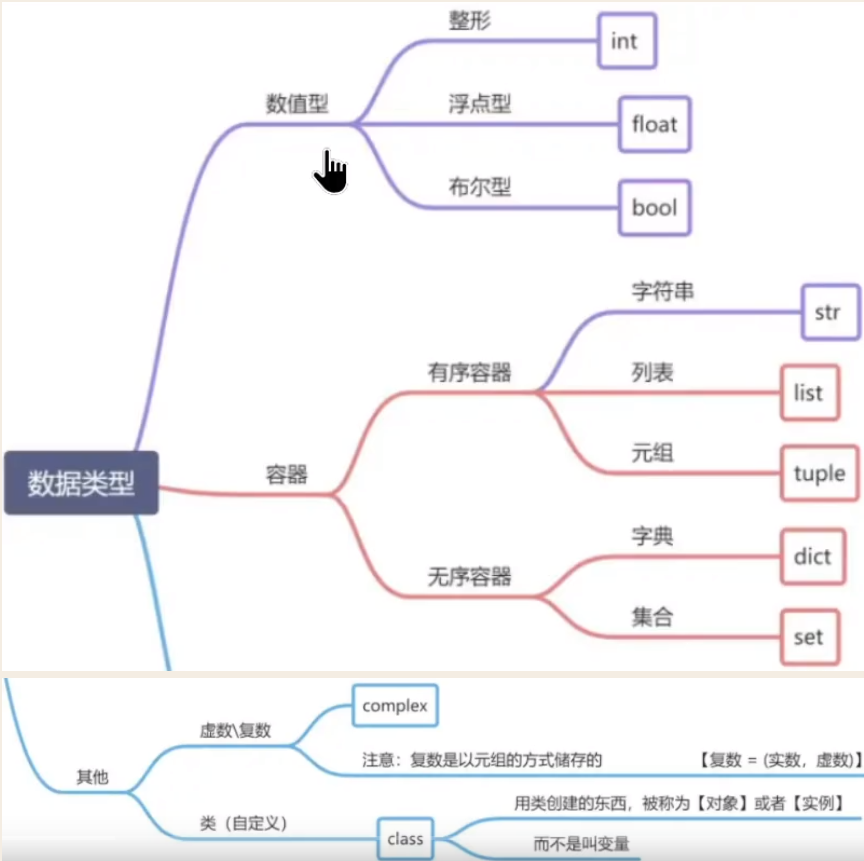
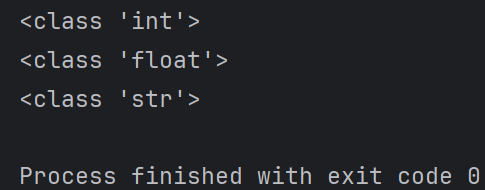
检测数据类型的函数:type()
#整数类型
num01 = 100 print(type(num01))
#浮点类型 num02 =0.12 num03 = 3.1415926 num04 = 9.8
print(type(num02))
#字符串类型
str01 = 'abc'
str02 = "Python 学习"
print(type(str02))
输出结果为:
2.字符串
字符串其实就是一串字符,也就是说跟珠子一样串起来的字符,把它给串起来的方式。英文str。字符串输入要在单引号或者双引号内输入。
| 操作符 | 描述 | 实例 |
| + | 字符串拼接 |
a = ‘Hello’ b = ‘Python’ pring(c = a + b) ‘HelloPython’ |
| * | 重复输出字符串 |
print(a * 2) ‘HelloHello’ |
| in | 成员运算符-如果字符串中包含给定的字符则返回True |
print(‘H’ in a) True |
| not in | 成员运算符-如果字符串中不包含给定的字符则返回True否则返回False |
print(‘H’ not in a) False |
| r/R | 原始字符串-所有的字符都是按照字面的意思来使用,没有转义特殊或者不能打印的字符,原始字符串除在字符串的第一个引号前加上字母’r'(可以是大小写)以外,与普通字符串有着几乎完全相同的语法 |
|
| [] | 通过索引(也称角标)获取字符串中的字符 |
|
| [:] | 截取字符串中的一部分 |
print(a[1:4]) ell |
格式化输出
| 格式符号 | 转换 | 格式符号 | 转换 |
| %s | 字符串 | %x | 十六进制整数(小写ox) |
| %d | 有符号的十进制整数 | %X | 十六进制整数(大写OX) |
| %f | 浮点数 | %e | 科学计数法(小写‘e’) |
| %c | 字符 | %E | 科学计数法(大写‘E’) |
| %u | 无符号十进制整数 | %g | %f和%e的简写 |
| %o | 八进制整数 | %G | %f和%E的简写 |
按照我们自己想要的输出格式,先定义一个模板,照着模版输出。
print(模版 % 变量名 )
age = 18 name = 'Sam' print('我的姓名是%s,年龄是%d' % (name,age))
输出结果:我的名字是Sam,年龄是18。
技巧:
- %s:可以是字符串,也可以是数字
- %6d:表示输出整数的显示位数,不足以0补全,超出当前位数则原样输出
- %.2f:表示小数点后显示保留的小数位数
num = 22.345 print('%.2f' % num)#保留两位小数 #输出结果:22.34
按照四舍五入应该是22.35
注意:因为计算机只认识和处理进制数值,在实际的计算中,所有的数据都必须为二进制,计算后又转换回来,就是在这个过程中造成数据的截断误差。
精确四舍五入解决方法:
num = 22.345 print('%.2f' % num) # 保留两位小数 from decimal import Decimal print(Decimal(str(num)).quantize(Decimal('0.00'), rounding='ROUND_HALF_UP')) #输出结果:22.35
①. Format():
相对基本格式化输出采用%的方法,format()的功能更强大,该函数把字符趾当成一个模版,通过传入的参数进行格式化,并且使用大括号{}作为特殊字符代替%,它不需要考虑数据类型。
print(‘{} {}’ . 变量名)
a = 'hello' b ='world' print('{},{}'.format(a,b)) #输出结果:hello world
②.用f-string方法格式化输出
my_name = '许晓勇' my_age = 41 print(f'我的名字叫{my_name},年龄{my_age+1}') #输出结果:我的名字叫许晓勇,年龄42
3.字符串操作:
①.下标:
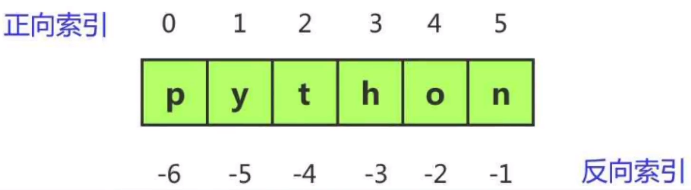
“下标”又叫“索引”或“角标”。也就是编号,用中括号[]表示。下标的作用就是通过下标快速找到对应的数据。(所有序列都有下标)
注意:下标从左到右顺序是从0开始的,反过来就是从-1开始。
s1 ="hello world" s2 = 'hello world' s3 = '''hello world''' s4 = 'hello\nworld' s5 = 'I\'m Yonge'
print(s1[0])#或是
print(s1[-11]) #取出的值是同一个,输出结果是一样的,都是h
②.切片:
“切片”是指对操作的对象截取其中一部分的操作。也就是截取字符串。字符串、列表、元组都支持切片操作。
序列对象[开始位置下标:结束位置下标:步长] 步长为1可省略。步长就是跳过几个元素的意思。
口诀:包头不包尾,目标位置+1.
s = 'abcdefg' print(s[2:6]) # 输出结果:cdef print(s[2:6:2]) # 输出结果:ce print(s[:7]) # 输出结果:abcdefg print(s[0::]) # 输出结果:abcdefg print(s[::-1]) # 输出结果:gfedcba
4.字符中的函数:
①.字符串查询(index,find)
建议使用find(),因为如果没找到匹配的字符串,index()方法会报异常。除了能查找目标字符串,还有判断功能。
| 名称 | 语法格式 | 代码解释 | 功能 |
| find | string.find(sub, start=0, end=len(string)) |
|
查找子字符串str第一次出现的位置,如果找到则返回相应的索引,否则返回-1 |
| rfind | string.rfind(sub, start=0, end=len(string)) | 类似于find()函数,不过是从右边查找 | |
| index | string.index(sub, start=0, end=len(string)) | 类似于find()函数,只不过如果没找到会报异常 | |
| rindex | string.rindex(sub, start=0, end=len(string)) | 类似于rfind()函数,如果没有匹配的字符串会报异常 |
# find index 示例 1 ss = 'hellopythonworld' print(ss.find('py')) # 输出结果:5 print(ss.find('hi')) # 输出结果:-1 print(ss.index('hi')) # 输出结果:出错。 # 示例 2:基本查找 text = "Hello, World! Hello, Python!" sub_str = "Hello" result1 = text.find(sub_str) print(f"基本查找结果: {result1}") # 示例 3:指定起始位置查找 start_index = 7 result2 = text.find(sub_str, start_index) print(f"指定起始位置查找结果: {result2}") # 示例 4:指定起始和结束位置查找 end_index = 13 result3 = text.find(sub_str, start_index, end_index) print(f"指定起始和结束位置查找结果: {result3}") # 示例 5:未找到子字符串 non_existent_sub = "Java" result4 = text.find(non_existent_sub) print(f"未找到子字符串的查找结果: {result4}")
示例:2-3-4-5输出结果:

②.字符串大小写转换操作(upper lower swapcase capitalize和title)
| 名称 | 语法格式 | 功能 | 实例 |
| upper | string.upper() | 将所有字符串元素都转成大写 |
text = “hello, world!” result = text.upper() print(result) # 输出: HELLO, WORLD! |
| lower | string.lower() | 将所有字符串所有元素都转成小写 |
text = “HELLO, WORLD!” result = text.lower() print(result) # 输出: hello, world! |
| swapcase | string.swapcase() | 交换大小写,大写转为小写,小写转为大写 |
text = “Hello, World!” result = text.swapcase() print(result) # 输出: hELLO, wORLD! |
| capitalize | string.capitalize() | 第一个大写,其它为小写 |
text = “hello, world!” result = text.capitalize() print(result) # 输出: Hello, world! |
| title | string.title() | 每个单词的第一个字符大写,其余均为小写 |
text = “hello, world!” result = text.title() print(result) # 输出: Hello, World! |
③.字符串对齐(center just和zfill)
| 名称 | 语法格式 | 参数解释 | 功能 |
| center | string.center(width, fillchar) |
|
返回一个指定的宽度width居中的字符串,fillchar为填充的字符,默认为空格 |
| ljust | string.ljust(width, fillchar=’ ‘) | 返回一个字符串左对齐,并使用fillchar填充至长度width的新字符串,fillchar默认为空格 | |
| rjust | string.rjust(width, fillchar=’ ‘) | 返回一个字符串右对齐,并使用fillchar填充至长度width的新字符串,fillchar默认为空格 | |
| zfill | string.zfill(width) | 返回长度为width的字符串,原字符串右对齐,前面填充0 |
# center示例 1:使用默认填充字符(空格) original_str = "Hello" width = 10 result1 = original_str.center(width) print(f"使用默认填充字符的结果: '{result1}'") # center示例 2:指定填充字符 fill_char = '*' result2 = original_str.center(width, fill_char) print(f"使用指定填充字符的结果: '{result2}'") # center示例 3:width 小于原字符串长度 width_small = 3 result3 = original_str.center(width_small) print(f"width 小于原字符串长度的结果: '{result3}'")
输出结果:

#ljust 示例 1:使用默认填充字符(空格) original_str = "Python" width = 10 result1 = original_str.ljust(width) print(f"使用默认填充字符的结果: '{result1}'") #ljust 示例 2:指定填充字符 fill_char = '-' result2 = original_str.ljust(width, fill_char) print(f"使用指定填充字符的结果: '{result2}'") # ljust示例 3:width 小于原字符串长度 width_small = 3 result3 = original_str.ljust(width_small) print(f"width 小于原字符串长度的结果: '{result3}'")
输出结果:

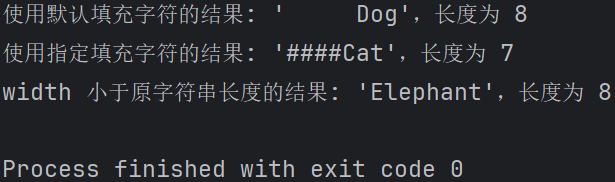
#rjust 示例 1:使用默认填充字符(空格) original_str1 = "Dog" width1 = 8 result1 = original_str1.rjust(width1) print(f"使用默认填充字符的结果: '{result1}',长度为 {len(result1)}") #rjust 示例 2:指定填充字符 original_str2 = "Cat" width2 = 7 fill_char = '#' result2 = original_str2.rjust(width2, fill_char) print(f"使用指定填充字符的结果: '{result2}',长度为 {len(result2)}") #rjust 示例 3:width 小于原字符串长度 original_str3 = "Elephant" width3 = 5 result3 = original_str3.rjust(width3) print(f"width 小于原字符串长度的结果: '{result3}',长度为 {len(result3)}")
输出结果:
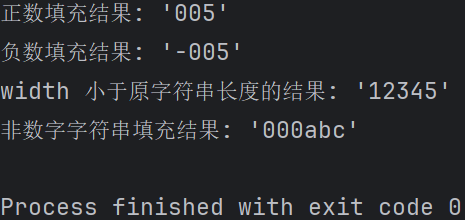
#zfill 示例 1:对正数进行填充 num_str1 = "5" width1 = 3 result1 = num_str1.zfill(width1) print(f"正数填充结果: '{result1}'") #zfill 示例 2:对负数进行填充 num_str2 = "-5" width2 = 4 result2 = num_str2.zfill(width2) print(f"负数填充结果: '{result2}'") #zfill 示例 3:width 小于原字符串长度 str3 = "12345" width3 = 3 result3 = str3.zfill(width3) print(f"width 小于原字符串长度的结果: '{result3}'") #zfill 示例 4:处理非数字字符串 text = "abc" width4 = 6 result4 = text.zfill(width4) print(f"非数字字符串填充结果: '{result4}'")
输出结果:
④.分割字符串(split splitlines和partition)
| 名称 | 语法格式 | 参数解释 | 功能 |
| split | string.split(sep=None,maxsplit=-1) |
|
用于将字符串按照指定的分隔符分割成多个子字符串,并返回一个包含这些子字符串的列表 |
| rsplit | string.rsplit(sep=None,maxsplit=-1) | 它的功能与 split() 类似,不过,rsplit() 是从字符串的右侧开始进行分割的 |
|
| splitllines | string.splitlines(keepends=False) |
若 若 |
按照行边界将字符串分割成多个行,并返回包含这些行的列表 |
| partition | string.partition(sep) |
|
根据指定的分隔符将字符串分割成三部分,并返回一个包含这三部分的元组 |
| rpartition | string.rpartition(sep) | 其功能与 partition() 类似,不过,rpartition() 是从字符串的右侧开始查找分隔符进行分割的 |
⑤.合并与替换(join replace)
| 名称 | 语法格式 | 参数解释 | 功能 |
| join | separator.join(iterable) |
|
将序列(如列表、元组等)中的元素以指定的字符串连接成一个新的字符串 |
| replace | string.replace(old, new[, count]) |
|
将字符串中的指定子字符串替换为另一个字符串 |
⑥.判断字符串(isidentifier isspace isalpha is decimal isnumeric和isalnum)
| 名称 | 语法格式 | 参数解释 | 功能 |
| isindentifier | string.isidentifier() |
返回值:如果字符串是有效的 Python 标识符,则返回 |
检查字符串是否是一个有效的 Python 标识符(字符 数字 下划线) |
| isspace | string.isspace() | 检查字符串是否完全由空白字符组成 | |
| isalpha | string.isalpha() |
返回值:如果字符串中的所有字符都是字母且字符串长度至少为 1,则返回 |
检查字符串是否只由字母(包含大写和小写字母)组成 |
| isdecimal | string.isdecimal() |
返回值:如果字符串中的所有字符都是十进制字符,并且字符串的长度至少为 1,则返回 |
用于检查字符串是否只包含十进制字符 |
| isdigit | string.isdigit() |
该方法不需要传入参数,它会返回一个布尔值:如果字符串中的所有字符都是数字,则返回 |
用于检查字符串是否只由数字字符组成 |
| isnumeric | string.isnumeric() | 用于检查字符串是否只由表示数值的字符组成 | |
| isalnum | string.isalnum() |
该方法不需要传入参数,会返回一个布尔值。如果字符串中的所有字符都是字母或数字,则返回 |
用于检查字符串是否只由字母(包含大小写)和数字组成 |
| islower | string.islower() |
该方法不接受任何参数,会返回一个布尔值。如果字符串中所有字母字符都是小写,且至少有一个字母字符,则返回 |
用于检查字符串中的所有字母字符是否都是小写形式 |
| isupper | string.isupper() |
此方法不接受任何参数,它会返回一个布尔值。若字符串里所有字母字符均为大写,并且字符串中至少存在一个字母字符,那么返回 |
用于检查字符串中的所有字母字符是否都为大写形式 |
| istitle | string.istitle() | string:要进行检查的字符串。
该方法不接受任何参数,会返回一个布尔值。如果字符串中每个单词的首字母都是大写,其余字母都是小写,并且字符串中至少有一个字母字符,则返回 |
用于检查字符串是否符合标题格式 |
| isascii | string.isascii() | string:待检查的字符串。
该方法不接受任何参数,返回一个布尔值。如果字符串中的所有字符的 Unicode 码点都在 0 – 127 之间(即 ASCII 字符集范围),则返回 |
用于检查字符串中的所有字符是否都在 ASCII 字符集中 |
| isprintable | string.isprintable() | string:需要进行检查的字符串。
该方法不接受任何参数,会返回一个布尔值。如果字符串中的所有字符都是可打印的,那么返回 |
用于检查字符串中的所有字符是否都是可打印的 |
| startswith | string.startswith(prefix, start=0, end=len(string)) |
|
用于检查字符串是否以指定的前缀开始 |
| endswith | string.endswith(suffix, start=0, end=len(string)) |
|
用于检查字符串是否以指定的后缀结束 |
⑦.去除两端多余字符操作
| 名称 | 语法格式 | 参数解释 | 功能 |
| lstrip | string.lstrip([chars]) |
返回值:返回一个新的字符串,该字符串是原字符串移除左/右侧指定字符序列后的结果,原字符串不会被修改。 |
用于移除字符串左侧的指定字符序列(默认为移除空白字符) |
| rstrip | string.rstrip([chars]) | 用于移除字符串右侧的指定字符序列(默认为移除空白字符) | |
| strip | string.strip([chars]) |
返回值:返回去除指定字符后的新字符串,原字符串不会被修改。 |
用于移除字符串首尾指定的字符(默认是移除空白字符) |
5.运算符
①.算数运算符:
| 运算符 | 描述 | 实例 |
| + | 加 | print(1 + 1)输出结果为2 |
| – | 减 | print(1 – 1)输出结果为0 |
| * | 乘 | print(2 * 2)输出结果为4 |
| / | 除 | print(10 / 2)输出结果为5 |
| // | 整除 | print(9 // 4)输出结果为2 |
| % | 取余 | print(9 // 4)输出结果为1 |
| ** | 幂 | 又称次方 乘方 指数 print(2 ** 4)输出结果为6 |
| () | 小括号 | 小括号用来提高运算的优先级,即print(1 + 2)* 3输出结果为9 |
input() 输入框加提示 输出的值全都是字符串类型
# 获取用户输入的两个数 try: num1 = int(input("请输入第一个数: ")) num2 = int(input("请输入第二个数: ")) # 进行加法运算 addition = num1 + num2 # 进行减法运算 subtraction = num1 - num2 # 进行乘法运算 multiplication = num1 * num2 # 进行除法运算,需要考虑除数为 0 的情况 if num2 != 0: division = num1 / num2 else: division = None print("错误:除数不能为 0。") # 输出运算结果 print(f"{num1} + {num2} = {addition}") print(f"{num1} - {num2} = {subtraction}") print(f"{num1} * {num2} = {multiplication}") if division is not None: print(f"{num1} / {num2} = {division}") except ValueError: print("输入无效,请输入有效的数字。")
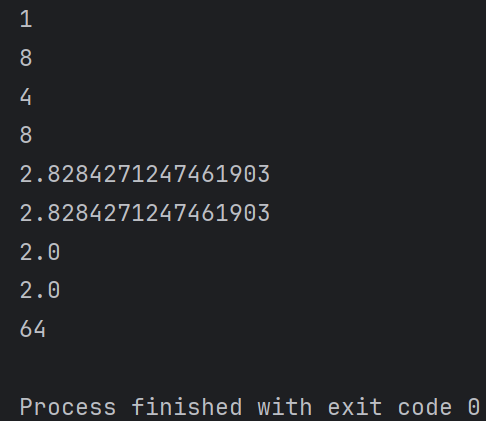
a = 17#判断奇数偶数 # 取余数 print(a % 2) # 取整数 print(a // 2) # 二次方也叫平方 print(2**2) #相当于(2*2) # 三次方也叫立方 print(2**3)#相当于(2*2*2) # 平方根 print(8**0.5) # 或是 print(8**(1/2))
# 立方根
print(8**(1/3)) #或是用幂的函数pow()
print(pow(8, 1/3))
# 平方
print(pow(8,2))
输出结果:
②.赋值运算符
| 运算符 | 描述 | 实例 |
| = | 赋值 | 将=右侧的结果赋值给=左侧的变量 |
③.复合赋值运算符
| 运算符 | 描述 | 实例 |
| += | 加法赋值运算符 | c += a 等价于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等价于 c = c – a |
| *= | 乘法赋值运算符 | c *= a 等价于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等价于 c = c / a |
| //= | 整除赋值运算符 | c //= a 等价于 c = c //= a |
| %= | 取余赋值运算符 | c %= a 等价于 c = c %= a |
| **= | 幂赋值运算符 | c **= a 等价于 c = c **= a |
注意:先计算后赋值
④.比较运算符
比较运算符也叫关系运算符,通常用来判断
| 运算符 | 描述 | 实例 |
| == | 判断相等或叫(恒等)。如果两个操作数的结果相等,则条件结果为真(True),否则条件结果为假(False) | 如 a = 3,b = 3 则print(a == b)为True |
| != | 不等于。如果两个操作数的结果不相等,则条件结果为真(True),否则条件结果为假(False) | 如 a = 3,b = 3 则print(a != b)为False,如 a = 1,b = 3 则print(a != b)为True |
| > | 大于。运算符左侧操作数结果是否大于右侧操作数结果。如果大于,则条件为真(True),如果小于,则条件为假(False)。 | 如 a = 7,b = 3 则print(a > b)为True |
| < | 小于。运算符左侧操作数结果是否小于右侧操作数结果。如果小于,则条件为真(True),如果大于,则条件为假(False)。 | 如 a = 7,b = 3 则print(a < b)为False |
| >= | 大于等于。运算符左侧操作数结果是否大于等于右侧操作数结果。如果大于或等于,则条件为真(True),如果小于,则条件为假(False)。 |
如 a = 7,b = 3 则print(a >= b)为True 如 a = 7,b = 7 则print(a >= b)为True |
| <= | 小于等于。运算符左侧操作数结果是否小于等于右侧操作数结果。如果小于或等于,则条件为真(True),如果小于,则条件为假(False)。 |
如 a = 7,b = 3 则print(a <= b)为False 如 a = 7,b = 7 则print(a <= b)为True |
⑤.逻辑运算符
| 运算符 | 逻辑表达式 | 描述 | 实例 |
| and | x and y | 布尔“与”“和”:如果x为False,x and y返回False,否则返回y的值。 | True and False,返回False,两个都为True,则返回True。 |
| or | x or y | 布乐“或”:如果x为True,则返回True,否则返回y的值。 | False or True,返回True,两个有一个为True,则返回True。 |
| not | not x | 布尔“非”:如果x为True,则返回Flase,如果x为False,则返回True。 | not True,返回Flase, not Flase,返回True。 |
6.转义字符
| 转义字符 | 描述 | 实例 |
| \n | 换行 | print()默认自带换行\n。print(‘换行’,end=’\n’) #end是结束符。取消换行的代码是print(123,end=”) |
| \t | 制表符,一个Tab键(四个空格)的距离,可以当作排版使用。 | print(‘he\tllo’)输出为:he llo |
| \\ | 取消转义,原样输出。 | print(‘we\\er’)输出为:we\er |
|
\’ 或 \“ |
字符串内,使用引号需要转义 | print(‘I\’m Yonge’)输出为:I’m Yonge |
| \e | 在 Python 里, \e 本身并不是标准的内置转义字符。Python 标准的转义字符包括像 \n(换行符)、 \t(制表符)、 \\(反斜杠)等。 不过, \e 在某些情境下会被当作 ANSI 转义序列的起始,用于在终端中控制文本的显示格式,比如设置文本颜色、样式等。在 ANSI 转义序列里, \e 通常表示 ESC 字符(ASCII 码为 27),也可以用 \033 来表示。 |
|
7.if判断 三元运算
True和False的界定:任何非零(0),非空(None)的对象都为真(True)。
数字0、空对象(None)均为假(False) ,判断的返回值为True(1)和False(0)。
a = 5 b = True #这里的True同等为数字1,如果是False的话就同等于数字0 print(a + b) #输出结果:6
两种流程控制语句:①.条件语句:if让程序根据条件有选择性的执行语句。
if子句必须有,elif子句可以有0个或者多个,else子句可以有0个或1个,且只能放在if子句最后。
在 Python 中,条件&判断&循环语句结构是通过冒号(:)和缩进(Tab键或是四个空格)来制定的。不缩进,外边的代码块就跟if没有关系。
②.判断循环语句if-else if-elif-else
if语句用于根据条件来决定是否执行特定的代码块。如果条件为真True,则执行if块中的代码。
age = 18 if age >= 18: print("你已经成年了。") #这里有缩进(Tab键或是四个空格)
#输出结果:你已经成年了。
print("你还未成年。") #这里没有缩进,输出结果是这行的print,而不会输出缩进的print。因为代码是从上往下执行的
#输出结果:你还未成年。
if-else是大多数编程语言中用于实现条件判断的控制结构,它允许程序根据不同的条件执行不同的代码块。
age = 18 if age >= 18: print("你已经成年了,可以投票。") else: print("你还未成年,不能投票。") #输出结果:你已经成年了,可以投票。
多条件判断if-elif-else在实际应用中,可能需要处理多个条件。
score = 85 if score >= 90: print("成绩为 A") elif score >= 80: print("成绩为 B") elif score >= 70: print("成绩为 C") elif score >= 60: print("成绩为 D") else: print("成绩为 F") #输出结果:成绩为:B
if嵌套是指在一个if语句的代码块中再包含另一个或多个if语句。这种结构允许你处理更复杂的条件逻辑。
# 定义变量 score = 85 attendance = 90 # 外层 if 语句 if score >= 60: print("你的成绩及格了。") # 内层 if 语句 if attendance >= 80: print("并且你的出勤率也达标了,表现不错!") else: print("但是你的出勤率不达标。") else: print("你的成绩不及格。") '''输出结果:你的成绩及格了。 并且你的出勤率也达标了,表现不错!'''
①.for循环语法
for 临时变量 in 序列:
重复执行的代码1
重复执行的代码2
……………………
for循环读取
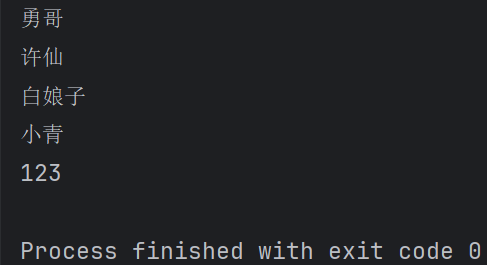
li=['勇哥', '许仙', '白娘子','小青',123] for i in li: # 这里的i是自定义变量,可以是其它。# li 是可迭代对象(通过for in 方式能够一个个把元素取出来) print(li) #这里的print()有缩进(按Tab键),代码才不会出错。
输出结果:

②.while 循环语法
while 条件:
条件成立重复执行的代码1
条件成立重复执行的代码2
………………………………
while循环读取
li=['勇哥', '许仙', '白娘子','小青',123] index = 0 #初始化一个变量index为 0,这个变量将作为列表的索引,用于访问列表中的元素。 while index < len(li): #这行代码设置了循环条件。len(li)会返回列表li的元素个数,只要index小于列表的长度,循环就会继续执行。 print(li[index]) #在每次循环中,通过索引index访问列表li中的元素,并将其打印输出。这里的print()有缩进(四个空格) index = index + 1 #这行代码将index的值增加1,以便在下一次循环中访问列表的下一个元素。防止死循环。
输出结果:
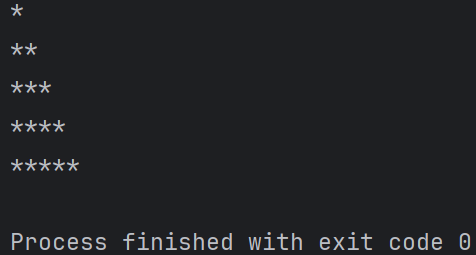
*号直角三角形
row = 1 while row <= 5: col = 1 while col <= row: print("*", end="") col += 1 print() row += 1
输出结果:
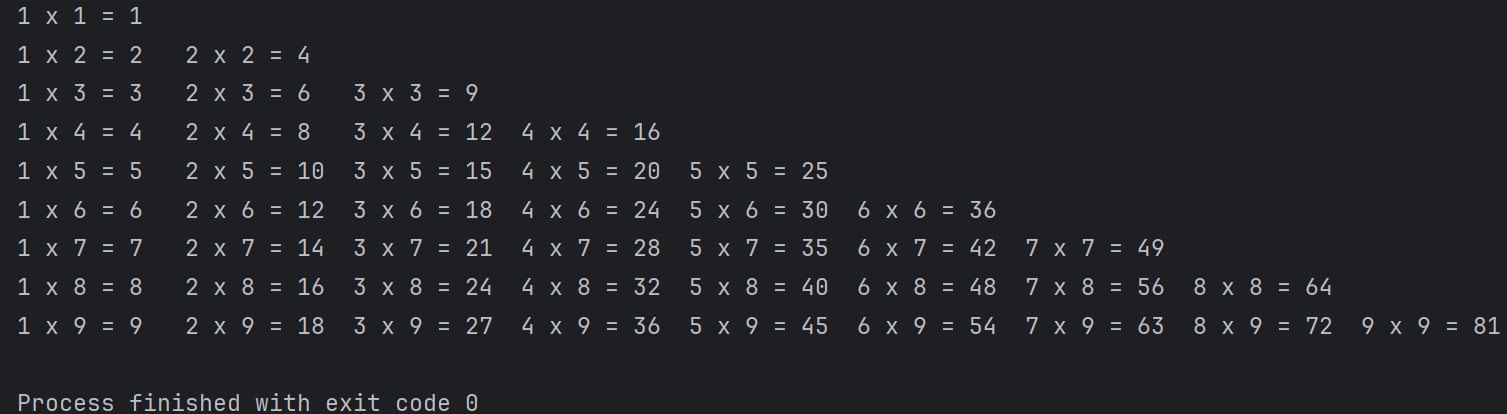
九九乘法表while循环
# 初始化外层循环的变量,控制行数,从 1 开始 i = 1 while i <= 9: # 初始化内层循环的变量,控制列数,从 1 开始 j = 1 while j <= i: # 打印乘法表达式,使用 end='\t' 让输出以制表符分隔 print(f"{j} x {i} = {i * j}", end='\t') # 列数加 1 j += 1 # 每行结束后换行 print() # 行数加 1 i += 1
#输出结果:同for循环
求100以内的素数(质数)
素数是只能被 1 和它本身整除的正整数。
for num in range(2, 101): is_prime = True for i in range(2, int(num ** 0.5) + 1): if num % i == 0: is_prime = False break if is_prime: print(num)
上述代码中,外层的for循环遍历从 2 到 100 的所有数字,因为 1 不是素数,所以从 2 开始。对于每个数字num,我们假设它是素数(将is_prime设为True),然后内层的for循环从 2 到该数的平方根(使用int(num ** 0.5) + 1)检查是否存在能整除它的数。如果存在这样的数,就将is_prime设为False并跳出内层循环。最后,如果is_prime仍然为True,则说明该数是素数,将其打印出来。
range函数:用于生成一系列不可变的整数序列,常用于 for 循环中控制迭代次数。
range() 函数有三种不同的调用方式:
①. range(stop)
参数说明:stop 是一个整数,表示生成序列的结束值(不包含该值)。生成的序列从 0 开始,步长为 1。
# 生成从 0 到 4 的整数序列 for i in range(5): print(i)
②. range(start, stop)
参数说明:start 是一个整数,表示生成序列的起始值(包含该值);stop 是一个整数,表示生成序列的结束值(不包含该值)。生成的序列步长为 1。
# 生成从 2 到 6 的整数序列 for i in range(2, 7): print(i) '''输出结果: 2 3 4 5 6 '''
③. range(start, stop, step)
参数说明:start 是起始值(包含该值),stop 是结束值(不包含该值),step 是步长,即相邻两个数之间的差值,可以是正数或负数,但不能为 0。
# 生成从 1 到 9 的奇数序列 for i in range(1, 10, 2): print(i) # 生成从 10 到 1 的递减序列 for i in range(10, 0, -1): print(i) '''输出结果: 1 3 5 7 9 10 9 8 7 6 5 4 3 2 1 '''
九九乘法表for循环
# 外层循环控制行数,从 1 到 9 for i in range(1, 10): # 内层循环控制列数,列数的范围从 1 到当前行数 for j in range(1, i + 1): # 打印乘法表达式,使用 end='\t' 表示以制表符分隔 print(f"{j} x {i} = {i * j}", end='\t') # 每行结束后换行 print()
输出结果:
猜拳游戏
import random # 定义选项列表 options = ["石头", "剪刀", "布"] while True: # 让玩家输入选择 player_choice = input("请输入你的选择(石头/剪刀/布),输入 '退出' 结束游戏:") # 检查玩家是否要退出游戏 if player_choice == "退出": print("游戏结束,再见!") break # 检查玩家输入是否有效 if player_choice not in options: print("输入无效,请输入 石头、剪刀 或 布。") continue # 计算机随机选择 computer_choice = random.choice(options) # 输出双方的选择 print(f"你出了 {player_choice},计算机出了 {computer_choice}。") # 判断胜负 if player_choice == computer_choice: print("平局!") elif ( (player_choice == "石头" and computer_choice == "剪刀") or (player_choice == "剪刀" and computer_choice == "布") or (player_choice == "布" and computer_choice == "石头") ): print("你赢了!") else: print("你输了!")
break和continue只能够在循环体内使用。
break(中断,强行终止):中途退出,结束循环。不再继续当层循环。只对当层循环有效。
continue(继续):结束当前的本轮循环,后面的代码不再执行,然后进行下一轮循环。
# 初始化变量 a a = 0 while a < 5: a = a + 1 if a == 3: break else: #在 Python 中,while 循环可以带有一个 else 子句。当 while 循环的条件变为 False 时(即正常结束循环),会执行 else 子句中的代码;
#但如果循环是因为 break 语句而终止的,则不会执行 else 子句。 print("已经执行完成!")
死循环
#死循环1 a = 0 while a <5: if a == 3: continue print(a) a = a + 1 #死循环2 li = ['勇哥', '许仙', '白娘子', '小青', 123] index = 0 while index < len(li): print(li[index])
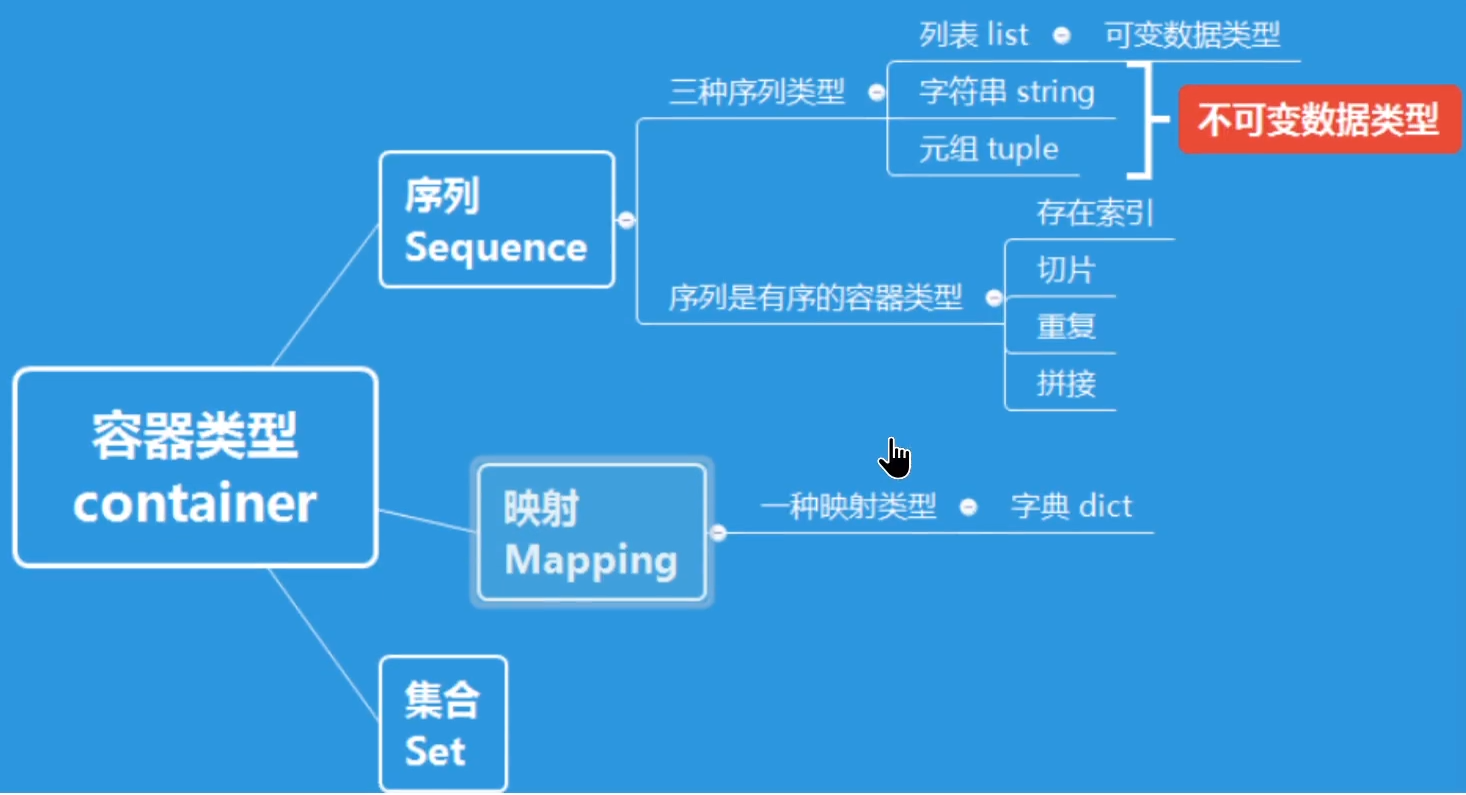
列表[list]:可以一次存储多个数据。用中括号[]包围所有元素,每个元素间用逗号隔开。
特性:有序。存储多个数据时,元素可以是不同类型。
li=['勇哥', '许仙', '白娘子','小青',123] print(li[[0]) #或者 print(li[-5]) #输出结果:勇哥
列表[list]是可变的数据结构,可以通过索引来直接修改列表中的元素。
# 定义一个列表 my_list = [10, 20, 30, 40, 50] # 修改索引为 2 的元素(索引从 0 开始) my_list[2] = 300 print(my_list)
# 输出结果: [10, 20, 300, 40, 50]
#一组数据修改方法
nums = [1, 2, 3, 4, 5, 6, 7, 8, 9]
nums[2:5] = [10, 11, 12]
print(nums)
#输出结果:[1, 2, 10, 11, 12, 6, 7, 8, 9]
列表的操作:增删改查
insert:插入。语法:list.insert(index, element)
insert() 方法会直接修改原列表,而不会返回一个新列表。
my_list = [2, 3, 4] # 在索引 0 的位置插入元素 1 my_list.insert(0, 1) print(my_list) #输出结果:[1,2,3,4]
append(附加,增补):末尾追加。语法:list.append(element)
用于在列表的末尾添加一个新元素,只能添加一个元素。该元素可以是任意数据类型,比如整数、字符串、列表、元组、字典等。
# 定义一个存储水果名称的列表 fruits = ['apple', 'banana'] # 使用 append 方法添加一个字符串 'cherry' 到列表末尾 fruits.append('cherry') print(fruits) #输出结果:['apple', 'banana', 'cherry']
extend(扩展)追加:语法:list.extend(iterable)
将可迭代对象的每个元素添加到列表中,可一次添加多个元素。
fruits = ["apple", "banana"] more_fruits = ["orange", "grape"] # 使用 extend 添加 more_fruits 中的元素 fruits.extend(more_fruits) print(fruits) # 输出结果: ['apple', 'banana', 'orange', 'grape'] letters = ["a", "b"] word = "hello" # 使用 extend 添加 word 中的字符 letters.extend(word) print(letters) # 输出结果: ['a', 'b', 'h', 'e', 'l', 'l', 'o']
del:用于删除对象或对象的元素。它可以用于删除变量、列表中的元素、字典中的键值对,甚至删除整个对象。
删除后该变量将不再存在。
x = 10 print(x) # 输出结果: 10 del x try: print(x) except NameError: print("变量 x 已被删除") # 输出结果: 变量 x 已被删除 #可借助 del 语句依据索引删除列表中的特定元素。 my_list = [10, 20, 30, 40, 50] # 删除索引为 2 的元素 del my_list[2] print(my_list) # 输出结果: [10, 20, 40, 50] # 也可以使用切片删除多个元素 my_list = [10, 20, 30, 40, 50] del my_list[1:3] print(my_list) # 输出结果: [10, 40, 50] #利用 del 语句能够根据键删除字典里的键值对 my_dict = {'name': 'Alice', 'age': 25, 'city': 'New York'} # 删除键为 'age' 的键值对 del my_dict['age'] print(my_dict) # 输出结果: {'name': 'Alice', 'city': 'New York'} #在类的实例中,del 语句可以用来删除对象的属性。 class Person: def __init__(self, name, age): self.name = name self.age = age p = Person('Bob', 30) print(p.age) # 输出结果: 30 del p.age try: print(p.age) except AttributeError: print("属性 age 已被删除") # 输出结果: 属性 age 已被删除
pop: 语法:list.pop([index])index要移除元素的索引,若不提供则默认为 -1,即最后一个元素。
可以移除并返回列表中指定索引位置的元素。如果不指定索引,默认移除并返回列表的最后一个元素。
# 创建一个列表 my_list = [10, 20, 30, 40, 50] # 不指定索引,移除并返回最后一个元素 last_element = my_list.pop() print(last_element) # 输出结果: 50 print(my_list) # 输出结果: [10, 20, 30, 40] # 指定索引,移除并返回索引为 1 的元素 second_element = my_list.pop(1) print(second_element) # 输出结果: 20 print(my_list) # 输出结果: [10, 30, 40]
列表排序
| 名称 | 语法格式 | 参数解释 | 功能 |
| reverse | list.reverse() |
|
|
| sort |
list.sort(key=None, reverse=False) |
在对可迭代对象进行排序时,可以使用 sort() 方法(列表对象专属)或 sorted() 内置函数,它们都有一个可选的 reverse 参数,该参数是布尔类型,用于控制排序的顺序。 |
|
| sorted |
sorted(iterable, key=None, reverse=False) |
#reverse my_list = [1, 2, 3, 4, 5] result = my_list.reverse() print(my_list) # 输出: [5, 4, 3, 2, 1] print(result) # 输出: None # 使用 sort() 方法进行降序排序 numbers = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5] numbers.sort(reverse=True) print(numbers) # 输出: [9, 6, 5, 5, 5, 4, 3, 3, 2, 1, 1] # 使用 sorted() 函数进行降序排序 numbers = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5] sorted_numbers = sorted(numbers, reverse=True) print(sorted_numbers) # 输出: [9, 6, 5, 5, 5, 4, 3, 3, 2, 1, 1] print(numbers) # 原列表不变,输出: [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
元组(tuple)是一种不可变的序列类型,用于存储多个元素。元组使用圆括号 () 来表示,元素之间用逗号分隔。需要注意的是,当元组中只有一个元素时,需要在元素后面加上逗号,否则会被视为普通的数据类型。
# 创建一个空元组 empty_tuple = () # 创建包含元素的元组 single_element_tuple = (1,) # 只有一个元素的元组,需要在元素后加逗号 normal_tuple = (1, 2, "hello", 3.14) # 省略圆括号创建元组 implicit_tuple = 4, 5, 6 print(empty_tuple) #输出结果:() print(single_element_tuple) #输出结果:(1,) print(normal_tuple) #输出结果:(1, 2, 'hello', 3.14) print(implicit_tuple) #输出结果:(4, 5, 6)
访问元组元素:同列表一样使用索引来访问元素,索引从 0 开始,也支持负数索引从末尾访问。
my_tuple = ("apple", "banana", "cherry") # 访问第一个元素 first_element = my_tuple[0] print(first_element) #输出结果:apple # 访问最后一个元素 last_element = my_tuple[-1] print(last_element) ##输出结果:cherry
元组同样支持切片操作,语法和列表的切片操作一致,即 tuple[start:stop:step]。
numbers = (0, 1, 2, 3, 4, 5, 6, 7, 8, 9) # 提取索引 2 到 5 的元素(不包括索引 5) sliced_tuple = numbers[2:5] print(sliced_tuple) #输出结果:(2, 3, 4) # 提取偶数索引的元素 even_index_tuple = numbers[::2] print(even_index_tuple) #输出结果:(0, 2, 4, 6, 8)
元组的一个重要特性是不可变,这意味着一旦创建了元组,就不能修改、添加或删除其中的元素。
try: my_tuple = (1, 2, 3) my_tuple[0] = 10 # 尝试修改元组元素,会引发 TypeError except TypeError as e: print(f"发生错误: {e}")
元组的常用方法:count() 用于返回指定元素在元组中出现的次数。
my_tuple = (1, 2, 2, 3, 2) count = my_tuple.count(2) print(count) #输出结果:3
index() 用于返回指定元素在元组中第一次出现的索引,如果元素不存在则会引发 ValueError。
my_tuple = ("apple", "banana", "cherry") index = my_tuple.index("banana") print(index) #输出结果:1
元组的遍历:可以使用 for 循环来遍历元组中的元素。
fruits = ("apple", "banana", "cherry") for fruit in fruits: print(fruit) #输出结果:apple banana cherry
元组的长度:使用 len() 函数可以获取元组的长度。
my_tuple = (1, 2, 3, 4, 5) length = len(my_tuple) print(length) #输出结果:5
元组的优点:
由于元组是不可变的,Python 在处理元组时会有一些性能上的优化,比如元组的哈希操作比列表更快,所以元组可以作为字典的键。
不可变性保证了数据在程序运行过程中不会被意外修改,提高了数据的安全性。
元组和列表的互转
可以使用 list() 函数将元组转换为列表,使用 tuple() 函数将列表转换为元组。
my_tuple = (1, 2, 3) my_list = list(my_tuple) print(my_list) #输出结果:[1, 2, 3] new_list = [4, 5, 6] new_tuple = tuple(new_list) print(new_tuple) #输出结果:(4,5,6)
字典(dict):是一种无序、可变且可迭代的数据类型,用于存储键值对(key – value pairs)。每个键必须是唯一的,且键必须是不可变的数据类型(如字符串、数字或元组),而值可以是任意数据类型(如字符串、数字、列表、元组、字典等)。
创建字典:使用花括号{}
# 创建一个空字典 empty_dict = {} # 创建一个包含键值对的字典 person = { "name": "Alice", "age": 25, "city": "New York" } print(person) #输出结果:{'name': 'Alice', 'age': 25, 'city': 'New York'}
使用dict()构造函数
# 使用关键字参数创建字典 person = dict(name="Bob", age=30, city="Los Angeles") print(person) #输出结果:{'name': 'Bob', 'age': 30, 'city': 'Los Angeles'} # 使用可迭代对象创建字典 data = [("name", "Charlie"), ("age", 35), ("city", "Chicago")] person = dict(data) print(person) #{'name': 'Charlie', 'age': 35, 'city': 'Chicago'}
访问字典中的值
可以通过键来访问字典中的值,如果键不存在,会引发 KeyError 异常。
person = { "name": "Alice", "age": 25, "city": "New York" } # 通过键访问值 name = person["name"] print(name) #输出结果:Alice # 使用 get() 方法访问值,如果键不存在,返回默认值(默认为 None) age = person.get("age") print(age) #输出结果:25 # 提供默认值 job = person.get("job", "Unknown") print(job) #输出结果:Unknown
修改和添加键值对
person = { "name": "Alice", "age": 25, "city": "New York" } # 修改现有键的值 person["age"] = 26 print(person) #输出结果:{'name': 'Alice', 'age': 26, 'city': 'New York'} # 添加新的键值对 person["job"] = "Engineer" print(person) #输出结果:{'name': 'Alice', 'age': 26, 'city': 'New York', 'job': 'Engineer'}
删除键值对:可以使用 del 语句或 pop() 方法删除字典中的键值对。
person = { "name": "Alice", "age": 25, "city": "New York" } # 使用 del 语句删除键值对 del person["city"] print(person) #输出结果:{'name': 'Alice', 'age': 25} # 使用 pop() 方法删除键值对,并返回被删除的值 age = person.pop("age") print(age) #输出结果:25 print(person) #输出结果:{'name': 'Alice'}
字典的常用方法
keys():返回一个包含字典所有键的视图对象。
values():返回一个包含字典所有值的视图对象。
items():返回一个包含字典所有键值对的视图对象。
clear():清空字典。
copy():返回字典的浅拷贝。
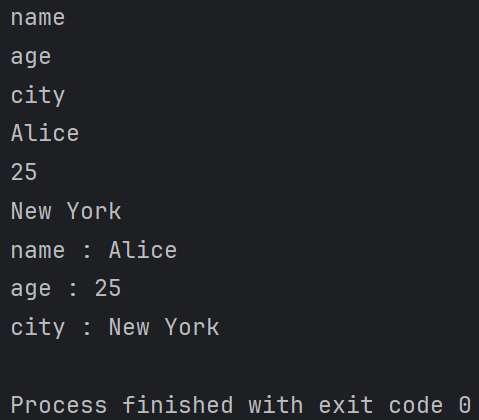
person = { "name": "Alice", "age": 25, "city": "New York" } # 获取所有键 keys = person.keys() print(list(keys)) #输出结果:['name', 'age', 'city'] # 获取所有值 values = person.values() print(list(values)) #输出结果:['Alice', 25, 'New York'] # 获取所有键值对 items = person.items() print(list(items)) #输出结果:[('name', 'Alice'), ('age', 25), ('city', 'New York')] # 清空字典 person.clear() print(person) 输出结果:{}
遍历字典:可以使用 for 循环遍历字典的键、值或键值对。
person = { "name": "Alice", "age": 25, "city": "New York" } # 遍历键 for key in person: print(key) # 遍历值 for value in person.values(): print(value) # 遍历键值对 for key, value in person.items(): print(key, ":", value)
输出结果:
集合(set):是一种无序、可变且不包含重复元素的数据类型。集合主要用于成员检测、消除重复元素以及进行交集、并集、差集等数学运算。
创建集合:使用花括号{}
# 创建一个包含元素的集合 fruits = {'apple', 'banana', 'cherry'} print(fruits) #输出结果:{'apple', 'banana', 'cherry'} # 注意:不能使用 {} 创建空集合,因为这会创建一个空字典 # 空集合应使用 set() 函数创建 empty_set = set() print(empty_set) #输出结果:set()
使用 set() 构造函数
# 从列表创建集合 numbers = [1, 2, 3, 2, 1] unique_numbers = set(numbers) print(unique_numbers) #输出结果:{1, 2, 3} # 从字符串创建集合 letters = set('hello') print(letters) #输出结果:{'l', 'h', 'e', 'o'}
访问集合元素
由于集合是无序的,不能通过索引访问集合中的元素。但可以使用 in 关键字检查元素是否存在于集合中。
fruits = {'apple', 'banana', 'cherry'}
print('apple' in fruits) # 输出结果: True
print('grape' in fruits) # 输出结果: False
添加元素
add() 方法:用于向集合中添加单个元素。
update() 方法:用于向集合中添加多个元素,可以是列表、元组、集合等可迭代对象。
fruits = {'apple', 'banana'}
# 添加单个元素
fruits.add('cherry')
print(fruits)
#输出结果:{'banana', 'cherry', 'apple'}
# 添加多个元素
fruits.update(['grape', 'orange'])
print(fruits)
#输出结果:
{'banana', 'grape', 'apple', 'cherry', 'orange'}
删除元素
remove() 方法:用于删除集合中的指定元素,如果元素不存在,会引发 KeyError 异常。
discard() 方法:用于删除集合中的指定元素,如果元素不存在,不会引发异常。
pop() 方法:随机删除并返回集合中的一个元素。
clear() 方法:清空集合中的所有元素。
fruits = {'apple', 'banana', 'cherry'}
# 使用 remove() 删除元素
fruits.remove('banana')
print(fruits)#输出结果:{'apple', 'cherry'}
# 使用 discard() 删除元素
fruits.discard('cherry')
print(fruits) #输出结果:{'apple'}
# 使用 pop() 删除元素
removed_fruit = fruits.pop()
print(removed_fruit)
print(fruits) #输出结果:apple
# 使用 clear() 清空集合
fruits.clear()
print(fruits) #输出结果:set()
集合的数学运算
交集(& 或 intersection() 方法):返回两个集合中共同拥有的元素。
set1 = {1, 2, 3, 4}
set2 = {3, 4, 5, 6}
# 使用 & 运算符
intersection = set1 & set2
print(intersection) #输出结果:{3, 4}
# 使用 intersection() 方法
intersection = set1.intersection(set2)
print(intersection) #输出结果:{3, 4}
并集(| 或 union() 方法):返回两个集合中所有不重复的元素。
set1 = {1, 2, 3, 4}
set2 = {3, 4, 5, 6}
# 使用 | 运算符
union = set1 | set2
print(union) #输出结果:{1, 2, 3, 4, 5, 6}
# 使用 union() 方法
union = set1.union(set2)
print(union) #输出结果:{1, 2, 3, 4, 5, 6}
差集(- 或 difference() 方法):返回在第一个集合中但不在第二个集合中的元素。
set1 = {1, 2, 3, 4}
set2 = {3, 4, 5, 6}
# 使用 - 运算符
difference = set1 - set2
print(difference) #输出结果:{1, 2}
# 使用 difference() 方法
difference = set1.difference(set2)
print(difference) #输出结果:{1, 2}
对称差集(^ 或 symmetric_difference() 方法):返回两个集合中不共同拥有的元素。
set1 = {1, 2, 3, 4}
set2 = {3, 4, 5, 6}
# 使用 ^ 运算符
symmetric_difference = set1 ^ set2
print(symmetric_difference)
#输出结果:{1, 2, 5, 6}
# 使用 symmetric_difference() 方法
symmetric_difference = set1.symmetric_difference(set2)
print(symmetric_difference)
#输出结果:{1, 2, 5, 6}
集合的其他常用方法
len():返回集合中元素的数量。
issubset():判断一个集合是否是另一个集合的子集。
issuperset():判断一个集合是否是另一个集合的超集。
set1 = {1, 2, 3}
set2 = {1, 2, 3, 4, 5}
# 获取集合元素数量
print(len(set1)) #输出结果:3
# 判断子集关系
print(set1.issubset(set2)) # 输出结果: True
# 判断超集关系
print(set2.issuperset(set1)) # 输出结果: True
成员运算符
in:主要用于检查某个元素是否是另一个序列(如列表、元组、字符串、集合、字典等)的成员。
#列表 my_list = [1, 2, 3, 4, 5] print(3 in my_list) # 输出结果: True print(6 in my_list) # 输出结果: False #字符串 my_list = [1, 2, 3, 4, 5] print(3 in my_list) # 输出结果: True print(6 in my_list) # 输出结果: False #字典 my_dict = {'name': 'Alice', 'age': 25} print('name' in my_dict) # 输出结果: True print('city' in my_dict) # 输出结果: False #for循环 my_list = [1, 2, 3, 4, 5] for num in my_list: print(num)
not in:用于检查某个元素是否不在特定的数据结构或集合中
#列表 my_list = [1, 2, 3, 4, 5] print(6 not in my_list) # 输出结果: True,因为 6 不在列表中 print(3 not in my_list) # 输出结果: False,因为 3 在列表中 #字符串 my_string = "Hello, World!" print("Python" not in my_string) # 输出结果: True,因为 "Python" 不在字符串中 print("World" not in my_string) # 输出结果: False,因为 "World" 在字符串中 #字典 my_dict = {'name': 'Alice', 'age': 25} print('city' not in my_dict) # 输出结果: True,因为 'city' 不是字典的键 print('name' not in my_dict) # 输出结果: False,因为 'name' 是字典的键
count: 用于统计指定元素在列表 字符串 元组等出现的次数。
#列表 my_list = [1, 2, 3, 2, 4, 2] # 统计元素 2 在列表中出现的次数 count = my_list.count(2) print(count) # 输出结果: 3 #字符串 my_string = "hello world, hello python" # 统计子字符串 "hello" 在字符串中出现的次数 count = my_string.count("hello") print(count) # 输出结果: 2 # 指定起始和结束位置 count = my_string.count("hello", 6) print(count) # 输出结果: 1 #元组 my_tuple = (1, 2, 3, 2, 4, 2) # 统计元素 2 在元组中出现的次数 count = my_tuple.count(2) print(count) # 输出结果: 3
推导式(Comprehension)是一种简洁且高效的创建列表、集合、字典等数据结构的方式。它允许你使用简洁的语法从一个可迭代对象(如列表、元组、集合等)中快速生成新的数据结构。
列表推导式:用于快速创建列表。 语法:[expression for item in iterable if condition]
expression:是对每个 item 进行操作的表达式,最终结果会作为新列表的元素。
item:是从 iterable 中取出的每个元素。
iterable:是一个可迭代对象,如列表、元组、集合等。
if condition:是可选的条件语句,用于过滤元素,只有满足条件的元素才会被包含在新列表中。
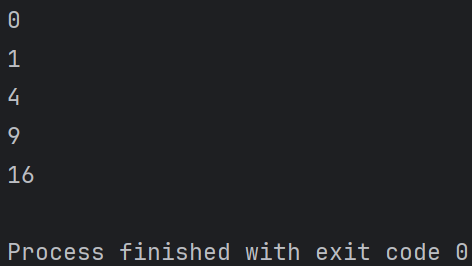
# 生成一个包含 0 到 9 的平方的列表 squares = [i**2 for i in range(10)] print(squares) # 输出结果: [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] # 过滤出列表中的偶数 numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] even_numbers = [i for i in numbers if i % 2 == 0] print(even_numbers) # 输出结果: [2, 4, 6, 8, 10]
集合推导式:集合推导式与列表推导式类似,只不过它生成的是集合(set),集合中的元素是唯一的。
# 生成一个包含 0 到 9 的平方的集合 squares_set = {i**2 for i in range(10)} print(squares_set) # 输出结果: {0, 1, 4, 9, 16, 25, 36, 49, 64, 81} # 过滤出列表中的偶数并生成集合 numbers = [1, 2, 2, 3, 4, 4, 5, 6, 6, 7, 8, 8, 9, 10, 10] even_numbers_set = {i for i in numbers if i % 2 == 0} print(even_numbers_set) # 输出结果: {2, 4, 6, 8, 10}
字典推导式:用于快速创建字典。
语法:{key_expression: value_expression for item in iterable if condition}
# 生成一个包含 0 到 4 的数字及其平方的字典 squares_dict = {i: i**2 for i in range(5)} print(squares_dict) # 输出结果: {0: 0, 1: 1, 2: 4, 3: 9, 4: 16} # 交换字典的键和值 original_dict = {'a': 1, 'b': 2, 'c': 3} swapped_dict = {value: key for key, value in original_dict.items()} print(swapped_dict) # 输出结果: {1: 'a', 2: 'b', 3: 'c'}
函数格式:
def 函数名(参数):
内部代码有缩进(Tab)键
函数名()
def sing(): print('我想唱歌!') sing() #输出结果:我想唱歌!
传值:直接往小括号里面写你要传递的数据。
注意:def 变量名():这个变量名可以随便起名字,最好是按照代码的功能去起名字。做到见字明意。
如果在定义的小括号里面没有写参数,也就是变量,那么就不要去传。
如果在定义的小括号里面写了参数,也就是变量,写了几个就传递几个。
def Demo(a, b): print('进入了Demo函数') print(a) print(b) Demo(100,200) #输出结果:100 200
return返回值
def sum = (a,b) c = a + b return c d = (10,20) print(d) #输出结果:30
全局环境&局部环境:局部变量可以使用全局变量,反过来,则不行。
a = 100 def test(): b = 200 print(a) #局部变量可以使用全局变量 print(a) test() print(b)#全局变量不可以使用局部变量 #输出结果:100且会提示b变量未定义
只有def定义的函数的内部代码块才算是局部环境变量,不是看缩进。
if 1 == 1: b = 200 print(b) #输出结果:200 for i in range(10): kiss = 520 print(kiss) #输出结果:520
global:将局部环境变量升级为全局环境变量。
a = 100 def test(): global b #将局部环境变量升级为全局环境变量 b = 200 test() print(b) #输出结果:200
文件操作:
# 以追加模式打开文件,如果文件不存在则创建新文件 f = open(r"E:\Python code\差不多~勇哥是自学小天才.txt", mode='a', encoding='utf-8') # 使用 write 方法向文件中追加内容 f.write('我爱python') # 关闭文件,释放系统资源 f.close()
r:创建原始字符串(raw string)的前缀。目的是防止反斜杠 \ 被当作转义字符处理,从而准确表示文件的完整路径。
open():打开文件并返回一个文件对象,借助这个文件对象,你可以对文件进行读取、写入、追加等操作。
mode 参数:该参数用于指定文件的打开模式,常见的模式有以下几种:
'r':只读模式(默认值),用于读取文件内容。若文件不存在,会抛出 FileNotFoundError 异常。
'w':写入模式,用于向文件写入内容。如果文件已存在,会先清空文件内容;若文件不存在,则会创建新文件。
'a':追加模式,用于在文件末尾追加内容。若文件不存在,会创建新文件。
'b':二进制模式,可与上述模式组合使用(如 'rb'、'wb'),用于处理二进制文件(如图片、音频等)。
'x':创建模式,若文件不存在则创建新文件并以写入模式打开;若文件已存在,会抛出 FileExistsError 异常。
with语句:
with 语句是 Python 中的上下文管理器,用于简化资源管理。在处理文件、网络连接、数据库连接等需要手动打开和关闭的资源时,使用 with 语句可以自动完成资源的清理工作,无需手动调用 close() 方法。当代码块执行完毕或出现异常时,with 语句会自动调用资源对象的 __exit__() 方法来关闭资源。简单的说,它会自动管理文件的打开和关闭,当代码块执行完毕后,文件会被自动关闭,避免了手动调用 close 方法的麻烦
with open(r"E:\Python code\差不多~勇哥是自学小天才.txt", encoding='utf-8') as f: # 读取文件的全部内容 content = f.read() # 打印文件内容 print(content) # 离开 with 语句块后,文件会自动关闭
正则表达式:
在Python中正则表达式是一种强大的文本处理工具,用于匹配、查找、替换和分割字符串。Python 通过re模块提供了对正则表达式的支持。
import re
re.match() 从字符串的起始位置开始匹配,如果匹配成功,则返回一个匹配对象;否则返回None。
import re pattern = r'hello' string = 'hello world' match_obj = re.match(pattern, string) if match_obj: print("匹配成功:", match_obj.group()) else: print("匹配失败") #输出结果:匹配成功: hello
#coding=utf-8# 导入re模块 import re # 使用match方法进行匹配操作 result = re.match(正则表达式,要匹配的字符串) # 如果上一步匹配到数据的话,可以使用group方法来提取数据 result.group()
re模块示例(匹配以itcast开头的语句)
import re result = re.match("yonge","yonge.cn") print(result.group()) #输出结果:yonge
re.search() 在字符串中搜索匹配正则表达式的第一个位置,如果匹配成功,则返回一个匹配对象;否则返回None。
import re pattern = r'world' string = 'hello world' search_obj = re.search(pattern, string) if search_obj: print("匹配成功:", search_obj.group()) else: print("匹配失败") #输出结果:匹配成功: world
re.findall() 在字符串中搜索所有匹配正则表达式的子串,并以列表的形式返回。
import re pattern = r'\d+' string = 'abc123def456' result = re.findall(pattern, string) print(result) #输出结果:['123', '456']
re.split() 根据正则表达式匹配的子串来分割字符串,并返回分割后的列表。
import re pattern = r'[ ,.]' string = 'hello, world. python' result = re.split(pattern, string) print(result) #输出结果:['hello', '', 'world', '', 'python']
re.sub() 用于替换字符串中匹配正则表达式的子串。
import re pattern = r'\d+' string = 'abc123def456' new_string = re.sub(pattern, 'xxx', string) print(new_string) #输出结果:abcxxxdefxxx
匹配对象常用的方法:
| 名称 | 功能 |
| group() | 返回匹配的子串。 |
| start() | 返回匹配子串的起始位置。 |
| end() | 返回匹配子串的结束位置。 |
| span() | 返回一个元组,包含匹配子串的起始和结束位置。 |
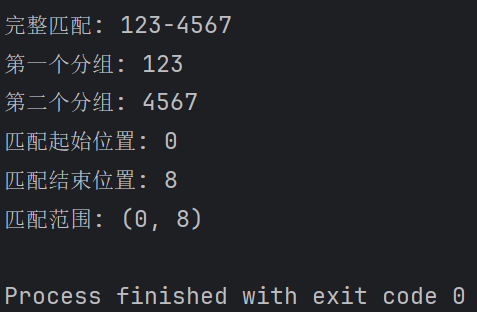
import re pattern = r'(\d{3})-(\d{4})' string = '123-4567' match_obj = re.search(pattern, string) if match_obj: print("完整匹配:", match_obj.group()) print("第一个分组:", match_obj.group(1)) print("第二个分组:", match_obj.group(2)) print("匹配起始位置:", match_obj.start()) print("匹配结束位置:", match_obj.end()) print("匹配范围:", match_obj.span())
输出结果:
常用的正则表达式元字符和模式
| 字符匹配 | 功能 |
| . | 匹配除换行符以外的任意单个字符 |
| \d | 匹配任意一个数字,等价于[0-9] |
| \D | 匹配任意一个非数字字符,等价于[^0-9] |
| \w | 匹配任意一个字母、数字或下划线,等价于[a-zA-Z0-9_] |
| \W | 匹配任意一个非字母、数字或下划线的字符,等价于[^a-zA-Z0-9_] |
| \s | 匹配任意一个空白字符,包括空格、制表符、换行符等,等价于[ \t\n\r\f\v] |
| \S | 匹配任意一个非空白字符,等价于[^ \t\n\r\f\v] |
| 数量限定 | 功能 |
| * | 匹配前面的字符 0 次或多次 |
| + | 匹配前面的字符 1 次或多次 |
| ? | 匹配前面的字符 0 次或 1 次 |
| {n} | 匹配前面的字符恰好 n 次 |
| {n,} | 匹配前面的字符至少 n 次 |
| {n,m} | 匹配前面的字符至少 n 次,最多 m 次 |
| 边界匹配 | 功能 |
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的结尾 |
注册信息:
import re def validate_username(username): # 用户名只能包含字母、数字和下划线,长度在 3 到 20 个字符之间 pattern = r'^[a-zA-Z0-9_]{3,20}$' return re.match(pattern, username) is not None def validate_password(password): # 密码长度至少为 8 个字符,必须包含至少一个大写字母、一个小写字母和一个数字 pattern = r'^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d]{8,}$' return re.match(pattern, password) is not None def validate_email(email): # 简单的邮箱格式验证 pattern = r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$' return re.match(pattern, email) is not None def validate_phone(phone): # 手机号码验证,以 1 开头,共 11 位数字 pattern = r'^1\d{10}$' return re.match(pattern, phone) is not None def register(): username = input("请输入用户名(3-20 个字母、数字或下划线):") if not validate_username(username): print("用户名格式不正确,请重新输入。") return password = input("请输入密码(至少 8 位,包含至少一个大写字母、一个小写字母和一个数字):") if not validate_password(password): print("密码格式不正确,请重新输入。") return email = input("请输入邮箱地址:") if not validate_email(email): print("邮箱格式不正确,请重新输入。") return phone = input("请输入手机号码:") if not validate_phone(phone): print("手机号码格式不正确,请重新输入。") return print("注册成功!") # 这里可以添加将注册信息保存到数据库等操作 if __name__ == "__main__": register()
常见的正则表达式
手机号校验
中国大陆手机号一般是 11 位数字,以 1 开头,第二位可能是 3、4、5、6、7、8、9 等
正则表达式:/^1[3456789]\d{9}$/
解释:
^ 表示匹配字符串的开始。
1 表示手机号以 1 开头。
[3456789] 表示第二位是 3 到 9 中的任意一个数字。
\d{9} 表示后面跟着 9 位数字。
$ 表示匹配字符串的结束。
邮箱校验
正则表达式:/^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$/
解释:
^ 匹配字符串开始。
[a-zA-Z0-9._%+-]+ 表示用户名部分,可以包含字母、数字、点、下划线、百分号、加号和减号,且至少有一个字符。
@ 匹配 @ 符号。
[a-zA-Z0-9.-]+ 表示域名部分,包含字母、数字、点和减号。
\. 匹配实际的点号(因为点号在正则中有特殊含义,所以需要转义)。
[a-zA-Z]{2,} 表示顶级域名,至少有两个字母。
$ 匹配字符串结束。
身份证号码校验(18 位)
正则表达式:/^[1-9]\d{5}(18|19|20)\d{2}(0[1-9]|1[0-2])(0[1-9]|[12]\d|3[01])\d{3}[0-9Xx]$/
解释:
^ 匹配字符串开始。
[1-9]\d{5} 表示前 6 位地址码,第一位不能是 0。
(18|19|20)\d{2} 表示年份,限定在 1800 到 2099 之间。
(0[1-9]|1[0-2]) 表示月份,01 到 12。
(0[1-9]|[12]\d|3[01]) 表示日期,根据月份合理取值。
\d{3} 表示顺序码。
[0-9Xx] 表示校验码,X 可以是大写或小写。
$ 匹配字符串结束。
密码强度校验(至少包含字母和数字,长度 8 到 20 位)
正则表达式:/^(?=.*[a-zA-Z])(?=.*\d)[a-zA-Z\d]{8,20}$/大小写皆可 或 /^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d]{8,}$/至少包含一个大写字母。
解释:
^ 匹配字符串开始。
(?=.*[a-zA-Z]) 是一个正向预查,表示字符串中至少有一个字母。
(?=.*\d) 是一个正向预查,表示字符串中至少有一个数字。
[a-zA-Z\d]{8,20} 表示由字母和数字组成,长度在 8 到 20 位之间。
$ 匹配字符串结束。
URL校验
正则表达式:/^(https?|ftp):\/\/([a-zA-Z0-9.-]+(\:[a-zA-Z0-9.&%$-]+)*@)*((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)|([a-zA-Z0-9-]+\.)*[a-zA-Z0-9-]+\.(com|edu|gov|int|mil|net|org|biz|arpa|info|name|pro|aero|coop|museum|[a-zA-Z]{2})(:\d+)?(\/($|[a-zA-Z0-9.,?’\\+&%$#=~_-]+))*$/
解释:
^ 匹配字符串开始。
(https?|ftp) 匹配协议,可以是 http、https 或 ftp。
:\/\/ 匹配 :// 分隔符。
后面复杂的部分是对域名、IP 地址、端口、路径等的匹配和限定。
$ 匹配字符串结束。
整数校验
正则表达式:/^-?\d+$/
解释:
^ 匹配字符串开始。
-? 表示可以有一个可选的负号。
\d+ 表示一个或多个数字。
$ 匹配字符串结束。
正整数校验
正则表达式:/^[1-9]\d*$/
解释:
^ 匹配字符串开始。
[1-9] 表示第一位不能是 0,必须是 1 到 9 中的一个数字。
\d* 表示后面可以跟零个或多个数字。
$ 匹配字符串结束。
浮点数校验
正则表达式:/^-?\d+(\.\d+)?$/
解释:
^ 匹配字符串开始。
-? 表示可以有一个可选的负号。
\d+ 表示整数部分,至少一个数字。
(\.\d+)? 表示小数部分是可选的,\. 匹配点号,\d+ 表示至少一个数字。
$ 匹配字符串结束。
日期校验(YYYY-MM-DD 格式)
正则表达式:/^((((1[6-9]|[2-9]\d)\d{2})(0[13578]|1[02])(0[1-9]|[12]\d|3[01]))|(((1[6-9]|[2-9]\d)\d{2})(0[13456789]|1[012])(0[1-9]|[12]\d|30))|(((1[6-9]|[2-9]\d)\d{2})02(0[1-9]|1\d|2[0-8]))|((((1[6-9]|[2-9]\d)(0[48]|[2468][048]|[13579][26]))|((16|[2468][048]|[3579][26])00))0229))$/
解释:
^ 表示匹配字符串的开始。
整体是多个分组的或关系(|)。
((((1[6-9]|[2-9]\d)\d{2})(0[13578]|1[02])(0[1-9]|[12]\d|3[01])) 匹配大月(1、3、5、7、8、10、12 月)有 31 天的日期,年份部分 (1[6-9]|[2-9]\d)\d{2} 表示 1600 年到 9999 年。
(((1[6-9]|[2-9]\d)\d{2})(0[13456789]|1[012])(0[1-9]|[12]\d|30)) 匹配小月(除 2 月外有 30 天的月份)的日期。
(((1[6-9]|[2-9]\d)\d{2})02(0[1-9]|1\d|2[0-8])) 匹配平年 2 月(28 天)的日期。
((((1[6-9]|[2-9]\d)(0[48]|[2468][048]|[13579][26]))|((16|[2468][048]|[3579][26])00))0229)) 匹配闰年 2 月(29 天)的日期,闰年的判断条件是能被 4 整除但不能被 100 整除,或者能被 400 整除。
$ 表示匹配字符串的结束。
车牌号校验(以中国大陆为例,普通民用汽车号牌)
正则表达式:/^[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1}$/
解释:
^ 匹配字符串开始。
[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1} 表示省份简称或特殊标识(如使、领),是一个字符。
[A-Z]{1} 表示地区代码,为一个大写字母。
[A-Z0-9]{4} 表示 4 位字母或数字。
[A-Z0-9挂学警港澳]{1} 表示最后一位可能是字母、数字,或者特殊标识(挂、学、警、港、澳)。
$ 匹配字符串结束。
邮政编码校验(中国大陆)
正则表达式:/^[1-9]\d{5}$/
解释:
^ 匹配字符串开始。
[1-9] 表示第一位不能为 0,是 1 到 9 中的一个数字。
\d{5} 表示后面跟着 5 位数字。
$ 匹配字符串结束。
中文姓名校验(一般情况,假设姓名为 2 到 4 个汉字)
正则表达式:/^[\u4e00-\u9fa5]{2,4}$/
解释:
^ 匹配字符串开始。
[\u4e00-\u9fa5] 表示匹配一个汉字,\u4e00 到 \u9fa5 是 Unicode 中汉字的编码范围。
{2,4} 表示匹配 2 到 4 个这样的汉字。
$ 匹配字符串结束。
英文单词校验(由字母组成,可包含连字符,长度不限)
正则表达式:/^[a-zA-Z-]+$/
解释:
^ 匹配字符串开始。
[a-zA-Z-] 表示可以是大写或小写字母,也可以是连字符。
+ 表示一个或多个这样的字符。
$ 匹配字符串结束。
IPv4 地址校验
正则表达式:/^(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/
解释:
^ 匹配字符串开始。
(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?) 表示每个部分(0 到 255 的数字)的匹配规则,分别处理了不同范围的数字情况。
\. 匹配实际的点号(转义)。
重复四次上述部分来匹配 IPv4 地址的四个字节。
$ 匹配字符串结束。
银行卡号校验(一般 16 到 19 位数字)
正则表达式:/^\d{16,19}$/
解释:
^ 匹配字符串开始。
\d{16,19} 表示由 16 到 19 位数字组成。
$ 匹配字符串结束。
import re # 手机号校验 def validate_phone_number(phone_number): regex = r'^1[3456789]\d{9}$' return bool(re.match(regex, phone_number)) # 邮箱校验 def validate_email(email): regex = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$' return bool(re.match(regex, email)) # 身份证号码校验(18 位) def validate_id_card(id_card): regex = r'^[1-9]\d{5}(18|19|20)\d{2}(0[1-9]|1[0-2])(0[1-9]|[12]\d|3[01])\d{3}[0-9Xx]$' return bool(re.match(regex, id_card)) # 密码强度校验(至少包含字母和数字,长度 8 到 20 位) def validate_password(password): regex = r'^(?=.*[a-zA-Z])(?=.*\d)[a-zA-Z\d]{8,20}$' return bool(re.match(regex, password)) # URL 校验 def validate_url(url): regex = r'^(https?|ftp):\/\/([a-zA-Z0-9.-]+(\:[a-zA-Z0-9.&%$-]+)*@)*((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)|([a-zA-Z0-9-]+\.)*[a-zA-Z0-9-]+\.(com|edu|gov|int|mil|net|org|biz|arpa|info|name|pro|aero|coop|museum|[a-zA-Z]{2})(:\d+)?(\/($|[a-zA-Z0-9.,?\'\\+&%$#=~_-]+))*$' return bool(re.match(regex, url)) # 整数校验 def validate_integer(number): regex = r'^-?\d+$' return bool(re.match(regex, number)) # 正整数校验 def validate_positive_integer(number): regex = r'^[1-9]\d*$' return bool(re.match(regex, number)) # 浮点数校验 def validate_float(number): regex = r'^-?\d+(\.\d+)?$' return bool(re.match(regex, number)) # 日期校验(YYYY-MM-DD 格式) def validate_date(date): regex = r'^((((1[6-9]|[2-9]\d)\d{2})(0[13578]|1[02])(0[1-9]|[12]\d|3[01]))|(((1[6-9]|[2-9]\d)\d{2})(0[13456789]|1[012])(0[1-9]|[12]\d|30))|(((1[6-9]|[2-9]\d)\d{2})02(0[1-9]|1\d|2[0-8]))|((((1[6-9]|[2-9]\d)(0[48]|[2468][048]|[13579][26]))|((16|[2468][048]|[3579][26])00))0229))$' return bool(re.match(regex, date)) # 车牌号校验 def validate_license_plate(license_plate): regex = r'^[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1}$' return bool(re.match(regex, license_plate)) # 邮政编码校验 def validate_postal_code(postal_code): regex = r'^[1-9]\d{5}$' return bool(re.match(regex, postal_code)) # 中文姓名校验 def validate_chinese_name(name): regex = r'^[\u4e00-\u9fa5]{2,4}$' return bool(re.match(regex, name)) # 英文单词校验 def validate_english_word(word): regex = r'^[a-zA-Z-]+$' return bool(re.match(regex, word)) # IPv4 地址校验 def validate_ipv4(ip): regex = r'^((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$' return bool(re.match(regex, ip)) # 银行卡号校验 def validate_bank_card(bank_card): regex = r'^\d{16,19}$' return bool(re.match(regex, bank_card)) # 示例测试 print(validate_phone_number("13800138000")) print(validate_email("test@example.com"))
time模块
import time
常用函数
time.time() 返回当前时间的时间戳,即从 1970 年 1 月 1 日午夜(UTC,协调世界时)开始到当前时刻所经过的秒数,返回值是一个浮点数。
import time timestamp = time.time() print(f"当前时间戳: {timestamp}")
time.localtime([secs]) 将一个时间戳转换为本地时间的 struct_time 对象。如果不提供 secs 参数,则默认使用当前时间的时间戳。
import time timestamp = time.time() local_time = time.localtime(timestamp) print(f"本地时间: {local_time}")
struck_time 对象是一个元组,包含以下属性:
| 索引 | 属性 | 含义 |
| 0 | tm_year | 年份(如:2025) |
| 1 | tm_mon | 月份(1-12) |
| 2 | tm_mday | 日期(1-31) |
| 3 | tm_hour | 小时(0-23) |
| 4 | tm_min | 分钟(0-59) |
| 5 | tm_sec | 秒(0-61,60和61用于闰秒) |
| 6 | tm_wday | 星期几(0-6,0表示星期一) |
| 7 | tm_yday | 一年中的第几天(1-366) |
| 8 | tm_isdst | 是否为夏令时(0表示否,1表示是,-1表示未知) |
time.gmtime([secs]) 将一个时间戳转换为 UTC 时间的 struct_time 对象。如果不提供 secs 参数,则默认使用当前时间的时间戳。
import time timestamp = time.time() utc_time = time.gmtime(timestamp) print(f"UTC 时间: {utc_time}")
time.mktime() 将一个 struct_time 对象转换为时间戳。
import time local_time = time.localtime() timestamp = time.mktime(local_time) print(f"转换后的时间戳: {timestamp}")
time.strftime(format[, t]) 将一个 struct_time 对象按照指定的格式转换为字符串。如果不提供 t 参数,则默认使用当前时间。
import time local_time = time.localtime() formatted_time = time.strftime("%Y-%m-%d %H:%M:%S", local_time) print(f"格式化后的时间: {formatted_time}")
常见的格式代码如下:
| 代码 | 含义 |
| %Y | 四位数的年份 |
| %m | 两位数的月份(01-12) |
| %d | 两位数的日期(01-31) |
| %H | 24小时制的小时(00-23) |
| %M | 分钟(00-59) |
| %S | 秒(00-61) |
time.strptime(string, format) 将一个字符串按照指定的格式解析为 struct_time 对象。
import time time_str = "2025-10-01 12:30:00" time_obj = time.strptime(time_str, "%Y-%m-%d %H:%M:%S") print(f"解析后的时间对象: {time_obj}")
time.sleep(sec) 让程序暂停执行指定的秒数。
import time print("开始暂停") time.sleep(2) # 暂停 2 秒 print("暂停结束")
没有使用多线程任务
import time def cake1(): print("烧饼1开始烤") time.sleep(5) print("烧饼1烤完了") def cake2(): print("烧饼2开始烤") time.sleep(5) print("烧饼2烤完了") cake1() cake2()
多任务-线程
在编程中,多任务线程是实现多任务处理的一种重要方式,它允许程序在同一时间内执行多个任务,从而提高程序的执行效率和响应能力。
使用多线程任务
import time import threading # 线程 def cake1(): print("烧饼1开始烤") time.sleep(5) print("烧饼1烤完了") def cake2(): print("烧饼2开始烤") time.sleep(5) print("烧饼2烤完了") # 为了准备子线程 开始创建子线程 t1 = threading.Thread(target=cake1) t2 = threading.Thread(target=cake2) # 启动子线程 t1.start() t2.start() print(123123)
线程的基本概念
线程是程序执行流的最小单元,一个进程可以包含多个线程,这些线程可以并发执行,共享进程的资源(如内存、文件句柄等)。与进程相比,线程的创建和销毁开销较小,切换速度也更快。
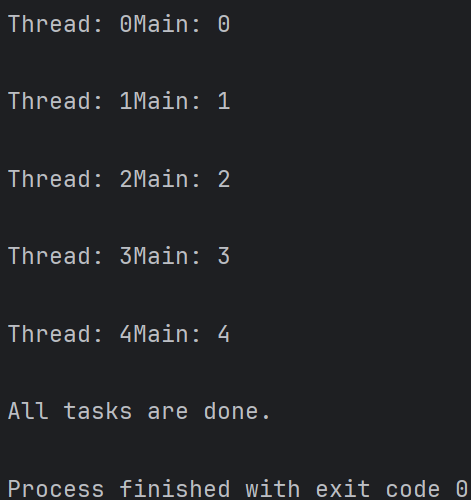
Python的标准库threading线程模块
import threading # 定义一个线程要执行的任务函数 def task(): for i in range(5): print(f"Thread: {i}") # 创建线程对象 thread = threading.Thread(target=task)#创建一个线程对象,target参数指定线程要执行的任务函数。 # 启动线程 thread.start() #启动线程,使线程开始执行target指定的任务函数。 # 主线程继续执行其他任务 for i in range(5): print(f"Main: {i}") # 等待线程执行完毕 thread.join() #主线程等待子线程执行完毕后再继续执行后续代码。 print("All tasks are done.")
输出结果:
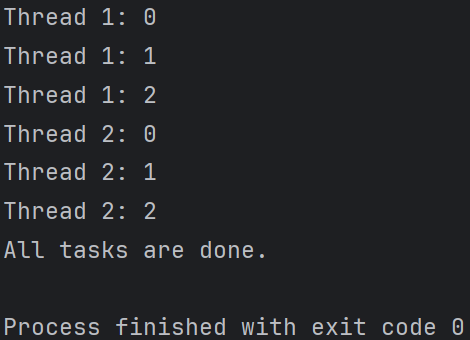
带参数的线程任务
import threading # 定义一个带参数的任务函数 def task(name, num): for i in range(num): print(f"{name}: {i}") # 创建线程对象并传递参数 thread1 = threading.Thread(target=task, args=("Thread 1", 3)) #args参数用于传递给任务函数的参数,它是一个元组。 thread2 = threading.Thread(target=task, args=("Thread 2", 3)) # 启动线程 thread1.start() thread2.start() # 等待线程执行完毕 thread1.join() thread2.join() print("All tasks are done.")
查看线程数量
import time import threading # 线程 def cake1(): print("烧饼1开始烤") time.sleep(5) print("烧饼1烤完了") def cake2(): print("烧饼2开始烤") time.sleep(10) print("烧饼2烤完了") # 为了准备子线程 开始创建子线程 t1 = threading.Thread(target=cake1) t2 = threading.Thread(target=cake2) # 启动子线程 t1.start() t2.start() # len 求列表的元素个数 while True: time.sleep(1) # 间隔一秒 # 会返回当前线程的数量 num_threads = len(threading.enumerate()) #enumerate查看线程数量 print(num_threads) if num_threads == 1: break # 退出循环
线程同步问题
由于多个线程可以共享进程的资源,当多个线程同时访问和修改共享资源时,可能会出现数据不一致的问题,即线程安全问题。为了解决这个问题,可以使用锁机制。
import threading import time # 定义了一个全局变量 g_num = 0 # 互斥锁 mutex = threading.Lock() # 创建锁 # mutex.acquire() 上锁 # mutex.release() 解锁 def test1(): global g_num for i in range(1000000): mutex.acquire() # 上锁 g_num += 1 # g_num = g_num + 1 mutex.release() # 解锁 def test2(): global g_num for i in range(1000000): mutex.acquire() # 上锁 g_num += 1 mutex.release() # 解锁 # 子线程和主线程的一些变量是共用的 t1 = threading.Thread(target=test1) t2 = threading.Thread(target=test2) t1.start() t2.start()
time.sleep(2) print(g_num) #输出结果: 200000
import threading # 共享资源 counter = 0 # 创建锁对象 lock = threading.Lock() # 定义一个任务函数,对共享资源进行操作 def increment(): global counter for _ in range(100000): # 获取锁 确保同一时间只有一个线程可以访问和修改共享资源 lock.acquire() try: counter += 1 finally: # 释放锁 允许其他线程获取锁并访问共享资源 lock.release() # 创建线程对象 thread1 = threading.Thread(target=increment) thread2 = threading.Thread(target=increment) # 启动线程 thread1.start() thread2.start() # 等待线程执行完毕 thread1.join() thread2.join() print(f"Final counter value: {counter}")
线程的优点
提高程序的执行效率:多个线程可以并发执行,充分利用多核处理器的资源,加快程序的执行速度。
提高程序的响应能力:在 GUI 程序中,使用线程可以避免长时间的任务阻塞主线程,保持界面的响应性。
线程的缺点
线程安全问题:多个线程同时访问和修改共享资源时,可能会出现数据不一致的问题,需要使用锁等同步机制来解决。
上下文切换开销:线程的切换需要保存和恢复上下文信息,会带来一定的开销。
调试困难:多线程程序的执行顺序是不确定的,调试时可能会出现难以复现的问题。
多进程任务multiprocessing模块
import multiprocessing def worker(): """子进程要执行的任务""" print('子进程正在运行') if __name__ == '__main__': # 创建一个新的进程 p = multiprocessing.Process(target=worker) # 启动进程 p.start() # 等待进程结束 p.join() print('主进程结束')
if __name__ == '__main__':语句是为了避免在 Windows 等系统下出现递归创建进程的问题,因为 Windows 系统在创建新进程时会重新导入主模块,所以需要使用该语句来确保代码只在主进程中执行。
import time import multiprocessing # 进程 def cake1(): print("烧饼1开始烤") time.sleep(5) print("烧饼1烤完了") def cacke2(): print("烧饼2开始烤") time.sleep(5) print("烧饼2烤完了") def cake3(): print("烧饼3开始烤") time.sleep(5) print("烧饼3烤完了") def main(): # main或run # 为了准备子进程 开始创建子进程 t1 = multiprocessing.Process(target=cake1) t2 = multiprocessing.Process(target=cake2) t3 = multiprocessing.Process(target=cake3) # 启动进程 t1.start() t2.start() t3.start() # for i in range(60): # multiprocessing.Process(target=烧饼1).start() if __name__ == '__main__': main()
多进程池:当需要创建大量的进程时,手动管理每个进程会变得很麻烦,这时可以使用multiprocessing.Pool类来创建进程池
import multiprocessing def square(x): """计算平方的函数""" return x * x if __name__ == '__main__': # 创建一个包含4个进程的进程池 with multiprocessing.Pool(processes=4) as pool: #with语句用于自动管理进程池的生命周期,确保在使用完后正确关闭和释放资源。 # 要处理的数据 numbers = [1, 2, 3, 4, 5] # 使用进程池并行计算平方 results = pool.map(square, numbers) #pool.map()方法会将numbers列表中的每个元素依次传递给square函数进行处理,并将结果收集到一个列表中返回。 print(results) #输出结果:[1, 4, 9, 16, 25]
进程间通讯multiprocessing.Queue()
import multiprocessing def sender(q): """向队列中发送数据的进程""" q.put('Hello, 进程间通信!') #q.put()方法用于向队列中放入数据 def receiver(q): """从队列中接收数据的进程""" message = q.get() #q.get()方法用于从队列中取出数据 print(f'接收到的消息: {message}') if __name__ == '__main__': # 创建一个队列 q = multiprocessing.Queue() #是一个线程和进程安全的队列,可用于在不同进程间传递数据 # 创建发送进程 p1 = multiprocessing.Process(target=sender, args=(q,)) # 创建接收进程 p2 = multiprocessing.Process(target=receiver, args=(q,)) # 启动发送进程 p1.start() # 启动接收进程 p2.start() # 等待发送进程结束 p1.join() # 等待接收进程结束 p2.join() print('主进程结束')
isinstance() 语法:isinstance(object,classinfo)
用于判断一个对象是否是某个类的实例,或者是否是某些类中的一个类的实例。
参数解释:object:需要进行类型检查的对象。classinfo:可以是单个类、类型,或者由多个类、类型组成的元组。
返回值:如果 object 是 classinfo 类型的实例,或者是 classinfo 元组中任意一个类型的实例,则返回 True;否则返回 False。
①.检查对象是否是单个类的实例
# 定义一个类 class MyClass: pass # 创建一个 MyClass 类的实例 obj = MyClass() # 检查 obj 是否是 MyClass 类的实例 result = isinstance(obj, MyClass) print(result) # 输出结果: True # 检查 obj 是否是 int 类型的实例 result = isinstance(obj, int) print(result) # 输出结果: False
②.检查对象是否是多类中的一个类的实例
# 定义多个类 class ClassA: pass class ClassB: pass # 创建一个 ClassA 类的实例 obj = ClassA() # 检查 obj 是否是 ClassA 或 ClassB 类的实例 result = isinstance(obj, (ClassA, ClassB)) print(result) # 输出结果: True # 创建一个 int 类型的对象 num = 10 result = isinstance(num, (ClassA, ClassB)) print(result) # 输出结果: False
③.与内置类型一起使用
# 定义一个字符串 text = "Hello, World!" # 检查 text 是否是 str 或 int 类型的实例 result = isinstance(text, (str, int)) print(result) # 输出结果: True # 检查 text 是否是 float 类型的实例 result = isinstance(text, float) print(result) # 输出结果: False
print(isinstance(123, str)) # False print(isinstance("123", str)) # True print(isinstance(123, int)) # True
pass 是一个空语句,它不执行任何操作,主要用于语法上需要语句但又不需要实际执行任何代码的场景
①.在函数中定义中使用
当你想要先定义一个函数,但还没有想好具体的实现逻辑时,可以使用 pass 占位。这样可以保证函数定义的语法正确性,后续再补充具体的函数体内容。
def future_function(): pass # 调用函数,不会有任何实际输出 future_function()
②.在类定义中使用
和函数定义类似,当你想要先定义一个类,但还未确定类的具体属性和方法时,可以使用 pass 占位。
class FutureClass: pass # 创建类的实例 obj = FutureClass()
③.在条件语句中使用
在条件语句(如 if、elif、else)中,有时可能某个条件分支暂时不需要执行任何操作,此时可以使用 pass 占位。
x = 10 if x > 20: print("x 大于 20") elif x > 15: print("x 大于 15 但不大于 20") else: pass # 这里暂时不需要执行任何操作,使用 pass 占位
④.在循环语句中使用
在循环语句(如 for、while)中,有时可能某个循环体暂时不需要执行任何操作,同样可以使用 pass 占位。
numbers = [1, 2, 3, 4, 5] for num in numbers: if num % 2 == 0: # 当数字是偶数时,暂时不做任何操作 pass else: print(num)
迭代器(Iterator)是一个实现了迭代器协议的对象,它可以用于遍历可迭代对象(如列表、元组、字典等)中的元素。迭代器协议要求对象实现两个方法:__iter__() 和 __next__()。
可迭代对象(interable):是指可以返回一个迭代器的对象,常见的可迭代对象有列表、元组、字符串、字典等。可以使用 iter() 函数将可迭代对象转换为迭代器。
from collections.abc import Iterable print(isinstance(123, Iterable)) # False print(isinstance("123", Iterable)) # True print(isinstance([1, 3, 4], Iterable)) # True print(isinstance(range(10), Iterable)) # True print(isinstance({1, 3, 4}, Iterable)) # True print(isinstance(1.34, Iterable)) #Flase #除了int整数型和浮点型float,都是可迭代对象。
①.迭代器(Iterator)是一个实现了 __iter__() 和 __next__() 方法的对象。__iter__() 方法返回迭代器本身,__next__() 方法返回迭代器的下一个元素,当没有更多元素时,抛出 StopIteration 异常。
iter() 函数:用于将可迭代对象转换为迭代器。
next() 函数:用于获取迭代器的下一个元素。
# 定义一个列表,列表是可迭代对象 my_list = [1, 2, 3, 4, 5] # 使用 iter() 函数将列表转换为迭代器 my_iterator = iter(my_list) # 使用 next() 函数获取迭代器的下一个元素 print(next(my_iterator)) # 输出: 1 print(next(my_iterator)) # 输出: 2 print(next(my_iterator)) # 输出: 3 print(next(my_iterator)) # 输出: 4 print(next(my_iterator)) # 输出: 5 # 当没有更多元素时,再次调用 next() 函数会抛出 StopIteration 异常 try: print(next(my_iterator)) except StopIteration: print("已经没有更多元素了")
②.使用for循遍历迭代器
for 循环在内部会自动调用 iter() 函数将可迭代对象转换为迭代器,并使用 next() 函数逐个获取元素,直到抛出 StopIteration 异常。
my_list = [1, 2, 3, 4, 5] for item in my_list: print(item)
③.自定义迭代器
你可以通过定义一个类并实现 __iter__() 和 __next__() 方法来创建自定义迭代器。
class MyRange: def __init__(self, start, end): self.start = start self.end = end self.current = start def __iter__(self): return self def __next__(self): if self.current < self.end: value = self.current self.current += 1 return value else: raise StopIteration # 创建自定义迭代器的实例 my_range = MyRange(0, 5) # 使用 for 循环遍历自定义迭代器 for num in my_range: print(num)
class ClassIterator: def __init__(self): self.names = ['勇哥', '乐乐', 'coco'] self.current = 0 # 计数 def __iter__(self): # iterable 可迭代对象 return self # 迭代器 def __next__(self): if self.current < len(self.names): item = self.names[self.current] self.current += 1 return item else: raise StopIteration # 停止迭代 # 调用类 a = ClassIterator() for i in a: print(i)
StopIteration 异常:通常在迭代器中使用,用于表示迭代结束。当迭代器没有更多元素可供迭代时,会抛出该异常。
迭代器是惰性的,它只在需要时才计算和返回下一个元素,这可以节省内存和计算资源。迭代器只能向前遍历元素,不能后退或重置,一旦迭代结束,就不能再次使用该迭代器进行遍历,需要重新创建迭代器。
IndexError 异常:通常在你尝试访问序列(如列表、元组、字符串等)中不存在的索引时抛出。
my_list = [1, 2, 3] try: # 列表的索引是从 0 开始的,这里尝试访问索引为 3 的元素,会触发 IndexError print(my_list[3]) except IndexError as e: print(f"捕获到 IndexError: {e}") #输出:捕获到 IndexError: list index out of range
TypeError 异常:表示操作或函数应用于不兼容类型的对象时引发的错误。
try: # 尝试将整数和字符串相加,会触发 TypeError result = 1 + 'a' except TypeError as e: print(f"捕获到 TypeError: {e}")
raise 关键字:用于主动抛出异常,你可以抛出内置的异常类型,也可以自定义异常类型。
抛出内置ZeroDivisionError异常
def divide(a, b): if b == 0: # 当除数为 0 时,主动抛出 ZeroDivisionError 异常 raise ZeroDivisionError("除数不能为零") return a / b try: result = divide(10, 0) except ZeroDivisionError as e: print(f"捕获到异常: {e}")
自定义异常并抛出
# 自定义异常类,继承自 Exception class MyCustomError(Exception): pass def check_value(value): if value < 0: # 当值小于 0 时,抛出自定义异常 raise MyCustomError("值不能为负数") return value try: result = check_value(-5) except MyCustomError as e: print(f"捕获到自定义异常: {e}")
生成器(Generator):是一种特殊的迭代器,它允许你在需要时逐个生成值,而不是一次性生成所有值。这种特性使得生成器在处理大量数据时非常高效,因为它不需要一次性将所有数据加载到内存中。
生成器函数:是一种特殊的函数,使用 yield 关键字来定义。当调用生成器函数时,它并不会立即执行函数体中的代码,而是返回一个生成器对象。每次调用生成器对象的 __next__() 方法(或者使用 next() 内置函数)时,函数会执行到下一个 yield 语句,返回 yield 后面的值,并暂停执行。
def simple_generator(): yield 1 yield 2 yield 3 # 创建生成器对象 gen = simple_generator() # 使用 next() 函数获取生成器的下一个值 print(next(gen)) # 输出结果: 1 print(next(gen)) # 输出结果: 2 print(next(gen)) # 输出结果: 3 # 当生成器没有更多的值时,会抛出 StopIteration 异常 try: print(next(gen)) except StopIteration: print("生成器已耗尽") #输出结果:生成吕已耗尽
生成器表达式:是一种简洁的创建生成器的方式,它类似于列表推导式,但使用圆括号而不是方括号。生成器表达式返回一个生成器对象,而不是一个列表。
# 创建一个生成器表达式 gen_expr = (x**2 for x in range(5)) # 使用 for 循环遍历生成器 for num in gen_expr: print(num)
输出结果:
生成器的优势
①.节省内存:生成器逐个生成值,不需要一次性将所有值存储在内存中,因此在处理大数据集时非常高效。
②.延迟计算:生成器只有在需要时才会生成值,避免了不必要的计算。
生成器的常见使用场景
处理大数据集:例如读取大文件时,可以使用生成器逐行读取文件内容,而不是一次性将整个文件加载到内存中。
def read_large_file(file_path): with open(file_path, 'r') as file: for line in file: yield line # 使用生成器逐行读取文件 file_gen = read_large_file('large_file.txt') for line in file_gen: print(line.strip())
无限序列生成
生成器可以用于生成无限序列,例如斐波那契数列。
def fibonacci(): a, b = 0, 1 while True: yield a a, b = b, a + b # 生成斐波那契数列的前10个数 fib_gen = fibonacci() for _ in range(10): print(next(fib_gen))
协程(Coroutine):是一种比线程更加轻量级的并发编程方式。它允许在程序执行过程中暂停和恢复,从而实现高效的异步操作。
基于生成器的协程(Python早期协程实现)
在 Python 2.5 及以后的版本中,可以使用生成器和 yield 关键字来实现简单的协程。
def simple_coroutine(): print('协程启动') while True: x = yield if x is None: break print(f'协程接收到的值: {x}') print('协程结束') # 创建协程对象 coro = simple_coroutine() # 启动协程,执行到第一个 yield 处暂停 # 第一次必须使用 next(coro) 或者 coro.send(None) 来启动协程 next(coro) # 向协程发送值 coro.send(10) coro.send(20) # 发送 None 来终止协程 coro.send(None)
coro.send(value) 方法:用于与基于生成器的协程进行交互的重要方法,在基于生成器实现的协程里,协程函数通过 yield 关键字暂停执行并返回一个值,同时也可以接收外部传入的值。其作用就是向协程发送一个值,并让协程从上次暂停的 yield 语句处继续执行。具体来说:当调用 coro.send(value) 时,value 会被赋值给 yield 表达式本身,协程会从 yield 语句处继续向下执行,直到遇到下一个 yield 语句或者函数结束。如果协程已经结束(没有更多的 yield 语句),调用 coro.send(value) 会抛出 StopIteration 异常。在 Python 中,yield from 可以用于简化协程的嵌套,coro.send(value) 也可以在这种嵌套结构中使用,将数据传递给内层的协程。
基于asyncio库的协程(Python3.4以后)
asyncio 是 Python 标准库中用于编写异步 I/O 代码的库,它提供了更高级的协程支持。
import asyncio # 定义一个协程函数 async def hello(): print('Hello') # 模拟异步操作,暂停当前协程 await asyncio.sleep(1) print('World') # 主函数 async def main(): # 创建一个协程对象 task = asyncio.create_task(hello()) # 等待任务完成 await task # 运行主函数 asyncio.run(main())
async def:用于定义异步函数,异步函数也称为协程函数。
await:用于暂停协程的执行,等待一个可等待对象(如另一个协程、Future 或 Task)完成。
asyncio.run():用于运行顶级的异步函数。
并发执行多个协程
可以使用 asyncio.gather() 函数并发执行多个协程。
import asyncio # 定义一个协程函数 async def task(num): print(f'Task {num} started') await asyncio.sleep(1) print(f'Task {num} finished') # 主函数 async def main(): # 创建多个任务 tasks = [task(i) for i in range(3)] # 并发执行多个任务 await asyncio.gather(*tasks) # 运行主函数 asyncio.run(main())
UDP(User Datagram Protocol)即用户数据报协议,是一种无连接的传输层协议,与 TCP(传输控制协议)同为互联网传输层的两大主流协议。
无连接:在进行数据传输之前,不需要像 TCP 那样先建立连接。发送方可以随时向接收方发送数据报,接收方只要处于监听状态就可以接收数据。
不可靠:UDP 不保证数据一定能到达目的地,也不保证数据的顺序和完整性。如果数据在传输过程中丢失、重复或乱序,UDP 本身不会进行重传、排序等操作。
高效性:由于不需要建立连接和维护复杂的状态信息,UDP 的开销较小,传输速度快,实时性好。因此,UDP 适用于对实时性要求较高、对少量数据丢失不太敏感的应用场景,如音频和视频流、实时游戏等。
在 Python 中,可以使用 socket 模块来实现 UDP 通信。
UDP服务器端代码:
import socket # 创建 UDP 套接字 server_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 绑定 IP 地址和端口号 server_address = ('localhost', 12345) server_socket.bind(server_address) print(f"UDP 服务器正在监听 {server_address}...") while True: # 接收客户端发送的数据和客户端地址 data, client_address = server_socket.recvfrom(1024) # 解码接收到的数据 message = data.decode('utf-8') print(f"收到来自 {client_address} 的消息: {message}") # 向客户端发送响应消息 response = f"已收到你的消息: {message}" server_socket.sendto(response.encode('utf-8'), client_address)
代码解释:
使用 socket.socket(socket.AF_INET, socket.SOCK_DGRAM) 创建一个 UDP 套接字,socket.AF_INET 表示使用 IPv4 地址族,socket.SOCK_DGRAM 表示使用 UDP 协议。
使用 bind() 方法将套接字绑定到指定的 IP 地址和端口号。
使用 recvfrom() 方法接收客户端发送的数据和客户端地址,1024 表示一次最多接收 1024 字节的数据。
使用 sendto() 方法向客户端发送响应消息。
UDP客户端代码:
import socket # 创建 UDP 套接字 client_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 服务器地址和端口 server_address = ('localhost', 12345) # 要发送的消息 message = "Hello, UDP Server!" # 发送消息到服务器 client_socket.sendto(message.encode('utf-8'), server_address) # 接收服务器的响应 data, server = client_socket.recvfrom(1024) # 解码响应消息 response = data.decode('utf-8') print(f"收到来自服务器的响应: {response}") # 关闭套接字 client_socket.close()
代码解释:
同样使用 socket.socket(socket.AF_INET, socket.SOCK_DGRAM) 创建一个 UDP 套接字。
使用 sendto() 方法将消息发送到服务器。
使用 recvfrom() 方法接收服务器的响应。
使用 close() 方法关闭套接字。
注意事项:
UDP 数据报有最大长度限制,一般为 65507 字节(包括 UDP 头部 8 字节),实际应用中需要考虑数据大小,避免数据丢失。
由于 UDP 是不可靠的协议,在实际应用中需要考虑数据丢失、重复等问题,并进行相应的错误处理。
TCP(Transmission Control Protocol)即传输控制协议,是一种面向连接的、可靠的、基于字节流的传输层通信协议。
在进行数据传输之前,需要先建立连接,传输完成后再断开连接。这种连接机制确保了通信双方可以可靠地进行数据交互,称为面向连接。
TCP 通过一系列机制来保证数据的可靠传输,包括确认应答、重传机制、滑动窗口协议、拥塞控制等。如果数据在传输过程中丢失、损坏或乱序,TCP 会自动进行重传和排序,确保接收方能够正确接收到完整的数据。
TCP 将应用层的数据看作是无结构的字节流进行传输,它会将数据分割成合适大小的数据包进行发送,并在接收端将这些数据包重新组装成完整的字节流。
在 Python 中,可以使用 socket 模块来实现 TCP 通信。
TCP服务器端代码:
import socket # 创建 TCP 套接字 server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 更换端口号为 54321 server_address = ('localhost', 54321) server_socket.bind(server_address) # 开始监听,允许的最大连接数为 1 server_socket.listen(1) print(f"TCP 服务器正在监听 {server_address}...") # 后续代码保持不变 while True: # 等待客户端连接 print("等待客户端连接...") client_socket, client_address = server_socket.accept() print(f"客户端 {client_address} 已连接") try: while True: # 接收客户端发送的数据 data = client_socket.recv(1024) if not data: # 如果没有接收到数据,说明客户端已关闭连接 break # 解码接收到的数据 message = data.decode('utf-8') print(f"收到来自 {client_address} 的消息: {message}") # 向客户端发送响应消息 response = f"已收到你的消息: {message}" client_socket.sendall(response.encode('utf-8')) finally: # 关闭客户端连接 client_socket.close()
代码解释:
使用 socket.socket(socket.AF_INET, socket.SOCK_STREAM) 创建一个 TCP 套接字,socket.AF_INET 表示使用 IPv4 地址族,socket.SOCK_STREAM 表示使用 TCP 协议。
使用 bind() 方法将套接字绑定到指定的 IP 地址和端口号。
使用 listen() 方法开始监听客户端的连接请求,参数表示允许的最大连接数。
使用 accept() 方法等待客户端的连接,该方法会返回一个新的套接字对象和客户端的地址。
使用 recv() 方法接收客户端发送的数据,使用 sendall() 方法向客户端发送响应消息。
使用 close() 方法关闭客户端连接。
TCP客户端代码:
import socket # 创建 TCP 套接字 client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 服务器地址和端口 server_address = ('localhost', 12345) # 连接到服务器 client_socket.connect(server_address) try: # 要发送的消息 message = "Hello, TCP Server!" # 发送消息到服务器 client_socket.sendall(message.encode('utf-8')) # 接收服务器的响应 data = client_socket.recv(1024) # 解码响应消息 response = data.decode('utf-8') print(f"收到来自服务器的响应: {response}") finally: # 关闭套接字 client_socket.close()
代码解释:
同样使用 socket.socket(socket.AF_INET, socket.SOCK_STREAM) 创建一个 TCP 套接字。
使用 connect() 方法连接到指定的服务器地址和端口。
使用 sendall() 方法向服务器发送消息,使用 recv() 方法接收服务器的响应。
使用 close() 方法关闭套接字。
注意事项:
在使用 TCP 时,需要注意连接的建立和关闭,避免出现连接泄漏的问题。
由于 TCP 是字节流协议,在处理数据时需要注意数据的边界问题,避免出现粘包和半包的情况。可以通过自定义协议、使用固定长度的数据块或添加分隔符等方式来解决。
在网络通信中,可能会出现各种异常情况,如连接超时、网络中断等,需要在代码中进行适当的异常处理,以增强程序的健壮性。
闭包(Closure):是一个非常重要的概念,它结合了函数和其相关的引用环境,让函数能够记住并访问其定义时的外部(非全局)变量。
闭包的定义:是指有权访问另一个函数作用域中变量的函数,即使该函数已经执行完毕,其作用域内的变量也不会被销毁,而是会被闭包所引用。
闭包的形成条件:①.存在嵌套函数:在一个函数内部定义另一个函数。
②.内部函数引用外部函数的变量:内部函数使用了外部函数中定义的变量。
③.外部函数返回内部函数:外部函数将内部函数作为返回值返回。
def test2(): # 全局 print("test2") def test1(): # test2局部的 print("test1") return test1 # 外部函数返回内部函数 a = test2()
a() # 调用的是 test1 函数 #输出结果:test1
def outer_function(x): # 外部函数,接受一个参数 x def inner_function(y): # 内部函数,接受一个参数 y return x + y # 外部函数返回内部函数 return inner_function # 创建一个闭包实例 closure = outer_function(10) # 调用闭包 result = closure(5) print(result) # 输出结果:15
代码解释:
outer_function 是外部函数,接受一个参数 x。
inner_function 是内部函数,接受一个参数 y,并引用了外部函数的变量 x。
outer_function 返回了 inner_function,形成了闭包。
调用 outer_function(10) 返回一个闭包 closure,此时 x 的值被固定为 10。
调用 closure(5) 相当于调用 inner_function(5),计算 x + y 的值,即 10 + 5 = 15。
闭包的应用场景
①.数据封装和隐藏:闭包可以将数据封装在函数内部,只提供必要的接口进行访问,从而实现数据的隐藏和保护。
def counter(): count = 0 def increment(): nonlocal count count += 1 return count return increment # 创建一个计数器实例 c = counter() print(c()) # 输出结果:1 print(c()) # 输出结果:2
在这个例子中,count 变量被封装在 counter 函数内部,外部无法直接访问,只能通过调用 increment 函数来修改和获取 count 的值。
在 Python 里,函数内部可以定义另一个函数,形成嵌套函数结构。内部函数默认情况下只能访问外部函数的变量,但不能直接对其进行修改。如果尝试在内部函数中直接对外部函数的变量进行赋值操作,Python 会认为你是在内部函数作用域中创建了一个新的局部变量,而不是修改外部函数的变量。
nonlocal 关键字的作用就是告诉 Python 解释器,在内部函数中使用这个关键字声明的变量,它不是内部函数的局部变量,而是外部(非全局)函数作用域中的变量,这样就可以在内部函数中修改该变量的值。
def outer_function(): # 外部函数定义一个变量 count 并初始化为 0 count = 0 def inner_function(): # 使用 nonlocal 关键字声明 count 是外部函数的变量 nonlocal count # 修改外部函数变量 count 的值 count += 1 return count # 调用内部函数 return inner_function # 创建一个闭包实例 closure = outer_function() # 第一次调用闭包 print(closure()) # 输出结果:1 # 第二次调用闭包 print(closure()) # 输出结果:2
代码解释:
outer_function 函数:这是外部函数,它定义了一个局部变量 count 并初始化为 0,然后定义了一个内部函数 inner_function,最后返回 inner_function。
inner_function 函数:这是内部函数,在函数内部使用 nonlocal count 声明 count 变量是外部函数的变量,然后对 count 进行加 1 操作并返回。
创建闭包并调用:调用 outer_function() 返回一个闭包 closure,每次调用 closure() 时,内部函数 inner_function 会修改外部函数的 count 变量的值,并返回更新后的 count 值。
对比不使用 nonlocal 的情况
def outer(): num = 10 def inner(): # 这里会创建一个新的局部变量 num,而不是修改外部的 num num = 20 return num return inner closure = outer() print(closure()) # 输出结果:20
在这个例子中,由于没有使用 nonlocal 关键字,inner 函数内部的 num = 20 会创建一个新的局部变量 num,而不会影响外部函数的 num 变量。
②.实现装饰器:装饰器是闭包的一个常见应用,它可以在不修改原函数代码的情况下,为函数添加额外的功能。
def log_decorator(func): def wrapper(*args, **kwargs): print(f"Calling function {func.__name__}") result = func(*args, **kwargs) print(f"Function {func.__name__} finished") return result return wrapper @log_decorator def add(a, b): return a + b result = add(3, 5) print(result) #输出结果:8
在这个例子中,log_decorator 是一个装饰器函数,它接受一个函数作为参数,并返回一个新的函数 wrapper。wrapper 函数在调用原函数前后添加了日志输出功能。
闭包的优缺点
优点:数据封装和隐藏:可以将数据封装在函数内部,避免全局变量的使用,提高代码的安全性和可维护性。
代码复用:闭包可以将一些通用的逻辑封装在内部函数中,提高代码的复用性。
缺点:内存占用:由于闭包会引用外部函数的变量,这些变量不会被垃圾回收机制回收,可能会导致内存占用过高。
性能问题:闭包的调用会涉及到多层函数调用,可能会对性能产生一定的影响。
装饰器(Decorator)是一种强大且实用的语法糖,它允许你在不修改原有函数代码的基础上,对函数的功能进行扩展。
装饰器的定义和原理
装饰器本质上是一个函数,它接受一个函数作为参数,并返回一个新的函数。新的函数通常会在原函数的基础上添加一些额外的功能,如日志记录、性能测试、权限验证等。装饰器的实现基于闭包的概念,利用闭包可以访问外部函数作用域中变量的特性,将原函数封装在新的函数内部。
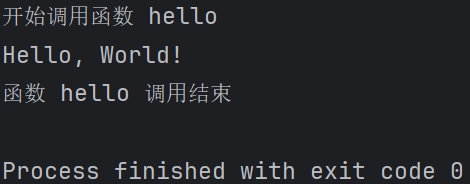
# 定义一个装饰器函数 def log_decorator(func): def wrapper(): print(f"开始调用函数 {func.__name__}") result = func() print(f"函数 {func.__name__} 调用结束") return result return wrapper # 定义一个普通函数 def hello(): print("Hello, World!") #输出结果: # 使用装饰器装饰 hello 函数 hello = log_decorator(hello) # 调用被装饰后的函数 hello()
代码解释:
log_decorator 函数:这是一个装饰器函数,它接受一个函数 func 作为参数,并返回一个新的函数 wrapper。
wrapper 函数:这是一个闭包函数,它在调用原函数 func 前后添加了日志输出功能。
装饰过程:通过 hello = log_decorator(hello) 将 hello 函数传递给 log_decorator 函数进行装饰,返回一个新的函数并重新赋值给 hello。
调用被装饰后的函数:调用 hello() 实际上是调用 wrapper() 函数,从而实现了在原函数基础上添加日志功能的目的。
语法糖写法
Python 提供了一种更简洁的语法糖来使用装饰器,使用 @ 符号直接在函数定义上方指定装饰器。
def log_decorator(func): def wrapper(): print(f"开始调用函数 {func.__name__}") result = func() print(f"函数 {func.__name__} 调用结束") return result return wrapper # 使用语法糖装饰 hello 函数 @log_decorator def hello(): print("Hello, World!") # 调用被装饰后的函数 hello()
输出结果:
如果原函数需要接受参数,那么装饰器的 wrapper 函数也需要接受相应的参数,并将这些参数传递给原函数。
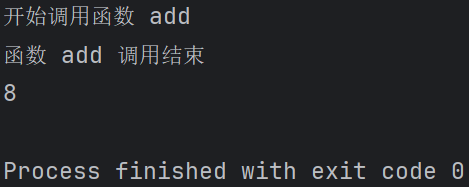
def log_decorator(func): def wrapper(*args, **kwargs): print(f"开始调用函数 {func.__name__}") # 传递参数给原函数 result = func(*args, **kwargs) print(f"函数 {func.__name__} 调用结束") return result return wrapper @log_decorator def add(a, b): return a + b # 调用被装饰后的函数 result = add(3, 5) print(result)
在这个例子中,wrapper 函数使用 *args 和 **kwargs 来接受任意数量的位置参数和关键字参数,并将它们传递给原函数 add。
输出结果:
装饰器本身也可以接受参数,这需要在装饰器函数外面再嵌套一层函数。
def repeat(n): def decorator(func): def wrapper(*args, **kwargs): for _ in range(n): result = func(*args, **kwargs) return result return wrapper return decorator @repeat(3) def say_hello(): print("Hello!") # 调用被装饰后的函数 say_hello()
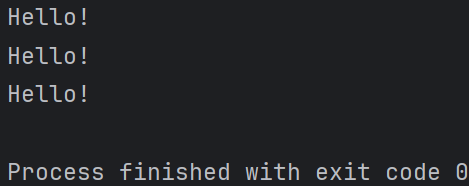
代码解释
repeat 函数:这是一个接受参数的装饰器工厂函数,它接受一个整数 n 作为参数,并返回一个装饰器函数 decorator。
decorator 函数:这是一个普通的装饰器函数,它接受一个函数 func 作为参数,并返回一个新的函数 wrapper。
wrapper 函数:在 wrapper 函数内部,使用 for 循环调用原函数 n 次。
装饰器的应用场景
日志记录:记录函数的调用信息,如调用时间、参数、返回值等。
性能测试:统计函数的执行时间,帮助优化代码性能。
权限验证:在调用函数前验证用户的权限,只有具备相应权限的用户才能调用该函数。
缓存:缓存函数的计算结果,避免重复计算,提高性能。
来源链接:https://www.cnblogs.com/xxy002/p/18660487
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。














暂无评论内容