

前言
ConcurrentLinkedQueue是基于链接节点的无界线程安全队列。此队列按照FIFO(先进先出)原则对元素进行排序。队列的头部是队列中存在时间最长的元素,而队列的尾部则是最近添加的元素。新的元素总是被插入到队列的尾部,而队列的获取操作(例如poll或peek)则是从队列头部开始。
与传统的LinkedList不同,ConcurrentLinkedQueue使用了一种高效的非阻塞算法,被称为无锁编程(Lock-Free programming),它通过原子变量和CAS(Compare-And-Swap)操作来保证线程安全,而不是通过传统的锁机制。这使得它在高并发场景下具有出色的性能表现。
可以看做一个线程安全的LinkedList,是一个线程安全的无界队列,但LinkedList是一个双向链表,而ConcurrentLinkedQueue是单向链表。
ConcurrentLinkedQueue线程安全在于设置head、tail以及next指针时都用的cas操作,而且node里的item和next变量都是用volatile修饰,保证了多线程下变量的可见性。而ConcurrentLinkedQueue的所有读操作都是无锁的,所以可能读会存在不一致性。
应用场景
如果对队列加锁的成本较高则适合使用无锁的 ConcurrentLinkedQueue 来替代。适合在对性能要求相对较高,同时有多个线程对队列进行读写的场景。
ConcurrentLinkedQueue通过无锁来做到了更高的并发量,是个高性能的队列,但是使用场景相对不如阻塞队列常见,毕竟取数据也要不停的去循环,不如阻塞的设计,但是在并发量特别大的情况下,是个不错的选择,性能上好很多,而且这个队列的设计也是特别费力,尤其的使用的改良算法和对哨兵的处理。
主要方法
ConcurrentLinkedQueue提供了丰富的方法来操作队列,包括:
offer(E e):将指定的元素插入此队列的尾部。add(E e):将指定的元素插入此队列的尾部(与offer方法功能相同,但在失败时抛出异常)。poll():获取并移除此队列的头部,如果此队列为空,则返回null。peek():获取但不移除此队列的头部,如果此队列为空,则返回null。size():返回此队列中的元素数量。需要注意的是,由于并发的原因,这个方法返回的结果可能并不准确。如果需要在并发环境下获取准确的元素数量,建议使用java.util.concurrent.atomic包中的原子变量进行计数。isEmpty():检查此队列是否为空。与size()方法类似,由于并发的原因,这个方法返回的结果也可能不准确。
需要注意的是,在并发环境下使用size()和isEmpty()方法时需要特别小心,因为它们的结果可能并不准确。如果需要精确的元素数量或空队列检测,建议使用额外的同步机制或原子变量来实现。
底层源码
类的内部类
private static class Node<E> {
// 元素
volatile E item;
// next域
volatile Node<E> next;
/**
* Constructs a new node. Uses relaxed write because item can
* only be seen after publication via casNext.
*/
// 构造函数
Node(E item) {
// 设置item的值
UNSAFE.putObject(this, itemOffset, item);
}
// 比较并替换item值
boolean casItem(E cmp, E val) {
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
void lazySetNext(Node<E> val) {
// 设置next域的值,并不会保证修改对其他线程立即可见
UNSAFE.putOrderedObject(this, nextOffset, val);
}
// 比较并替换next域的值
boolean casNext(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
// Unsafe mechanics
// 反射机制
private static final sun.misc.Unsafe UNSAFE;
// item域的偏移量
private static final long itemOffset;
// next域的偏移量
private static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Node.class;
itemOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("item"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}
说明: Node类表示链表结点,用于存放元素,包含item域和next域,item域表示元素,next域表示下一个结点,其利用反射机制和CAS机制来更新item域和next域,保证原子性。
类的属性
public class ConcurrentLinkedQueue<E> extends AbstractQueue<E>
implements Queue<E>, java.io.Serializable {
// 版本序列号
private static final long serialVersionUID = 196745693267521676L;
// 反射机制
private static final sun.misc.Unsafe UNSAFE;
// head域的偏移量
private static final long headOffset;
// tail域的偏移量
private static final long tailOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = ConcurrentLinkedQueue.class;
headOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("head"));
tailOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("tail"));
} catch (Exception e) {
throw new Error(e);
}
}
// 头节点
private transient volatile Node<E> head;
// 尾结点
private transient volatile Node<E> tail;
}
说明: 属性中包含了head域和tail域,表示链表的头节点和尾结点,同时,ConcurrentLinkedQueue也使用了反射机制和CAS机制来更新头节点和尾结点,保证原子性。
类的构造函数
- ConcurrentLinkedQueue()
public ConcurrentLinkedQueue() {
// 初始化头节点与尾结点
head = tail = new Node<E>(null);
}
说明: 该构造函数用于创建一个最初为空的 ConcurrentLinkedQueue,头节点与尾结点指向同一个结点,该结点的item域为null,next域也为null。
- ConcurrentLinkedQueue(Collection<? extends E>)
public ConcurrentLinkedQueue(Collection<? extends E> c) {
Node<E> h = null, t = null;
for (E e : c) { // 遍历c集合
// 保证元素不为空
checkNotNull(e);
// 新生一个结点
Node<E> newNode = new Node<E>(e);
if (h == null) // 头节点为null
// 赋值头节点与尾结点
h = t = newNode;
else {
// 直接头节点的next域
t.lazySetNext(newNode);
// 重新赋值头节点
t = newNode;
}
}
if (h == null) // 头节点为null
// 新生头节点与尾结点
h = t = new Node<E>(null);
// 赋值头节点
head = h;
// 赋值尾结点
tail = t;
}
说明: 该构造函数用于创建一个最初包含给定 collection 元素的 ConcurrentLinkedQueue,按照此 collection 迭代器的遍历顺序来添加元素。
核心函数分析
offer函数
public boolean offer(E e) {
// 检查e是不是null,是的话抛出NullPointerException异常。
checkNotNull(e);
// 创建新的节点
final Node<E> newNode = new Node<E>(e);
// 将“新的节点”添加到链表的末尾。
for (Node<E> t = tail, p = t;;) {//这个for循环是个死循环,增加了两个指针p,t。
Node<E> q = p.next;
// 情况1:q为空,p就是尾节点,新节点插入
if (q == null) {
// CAS操作:如果“p的下一个节点为null”(即p为尾节点),则设置p的下一个节点为newNode。
// 如果该CAS操作成功的话,则比较“p和t”(若p不等于t,则设置newNode为新的尾节点),然后返回true。
// 如果该CAS操作失败,这意味着“其它线程对尾节点进行了修改”,则重新循环。
if (p.casNext(null, newNode)) {
if (p != t) // hop two nodes at a time
casTail(t, newNode); // Failure is OK.
return true;
}
}
// 情况2:p和q相等
else if (p == q)
p = (t != (t = tail)) ? t : head;
// 情况3:其它\\
//这里是移动p指针,意思就是此时如果p不是最后一个元素则把p指针指向tail,否则指向q,也就是指向p.next元素。
else
p = (p != t && t != (t = tail)) ? t : q;
}
}
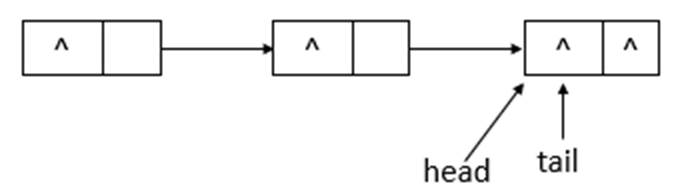
说明: offer函数用于将指定元素插入此队列的尾部。下面模拟offer函数的操作,队列状态的变化(假设单线程添加元素,连续添加10、20两个元素)。
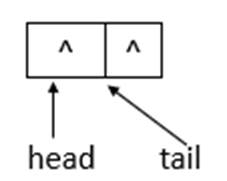
若ConcurrentLinkedQueue的初始状态如上图所示,即队列为空。单线程添加元素,此时,添加元素10,则状态如下所示
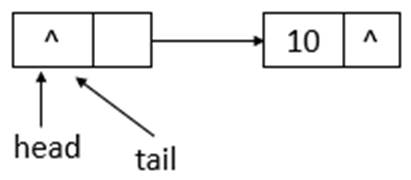
如上图所示,添加元素10后,tail没有变化,还是指向之前的结点,继续添加元素20,则状态如下所示
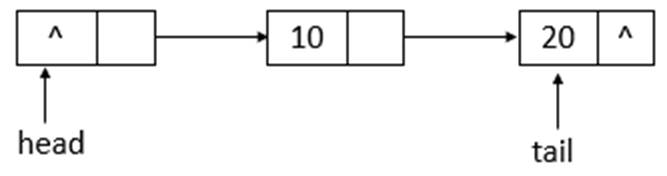
如上图所示,添加元素20后,tail指向了最新添加的结点。
poll函数
public E poll() {
restartFromHead:
for (;;) { // 无限循环
for (Node<E> h = head, p = h, q;;) { // 保存头节点
// item项
E item = p.item;
if (item != null && p.casItem(item, null)) { // item不为null并且比较并替换item成功
// Successful CAS is the linearization point
// for item to be removed from this queue.
if (p != h) // p不等于h // hop two nodes at a time
// 更新头节点
updateHead(h, ((q = p.next) != null) ? q : p);
// 返回item
return item;
}
else if ((q = p.next) == null) { // q结点为null
// 更新头节点
updateHead(h, p);
return null;
}
else if (p == q) // p等于q
// 继续循环
continue restartFromHead;
else
// p赋值为q
p = q;
}
}
}
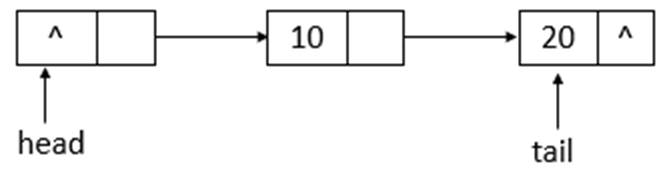
说明: 此函数用于获取并移除此队列的头,如果此队列为空,则返回null。下面模拟poll函数的操作,队列状态的变化(假设单线程操作,状态为之前offer10、20后的状态,poll两次)。
队列初始状态如上图所示,在poll操作后,队列的状态如下图所示
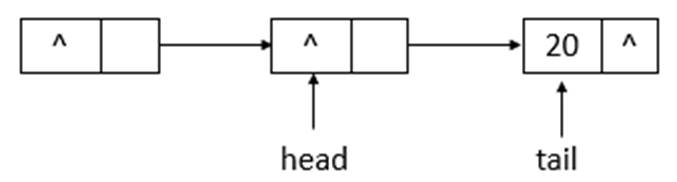
如上图可知,poll操作后,head改变了,并且head所指向的结点的item变为了null。再进行一次poll操作,队列的状态如下图所示。
如上图可知,poll操作后,head结点没有变化,只是指示的结点的item域变成了null。
remove函数
public boolean remove(Object o) {
// 元素为null,返回
if (o == null) return false;
Node<E> pred = null;
for (Node<E> p = first(); p != null; p = succ(p)) { // 获取第一个存活的结点
// 第一个存活结点的item值
E item = p.item;
if (item != null &&
o.equals(item) &&
p.casItem(item, null)) { // 找到item相等的结点,并且将该结点的item设置为null
// p的后继结点
Node<E> next = succ(p);
if (pred != null && next != null) // pred不为null并且next不为null
// 比较并替换next域
pred.casNext(p, next);
return true;
}
// pred赋值为p
pred = p;
}
return false;
}
说明: 此函数用于从队列中移除指定元素的单个实例(如果存在)。其中,会调用到first函数和succ函数,first函数的源码如下
Node<E> first() {
restartFromHead:
for (;;) { // 无限循环,确保成功
for (Node<E> h = head, p = h, q;;) {
// p结点的item域是否为null
boolean hasItem = (p.item != null);
if (hasItem || (q = p.next) == null) { // item不为null或者next域为null
// 更新头节点
updateHead(h, p);
// 返回结点
return hasItem ? p : null;
}
else if (p == q) // p等于q
// 继续从头节点开始
continue restartFromHead;
else
// p赋值为q
p = q;
}
}
}
说明: first函数用于找到链表中第一个存活的结点。succ函数源码如下
final Node<E> succ(Node<E> p) {
// p结点的next域
Node<E> next = p.next;
// 如果next域为自身,则返回头节点,否则,返回next
return (p == next) ? head : next;
}
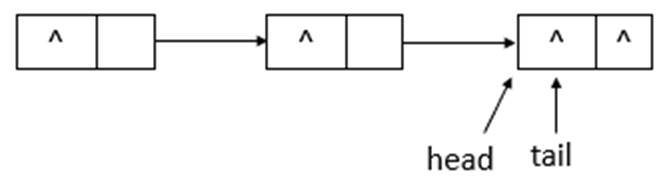
说明: succ用于获取结点的下一个结点。如果结点的next域指向自身,则返回head头节点,否则,返回next结点。下面模拟remove函数的操作,队列状态的变化(假设单线程操作,状态为之前offer10、20后的状态,执行remove(10)、remove(20)操作)。
如上图所示,为ConcurrentLinkedQueue的初始状态,remove(10)后的状态如下图所示
如上图所示,当执行remove(10)后,head指向了head结点之前指向的结点的下一个结点,并且head结点的item域置为null。继续执行remove(20),状态如下图所示
如上图所示,执行remove(20)后,head与tail指向同一个结点,item域为null。
size函数
public int size() {
// 计数
int count = 0;
for (Node<E> p = first(); p != null; p = succ(p)) // 从第一个存活的结点开始往后遍历
if (p.item != null) // 结点的item域不为null
// Collection.size() spec says to max out
if (++count == Integer.MAX_VALUE) // 增加计数,若达到最大值,则跳出循环
break;
// 返回大小
return count;
}
说明: 此函数用于返回ConcurrenLinkedQueue的大小,从第一个存活的结点(first)开始,往后遍历链表,当结点的item域不为null时,增加计数,之后返回大小。
HOPS(延迟更新的策略)的设计
通过上面对offer和poll方法的分析,我们发现tail和head是延迟更新的,两者更新触发时机为:
-
tail更新触发时机:当tail指向的节点的下一个节点不为null的时候,会执行定位队列真正的队尾节点的操作,找到队尾节点后完成插入之后才会通过casTail进行tail更新;当tail指向的节点的下一个节点为null的时候,只插入节点不更新tail。
-
head更新触发时机:当head指向的节点的item域为null的时候,会执行定位队列真正的队头节点的操作,找到队头节点后完成删除之后才会通过updateHead进行head更新;当head指向的节点的item域不为null的时候,只删除节点不更新head。
从上面更新时的状态图可以看出,head和tail的更新是“跳着的”即中间总是间隔了一个。那么这样设计的意图是什么呢?
如果让tail永远作为队列的队尾节点,实现的代码量会更少,而且逻辑更易懂。但是,这样做有一个缺点,如果大量的入队操作,每次都要执行CAS进行tail的更新,汇总起来对性能也会是大大的损耗。如果能减少CAS更新的操作,无疑可以大大提升入队的操作效率,所以doug lea大师每间隔1次(tail和队尾节点的距离为1)进行才利用CAS更新tail。对head的更新也是同样的道理,虽然,这样设计会多出在循环中定位队尾节点,但总体来说读的操作效率要远远高于写的性能,因此,多出来的在循环中定位尾节点的操作的性能损耗相对而言是很小的。
关于作者
来自一线程序员Seven的探索与实践,持续学习迭代中~
本文已收录于我的个人博客:https://www.seven97.top
公众号:seven97,欢迎关注~








没有回复内容