
0 摘要
Top-Down模型由硬件架构师定义,用于提供不同硬件组件的利用率信息。其目标是将用户与复杂的硬件架构隔离开来,同时让他们深入了解代码是如何有效利用资源的。在本文中,我们探讨了为支持最先进高性能计算集群的不同硬件架构(英特尔Skylake、富士通A64FX、IBM Power9和华为鲲鹏920)定义的四种Top-Down模型的适用性,并为AMD Zen 2提出了一个模型。我们研究了用于科学生产的并行 CFD 代码,以比较这五个自顶向下模型。我们对每个模型的洞察力、信息的清晰度、易用性和可得出的结论进行了评估。我们的研究表明,Top-Down模型使性能分析人员很难在不深入研究微体系结构细节的情况下发现复杂科学代码中的低效之处。
1 引言及相关工作
CPU 架构的多样性是 HPC 行业的新现实。在 2022 年 11 月的 Top500 榜单中,前五名包括三种不同的 CPU 架构:x86、Arm 和 IBM POWER。为了增加全景图的多样性,每种 CPU 架构都有不同的供应商实现(例如,x86 由英特尔和 AMD 实现,Arm 由富士通、Nvidia 和华为实现)。在这种多样性的情况下,建立跨平台方法来评估这些硬件系统的有效使用变得越来越困难。这种复杂性可能不是由 HPL 或 HPCG 等基准测试引起的,而是由生产科学应用引起的。
多种性能分析模型试图:(i) 测量性能;(ii) 识别性能瓶颈。此外,有些模型还能提示如何规避上述瓶颈。
例如,Roofline 模型[Roofline: an insightful visual performance model for multicore architectures,IEEE:Applying the roofline model] 将性能与算术强度(或运行强度)联系起来。该模型能反馈特定代码是计算受限还是内存受限,还能告知执行距离理论峰值还有多远。根据分析级别的不同,该模型可以定义不同的顶点(例如,考虑缓存级别和主内存)[IEEE: Cache-aware Roofline model: Upgrading the loft]。代码的运算强度既可以(i)从理论上定义,即计算算法所需的逻辑运算次数,也可以(ii)从经验上定义,即测量执行过程中的运算次数。第二种方法会产生不同的结果,因为它包含了编译器在算法执行过程中可能引入的修改[Benchmarking of state-of-the-art HPC Clusters with a Production CFD Code]。对于远离理论峰值的代码,Roofline 模型的主要局限在于无法说明性能损失在哪里。对于内存绑定的代码,性能最终会受到内存子系统的限制。但是,这并不意味着当前的实现或执行也存在相同的瓶颈。
问题是,执行周期在哪里流失?自顶向下模型试图回答这个问题。
1.1. Top-Down模型
通过对执行周期进行计数和分类,自上而下模型指出了应用程序当前的限制因素。英特尔公司最初描述了这一模型[A Top-Down method for performance analysis and counters architecture],后来将其确立为英特尔TMAM方法。该模型的结构是一棵度量树,根据所花费的资源(如计算资源、内存资源、因停滞而损失的资源等)对周期进行组织。对于英特尔 CPU 来说,每个层次结构都有一个官方定义。层次结构越深,微体系结构的特定性就越强。这可能会导致难以比较不同 CPU 之间的结果。
与英特尔 CPU 相比,AMD 没有官方定义的自顶向下模型。过去曾有人试图将英特尔的模型映射到 AMD 15h、Opteron 和 R 系列处理器上。由于微体系结构和可用硬件计数器的不同,这项工作凸显了映射的局限性。其他架构也有树状层次结构,但未标注为 “自上而下”。每个供应商都有自己的定义,可能与 TMAM 的定义不一致。
读者应注意,“自顶向下 ”模型始终以周期为单位进行定义。这意味着 CPU(和内存)时钟频率未被考虑在内。
我们利用以前使用名为 Alya的生产 CFD 代码的经验,探索自顶向下模型所能提供的洞察力。我们在英特尔原始模型的基础上,为 AMD Zen 2 CPU 定义了一个自顶向下模型,并实施了一个工作流程,以测量和计算所研究的每个系统的指标。我们还分析了模型在不同 CPU 架构中的适用性,以及模型层次结构是否具有可比性。
1.2. 贡献
- 在 AMD Zen 中定义自顶向下模型 2.
- 在英特尔 Skylake、AMD Zen 2、A64FX、Power9 和鲲鹏 920 CPU 中实现自顶向下模型。
- 应用自顶向下模型,研究不同 CPU 架构下生产型 HPC 代码中的代码修改效果。
- 在不同 CPU 架构的系统中比较自顶向下模型。
我们在五个不同的集群上使用了三种不同的架构:x86、aarch64 和 ppc64le。其中一个集群(基于英特尔 Skylake CPU 的集群)已经定义了自顶向下模型。对于其中两个集群,由于没有模型,因此我们必须定义自顶向下模型;(i) 对于 AMD Zen 2,我们基于上一代 CPU ;(ii) 对于 Kunpeng 920,我们利用了 CPU 制造商提供的模型(据我们所知到目前为止尚未公开)。对于集群 A64FX 和 Power9,有一些与自顶向下模型类似的模型定义,我们必须对其进行调整才能与之相比较。
2 高性能计算系统及其自顶向下模型
在本节中,我们将介绍所研究的硬件。我们将解释如何构建每台机器的自顶向下模型,以及如何解释最相关的指标。我们将 TMAM 的自顶向下模型作为与其他机器进行比较的基准。有关如何计算各项指标的详细列表,请参阅附录A。
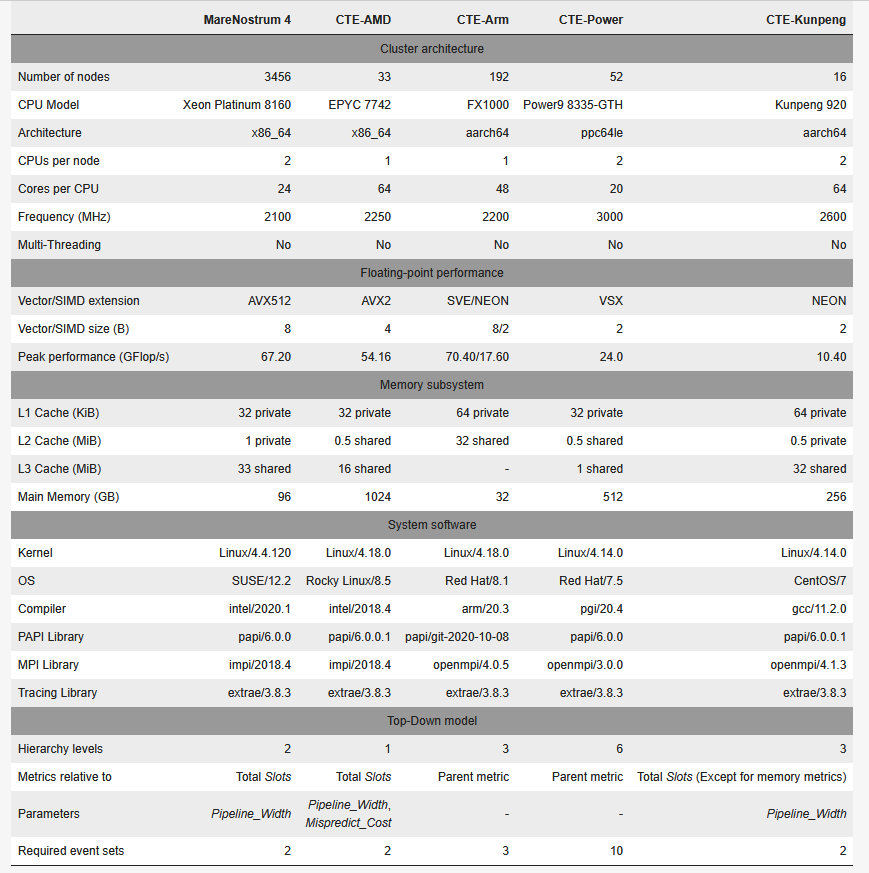
下表总结了所研究的所有高性能计算系统的集群配置。其中包括一些相关的硬件特性以及系统软件栈。我们还显示了每台机器上自顶向下模型的总体摘要。
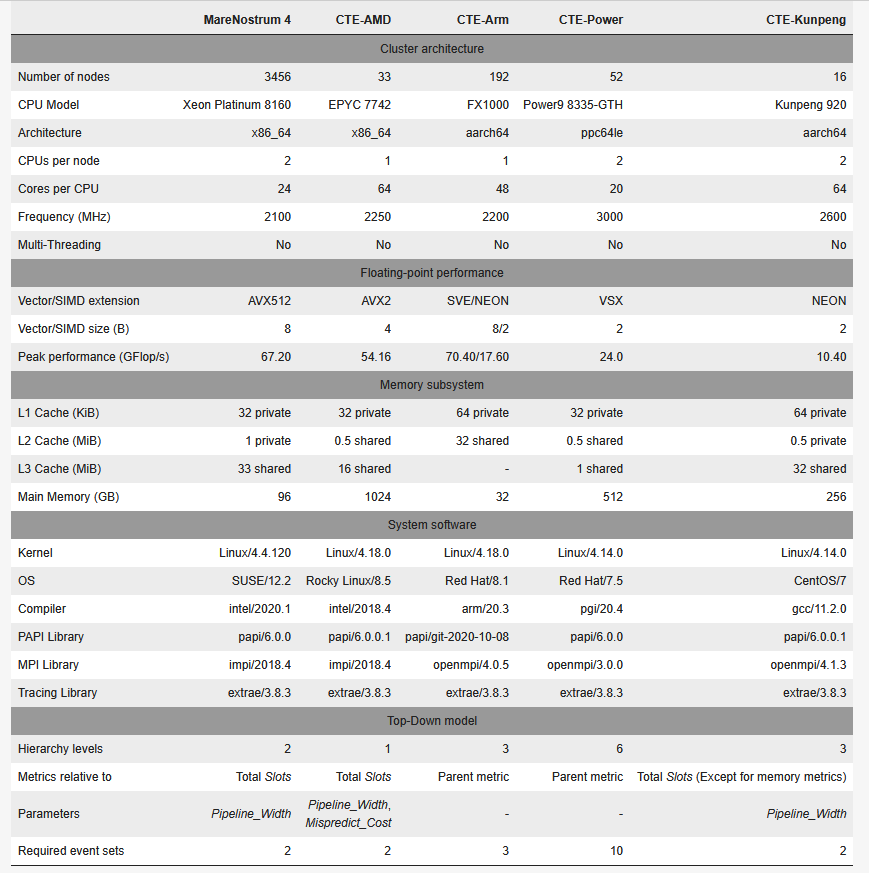
2.1 MareNostrum 4 通用型
MareNostrum 4 是巴塞罗那超级计算中心(BSC)的旗舰级 Tier-0 超级计算机。通用分区(以下简称 MareNostrum 4)有 3456 个节点,内含两个英特尔Xeon Platinum8160 CPU。该分区在 2019 年 6 月的 Top500 中排名第 29 位。
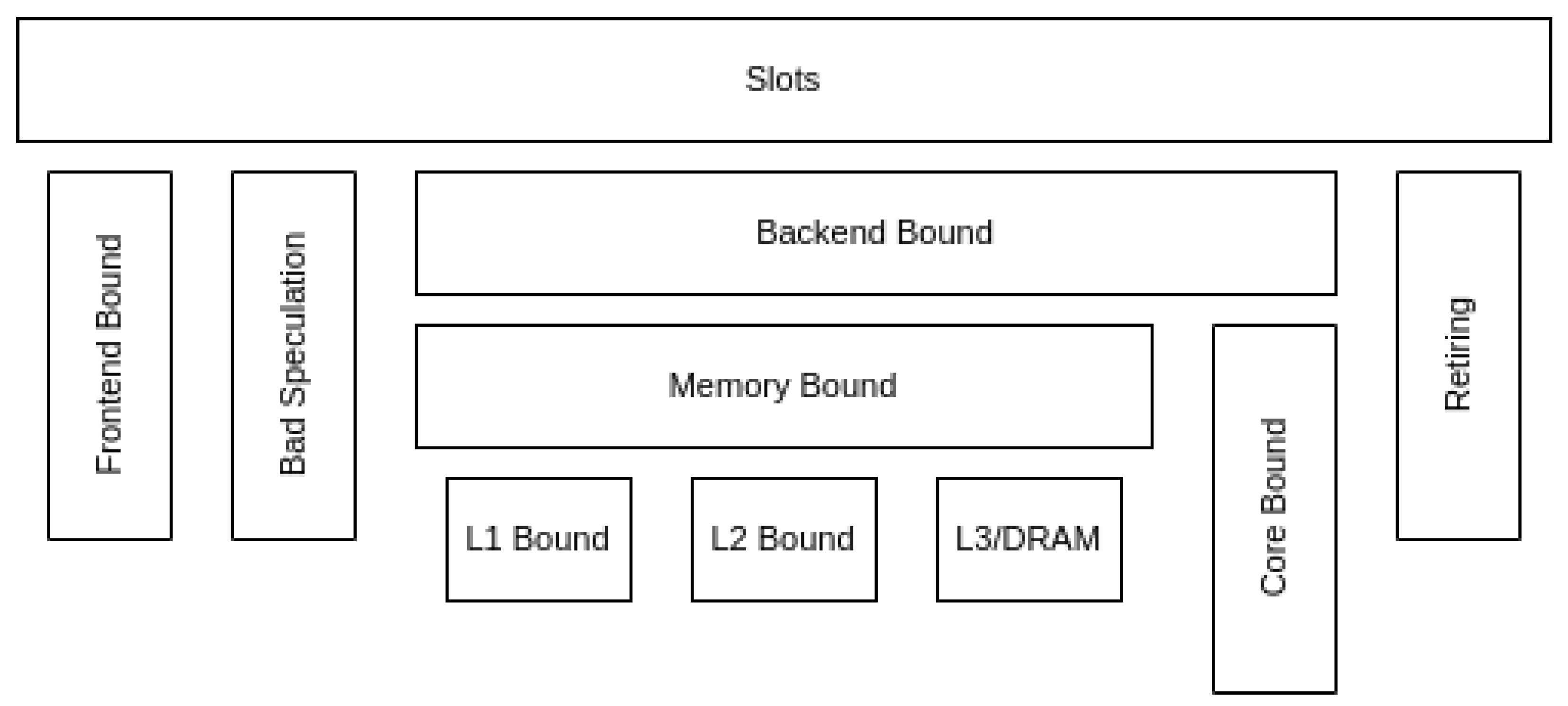
MareNostrum 4 中的自顶向下模型是按照英特尔的 TMAM 定义构建的。下图显示了模型的示意图。这一版本的模型重点关注处理器流水线前端和后端边界的Slot 占用情况。一个Slot 可以被来自前端的一个微操作(𝜇Op)消耗,或因后端相应资源繁忙而丢失。就 Skylake CPU 而言,每个周期有 4 个可用Slot (每个周期最多可分配 4 个𝜇Ops)。

- 前端绑定(Frontend Bound):由于没有足够的 𝜇OPs 而丢失。
- 错误推测(Bad Speculatio):slot 被使用,但执行的投机指令后来被清除。
- 后端绑定(Back-end Bound):插槽丢失的原因是后端资源被较早的𝜇OP占用.
- 退休(Retiring):slot 用于最终退休的指令。该指标中的高意味着流水线没有因停滞而丢失时隙。这并不意味着硬件资源得到了有效利用。它只意味着工作正在流入流水线。
每个类别又分为更详细的指标。例如,“后端绑定 ”类别分为 “内存绑定 ”和 “内核绑定”。在这一版本的 “自顶向下 ”模型中,子指标与其父指标的值相加。所有值都代表执行总slot 的部分。第一层中所有指标的总和为1。利用 MareNostrum 4 中的硬件计数器,我们可以为 Skylake CPU 构建两级自顶向下模型。这两级模型具有足够的通用性,可与其他 CPU 进行比较,即使它们基于不同的架构。
2.2 CTE-AMD
CTE-AMD 是部署在 BSC 的 CTE 集群的一部分。它有 33 个节点,由 AMD Rome 处理器组成,类似于 2021 年安装在橡树岭国家实验室、2022 年 6 月在 Top500 中排名第一的 Frontier 超级计算机的 CPU。我们的工作将之前定义的 R 系列处理器映射扩展到了 CTE-AMD 托管的 EPYC 7742 CPU。由于系统软件(即硬件计数器和 PAPI 库)的限制,我们只能映射第一级指标。

CTE-AMD 的自顶向下模型与英特尔的模型共享第一层指标。不过,尽管名称相同,英特尔和 AMD 的指标还是存在一些差异,主要包括
- 前端绑定基于计数器 UOPS_QUEUE_EMPTY,不考虑后端是否停滞。
- Bad Speculation 需要一个微体系结构参数 Mispredict_Cost,它表示因错误预测而损失的平均周期。根据公开的实验数据,我们将该常数定义为 18。
与 MareNostrum 4 一样,每个级别的指标介于 0 和 1 之间,代表总执行的部分slot。
2.3 CTE-Arm
CTE-Arm 是 CTE 系统的另一个集群。它采用富士通公司开发的 A64FX 芯片,基于 Arm-v8 指令集。该集群的架构与 2020 年 6 月在 Top500 中排名第一的 Fugaku 超级计算机的架构相同。
CTE-Arm 中的自顶向下模型是根据富士通发布的官方微体系结构手册构建的。手册中使用的术语是周期核算,而不是自顶向下模型。该模型以硬件计数器树的形式呈现,而非指标。它不需要任何微架构参数。
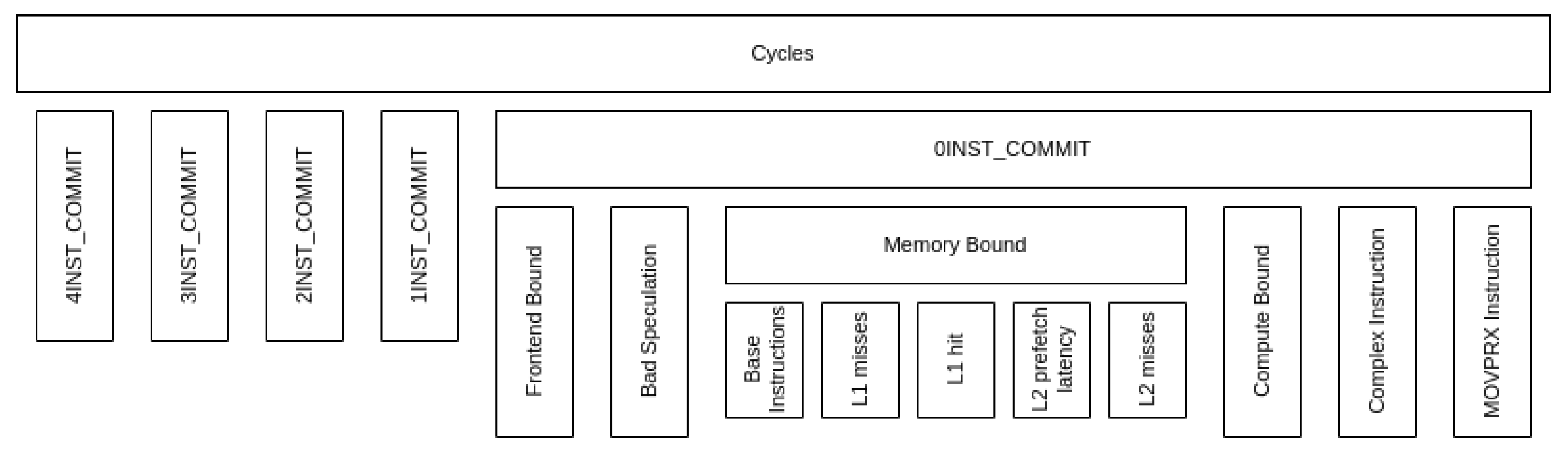
层次结构最深可达五层。层次结构中的几乎所有节点都与硬件计数器相对应,每个节点都是其所有子节点的总和。这意味着层次结构中的计数器之间存在一些冗余,但也意味着研究第一和第二层次时无需构建整个层次结构。一些标记为 “其他 ”的指标对应于父节点与所有子节点的集合之间的差异。
与 MareNostrum 4 和 CTE-AMD 中的自顶向下模型不同,CTE-Arm 的指标侧重于指令提交阶段(而非前端和后端之间的边界)损失的周期。层次结构的第一层根据提交指令的数量对周期进行分类。最好的情况是提交了四条指令,而最差的情况是没有提交任何指令。由于在一个循环中提交零条指令的情况最为关键,因此自顶向下模型层次结构重点关注这一路径。
与 MareNostrum 4 和 CTE-AMD 不同,CTE-Arm 中的指标是相对于父指标而言的。这意味着度量指标代表的是父度量指标的部分周期,而不是全部执行周期。
2.4 CTE-Power
CTE-Power 是 CTE 集群的一部分,跨越 52 个节点,内含两个 IBM Power9 8335-GTH CPU。Summit 和 Sierra 是与 CTE-Power 基于相同 CPU 的两台超级计算机,在 2018 年 6 月的 Top500 中排名第一和第三。
CTE-Power 中的自顶向下模型是根据 IBM 官方发布的 PMU 用户指南构建的。它不需要任何微架构参数。手册包括模型层次结构前两级的树形图。较低层次仅使用各自的硬件计数器进行引用。
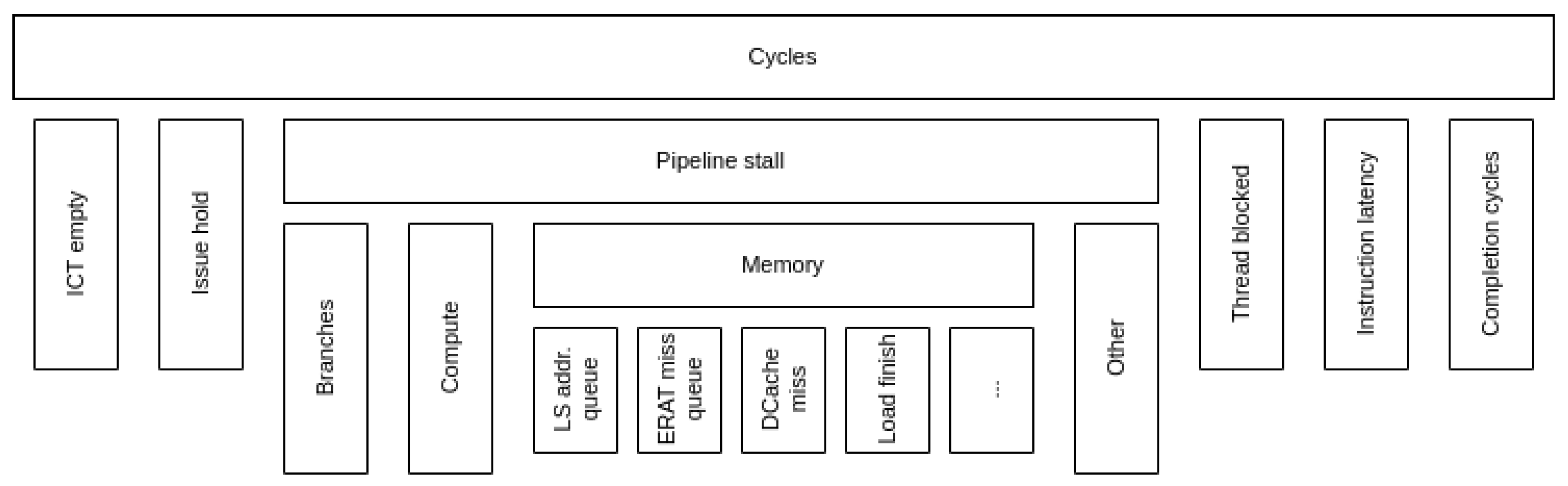
- CT 为空,无指令完成(流水线为空)。类似于其他模型中的前端绑定。
- Issue hold 下一条要完成的指令(即流水线中最旧的)被保留在 issue 阶段。
- 流水线停滞,类似于以前模型中的 Back-end Bound 类别。
- 线程阻塞 由于另一个硬件线程的指令占用了流水线,下一条完成指令被阻塞。
- 指令延迟 由于流水线延迟,需要等待指令完成的周期。
- 完成周期 至少完成一条指令的周期。类似于以前型号中的 “退休”类别。
层次结构最多可分为六层。从第二层开始,层次结构中的某些节点并不代表机器中可用的实际硬件计数器,而是其下计数器的集合。这意味着,如果研究需要超出层次结构的第一层,CTE-Power 中的自顶向下模型就需要构建整棵树。在这项工作中,我们只研究第三层以下的指标,并遵循内存路径,因为它与所研究的应用最相关。与 CTE-Arm 一样,CTE-Power 中的指标总是代表父周期的一部分,而不是整个执行过程。
从官方文档来看,尚不清楚该模型的类别是否相互脱节。此外,指令延迟类别(手册中标注为 “完成到完成”)在列出模型顶层时被提及一次,但在后面却没有再提及。如果没有更多细节,就无法深入了解指令延迟是否是所研究应用的主要限制因素。
在 MareNostrum 4 中,“退役”(Retiring)类别分支为其他考虑到流水线延迟的指标(由于受可用计数器的限制,我们没有将这一分支纳入我们的工作中)。可以说,与 MareNostrum 4 中的模型类似,CTE-Power 中的指令延迟也可以包含在完成周期中。
2.5. CTE-Kunpeng
CTE-Kunpeng 是一个由基于 Arm 的 Kunpeng 920 CPU 驱动的集群,它于 2021 年部署在 BSC,是 BSC 与华为合作的成果。CTE-Kunpeng 中的模型旨在模仿与 MareNostrum 4 相同的结构和命名规则。硬件计数器的名称与 Skylake CPU 的计数器不同,目前尚不清楚它们是否完全涵盖相同的情况。不过,指标的表述仿效了英特尔的原始定义。CTE-Kunpeng 中的模型定义了三个层次。
层次结构的第一层包括代表总周期一部分的指标。另一方面,第二层和第三层的内存绑定分支定义了与内核停滞等待内存的周期相关的指标。CTE-Kunpeng 是我们在本文中涉及的唯一一种情况,在这种情况下,指标是相对于不同层次的不同数量而言的。这增加了比较不同模型指标的难度。
3 高性能计算应用: Alya
Alya 是巴塞罗那超级计算中心开发的计算流体力学代码,也是 PRACE 统一欧洲应用基准套件的一部分。该应用程序使用 Fortran 语言编写,并使用 MPI 编程模型进行并行化。在这项工作中,我们运行了以前研究过的 Alya 版本和输入。这个版本实现了一个编译时参数 VECTOR_SIZE,它改变了网格元素的打包方式,从而向编译器暴露了更多的数据并行性。我们之前的研究探讨了在增加 VECTOR_SIZE 的同时,执行时间、执行指令和 IPC 是如何演变的。我们测得执行时间曲线呈 U 型,VECTOR_SIZE 32 是最佳配置。我们的研究仅限于 MareNostrum 4,并比较了不同的编译器。在这项工作中,我们利用以前对 Alya 的了解,在多个集群中运行,并为每个集群构建自顶向下模型。
- 总体结构
我们的用例是模拟化学燃烧。因此,它包括计算化学反应、反应温度和流体速度。
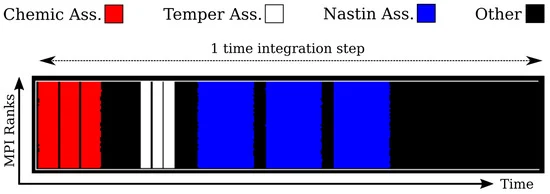
对于我们的特定输入,Alya 的执行分为五个集成步骤(或时间步)。每个步骤又分为若干阶段。下图显示了 MareNostrum 4 中一个时间步的时间轴。x 轴代表时间,y 轴代表 MPI 进程。时间轴以彩色编码显示不同的执行阶段。在这项工作中,我们探讨的是纳斯廷矩阵组装阶段,该阶段代表一个时间步中最长的时间(时间轴的蓝色区域),对应于不可压缩流体。
4 模型实现
在本节中,我们将 (i) 列出用于测量各集群硬件计数器的工具;(ii) 解释根据模型定义将所有工具串联起来计算自顶向下模型指标的方法。除 Daltabaix 外,所有工具均可公开获取,Daltabaix 是专门为这项工作开发的。如作者要求,可提供访问权限。
4.1. 工具
PAPI(性能应用编程接口 Performance Application Programming Interface)是一个利用 perf 的可移植性并具有简易编程接口的库。它还定义了一个通用计数器列表,称为预设值,大多数 CPU 都能使用。不过,即使名称相同,PAPI 计数器在不同系统中读取时测量的事件可能并不相同。例如,PAPI_VEC_INS 可以读取 CPU 上所有已发出的矢量指令,而在另一个系统上只能测量已发出的算术矢量指令。
Extrae是一种跟踪工具,可在应用程序执行期间拦截 MPI 调用和其他事件,并收集运行时信息。收集到的信息包括:(i) 通过 PAPI 的性能计数器;(ii) 调用了哪个 MPI 基元;(iii) 通信期间涉及了哪些进程。所有这些信息都存储在一个名为跟踪的文件中。跟踪文件中的每条记录都有一个相关的时间戳。使用 Extrae 追踪 MPI 应用程序不需要重新编译应用程序。
Paraver是一种可视化工具,可帮助浏览 Extrae 生成的跟踪。使用 Paraver 时常见的可视化模式是时间轴。时间线表示给定指标在不同时间段的演变情况。图 7 显示了两个时间线示例。x 轴代表时间,y 轴代表 MPI 进程。每个突发都用颜色标示。对于定量值(上图),色标从深蓝(高值)到浅绿(低值)。对于定性值(底部),每种颜色代表不同的概念(如 MPI 基元)。

Daltabaix 是我们开发的一款数据处理工具,它可以获取 Paraver 跟踪数据,并为给定的 CPU 计算自顶向下模型的指标。指标列表、哪些计数器是必要的以及如何组合这些指标,都存储在每个支持 CPU 型号的配置文件中。由于单个 PAPI 事件集可轮询的硬件计数器数量不足以在每台机器上构建整个自顶向下模型,因此 Daltabaix 会从不同事件集的执行轨迹中收集计数器。对于并行执行,Daltabaix 将所有测量值的总和用于计算自顶向下模型的指标。这种方法背后的原因是,我们定义了应用程序消耗的时钟或插槽(取决于系统)预算,而不管哪个周期属于哪个内核。
4.2. 测量方法
在每台机器上,我们使用一个完整节点运行 Alya,每个内核映射一个 MPI 级。我们将模拟配置为以五个时间步运行。我们手动检测代码,在每个时间步开始和结束纳斯丁矩阵组装阶段时执行测量。我们验证了硬件计数器在运行之间的可变性低于 5%,因此我们认为可以在属于不同执行的计数器之间进行操作。
下图显示了我们研究的工作流程示意图。从左至右:(i) 我们使用 Extrae 仪器执行 Alya。(ii) Extrae 调用 PAPI 接口,该接口将轮询硬件计数器。(iii) 执行结束时,Extrae 生成 Paraver 跟踪,并将其输入 Daltabaix。(iv) 根据配置文件的定义,Daltabaix 通过调用 Paraver 命令行工具提取自顶向下模型的相关指标。指标以表格形式打印出来,并存储在一个单独的文件中。
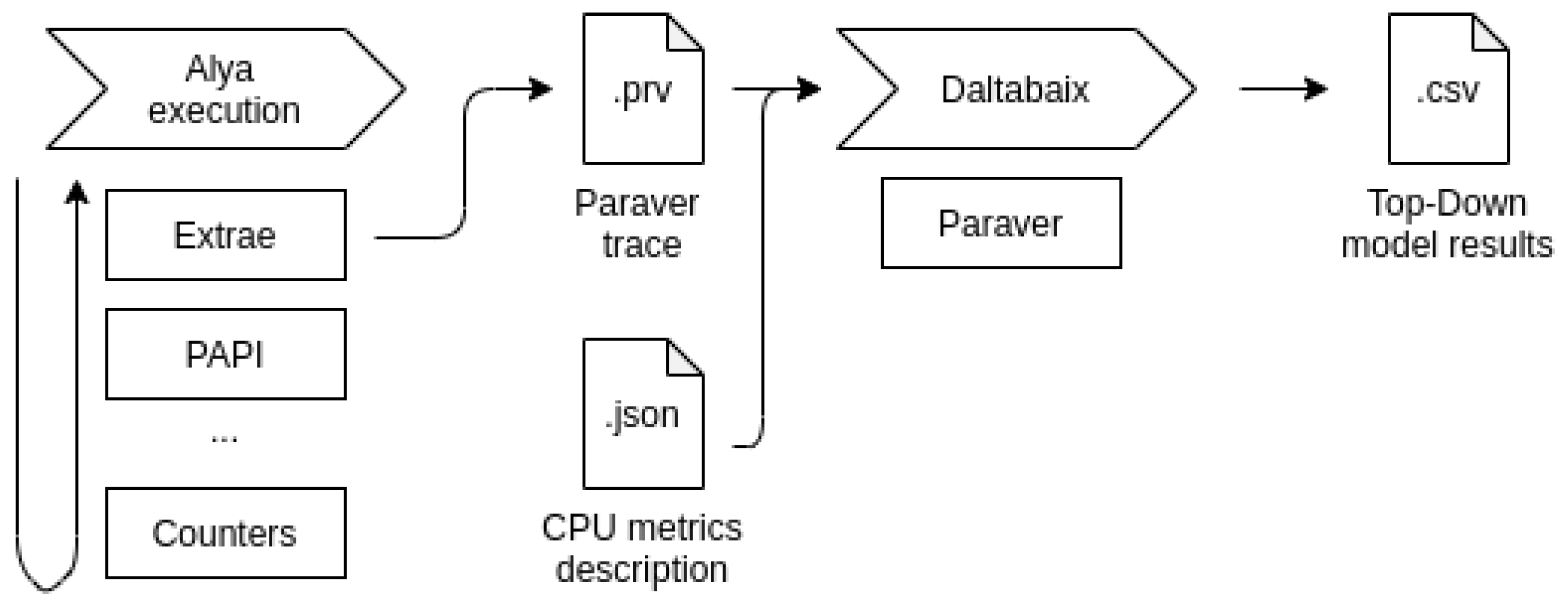
由于每个 CPU 中的自顶向下模型之间没有共同点,因此 Daltabaix 需要根据自顶向下模型的 定义及其架构参数,以不同的方式为每个集群工作。该工具的附加价值在于,它提供了一个统一所有类自顶向下模型的接口。不过,读者应该注意,要重现我们的结果,并不一定要使用我们介绍的这些工具。附录 A 中的表格是为每个集群构建相同模型的配方,而使用硬件计数器收集的数据(无论使用何种工具查询)则是其中的成分。Daltabaix 只是按照模型定义进行烹饪,并以易于消化的格式输出数据。
参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
5 结果
我们以表格的形式列出模型层次结构。行代表指标,每列代表给定 VECTOR_SIZE 的运行。虚线上方的指标不是自顶向下模型的一部分,但提供了我们认为与分析整体指标相关的补充信息。每个单元格包含给定运行的给定度量值,并以从红色(度量值等于零)到绿色(度量值等于一)的渐变色编码。读者应牢记,根据机器的不同,这些指标代表的是已消耗插槽(或周期)总量的一部分,而对于其他机器,它们代表的是父指标的一部分。
5.1. MareNostrum 4
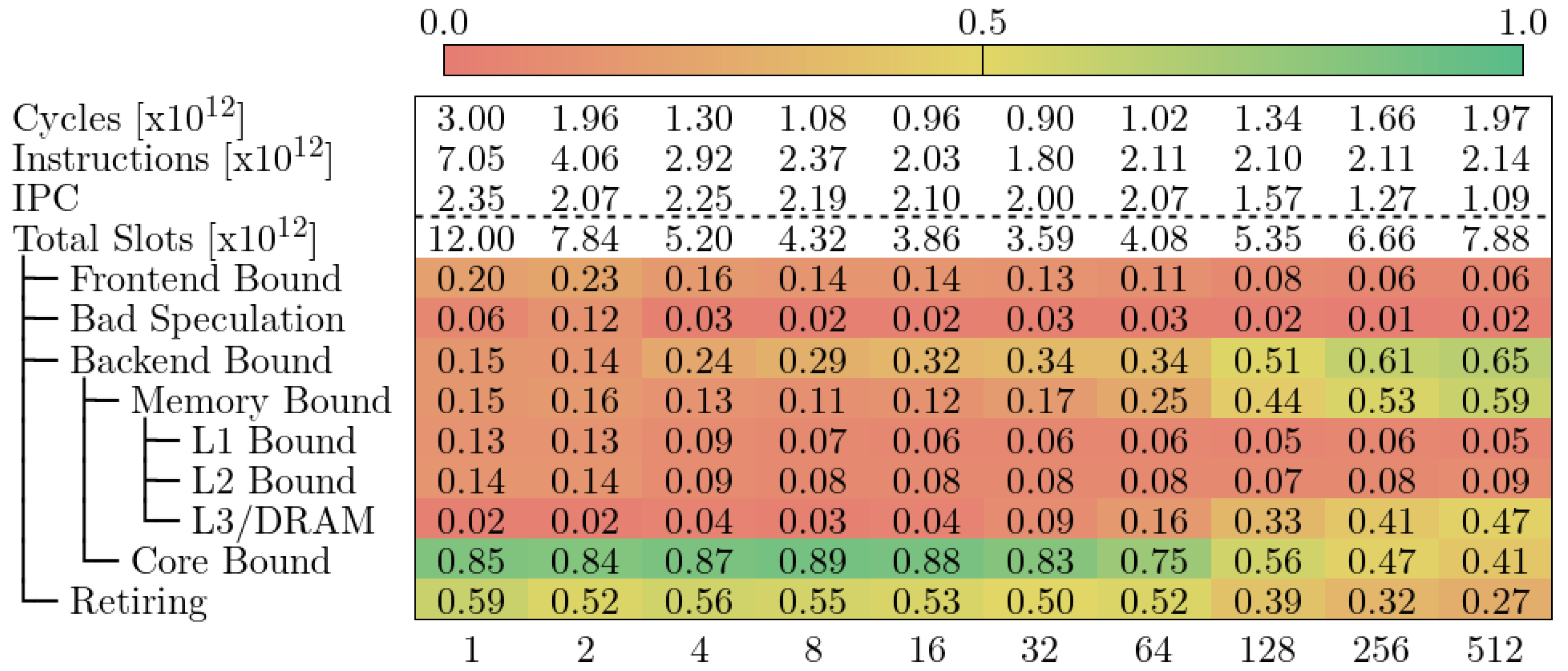
下图显示了 MareNostrum 4 中 Alya 的自顶向下模型。我们观察到,在 VECTOR_SIZE 为 32 之前,循环次数一直在减少,之后又反弹回来。执行指令的数量和 IPC 也与我们之前了解的应用相吻合。自顶向下模型告诉我们,当 VECTOR_SIZE 增加时,MareNostrum 4 中的 Alya 会受到不同因素的影响。
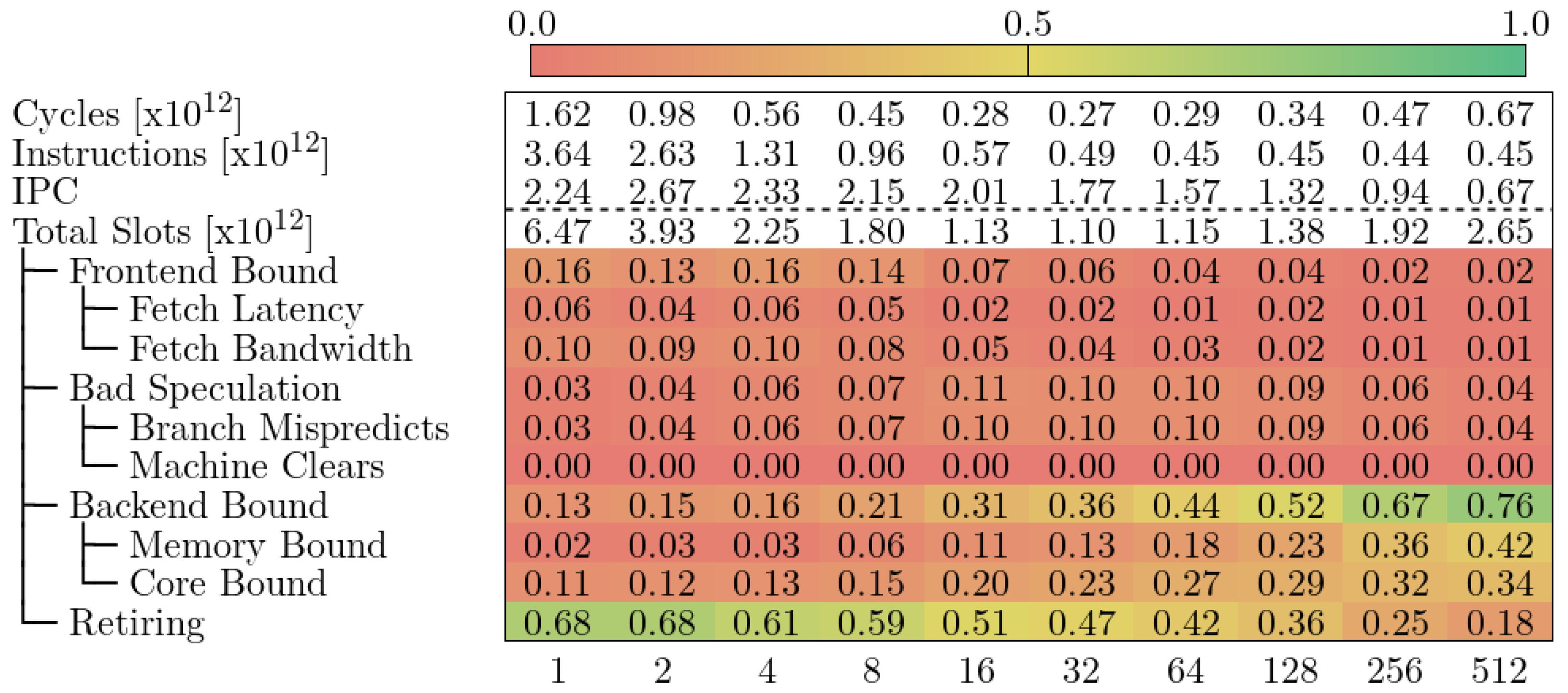
1 至 32:大部分循环被归类为 “退休”,这意味着流水线没有停滞。读者需要注意的是,该模型并不能让我们深入了解流水线上的指令是否是有用的计算。
32-128:代码属于 Core Bound,这意味着流水线因计算资源而停滞。TMAM 的官方定义定义了核心约束下的指标,但 MareNostrum 4 中的 PAPI 安装无法提供必要的计数器。指令组合或流水线使用明细可以提供更多信息,说明是哪种类型的操作堵塞了 CPU。不过,请注意内存绑定指标正在逐渐增加。这意味着内存访问导致的流水线停滞影响越来越大。
128-512:代码属于 “内存绑定”,这意味着由于流水线正在等待内存资源而导致插槽丢失。同样,原始模型描述的详细指标我们无法在 MareNostrum 4 中进行测量。此外,我们也不知道程序员可以采取哪些措施来减少内存压力。
由于我们无法在 MareNostrum 4 中构建更多层次的自顶向下模型,因此无法进一步研究内存约束类别。不过,我们从之前的研究中得知,VECTOR_SIZE 值过高的问题与内存有关,因此我们可以研究内存层次结构中不同级别的访问次数和未命中次数。在 Skylake CPU 中,二级缓存是私有缓存的最后一级。它是内存层次结构中的最高级别,在这里我们可以测量每个内核的内存访问量。下图显示了 L2 高速缓存访问量(绿色条形图,使用 PAPI_L2_TCA 测量)、L2 高速缓存未命中率(紫色条形图,使用 PAPI_L2_TCM 测量)和 L2 未命中率(线形图,使用 PAPI_L2_TCM/PAPI_L2_TCA 测量)的变化情况。

我们发现,二级缓存访问次数呈 U 型,与执行周期类似。相比之下,二级缓存未命中次数在 VECTOR_SIZE 1 到 32 之间保持平稳,当数值越大时则急剧增加。二级缓存访问量和未命中率(未命中率)的综合显示,从 VECTOR_SIZE 32 开始出现了明显的跃迁。这一跳变与 Alya 的运行时间停止下降的时间点相吻合,代码修改似乎是有害的。这也与上上图的结果相吻合;当 VECTOR_SIZE 在 32 和 128 之间时,最高的指标是核心约束,但内存约束是持续增加的指标。我们的结论是,在 MareNostrum 4 中,Alya 的代码修改在 VECTOR_SIZE 32 之前是有益的,因为它减少了执行指令的数量和 L2 访问的数量。但是,这种修改会出现一个拐点,之后 L2 未命中率会变得过高,耗时也会反弹。
自顶向下模型帮助我们大致确定了 CPU 在执行过程中停滞的部分。不过,更详细的指标需要访问硬件计数器,而我们的平台无法访问这些计数器。这限制了该模型所能提供的洞察力。我们可以对自顶向下模型提供的信息进行补充,以弥补缺失的指标(如 L2 访问和未命中)。如果没有这些补充数据,我们就无法知道执行周期是如何损失的。此外,对 MareNostrum 4 的研究表明,查看最高值的指标只能说明部分问题。
5.2. CTE-AMD
下图显示了 CTE-AMD 中 Alya 的自顶向下模型。我们观察到的行为与的 MareNostrum 4 类似(即执行周期数在 VECTOR_SIZE 32 之前减少,之后反弹)。在这种情况下,我们也发现后端约束类别是限制 VECTOR_SIZE 高值的主要因素。不过,CTE-AMD 的后端约束起点为 56%,而 MareNostrum 4 为 13%。此外,与 MareNostrum 4 相比,CTE-AMD 中归类为 Retiring 的slot比例始终较低。遗憾的是,我们无法进一步深入研究,因为我们没有集群中可用的指标定义或更多硬件计数器。
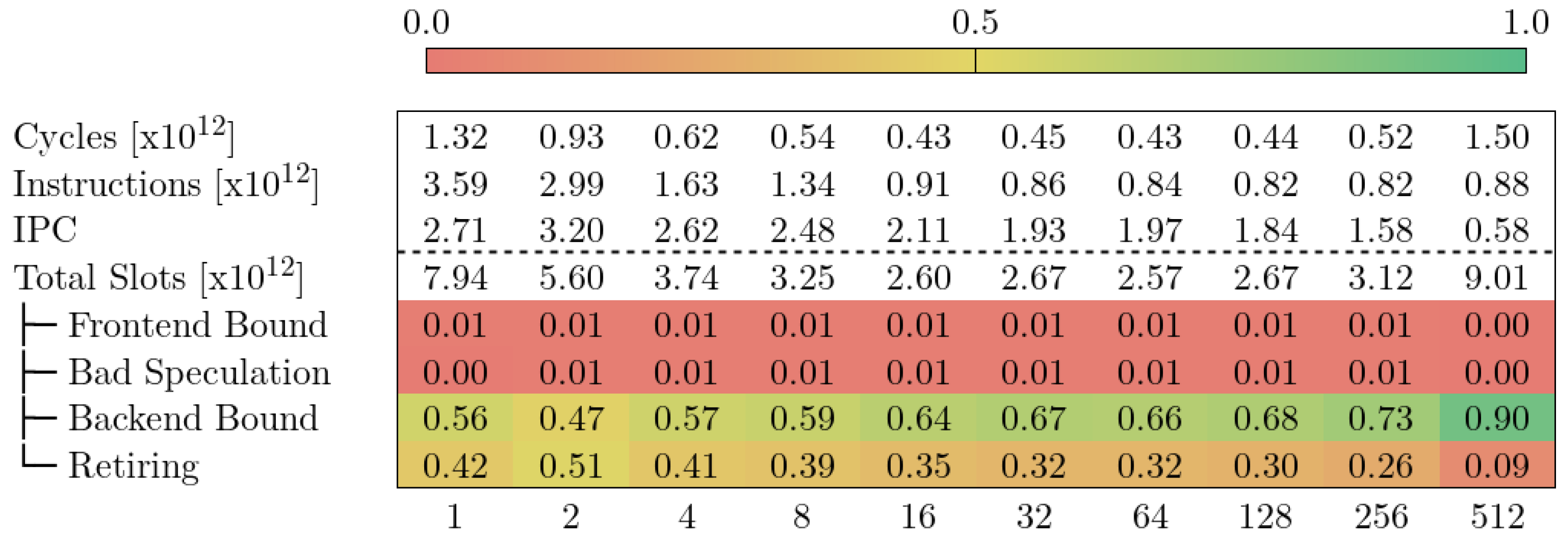
5.3. CTE-Arm
下图显示了 CTE-Arm 中 Alya 的自顶向下模型。上半部分表示模型的前三个层次,下半部分表示内存约束下的指标。与 MareNostrum 4 和 CTE-AMD 一样,在 VECTOR_SIZE 达到一定值之前,执行周期一直在减少,然后又跳升。我们发现,在 CTE-Arm 中,VECTOR_SIZE 128 和 256 的值产生的周期最少。与 MareNostrum 4 和 CTE-AMD 相比,VECTOR_SIZE 值要高得多,分别为 32 和 64 左右。
CTE-Arm 中的自上而下模型没有像 MareNostrum 4 中那样的 Retiring 指标。我们可以通过组合{4,3,2,1}INST_COMMIT 实现类似的度量。这一新指标将至少提交过一条指令的周期分组,与 Retiring 的定义类似,但包括 CPU 无法提交指令的周期。MareNostrum 4 和 CTE-Arm 模型的主要区别在于,前者使用 “槽”(Slot)来构建指标,而后者则使用 “周期”(Cycles)。
我们观察到在 VECTOR_SIZE 1 的情况下,CTE-Arm 75% 的执行周期完全处于停滞状态(0INST_COMMIT)。在所有 VECTOR_SIZE 值中都可以观察到这一趋势,其中 4 的值最低(59%),512 的值最高(79%)。读者应注意,0INST_COMMIT 指标显示了流水线停滞的严重程度,但并不反映总的执行时间。此外,该指标是相对于总执行周期而言的,这意味着 0INST_COMMIT 值最低的运行不一定是最快的。目前,CTE-Arm 中的 “自顶向下 ”模型不允许我们比较不同运行的指标。它允许我们做的是在特定运行中沿着层次往下走,或观察不同运行的总体趋势。
对于 VECTOR_SIZE 的低值,内存约束和计算约束指标是主要限制因素。从 VECTOR_SIZE 32 开始,内存约束占 0INST_COMMIT 所损失周期的一半以上。我们可以进一步深入分析并测量内存约束以下的指标(如图 11 底部所示)。我们注意到,除了 VECTOR_SIZE 1 的 L1 命中率较高外,Base 指令始终是主要指标。富士通官方文档[11]中对这一指标的描述如下 属于基本指令(Armv8 ISA 中的基本指令集包含基本标量运算和内存指令)的指令引起的循环。仅凭这一定义,尚不清楚该指标与内存约束下的其他指标之间是否存在重叠。不过,同一文件中的表 14-6 证实没有重叠。我们的观察结果是,由于 L1 未命中而损失的周期比例增加,而 L1 命中的比例则相反。根据现有信息,我们无法将等待内存访问完成所损失的周期归咎于特定类型的加载操作。我们只能得出结论,这是一种标量指令(不是 SIMD 或 SVE)。
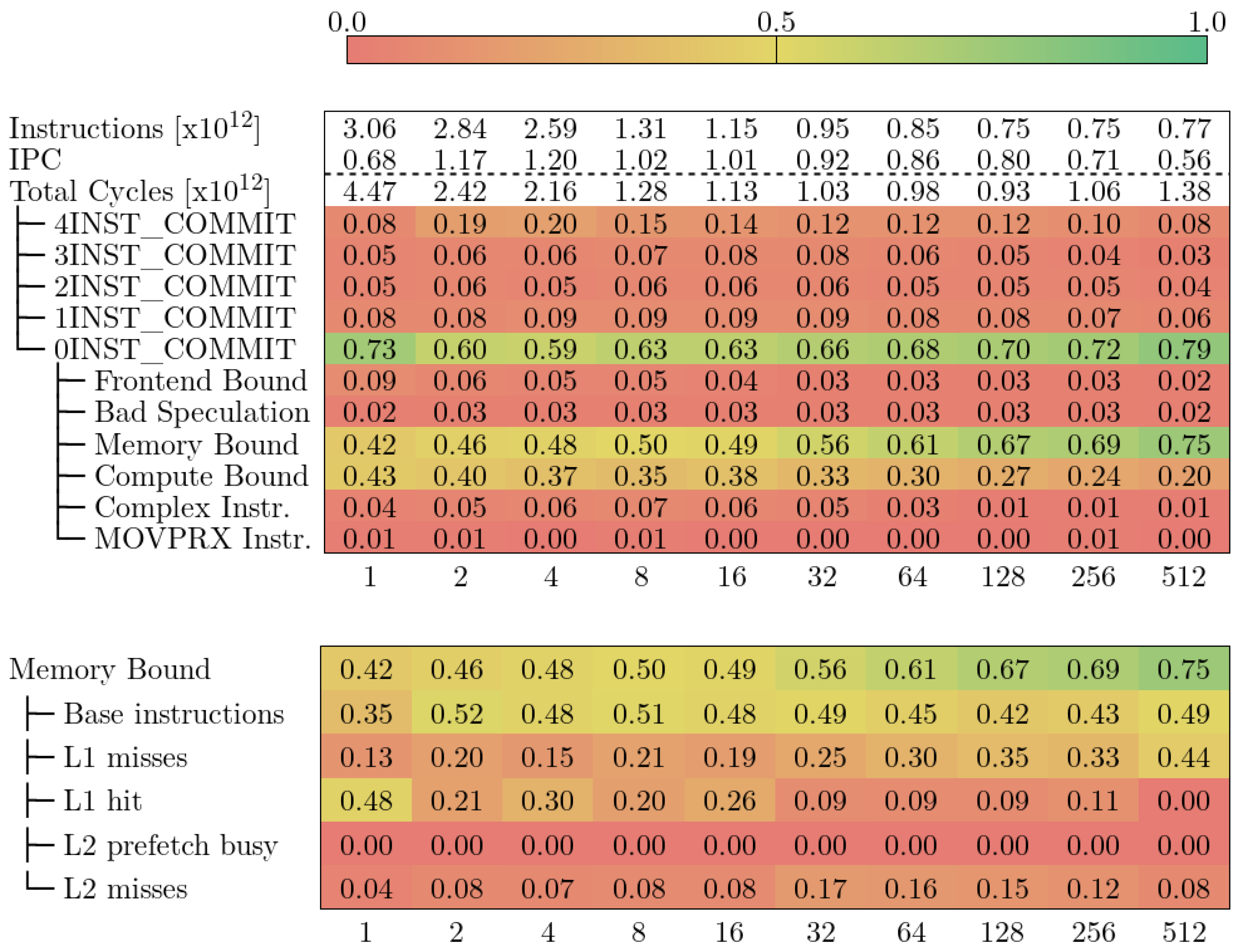
5.4 CTE-Power
下图显示了 CTE-Power 中 Alya 的自顶向下模型。与 CTE-Arm 一样,总周期数随着 VECTOR_SIZE 的增加而减少,但当 VECTOR_SIZE 为 512 时又开始反弹。
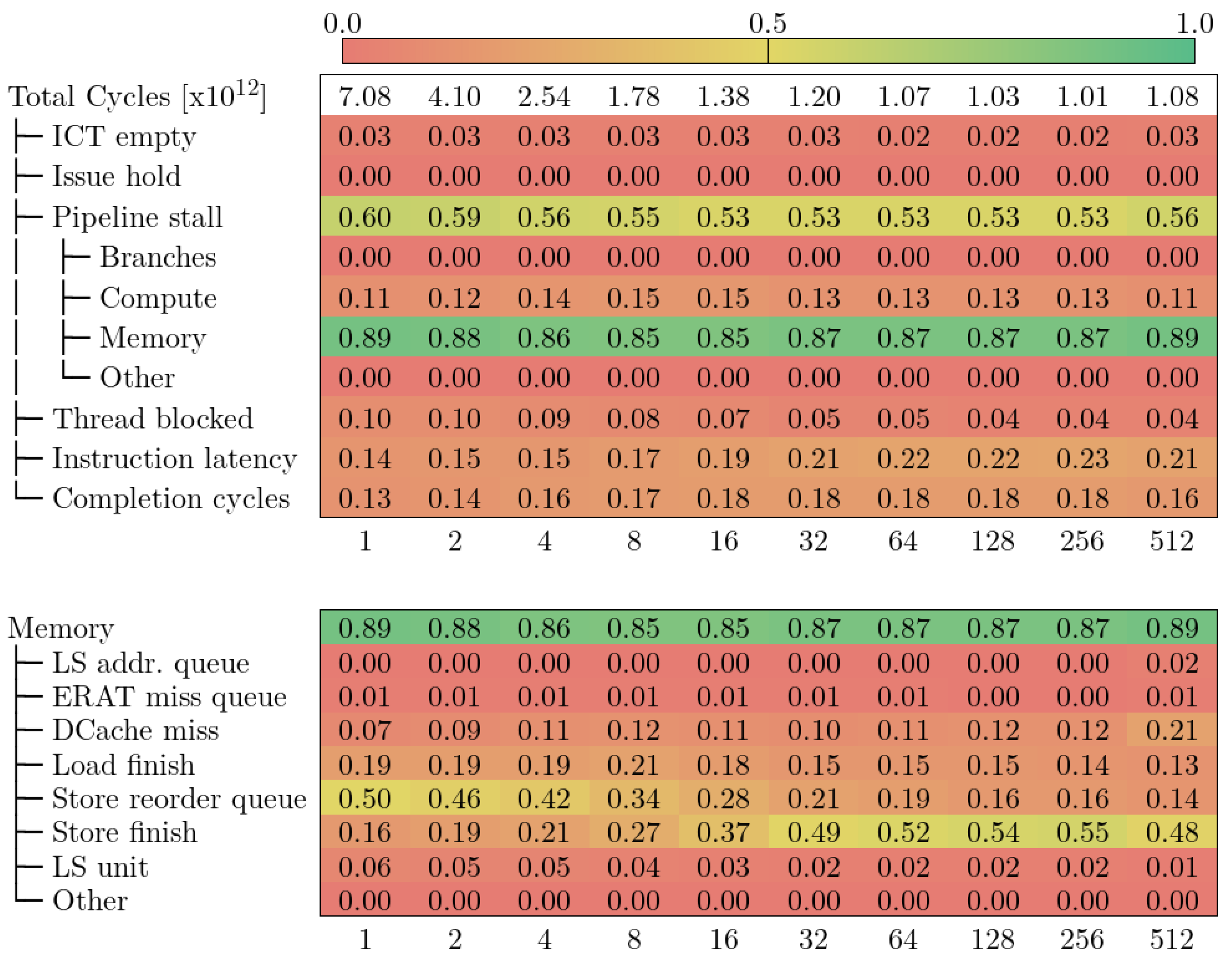
在所有执行过程中,主要限制因素是管道停滞类别,这与 MareNostrum 4 中的 Retiring 类别相当。此外,内存子类别始终占停滞周期的 85% 至 90%。相比之下,排名第二的计算子类别最多只占 15%。
深入研究内存类别,我们发现当 VECTOR_SIZE 增加时,有两个指标发生了明显变化:存储重排队列和存储完成。在 VECTOR_SIZE 为 1 时,第一个指标占内存停滞造成的循环次数的 50%,而在存储完成指标的权重增加时,它的权重却在下降。
存储重排序队列由计数器 PM_CMPLU_STALL_SRQ 定义,用于测量存储操作因存储重排序缓冲器 (SRQ) 已满(即同时有太多存储操作在执行)而停滞的周期。
存储完成是由计数器 PM_CMPLU_STALL_STORE_FINISH 定义的,它衡量的是存储操作需要满足所有依赖条件才能完成的等待周期(即存储操作的标称延迟)。
根据这两个指标的定义,我们可以推断出参数 VECTOR_SIZE 会影响同时进行的存储操作的数量。如果参数值较低(VECTOR_SIZE ≤ 16),则同时进行的存储操作过多,导致流水线停滞。从这一点出发,并发存储操作会减少,这意味着流水线仍在等待存储完成。不过,这些存储操作需要最少的周期才能完成(流水线延迟)。CTE-Power 的自顶向下模型在很大程度上依赖于微体系结构,因此深入层次结构可能会更深入地了解性能瓶颈,但也更难与其他机器进行比较。
5.5. CTE-Kunpeng
下图显示了 Alya 在 CTE-Kunpeng 中的自顶向下模型。此外,该模型的定义与英特尔的原始自顶向下模型非常相似。与 MareNostrum 4 相反,CTE-Kunpeng 中的结果显示,Core Bound 是 VECTOR_SIZE 值较低时的主要限制因素。我们知道,与 MareNostrum 4 相比,CTE-Kunpeng 中 CPU 的单线程性能较低。在 Alya 的情况下,由于计算资源被占用,内核浮点吞吐量较弱,反映为周期停滞。在撰写本文时,我们还没有核心约束下的指标定义,因此无法构建整个层次结构。
随着 VECTOR_SIZE 的增加,内存约束指标也在增加。从 VECTOR_SIZE 256 开始,Alya 开始受到内存子系统的约束。我们可以针对内存绑定部分研究 CTE-Kunpeng 中的不同缓存级别。在 MareNostrum 4 中,由于缺乏计算指标的 PAPI 计数器,我们无法进行这种深入研究。在这一点上,模型表明周期损失是由于 L3 高速缓存和 DRAM 访问或未命中造成的。鲲鹏 920 CPU 的高速缓存层次结构跨内核共享 L3 层,因此很难将访问或未命中归咎于某个特定的内核。
6 结论与讨论
在本文中,我们研究了由五家不同芯片供应商(英特尔、AMD、富士通、华为和 IBM)在五个高性能计算集群中实现的三种不同 ISA(x86-64、Arm-v8 和 IBM Power9)的自顶向下模型。我们使用 CFD 应用程序 Alya 来测量每个模型的指标,并深入了解性能瓶颈。我们的研究结果可归纳为两大类:(i) 在同一集群内研究自顶向下模型时可得出的结论;(ii) 从不同集群收集的自顶向下结果的相关考虑因素。
我们发现,在同一集群内实施自顶向下模型可能很棘手;深入模型的层次结构意味着需要硬件计数器,而由于工具、系统成熟度和软件配置的限制,硬件计数器并不总是可用的。此外,一些架构细节也可能缺失。
就个案而言,x86-64 Skylake 是英特尔官方支持文档最多的产品。这些指标定义明确,易于理解,但它们需要硬件计数器,而 MareNostrum 4 中并不提供这些计数器。这一问题在 CTE-AMD 中更为明显,我们无法超越自顶向下模型的第一级指标。对于 CTE-Power,构建整个层次结构所需的计数器数量意味着需要通过多次运行来获取数据。一旦构建完成,与其他集群相比,解释指标需要对系统的微观架构有更深入的了解。CTE-Arm 中的模型试图达到一种平衡;官方文档中的循环核算附有多个互补指标表,因此我们能够超越第一级指标。不过,CTE-Arm 中的模型定义不允许在运行之间进行指标比较,因为指标是相对于树状结构中的父指标而不是根指标而言的。
将硬件计数器映射到给定系统中的自顶向下模型后,我们将对从模型本身获得的启示进行评论。指标总是相对于各自运行的执行周期(或父指标)而定义的。因此,在同一集群上比较不同软件配置(如改变 VECTOR_SIZE)下的运行时,某个指标值的高低并不意味着执行时间的长短。自顶向下模型仅显示总体趋势,以及在不同配置(如改变 VECTOR_SIZE)下的不同运行过程中的演变情况。一旦构建完成,所有集群的指标解释都取决于微体系结构知识。
在不同的集群中,我们发现了更多的限制。由于没有跨系统的标准度量命名规范,因此很难比较在不同集群上收集的自顶向下模型的结果。例如,在 MareNostrum 4、CTE-AMD 和 CTE-Kunpeng 上,Top-Down 模型的低效是在 CPU 前端和后端之间的边界收集的,而在 CTE-Arm 和 CTE-Power 上,模型计算的是指令提交阶段损失的周期。
我们看到,在不同的机器上,根据硬件计数器的可用性,我们可以深入模型的层次结构。然而,即使能够访问整个性能监控单元(硬件计数器存储在其中),也并不意味着就能神奇地获得更多洞察力,因为要正确理解大多数计数器,需要对底层微体系结构有深入的了解,而运行科学代码的科学家并不具备这些知识。这就需要在使用自顶向下模型时进行权衡;细节和洞察力越深,就越依赖于以前的微体系结构知识,也就越难与其他机器进行比较。此外,在某些集群中,模型的定义需要架构参数,这就增加了定义模型并与其他集群进行比较的难度。
一个普遍而关键的问题是,没有任何一个模型的指标能说明 CPU 资源的使用情况。我们可以测量的插slot,但这并不能说明代码是否高效运行,而仅仅意味着没有流水线停滞。在英特尔定义的 “自上而下 ”模型中,“退役 ”类别下有一些指标,试图说明是否存在改进空间。不过,我们没有将这些指标纳入我们的工作中,因为(再一次)我们受到了可用硬件计数器的限制。
虽然社区接受自顶向下模型作为发现 HPC 代码效率低下的方法,但我们也遇到过这种情况:
- 在分析和改进科学应用的性能时,它需要额外的信息(微架构细节或更多硬件计数器)来绘制一幅完整的图画;
- 无法量化计算节点内每种资源的使用/饱和程度;
- 无法轻松比较相同架构或不同架构的集群。
对于希望将自顶向下模型用作检查工具以发现复杂科学代码中效率低下问题的性能分析师来说,所有这些局限性都给工作带来了很大困难。对微观架构知识的依赖也使其无法作为共同设计工具提供给所研究科学应用的研究人员。
一种更简单、更有洞察力且与微体系结构无关的计算资源饱和度测量模型如下: 一个执行周期计数器(如 CPU_CYCLES),所有集群都有这个计数器。每个流水线一个计数器,用于计算活动周期(即硬件资源正在执行有用工作的周期)。有了这些信息,性能分析师就能计算出每个计算资源被使用的周期,从而衡量代码在给定硬件下的效率。我们指出,这种方法与微体系结构无关,因为它只计算活动周期,而活动周期是一种可在不同功能单元间进行相同解释的指标。屋顶线模型可以提供更多关于代码实际性能与理论峰值相差多远的信息,从而有助于这项研究。
对于内存层次结构,我们建议查看未命中率。然而,指令未命中率与体系结构有关,因为不同的 ISA 对每条指令的访问次数可能不同。更精确的衡量标准是微操作未命中率,但它的缺点是严重依赖于微体系结构。中间方案是在内存层次结构的每一级都设置一个请求计数器和一个请求命中/未命中计数器。有些集群已经有了这些计数器,但并非所有集群都有。要获得准确的性能指标,就必须知道层次结构中每一级的延迟和带宽,这样才能衡量每次访问的成本(这也是微体系结构特有的功能)。目前还没有独立于硬件的简单方法来精确测量内存访问效率。
最后,我们认为自顶向下模型中提出的周期汇总指标具有易于解释(单一数字)的优点,但却隐藏了代码的异构区域。就 Alya 而言,我们知道有一个特定区域是我们想要研究的:Nastin 矩阵组装。然而,对于其他代码,我们可能无法获得这些先前的知识,因此性能分析师必须为应用程序的整个执行过程构建自顶向下模型。更精确和自动化的方法是首先使用聚类技术对执行阶段进行分类,然后将自顶向下模型应用于每个阶段。
以下略(需要完整版本+钉或v: pythontesting)
来源链接:https://www.cnblogs.com/testing-/p/18726583





没有回复内容