

4. 分区、视图与其他对象
4.1. 分区概述
分区允许您将非常大的表和索引分解成更小、更易于管理的部分,称为分区。每个分区是一个独立的对象,有自己的名称,并且可以选择拥有自己的存储特性。
为了说明分区的概念,假设一个人力资源经理有一个大盒子,里面装着员工文件夹。每个文件夹都列出了员工的雇用日期。经常有查询是针对特定月份雇用的员工。满足这类请求的一种方法是在员工雇用日期上创建一个索引,指明分散在整个盒子中的文件夹的位置。相比之下,分区策略使用许多较小的盒子,每个盒子包含特定月份雇用的员工文件夹。
使用较小的盒子有几个优点。当被要求检索6月份雇用的员工文件夹时,人力资源经理可以检索6月份的盒子。此外,如果任何小盒子暂时受损,其他小盒子仍然可用。搬家也变得更容易,因为经理不需要移动一个沉重的大盒子,而是可以移动几个小盒子。从应用程序的角度来看,只存在一个模式对象。DML语句不需要修改就可以访问分区表。分区对于许多不同类型的数据库应用程序都很有用,特别是那些管理大量数据的应用程序。好处包括:
-
提高可用性
一个分区的不可用并不会导致整个对象的不可用。查询优化器会自动从查询计划中移除未被引用的分区,因此当分区不可用时,查询不会受到影响。 -
更简便的模式对象管理
分区对象有可以集体或单独管理的部分。DDL语句可以操作分区,而不是整个表或索引。因此,您可以将重建索引或表等资源密集型任务分解。例如,您可以一次移动一个表分区。如果出现问题,那么只需要重新执行分区移动,而不需要重新移动整个表。此外,删除分区避免了执行大量的DELETE语句。 -
在OLTP系统中减少对共享资源的争用
在某些OLTP系统中,分区可以减少对共享资源的争用。例如,DML操作分布在多个片段上,而不是一个片段。 -
在数据仓库中增强查询性能
在数据仓库中,分区可以加速处理临时查询。例如,包含一百万行的销售表可以按季度分区。
4.1.1. 分区的特点
表或索引的每个分区必须具有相同的逻辑属性,例如列名、数据类型和约束。例如,表中的所有分区共享相同的列和约束定义,索引中的所有分区共享相同的索引列。然而,每个分区可以具有独立的物理属性,例如它所属的表空间。
4.1.1.1. 分区键
分区键是一组一个或多个列,它决定了分区表中每一行应该进入哪个分区。每一行都明确无误地被分配到一个单一的分区。在sale表中,您可以指定time_id列为范围分区的键。数据库根据此列中的日期是否落在指定范围内来分配行到分区。Oracle数据库通过使用分区键自动将插入、更新和删除操作定向到适当的分区。
4.1.1..2. 分区策略
Oracle 分区提供了几种分区策略,这些策略控制数据库如何将数据放置到分区中。基本策略包括范围、列表和哈希分区。单级分区策略仅使用一种数据分布方法,例如,仅使用列表分区或仅使用范围分区。在复合分区中,表首先根据一种数据分布方法进行分区,然后每个分区进一步使用第二种数据分布方法划分为子分区。例如,你可以使用列表分区对 channel_id进行分区,并使用范围子分区对time_id进行分区。
范围分区:在范围分区中,数据库根据分区键值的范围将行映射到分区。范围分区是最常见的分区类型,通常与日期一起使用。
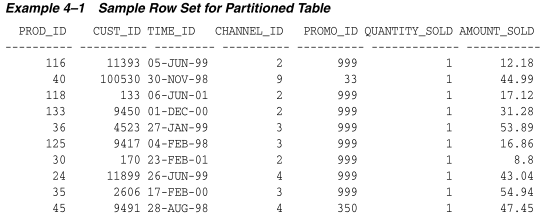
假设你想要填充示例 4-1 中显示的销售行到一个分区表中。
你使用示例 4-2 中的语句创建了一个名为 time_range_sales 的分区表。time_id 列是分区键。
Example 4–2 Range-Partitioned Table
CREATE TABLE time_range_sales (
prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2) )
PARTITION BY RANGE (time_id)
(PARTITION SALES_1998 VALUES LESS THAN (TO_DATE('01-JAN-1999','DD-MON-YYYY')),
PARTITION SALES_1999 VALUES LESS THAN (TO_DATE('01-JAN-2000','DD-MON-YYYY')),
PARTITION SALES_2000 VALUES LESS THAN (TO_DATE('01-JAN-2001','DD-MON-YYYY')),
PARTITION SALES_2001 VALUES LESS THAN (MAXVALUE)
);
之后,你使用示例 4-1 中的行数据加载time_range_sales分区表。图 4-1 显示了四个分区中的行分布。数据库根据PARTITION BY RANGE子句中指定的规则,根据time_id值为每一行选择相应的分区。
范围分区键值决定了范围分区的高值,这被称为转换点。在图4-1中,SALES_1998分区包含分区键time_id值小于转换点01-JAN-1999的行。
数据库为超出该转换点的数据创建间隔分区。间隔分区通过指示数据库在插入到表中的数据超出所有范围分区时自动创建指定范围或间隔的分区,从而扩展了范围分区。在图4-1中,SALES_2001分区包含分区键time_id值大于或等于 01-JAN-2001的行。
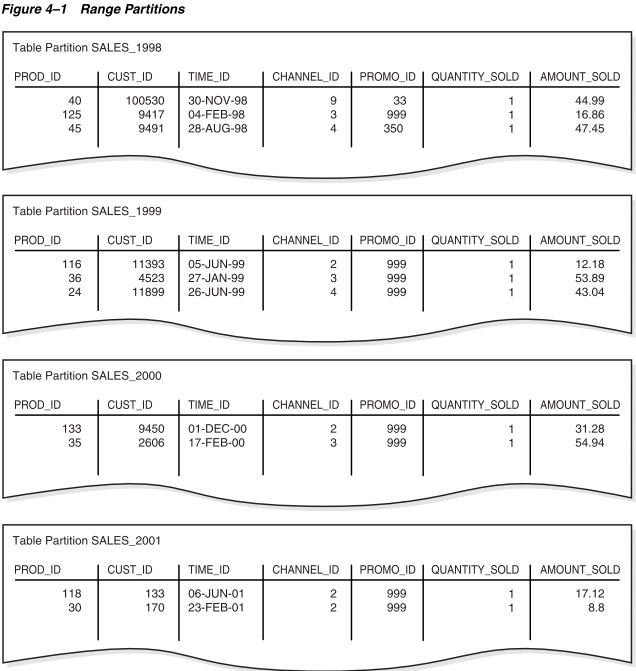
列表分区:在列表分区中,数据库使用一组离散值作为每个分区的分区键。你可以使用列表分区来控制个别行如何映射到特定的分区。通过使用列表,你可以在用于标识它们的键不方便排序时,对相关数据集进行分组和组织。假设你使用示例4-3中的语句创建了一个名为list_sales的列表分区表。channel_id列是分区键。
Example 4–3 List-Partitioned Table
CREATE TABLE list_sales (
prod_id NUMBER(6)
,cust_id NUMBER
,time_id DATE
,channel_id CHAR(1)
,promo_id NUMBER(6)
,quantity_sold NUMBER(3)
,amount_sold NUMBER(10,2))
PARTITION BY LIST (channel_id)
(PARTITION even_channels VALUES (2,4),
PARTITION odd_channels VALUES (3,9)
);
之后,你使用示例4-1中的行数据加载表。图4-2显示了两个分区中的行分布。数据库根据PARTITION BY LIST子句中指定的规则,根据channel_id值为每一行选择相应的分区。channel_id值为 2 或 4 的行存储在 EVEN_CHANNELS分区中,而channel_id值为 3 或 9 的行存储在ODD_CHANNELS分区中。
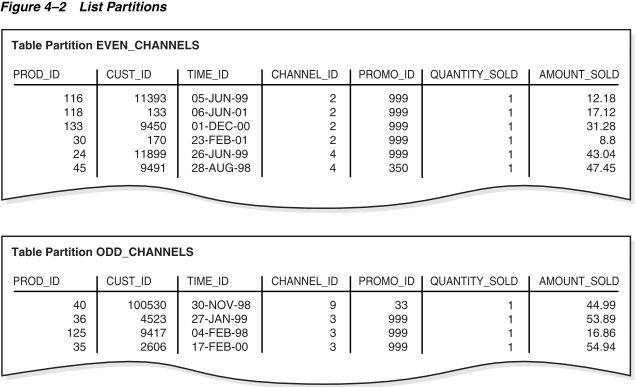
哈希分区:在哈希分区中,数据库根据数据库对用户指定的分区键应用的哈希算法将行映射到分区。行的目的地由数据库应用的内部哈希函数确定。哈希算法旨在均匀地将行分布在设备上,以便每个分区包含大约相同数量的行。
哈希分区对于分割大型表以提高可管理性非常有用。你不是管理一个大型表,而是管理几个较小的部分。单个哈希分区的丢失不会影响剩余的分区,并且可以独立恢复。哈希分区在具有高更新争用的 OLTP(在线事务处理)系统中也非常有用。
例如,一个段被分割成几个部分,每个部分都会进行更新,而不是一个单独的段经历争用。假设你使用示例4-4中的语句创建了名为hash_sales的分区表。prod_id列是分区键。
Example 4–4 Hash-Partitioned Table
CREATE TABLE hash_sales (
prod_id NUMBER(6)
,cust_id NUMBER
,time_id DATE
,channel_id CHAR(1)
,promo_id NUMBER(6)
,quantity_sold NUMBER(3)
,amount_sold NUMBER(10,2) )
PARTITION BY HASH (prod_id)
PARTITIONS 2;
之后,你使用示例4-1中的行数据加载表。图4-3显示了两个分区中可能的行分布。请注意,这些分区的名称是由系统生成的。
当你插入行时,数据库会尝试将它们随机且均匀地分布在各个分区中。你不能指定行放置到哪个分区。数据库应用哈希函数,其结果决定了包含该行的分区。如果你更改分区的数量,数据库会重新在所有分区上分布数据。
4.1.2. 分区表
分区表由一个或多个分区组成,这些分区可以单独管理,并且可以独立于其他分区运行。表要么是分区的,要么不是分区的。即使分区表只包含一个分区,这个表也与不能添加分区的非分区表不同。”分区特性”第4-2页提供了分区表的例子。
分区表由一个或多个表分区段组成。如果你创建了一个名为hash_products的分区表,那么不会为这个表分配表段。相反,数据库将每个表分区的数据存储在其自己的分区段中。每个表分区段包含表数据的一部分。堆组织表的一些或所有分区可以以压缩格式存储。压缩节省空间,并且可以加快查询执行速度。因此,压缩在数据仓库环境中很有用,其中插入和更新操作的数量很小,在OLTP环境中也是如此。表压缩的属性可以为表空间、表或表分区声明。如果在表空间级别声明,则默认情况下在表空间中创建的表会被压缩。你可以更改表的压缩属性,这种情况下,更改只适用于进入该表的新数据。因此,单个表或分区可能包含压缩和未压缩的块,这保证了数据大小不会因为压缩而增加。如果压缩可能会增加块的大小,那么数据库不会将其应用于该块。
4.1.3. 分区索引
分区索引是一种像分区表一样被分解成更小、更易于管理的部分的索引。全局索引与它们所创建的表独立分区,而本地索引则自动与表的分区方法相关联。像分区表一样,分区索引提高了可管理性、可用性、性能和可扩展性。下图显示了索引分区选项。
4.1.3.1. 本地分区索引
在本地分区索引中,索引是按照与其所对应的表相同的列、相同数量的分区以及相同的分区边界进行分区的。每个索引分区与底层表的一个分区精确关联,这样,一个索引分区中的所有键仅引用存储在单个表分区中的行。通过这种方式,数据库自动将索引分区与其关联的表分区同步,使得每个表-索引对独立。本地分区索引在数据仓库环境中很常见。本地索引提供以下优势:
- 可用性增加,因为使数据无效或不可用的分区操作仅影响该分区。
- 分区维护简化。当移动表分区或数据从分区中老化时,只需重建或维护相关的本地索引分区。在全局索引中,所有索引分区都必须重建或维护。
- 如果对分区进行点时间恢复,则索引可以恢复到恢复时间(见第18-14页的“数据文件恢复”)。不需要重建整个索引。
示例4-4显示了使用prod_id列作为分区键创建分区hash_sales表的语句。示例4-5在hash_sales表的time_id列上创建了一个本地分区索引。
Example 4–5 Local Partitioned Index
CREATE INDEX hash_sales_idx ON hash_sales(time_id) LOCAL;
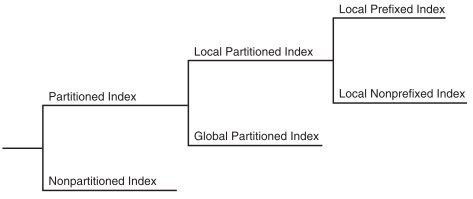
在图4-4中,hash_products表有两个分区,因此hash_sales_idx索引也有两个分区。每个索引分区与不同的表分区相关联。索引分区SYS_P38索引表分区SYS_P33中的行,而索引分区SYS_P39索引表分区SYS_P34中的行。
您不能显式地向本地索引添加分区。相反,只有在向底层表添加分区时,才会向本地索引添加新分区。同样,您不能显式地从本地索引中删除分区。相反,只有在从底层表删除分区时,本地索引分区才会被删除。
像其他索引一样,您可以在分区表上创建位图索引。唯一的限制是位图索引必须是分区表的本地索引——它们不能是全局索引。全局位图索引仅支持非分区表。
本地前缀和非前缀索引
本地分区索引分为以下子类别:
■ 本地前缀索引
在这种情况下,分区键位于索引定义的前端。在第4-3页的示例4-2中,表是根据time_id的范围进行分区的。在这张表上的本地前缀索引将把time_id作为其列列表中的第一列。
■ 本地非前缀索引
在这种情况下,分区键不在索引列列表的前端,甚至可能根本不在列表中。在第4-8页的示例4-5中,索引是本地非前缀的,因为分区键product_id不在前端。
两种类型的索引都可以利用分区消除(也称为分区修剪),这是当优化器通过排除某些分区来加速数据访问时发生的情况。一个查询能否消除分区取决于查询谓词。使用本地前缀索引的查询总是允许进行索引分区消除,而使用本地非前缀索引的查询可能不允许。
在Oracle数据库中,分区消除是一种性能优化技术,它允许数据库查询在执行时跳过不包含相关数据的分区,从而减少I/O操作和提高查询效率。本地前缀索引由于其分区键位于索引定义的前端,因此优化器更容易确定哪些分区可能包含查询所需的数据,从而更容易实现分区消除。相反,本地非前缀索引的分区键不在索引定义的前端,优化器可能无法直接从索引中确定哪些分区是相关的,因此在某些情况下可能无法实现分区消除。
本地分区索引的存储方式类似于表分区,每个本地索引分区都存储在自己的段中。每个段包含索引数据的一部分。因此,由四个分区组成的本地索引不是存储在单个索引段中,而是存储在四个独立的段中。
4.1.3.2. 全局分区索引
全局分区索引是一个B树索引,它的分区是独立于它所创建的底层表进行的。单个索引分区可以指向任何或所有表分区,而在本地分区索引中,索引分区和表分区之间存在一对一的关系。
一般来说,全局索引对于OLTP(在线事务处理)应用程序很有用,其中快速访问、数据完整性和可用性很重要。在OLTP系统中,一个表可能按一个键进行分区,例如,employees.department_id列,但应用程序可能需要通过许多不同的键来访问数据,例如,通过employee_id或job_id。在这种情况下,全局索引可能会很有用。
您可以按范围或哈希来分区全局索引。如果按范围分区,则数据库会根据您在列列表中指定的表列的值范围来分区全局索引。如果按哈希分区,则数据库会使用分区键列中的值的哈希函数来分配行到分区。例如,假设您在示例4-2中的time_range_sales表上创建了一个全局分区索引。在这个表中,1998年的销售行存储在一个分区中,1999年的销售行存储在另一个分区中,依此类推。示例4-6创建了一个按channel_id列范围分区的全局索引。
Example 4–6 Global Partitioned Index
CREATE INDEX time_channel_sales_idx
ON time_range_sales (channel_id)
GLOBAL PARTITION BY RANGE (channel_id)
(PARTITION p1 VALUES LESS THAN (3),
PARTITION p2 VALUES LESS THAN (4),
PARTITION p3 VALUES LESS THAN (MAXVALUE)
);
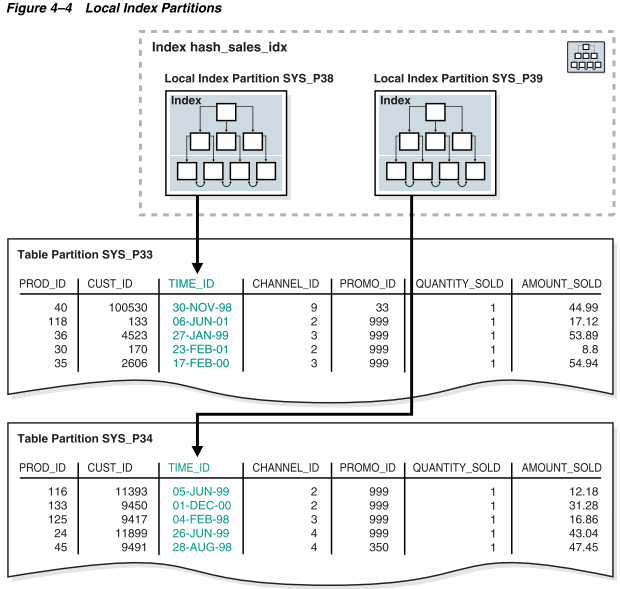
如图4-5所示,全局索引分区可以包含指向多个表分区的条目。索引分区p1指向具有channel_id为2的行,索引分区p2指向具有channel_id为3的行,索引分区p3指向具有channel_id为4或9的行。
4.1.4 分区索引组织表
您可以按范围、列表或哈希对索引组织表(IOT)进行分区。分区对于提高IOT的可管理性、可用性和性能很有用。此外,使用IOT的数据容器可以利用分区其存储数据的能力。
请注意分区IOT的以下特性:
■ 分区列必须是主键列的子集。
■ 次级索引可以本地分区和全局分区。
■ 溢出数据段总是与表分区等分。
Oracle数据库支持在分区和非分区的索引组织表上创建位图索引。在索引组织表上创建位图索引需要一个映射表。
4.2. 视图概述
视图是对一个或多个表的逻辑表示。本质上,视图是一个存储的查询。视图从它所基于的表中获取数据,这些表被称为基表。基表可以是表或其他视图。对视图执行的所有操作实际上都会影响到基表。您可以在大多数使用表的地方使用视图。
注意:物化视图使用与标准视图不同的数据结构。详见第4-16页的“物化视图概述”。
视图使您能够根据不同类型用户的需求定制数据的展示。视图通常用于:
■ 通过限制对表的预设行或列的访问,提供额外的表安全级别
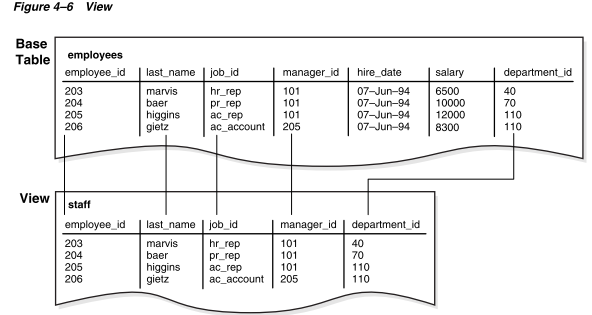
例如,图4-6显示了staff视图不显示基表employees的salary或commission_pct列。
■ 隐藏数据复杂性
例如,可以定义一个包含连接的单个视图,这是多个表中相关列或行的集合。然而,视图隐藏了这些信息实际上来自多个表的事实。查询还可能对表信息进行广泛的计算。因此,用户可以在不知道如何执行连接或计算的情况下查询视图。
■ 以不同于基表的视角展示数据
例如,可以重命名视图的列,而不会影响视图所基于的表。
■ 将应用程序与基表定义的更改隔离
例如,如果视图的定义查询引用了一个四列表的三个列,并且表中添加了第五个列,那么视图的定义不会受到影响,使用视图的所有应用程序也不会受到影响。
作为使用视图的一个例子,考虑hr.employees表,它包含多个列和众多行。为了只允许用户查看这些列中的五列或特定的行,您可以如下创建视图:
CREATE VIEW staff AS
SELECT employee_id, last_name, job_id, manager_id, department_id
FROM employees;
与所有子查询一样,定义视图的查询不能包含FOR UPDATE子句。图4-6以图形方式展示了名为staff的视图。请注意,该视图只显示了基表中的五列。
4.2.1. 视图特点
与表不同,视图不分配存储空间,也不包含数据。相反,视图由一个查询定义,该查询从视图引用的基表中提取或派生数据。由于视图基于其他对象,它不需要除了存储定义视图的查询之外的存储空间,这些查询存储在数据字典中。
视图对其引用的对象有依赖性,这些依赖性由数据库自动处理。例如,如果您删除并重新创建视图的基表,数据库将确定新的基表是否符合视图定义的要求。
4.2.1.1. 在视图中的数据操作
由于视图是从表派生出来的,它们有很多相似之处。例如,视图可以包含多达1000列,就像表一样。用户可以查询视图,并且在某些限制下,他们可以在视图上执行数据操作语言(DML)。对视图执行的操作可能会影响视图的某些基表中的数据,并受到基表的完整性约束和触发器的约束控制。
由于视图是从表派生出来的,它们有很多相似之处。例如,视图可以包含多达1000列,就像表一样。用户可以查询视图,并且在某些限制下,他们可以在视图上执行数据操作语言(DML)。对视图执行的操作可能会影响视图的某些基表中的数据,并受到基表的完整性约束和触发器的约束控制。
以下示例创建了hr.employees表的一个视图:
CREATE VIEW staff_dept_10 AS
SELECT employee_id, last_name, job_id, manager_id, department_id
FROM employees WHERE department_id = 10
WITH CHECK OPTION CONSTRAINT staff_dept_10_cnst;
定义查询仅引用了部门10的行。CHECK OPTION创建了一个带有约束的视图,这样针对视图发出的INSERT和UPDATE语句就不能产生视图无法选择的行。因此,可以插入部门10的员工行,但不能插入部门30的行。
4.2.1.2. 视图中数据的访问方式
Oracle数据库将视图定义存储在数据字典中,作为定义视图的查询文本。当您在SQL语句中引用视图时,Oracle数据库执行以下任务:
-
合并查询(尽可能)针对视图的查询与定义视图和任何底层视图的查询,Oracle数据库优化合并后的查询,就像您在不引用视图的情况下发出查询一样。因此,无论列是否在视图定义或用户对视图的查询中引用,Oracle数据库都可以使用任何引用基表列上的索引。有时Oracle数据库无法将视图定义与用户查询合并。在这种情况下,Oracle数据库可能无法使用引用列上的所有索引。
-
在共享SQL区域解析合并后的语句
如果没有任何现有的共享SQL区域包含类似的语句,Oracle数据库只有在引用视图的语句中解析一个新的共享SQL区域。因此,视图提供了与共享SQL相关的减少内存使用的好处。 -
执行SQL语句
以下示例说明了查询视图时的数据访问。假设您基于employees和departments表创建了employees_view:
CREATE VIEW employees_view AS
SELECT employee_id, last_name, salary, location_id
FROM employees
JOIN departments
USING (department_id)
WHERE department_id = 10;
某个用户在employee_view执行了下面的查询
SELECT last_name FROM employees_view WHERE employee_id = 200;
Oracle数据库合并视图和用户查询以构建以下查询,然后执行该查询以检索数据:
SELECT last_name
FROM employees, departments
WHERE employees.department_id = departments.department_id
AND departments.department_id = 10
AND employees.employee_id = 200;









没有回复内容