
总结使用
1. VScode插件Markdown All In One 统一把markdown转html + PDF阅读器统一把html转pdf
2. VScode插件Markdown Preview Enhanced。格式是正确的。但是无法批处理和指令处理
3. pandoc –pdf-engine=xelatex typst、markdown-pdf可以试试,但是不保证公式和图片对不对,或者报错什么的
需求
markdown格式转为pdf
我遇到的:
1. 我现在想把多个八股文文档(GitHub项目里的 scutan90/DeepLearning-500-questions: 深度学习500问,以问答形式对常用的概率知识、线性代数、机器学习、深度学习、计算机视觉等热点问题进行阐述,以帮助自己及有需要的读者。 全书分为18个章节,50余万字。由于水平有限,书中不妥之处恳请广大读者批评指正。 未完待续………… 如有意合作,联系scutjy2015@163.com 版权所有,违权必究 Tan 2018.06)
2. 有的GitHub项目,可以导出markdown、pdf,比如OI-Wiki
遇到问题
1. markdown格式,涉及多种不同的设计规则。这里应该是Github专门的md格式
2. 公式有时识别不到
3. 换行、图片位置,有时做得不好
4. 中文、英文字体和粗体,有时无法处理
着手方向
1. Github本身是怎么处理打印这件事的。还有参考一些项目,比如OI-Wiki,看看它们怎么去处理,它们挺有打印成pdf的需求的。
2. 一些已有的GitHub项目,python库,还有Foxit这样的PDF阅读器,还有一些md的软件,比如typora。
3. 搜索VScode插件、GitHub项目,关键词如multi、multiply、batch
已有方法,网上的讨论
How Can I Convert Github-Flavored Markdown To A PDF – Super User
http://www.markdowntopdf.com
Grip
joeyespo/grip:在提交 GitHub README.md 文件之前,先在本地预览它们。
pip install grip
grip your_markdown.md
grip your_markdown.md --export your_markdown.html
或者:Alternatively you can download (free!) Atom (atom.io), open your file in Atom, use control + shift+ M to view it in preview, save as html, then open the html in your Chrome browser and save as pdf.
非常棒的一个工具,即装即用,就是公式识别不太好。

vscode插件Markdown Preview Enhanced
格式都挺好的
不过只能手动处理,而且无法批处理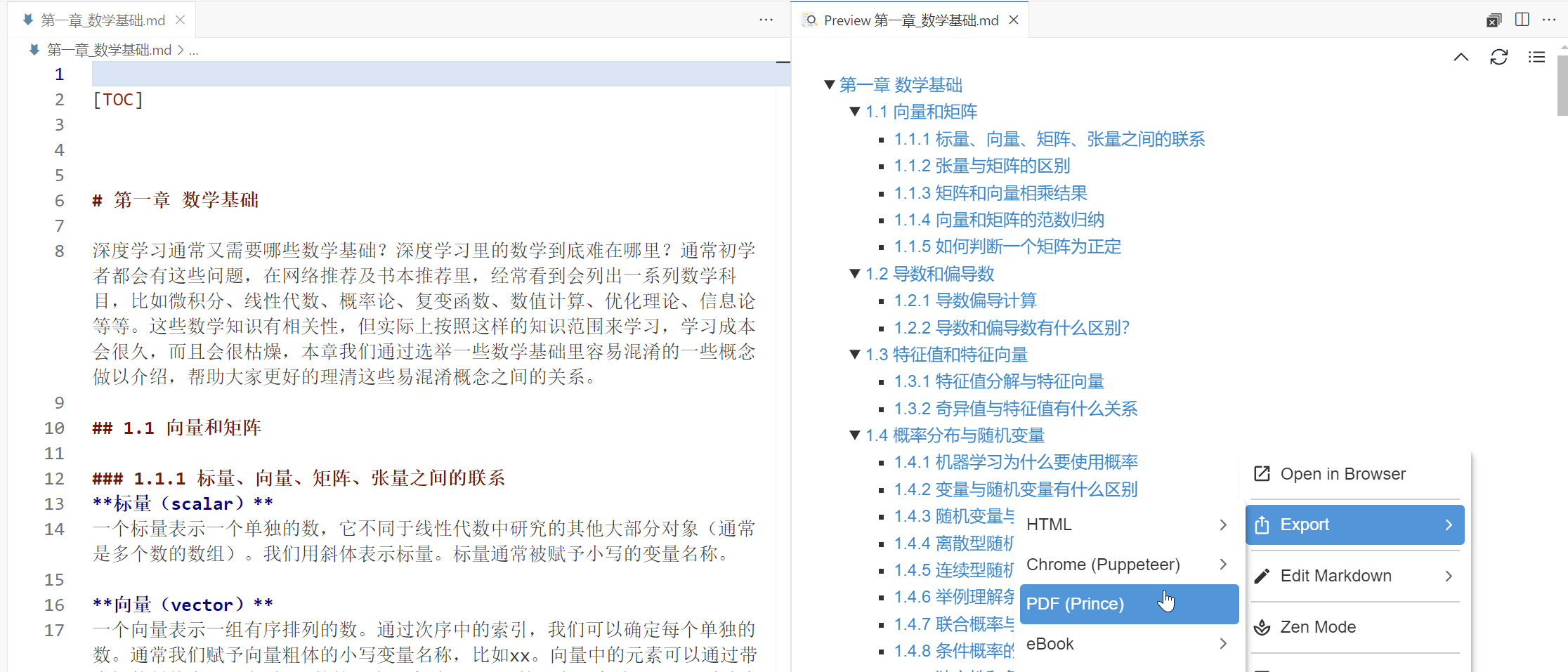
Markdown PDF vscode插件 / 工具
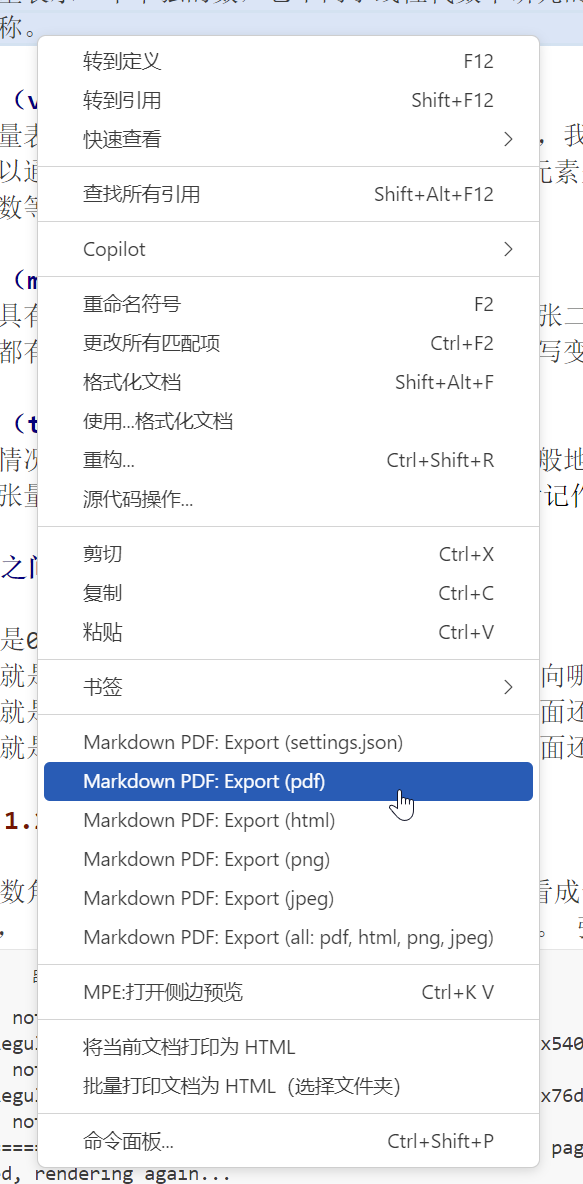
但是转pdf或html,效果不好:

这是因为markdown转pdf 公式没有得到转换,
采用VScode中Markdown PDF无法正确输出包含公式的pdf解决方案_markdown pdf 数学公式无法识别-CSDN博客 这里的方法解决,
Markdown PDF无法正确输出包含公式的pdf解决方案
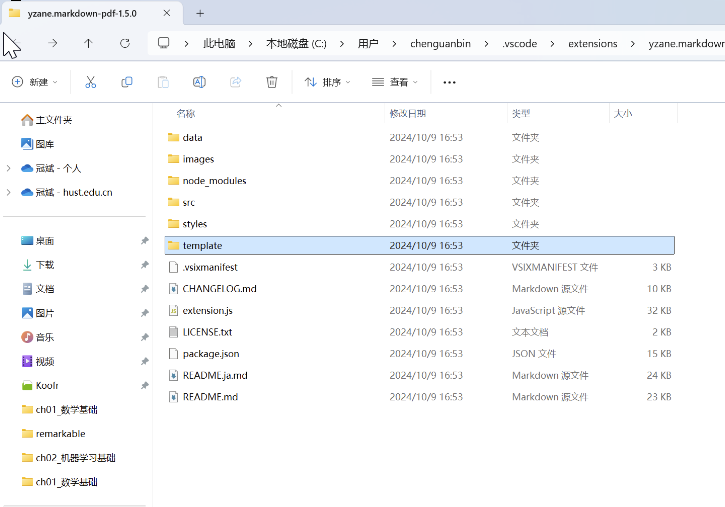
安装该插件后,可以找到如下路径文件
C://Users/<username>/.vscode/extensions/yzane.markdown-pdf-XXX/template/template.html
然后在该文件末尾添加如下两行javascript代码。
<script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=TeX-AMS-MML_HTMLorMML"></script>
<script type="text/x-mathjax-config"> MathJax.Hub.Config({ tex2jax: {inlineMath: [['$', '$']]}, messageStyle: "none" });</script>
vscode插件Markdown All in One
Ctrl+Shift+P: Markdown: Print current document to HTML 或者右键
可以批处理


得到的是md->html,完整文件夹多级结构的一一对应。特别好!
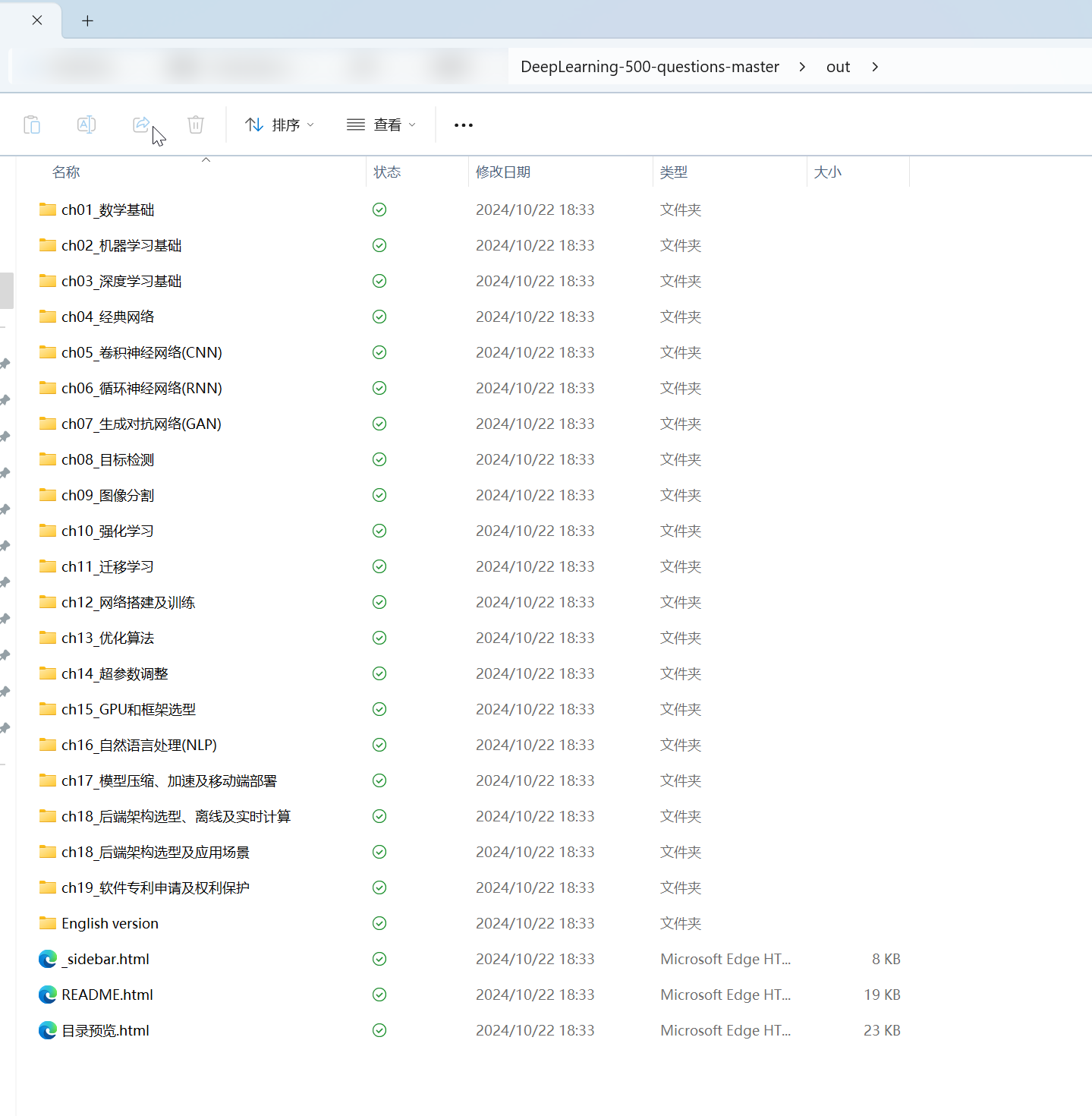
但是只能转html格式
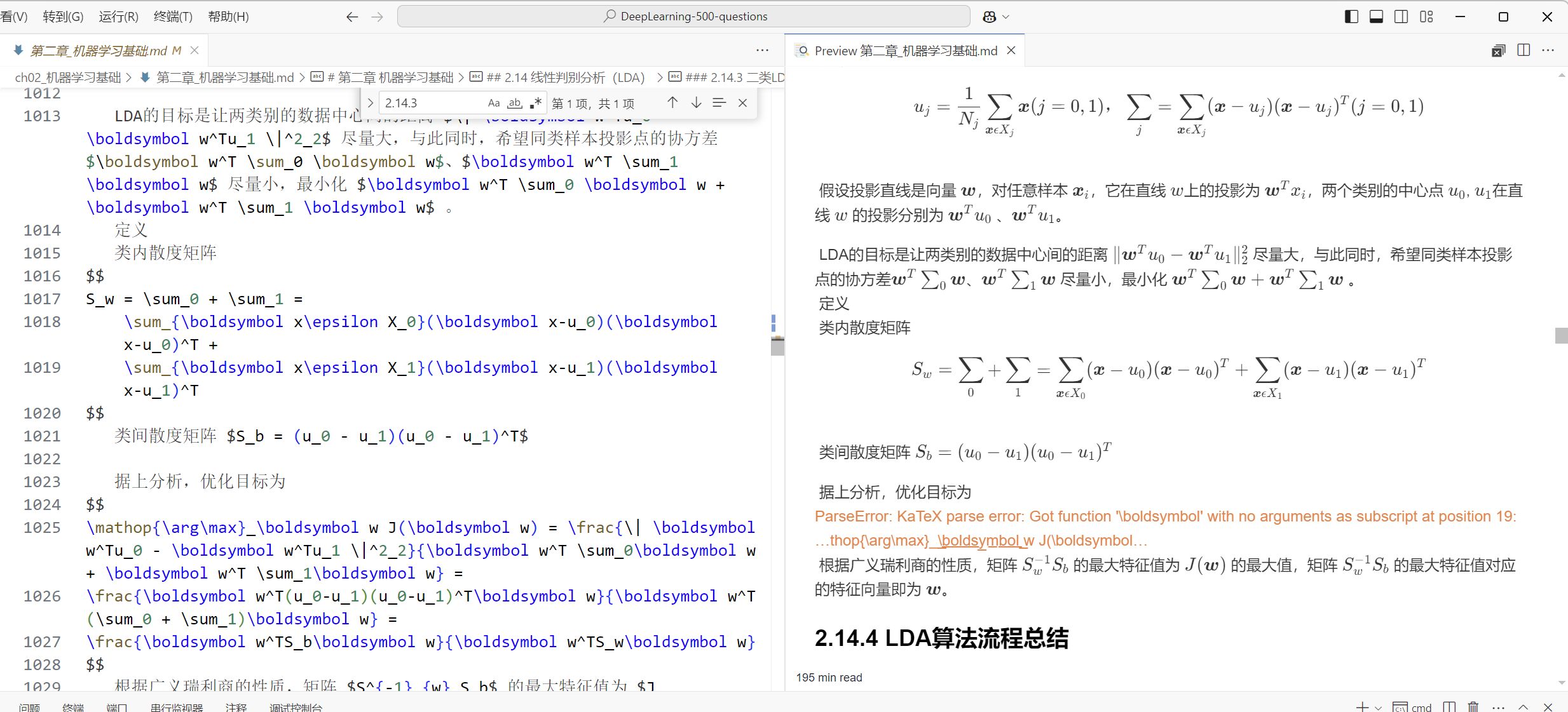
基本上公式、图片都挺准确的
也有极少数问题:
html文件搜索ParseError寻找
1. equarray(latex里的)无法识别
2. `$U,W,b$` 无法识别公式+斜体
解决方法:
1. KaTeX parse error: No such environment: eqnarray at position 7: \begin{̲e̲q̲n̲a̲r̲r̲a̲y̲}̲ \label{eq} – CSDN文库
\begin{eqnarray} 修改为\begin{equation}\begin{aligned}
\end{eqnarray} 修改为\end{aligned}\end{equation}
2.
`$修改为$,$`修改为$
chatgpt:
写一个代码,识别一个文件夹里的所有markdown文件,它可能是多级文件夹,某个字符串出现的位置和数目。这个字符串,比如是"eqnarray"、"`$"、"$`"。
写一个代码,识别一个文件夹里的所有markdown文件,它可能是多级文件夹。把markdown文件里面,所有的字符串"\begin{eqnarray}"改为"\begin{equation}\begin{aligned}",所有的字符串"\end{eqnarray}"改为"\end{aligned}\end{equation}",所有的字符串"`$"改为"$",所有的字符串"$`"改为"$"。并输出所有修改的位置
import os def find_string_in_file(file_path, search_string): """查找指定文件中某个字符串出现的位置和次数""" occurrences = [] with open(file_path, 'r', encoding='utf-8') as file: lines = file.readlines() for line_num, line in enumerate(lines, 1): # 查找当前行中字符串出现的位置 index = line.find(search_string) while index != -1: occurrences.append((line_num, index)) # 查找后续出现的位置 index = line.find(search_string, index + 1) return occurrences def find_string_in_directory(directory, search_string): """递归遍历文件夹,查找所有 Markdown 文件中指定字符串出现的位置和次数""" string_occurrences = {} # 遍历文件夹及子文件夹 for root, dirs, files in os.walk(directory): for file in files: if file.endswith('.md'): file_path = os.path.join(root, file) occurrences = find_string_in_file(file_path, search_string) if occurrences: string_occurrences[file_path] = occurrences return string_occurrences def print_string_occurrences(occurrences, search_string): """输出指定字符串出现的位置和次数""" for file_path, positions in occurrences.items(): print(f"\nFile: {file_path}") print(f"'{search_string}' found {len(positions)} time(s):") for line_num, col_num in positions: print(f" Line {line_num}, Column {col_num}") if __name__ == "__main__": directory = input("请输入要搜索的文件夹路径: ") search_string = input("请输入要查找的字符串: ") occurrences = find_string_in_directory(directory, search_string) if occurrences: print_string_occurrences(occurrences, search_string) else: print(f"No occurrences of '{search_string}' found.")
File: C:\Users\chenguanbin\OneDrive - hust.edu.cn\_工作\八股文\DeepLearning-500-questions\ch02_机器学习基础\第二章_机器学习基础.md Line 923, Column 0: '\begin{eqnarray}' -> '\begin{equation}\begin{aligned}' Line 930, Column 0: '\end{eqnarray}' -> '\end{aligned}\end{equation}' Line 948, Column 0: '\begin{eqnarray}' -> '\begin{equation}\begin{aligned}' Line 952, Column 0: '\end{eqnarray}' -> '\end{aligned}\end{equation}' Line 956, Column 0: '\begin{eqnarray}' -> '\begin{equation}\begin{aligned}' Line 961, Column 0: '\end{eqnarray}' -> '\end{aligned}\end{equation}' File: C:\Users\chenguanbin\OneDrive - hust.edu.cn\_工作\八股文\DeepLearning-500-questions\ch03_深度学习基础\第三章_深度学习基础.md Line 612, Column 1: '\begin{eqnarray}' -> '\begin{equation}\begin{aligned}' Line 612, Column 534: '\end{eqnarray}' -> '\end{aligned}\end{equation}' Line 668, Column 1: '\begin{eqnarray}' -> '\begin{equation}\begin{aligned}' Line 668, Column 226: '\end{eqnarray}' -> '\end{aligned}\end{equation}' File: C:\Users\chenguanbin\OneDrive - hust.edu.cn\_工作\八股文\DeepLearning-500-questions\ch06_循环神经网络(RNN)\第六章_循环神经网络(RNN).md Line 17, Column 31: '`$' -> '$' Line 17, Column 33: '$`' -> '$' Line 43, Column 16: '`$' -> '$' Line 43, Column 28: '`$' -> '$' Line 43, Column 40: '`$' -> '$' Line 43, Column 22: '$`' -> '$' Line 43, Column 31: '$`' -> '$' Line 43, Column 43: '$`' -> '$' File: C:\Users\chenguanbin\OneDrive - hust.edu.cn\_工作\八股文\DeepLearning-500-questions\English version\ch03_DeepLearningFoundation\ChapterIII_DeepLearningFoundation.md Line 581, Column 1: '\begin{eqnarray}' -> '\begin{equation}\begin{aligned}' Line 581, Column 540: '\end{eqnarray}' -> '\end{aligned}\end{equation}'
import os def find_string_in_file(file_path, search_string): """查找指定文件中某个字符串出现的位置和次数""" occurrences = [] with open(file_path, 'r', encoding='utf-8') as file: lines = file.readlines() for line_num, line in enumerate(lines, 1): # 查找当前行中字符串出现的位置 index = line.find(search_string) while index != -1: occurrences.append((line_num, index)) # 查找后续出现的位置 index = line.find(search_string, index + 1) return occurrences def find_string_in_directory(directory, search_string): """递归遍历文件夹,查找所有 Markdown 文件中指定字符串出现的位置和次数""" string_occurrences = {} # 遍历文件夹及子文件夹 for root, dirs, files in os.walk(directory): for file in files: if file.endswith('.md'): file_path = os.path.join(root, file) occurrences = find_string_in_file(file_path, search_string) if occurrences: string_occurrences[file_path] = occurrences return string_occurrences def print_string_occurrences(occurrences, search_string): """输出指定字符串出现的位置和次数""" for file_path, positions in occurrences.items(): print(f"\nFile: {file_path}") print(f"'{search_string}' found {len(positions)} time(s):") for line_num, col_num in positions: print(f" Line {line_num}, Column {col_num}") if __name__ == "__main__": directory = input("请输入要搜索的文件夹路径: ") search_string = input("请输入要查找的字符串: ") occurrences = find_string_in_directory(directory, search_string) if occurrences: print_string_occurrences(occurrences, search_string) else: print(f"No occurrences of '{search_string}' found.")



而且无法用指令去处理,但是其实批处理一个文件夹内的所有文件,已经挺可以了。
还有少数是多个软件也无法解决的:
html转pdf
1. wkhtmltopdf:公式有些没识别到,还有公式格式有点难看。
有些图片也没识别到


2. foxit:可以批处理,选择一个文件夹。
遇到图片消失的
html
foxit pdf

还有表格有点丑

markdown-pdf项目
alanshaw/markdown-pdf: Markdown to PDF converter
选择node版本11.10(选择高版本可能会报错):
npm install markdown-pdf --save
它可以进行批处理
alanshaw/markdown-pdf: Markdown to PDF converter
这是官方提供的,From multiple paths to multiple paths:
var markdownpdf = require("markdown-pdf")
var mdDocs = ["home.md", "about.md", "contact.md"]
, pdfDocs = mdDocs.map(function (d) { return "out/" + d.replace(".md", ".pdf") })
markdownpdf().from(mdDocs).to(pdfDocs, function () {
pdfDocs.forEach(function (d) { console.log("Created", d) })
})
node xxx.js
但是公式没识别出来

emmm,也有人提出需求:Is there a way to use MathJax? · Issue #155 · alanshaw/markdown-pdf
pandoc
1. pandoc –pdf-engine=xelatex
有可能遇到问题
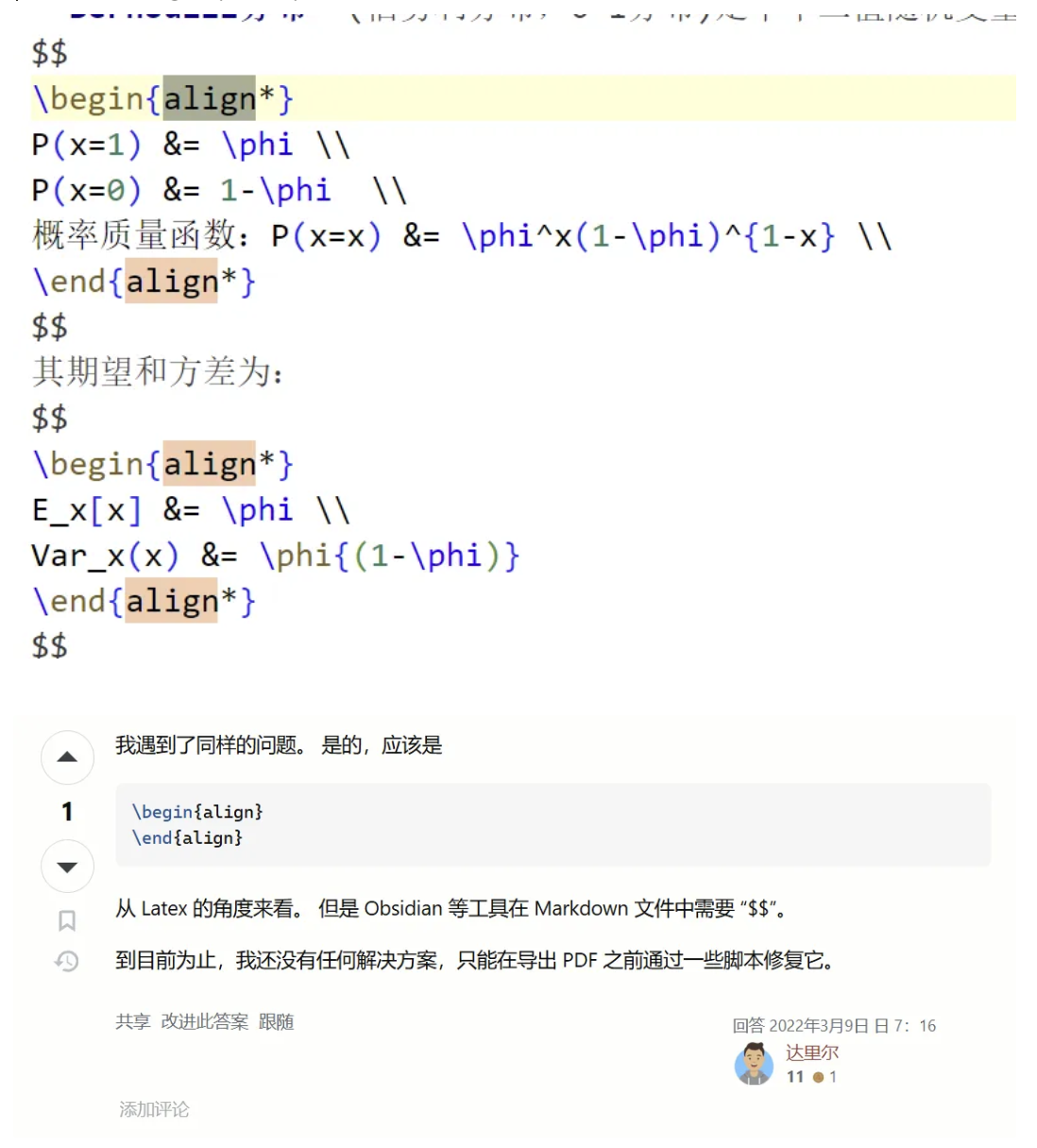
! Package amsmath Error: Erroneous nesting of equation structures; (amsmath) trying to recover with `aligned'. See the amsmath package documentation for explanation. Type H <return> for immediate help. ... l.584 \end{align*}
解决方案是把前后的”$$”删除
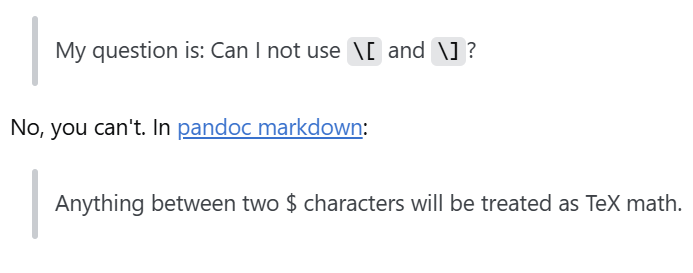
还有比如Missing $ inserted的问题
Error producing PDF. ! Missing $ inserted. <inserted text> $ l.290 鏄湡瀹炲€硷紝\$ \frac{\partial y_l}{\partial z_l}
markdown – Pandoc Error: ! missing $ inserted – Stack Overflow
2. pandoc –pdf-engine=typst
它有时也会有格式的问题

遇到问题,无法粗体和斜体
使用
–ascii
–highlight
-V CJKmainfont:SourceHanSerifCN-Regular -V CJKoptions:BoldFont=SourceHanSansCN-Medium,ItalicFont=STKaiti
都不行
潜在解决方法:官方文档(后续我没处理了,有点麻烦)
用 pandoc 让 Markdown 从 LaTeX 输出 pdf 文档 – 黄石的时空回环
中文没有加粗 | Typst 中文社区导航

其它方法和软件
1. prince软件(Markdown Preview Enhanced里面有使用)
效果不佳,无法识别公式
2.
- pandoc + Typst
- pandoc + latex
- rst2pdf
- rinohtype
- weasyprint
- mdpdf
效果均不太理想。比如公式,比如markdown一些格式无法识别









没有回复内容