手搓大模型Task04:如果评估你的大模型


前言
随着LLM的推广普及,越来越多的朋友们熟悉了模型的SFT微调流程,但是对于微调的结果,尤其是如何判断各大模型在当前数据集上的表现,仍然是一个待解决的问题。并且,对选择式、判别式、生成式等不同的生成任务,如何才能够客观地评价模型的生成质量,仍是一个需要明确的问题。
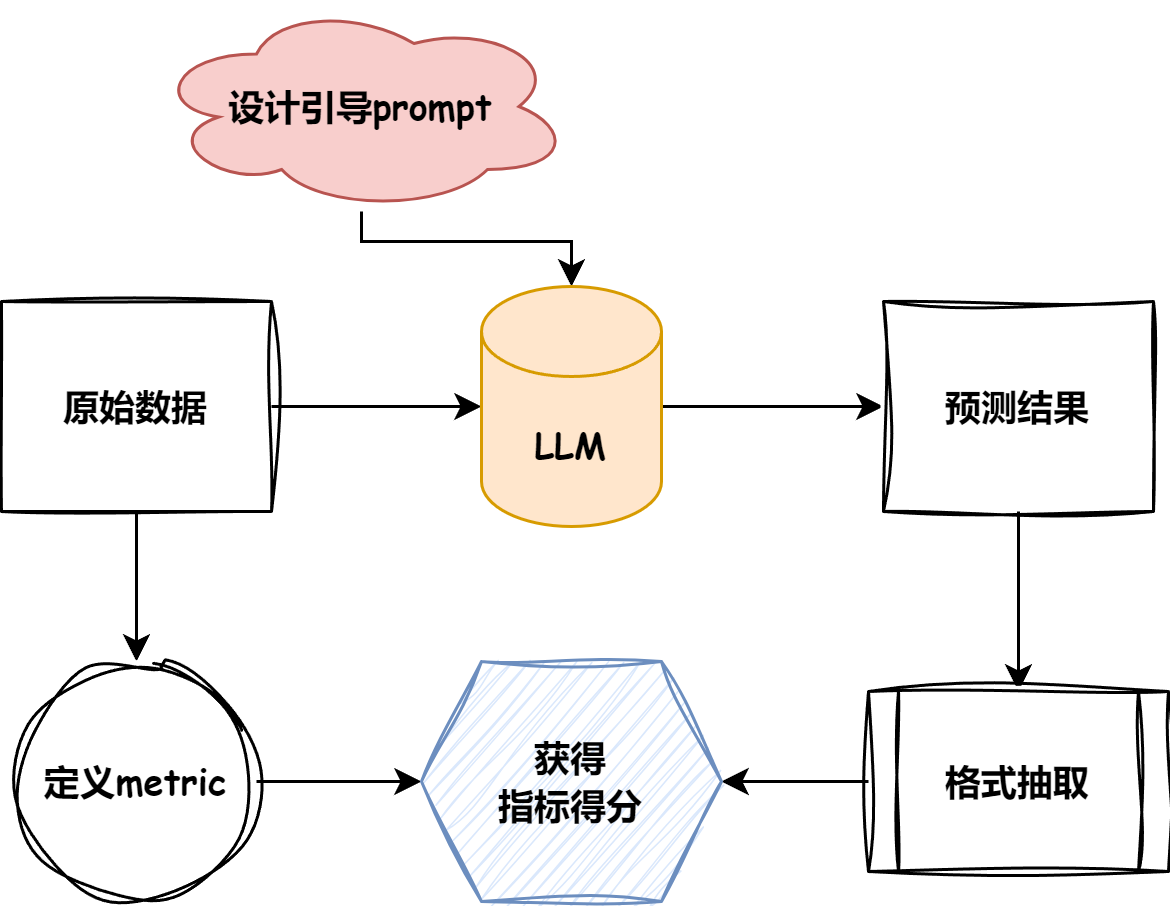
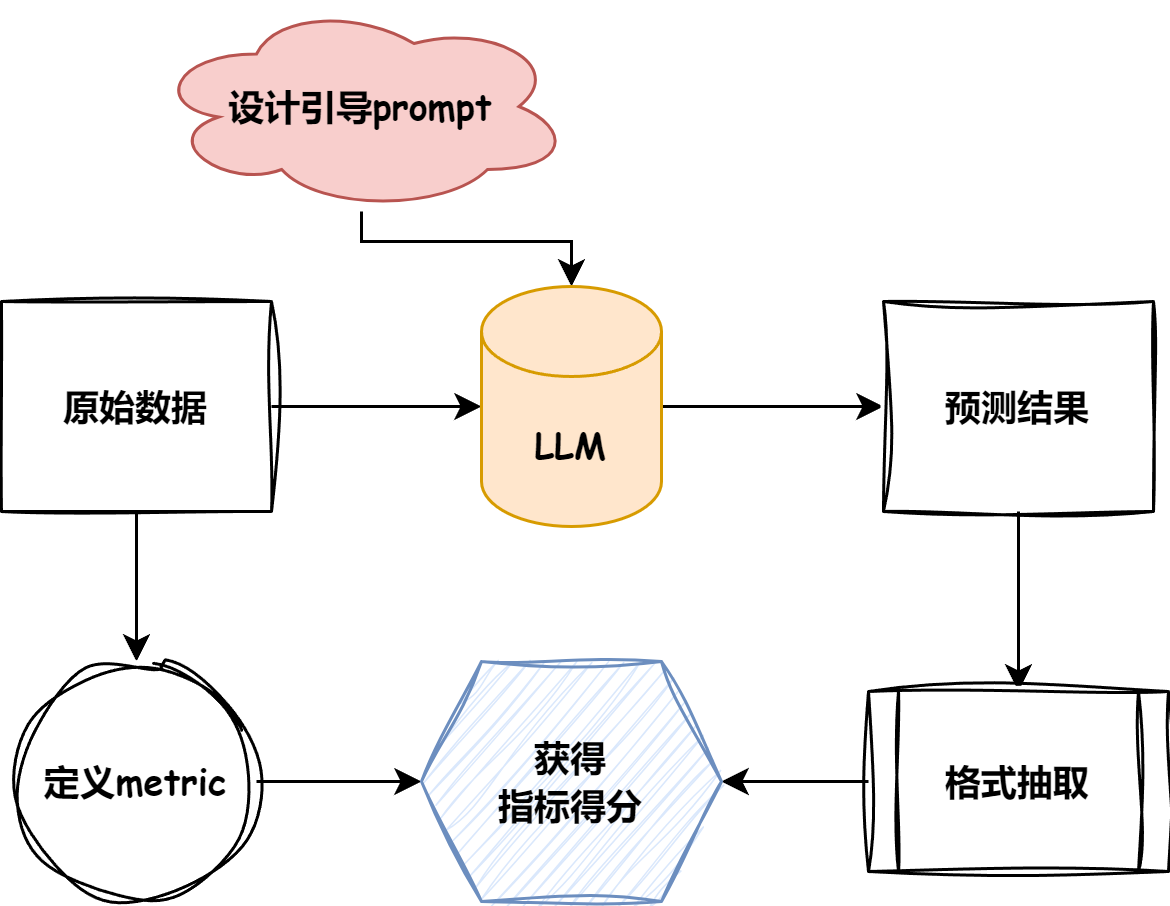
1.Evaluation包含哪些流程
首先要明确评测任务的基础pipeline。下图是评测任务的简要流程:
2.支持的评测数据集与评测Metric
所采用的数据集在这里https://github.com/lixinjie97/tiny-universe/tree/main/04.TinyEval/Eval/dataset,目前有的数据集与类型包含(后续会持续更新!):

大家可以按照需要的任务进行探索,接下来我也会手把手为大家讲解评测步骤!
3.生成式的F1
直接show例子:
”pred”: “57081.86元”, “answers”: “人民币57081.86元。”
首先,经过数据清洗与jieba分词,将短句分为词组,以示例文本为例,经过分词与去掉标点符号等操作,得到下列输出:
”pred”: [‘5708186’, ‘元’], “answers”: [‘人民币’, ‘5708186’, ‘元’]”
将上述的两个”干净”的输出送入f1评分函数如下:
def f1_score(prediction, ground_truth, **kwargs):
# Counter以dict的形式存储各个句子对应的词与其对应个数,&操作符返回两个Counter中共同的元素的键值对
common = Counter(prediction) & Counter(ground_truth)
# 显示prediction与gt的共同元素的个数
num_same = sum(common.values())
if num_same == 0:
return 0
# 即模型预测正确的样本数量与总预测样本数量的比值
precision = 1.0 * num_same / len(prediction)
# 模型正确预测的样本数量与总实际样本数量的比值
recall = 1.0 * num_same / len(ground_truth)
f1 = (2 * precision * recall) / (precision + recall)
return f1首先记录两个list中相同的元素,再统计相同的元素的总数,最终再按照precision与recall的定义分别计算相应的分数。
然后就得到该结果的对应分数啦,最后再将所有的结果取平均值,即得到该task的F1_score
4.总结
我们在进行了,模型微调后,想要知道微调的效果,那么就要选择相应的指标进行评估,设计一个完善且好用的评分指标是一件很重要的事情,需要设计者对模型的结构和数据足够地了解。








没有回复内容