

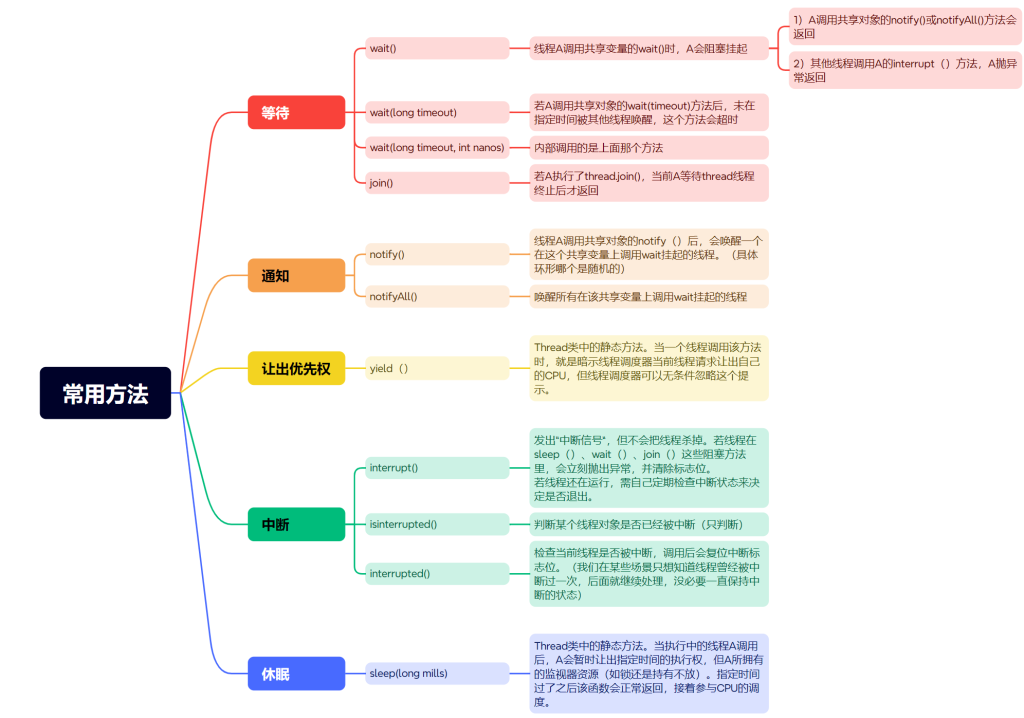
一、简介
1.1Playwright 是什么?
它是微软在 2020 年初开源的新一代自动化测试工具,其功能和 selenium 类似,都可以驱动浏览器进行各种自动化操作。
1.2、特点是什么
- 支持当前所有的主流浏览器,包括 chrome、edge、firefox、safari;
- 支持跨平台多语言:支持Windows、Linux、macOS;
- 安装和配置过程简单,会自动安装对应的浏览器和驱动,不需要额外配置 WebDriver 等
- 更强大的自动化测试配置,支持浏览器有头和无头模式,速度更快、执行更可靠;
- 支持拦截、修改网络请求,支持文件的上传和下载操作,可以捕获页面截图或生成PDF,支持视频录制功能
- 强大的工具库:Codegen、Playwright inspector、Trace Viewer。
Codegen:能够记录用户的操作,并将其转化为测试用例,且可以保存为任何语言的测试代码。
Playwright Inspector:可用于检查页面状态,生成精准的选择器,能够逐步执行测试,清晰地查看点击位置,还能探索详细的执行日志。
Trace Viewer:能够捕获所有关键信息,以便在测试失败时进行深入调查。Playwright 的跟踪功能十分强大,包含测试执行过程中的截屏、实时的 DOM 快照、动作资源管理器以及测试的源代码等内容
1.3、Playwright vs seleium对比
| 序号 | 比较项目 | Playwright | Selenium | 评分 | 谁胜出 |
|---|---|---|---|---|---|
| 1 | 安装难易度 | 安装较为简便,依赖少 | 安装过程相对复杂,依赖较多 | 8:06 | Playwright |
| 2 | 编程语言支持 | 支持多种主流语言 | 支持多种主流语言 | 8:08 | 平手 |
| 3 | 浏览器兼容性 | 对主流浏览器兼容性好 | 对主流浏览器兼容性好 | 8:08 | 平手 |
| 4 | 跨平台性 | 良好的跨平台支持 | 跨平台性较好 | 8:07 | Playwright |
| 5 | 文档质量 | 文档清晰详细 | 文档较为全面 | 8:07 | Playwright |
| 6 | API 设计 | 简洁直观 | 相对复杂一些 | 8:07 | Playwright |
| 7 | 性能 | 性能较高 | 性能一般 | 8:07 | Playwright |
| 8 | 异步支持 | 优秀的异步处理 | 异步处理稍显复杂 | 8:07 | Playwright |
| 9 | 等待机制 | 灵活多样 | 有多种等待方式,但稍显复杂 | 8:07 | Playwright |
| 10 | 元素定位 | 方便准确 | 较为准确 | 8:07 | Playwright |
| 11 | 稳定性 | 稳定性较好 | 稳定性一般 | 8:07 | Playwright |
| 12 | 错误处理 | 清晰明确 | 相对复杂 | 8:07 | Playwright |
| 13 | 并发执行 | 支持高效并发 | 并发执行稍弱 | 8:07 | Playwright |
| 14 | 移动端测试 | 支持较好 | 支持一般 | 8:07 | Playwright |
| 15 | 无头模式支持 | 支持良好 | 支持良好 | 8:08 | 平手 |
| 16 | 录制功能 | 有录制功能 | 录制功能相对较弱 | 8:07 | Playwright |
| 17 | 社区活跃度 | 社区逐渐活跃 | 社区非常活跃 | 7:08 | Selenium |
| 18 | 插件丰富度 | 插件相对较少 | 插件丰富 | 7:08 | Selenium |
| 19 | 更新频率 | 更新较快 | 更新频率一般 | 8:07 | Playwright |
| 20 | 学习曲线 | 相对较平缓 | 学习曲线稍陡 | 8:07 | Playwright |
| 21 | 对新特性支持 | 快速支持新特性 | 支持新特性稍慢 | 8:07 | Playwright |
| 22 | 代码可读性 | 代码简洁,可读性高 | 代码相对复杂,可读性一般 | 8:07 | Playwright |
| 23 | 与 CI/CD 集成 | 集成方便 | 集成相对复杂 | 8:07 | Playwright |
| 24 | 支持的浏览器版本范围 | 较广 | 一般 | 8:07 | Playwright |
| 25 | 对 WebRTC 的支持 | 支持较好 | 支持一般 | 8:07 | Playwright |
| 26 | 对 HTML5 特性支持 | 支持良好 | 支持一般 | 8:07 | Playwright |
| 27 | 对 CSS3 特性支持 | 支持良好 | 支持一般 | 8:07 | Playwright |
| 28 | 对 JavaScript 框架支持 | 支持良好 | 支持一般 | 8:07 | Playwright |
| 29 | 对前端框架的兼容性 | 兼容性好 | 兼容性一般 | 8:07 | Playwright |
| 30 | 支持的操作系统 | 多操作系统支持 | 多操作系统支持 | 8:08 | 平手 |
| 31 | 内存占用 | 相对较低 | 较高 | 8:07 | Playwright |
| 32 | 执行速度 | 速度较快 | 速度一般 | 8:07 | Playwright |
| 33 | 对动态页面处理 | 处理能力强 | 处理能力一般 | 8:07 | Playwright |
| 34 | 对 AJAX 请求的处理 | 处理优秀 | 处理一般 | 8:07 | Playwright |
| 35 | 对 iframe 的处理 | 处理方便 | 处理稍复杂 | 8:07 | Playwright |
| 36 | 对表单提交的处理 | 处理准确 | 处理一般 | 8:07 | Playwright |
| 37 | 对弹窗的处理 | 处理灵活 | 处理稍复杂 | 8:07 | Playwright |
| 38 | 对鼠标和键盘事件模拟 | 模拟自然 | 模拟稍复杂 | 8:07 | Playwright |
| 39 | 对文件上传下载的支持 | 支持良好 | 支持一般 | 8:07 | Playwright |
| 40 | 对网络请求拦截的支持 | 支持较好 | 支持一般 | 8:07 | Playwright |
二、安装Playwright
2.1在Python中安装Playwright相对简单,可以通过pip安装:
pip install playwright
2.2安装完成后,还需要安装浏览器的自动化驱动程序:
playwright install
这将自动下载并安装所需的浏览器驱动程序。
三、使用方法
3.1初始化浏览器
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False) # headless=False 表示非无头模式
3.2创建一个页面并导航到特定的URL:
page = browser.new_page()
page.goto(‘https://example.com’)
3.3交互操作
在页面上执行填写表单点击登录操作实例:
page.fill(‘input[name=”username”]’, ‘your_username’) # 填写用户名
page.fill(“xpath=//input[@id=’password’]”,”your_password”) # 填写密码
btn = page.query_selector(“button#login_btn”)# 找到登录按钮元素
btn.click() # 点击按钮
等同于:page.click(‘button#login_btn’)
等同于:page.click(“text=登录”) ##根据文本获取元素,并点击
3.4常用功能总结
Playwright 提供了丰富的 API 来操作页面元素和与页面交互。以下是一些常用功能:
-
页面导航与跳转
page.goto(url, **kwargs): 导航到指定的 URL。
page.reload(): 重新加载当前页面。
page.wait_for_load_state(state): 等待页面达到指定的加载状态(如 ‘networkidle’、‘domcontentloaded’ 等)。 -
页面元素查询与操作
page.query_selector(selector): 使用 CSS 选择器查询页面元素。
page.query_selector_all(selector): 使用 CSS 选择器查询所有匹配的页面元素。
element.click(): 模拟点击元素。
element.fill(values): 填充表单元素的值。
element.input(value): 为元素输入文本。
element.press(key, **kwargs): 模拟按键操作。
element.hover(): 将鼠标悬停在元素上。 -
页面内容获取
page.title(): 获取当前页面的标题。
page.content(): 获取当前页面的outerrHTML内容。
page.evaluate(expression, **kwargs): 在页面上下文中执行 JavaScript 表达式并返回结果。 -
截图与录屏
page.screenshot(path=None, **kwargs): 截取当前页面的截图。
browser.start_recording(options): 开始录制浏览器操作,生成视频文件。
browser.stop_recording(): 停止录制浏览器操作。 -
监听浏览器事件
page.on(event, callback): 监听指定类型的事件,并在事件发生时调用回调函数。
page.off(event, callback): 取消监听指定类型的事件。 -
网络请求拦截与处理
page.route(url, route_handler): 拦截匹配指定 URL 的网络请求,并可以自定义处理逻辑。
route_handler.abort(): 中止拦截到的网络请求。
route_handler.continue_(): 继续拦截到的网络请求。
route_handler.fulfill(response): 使用自定义的响应内容满足拦截到的网络请求。 -
浏览器上下文管理
browser.new_context(options): 创建一个新的浏览器上下文。
context.close(): 关闭浏览器上下文,释放资源。 -
选择器
Playwright 使用选择器来定位页面元素。选择器可以是 CSS 选择器、XPath 或其他类型。例如,page.query_selector 方法接受一个选择器作为参数,并返回匹配的第一个元素。 -
等待策略
Playwright 提供了多种等待策略,如 wait_for_load_state, wait_for_navigation, wait_for_timeout, 和 wait_for_selector 等,以确保在继续执行操作之前页面已加载完成或元素已出现。 -
调试与日志
browser.new_page(headless=False): 在非无头模式下打开浏览器,方便进行调试。
console.log(message): 在控制台输出日志信息。
11.执行js
page.evaluate(‘原生态js’)
12.获取某个元素内容innerText:page.text_content(selector)
比如要获取上面截图中的【欢迎登录】四个字:
欢迎登录
page.text_content(‘xpath=//h1[@class=”form-title”]’)
13.获取属性值:page.get_attribute(selector,attr)
比如要获取截图中左边的大图:

page.get_attribute(“xpath=//img[@alt=’网站展示图片’]”,’src’)
14.获取元素节点
获取单个:page.query_selector(“//a”)
获取多个节点:page.query_selector_all(“//a”)
监听页面导航
page.on(“request”, lambda request: print(f”Request: {request.url}”))
监听控制台消息
page.on(“console”, lambda message: print(f”Console: {message.text()}”))
监听页面加载完成
page.on(“load”, lambda: print(“Page loaded”))
四、常用示例
4.1.截图及录制视频示例:
截图并保存:page.screenshot(path=”screenshot.png”)
生成PDF:page.pdf(path=’document.pdf’)
录制浏览器会话示例:
video_dir = ‘.’
browser = p.chromium.launch(headless=False, record_video_dir=video_dir)
4.2.关闭弹出对话框示例:
page.on(‘dialog’, async (dialog) => {
console.log(弹出消息框内容:${dialog.message()});
await dialog.dismiss(); // 关闭消息框
});
通过监听page.on(‘dialog’)事件,并使用dialog.dismiss()方法来关闭消息框。这样可以在自动化测试或爬虫过程中处理弹出消息框的情况。
4.3.拦截和修改网络请求示例:
def handle_request(route, request):
if request.url.contains(‘example.com’):
route.continue_()
else:
route.abort()
page.route(‘**’, handle_request)
4.4异步操作示例:
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as p:
browser = await p.chromium.launch()
page = await browser.new_page()
await page.goto(“https://www.example.com”)
# 在这里可以执行其他异步操作
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
4.5.某滑块站点的登录操作示例:
with sync_playwright() as p:
browser = p.firefox.launch(headless=True) # 关闭无头
context = browser.new_context(
user_agent=’Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36′,
viewport={‘width’: 1920, ‘height’: 1080}
) # 指定user_agent和viewport创建新窗口
page = context.new_page() # 新建标签页
page.goto(self.login_url) # 跳转到指定链接
page.wait_for_timeout(1000) # 等待1秒
# 填充数据
page.fill(‘css=[id=”username”]’, username)
page.fill(‘css=[id=”password”]’, password)
page.wait_for_timeout(1000) # 等待1秒
# 点击登录
page.click(‘div.mb-login-btn’) # 点击
print(‘username: {}, password: {}, msg: 点击登录’.format(username, password))
page.wait_for_timeout(2000) # 等待2秒
# 处理滑块
slide_success = False
for i in range(3):
print('username: {}, password: {}, msg: 滑块识别第{}次尝试'.format(username, password, i))
try:
bg = re.search(r'base64,(.*?)"\)', page.get_attribute('.imgBg', 'style')).group(1).strip().replace('"', '') # get_attribute能够根据选择器锁定的标签拿到想要的属性
bth = page.get_attribute('.imgBtn > img', 'src').split('base64,', 1)[1].strip()
slide_x_value = self.identify_gap(base64.b64decode(bg), base64.b64decode(bth))
except Exception as e:
continue
# 根据x长度移动轨迹 获取拖动按钮位置并拖动
slider_btn = page.locator("span.v_rightBtn.btn1") # 定位标签
box = slider_btn.bounding_box() # 获取标签大小属性
page.mouse.move(box['x'] + box['width'] / 2, box['y'] + box['height'] / 2) # 移动鼠标
page.mouse.down() # 按下鼠标
mov_x = box['x'] + box['width'] / 2 + slide_x_value
page.mouse.move(mov_x, box['y'] + box['height'] / 2) # 鼠标按下后滑动距离
page.mouse.up() # 松开鼠标
page.wait_for_timeout(1000)
# 点击账号登录
page.click('.xQuery-master-button')
page.wait_for_timeout(3000)
# 保存storage state 到指定的文件
# storage = context.storage_state(path="auth/state.json")
# print(storage)
if '用户中心' not in page.content(): # page.content()获取标签页全部文本
return False, []
# print({cookie['name']: cookie['value'] for cookie in page.context.cookies()})
cookies_dict = page.context.cookies() # 获取标签页cookie
# 导出登录信息
# storage = context.storage_state(path=r"C:\Users\Admin\Desktop\auth.json")
# 加载登录信息
# context = browser.new_context(storage_state=r"C:\Users\Admin\Desktop\auth.json")
# print(storage)
browser.close() # 关闭浏览器
return True, cookies_dict
参考文档:
https://www.cnblogs.com/ranbox/p/18461048
https://blog.csdn.net/shadowtalon/article/details/139311778
https://blog.csdn.net/cat12340/article/details/143685240
官方文档:
https://github.com/microsoft/playwright
https://playwright.dev/python/docs/intro
https://playwright.dev/python/docs/api/class-playwright
来源链接:https://www.cnblogs.com/pddeditor/p/18673566





没有回复内容