
7 性能分析工具概述
在上一章中,我们探讨了现代处理器中用于辅助性能分析的功能。但是,如果直接开始使用这些功能,很快就会变得非常复杂,因为使用这些功能需要大量的底层编程。幸运的是,性能分析工具解决了有效使用这些硬件性能监控功能所需的所有复杂问题。
这使得剖析工作得以顺利进行,但直观了解此类工具如何获取和解释数据仍然至关重要。这就是为什么我们在讨论完 CPU 性能监控功能后才讨论分析工具的原因。
本章简要介绍了主要平台上最流行的性能分析工具。其中一些工具是跨平台的,但大多数不是,因此了解有哪些工具可供使用非常重要。剖析工具通常由硬件供应商自行开发和维护,因为他们知道如何正确使用处理器上的性能监控功能。因此,高级性能工程工具的选择取决于您使用的操作系统和 CPU。
阅读完本章后,请花时间练习使用您最终可能使用的工具。熟悉这些工具的界面和工作流程。对日常使用的应用程序进行简介。即使您没有发现任何可操作的见解,当实际需要时,您也会准备得更加充分。
7.1 Intel VTune Profiler
VTune Profiler(前身为 VTune Amplifier)是一款基于 x86 处理器的性能分析工具,具有丰富的图形界面。它可在 Linux 或 Windows 操作系统上运行。由于 VTune 不支持苹果芯片(如 M1 和 M2),而且基于英特尔的 Macbook 很快就会被淘汰,因此我们跳过了对 MacOS 支持 VTune 的讨论。
VTune 可在英特尔和 AMD 系统上使用。不过,基于硬件的高级采样需要英特尔制造的 CPU。例如,使用英特尔 VTune 无法在 AMD 系统上收集硬件性能计数器。
截至 2023 年初,VTune 可作为独立工具或英特尔oneAPI 基础工具包的一部分免费提供。
7.1.1 配置
Linux perf 和 VTune 自带的名为SEP (Sampling Enabled Profiler) 的驱动程序。第一种用于用户模式采样,但如果要执行高级分析,则需要构建并安装 SEP 驱动程序,这并不难。
# 进入 vtune 安装的 sepdk 文件夹
$ cd ~/intel/oneapi/vtune/latest/sepdk/src
# 构建驱动程序
$ ./build-driver
# 添加 vtune 组并将你的用户添加到该组
# 创建一个新的 shell,或者重新启动系统
$ sudo groupadd vtune
$ sudo usermod -a -G vtune `whoami`
# 安装 sep 驱动程序
$ sudo ./insmod-sep -r -g vtune
完成上述步骤后,您就可以使用高级分析类型,如微架构探索和内存访问。安装 VTune 后,Windows 不需要任何额外配置。收集硬件性能事件需要管理员权限。
7.1.2 你能用它做什么?
- 查找热点:函数、循环、语句。
- 监控各种特定于 CPU 的性能事件,如分支预测错误和 L3 缓存未命中。
- 找出发生这些事件的代码行。
- 利用 TMA 方法分析 CPU 性能瓶颈。
- 针对特定功能、进程、时间段或逻辑内核过滤数据。
- 观察一段时间内的工作负载行为(包括 CPU 频率、内存带宽利用率等)。
VTune 可以提供有关运行进程的丰富信息。如果你想提高应用程序的整体性能,它就是你的理想工具。VTune 总是提供一段时间内的汇总数据,因此可用于寻找 “平均情况 ”的优化机会。
7.1.3 不能用它做什么
- 分析极短的执行异常。
- 观察整个系统的复杂软件动态。
由于该工具的采样性质,它最终会错过持续时间很短的事件(如亚微秒级)。
7.1.4 示例
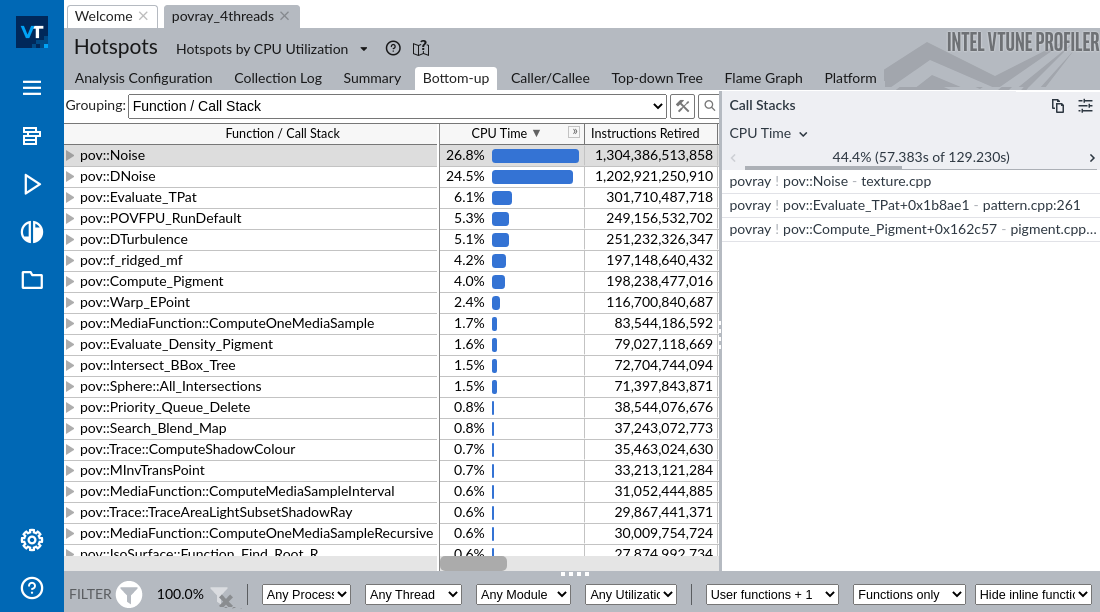
下面是 VTune 最有趣功能的一系列截图。在这个示例中,我使用了 POV-Ray,这是一种用于创建 3D 图形的光线跟踪器。下图显示了内置 POV-Ray 3.7 基准的热点分析,该基准由 clang14 编译器编译,带有 -O3 -ffast-math -march=native -g 选项,在英特尔 Alder Lake 系统(酷睿 i7-1260P,4 个 P 核 + 8 个 E 核)上运行,有 4 个工作线程。
在图片的左侧,您可以看到工作负载中的热函数列表以及相应的 CPU 时间百分比和退出指令的数量。
在右侧面板上,您可以看到导致调用函数 pov::Noise 的最频繁调用堆栈。根据该屏幕截图,44.4% 的时间 pov::Noise 函数是从 pov::Evaluate_TPat 调用的,而后者又从 pov::Compute_Pigment 调用。
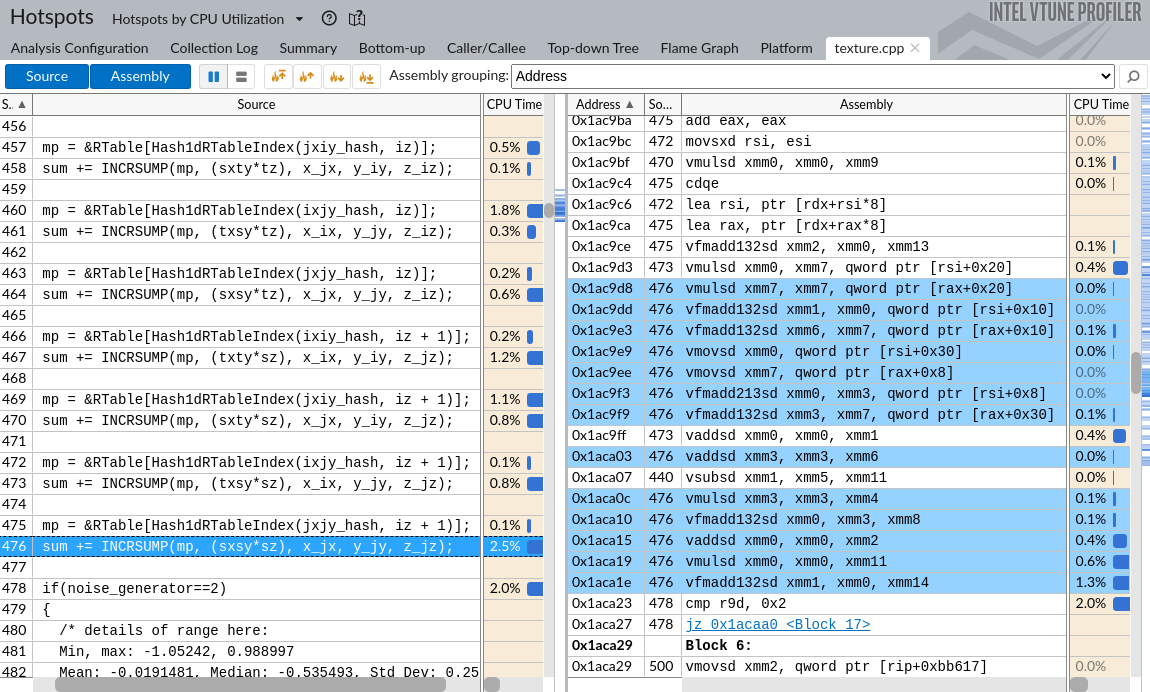
如果双击 pov::Noise 函数,您将看到下图所示的图像。出于篇幅考虑,仅显示最重要的列。
左侧面板显示与每行代码对应的源代码和 CPU 时间。在右侧,您可以看到汇编指令以及分配给它们的 CPU 时间。突出显示的机器指令对应于左侧面板中的第 476 行。每个面板中所有 CPU 时间百分比(不仅仅是可见的百分比)的总和等于分配给 pov::Noise 函数的总 CPU 时间,即 26.8%。
使用 VTune 配置在英特尔 CPU 上运行的应用程序时,它可以收集许多不同的性能事件。为了说明这一点,我运行了不同的分析类型–微体系结构探索。要访问原始事件计数,可以将视图切换到 “硬件事件”,如下图所示。要启用切换视图,需要在选项 → 常规 → 显示所有适用视点中勾选标记。在下图顶部附近,可以看到平台选项卡已被选中。另外两个页面也很有用。摘要 “页面显示从 CPU 计数器收集的原始性能事件的绝对数量。事件计数页面提供了按功能细分的相同数据。
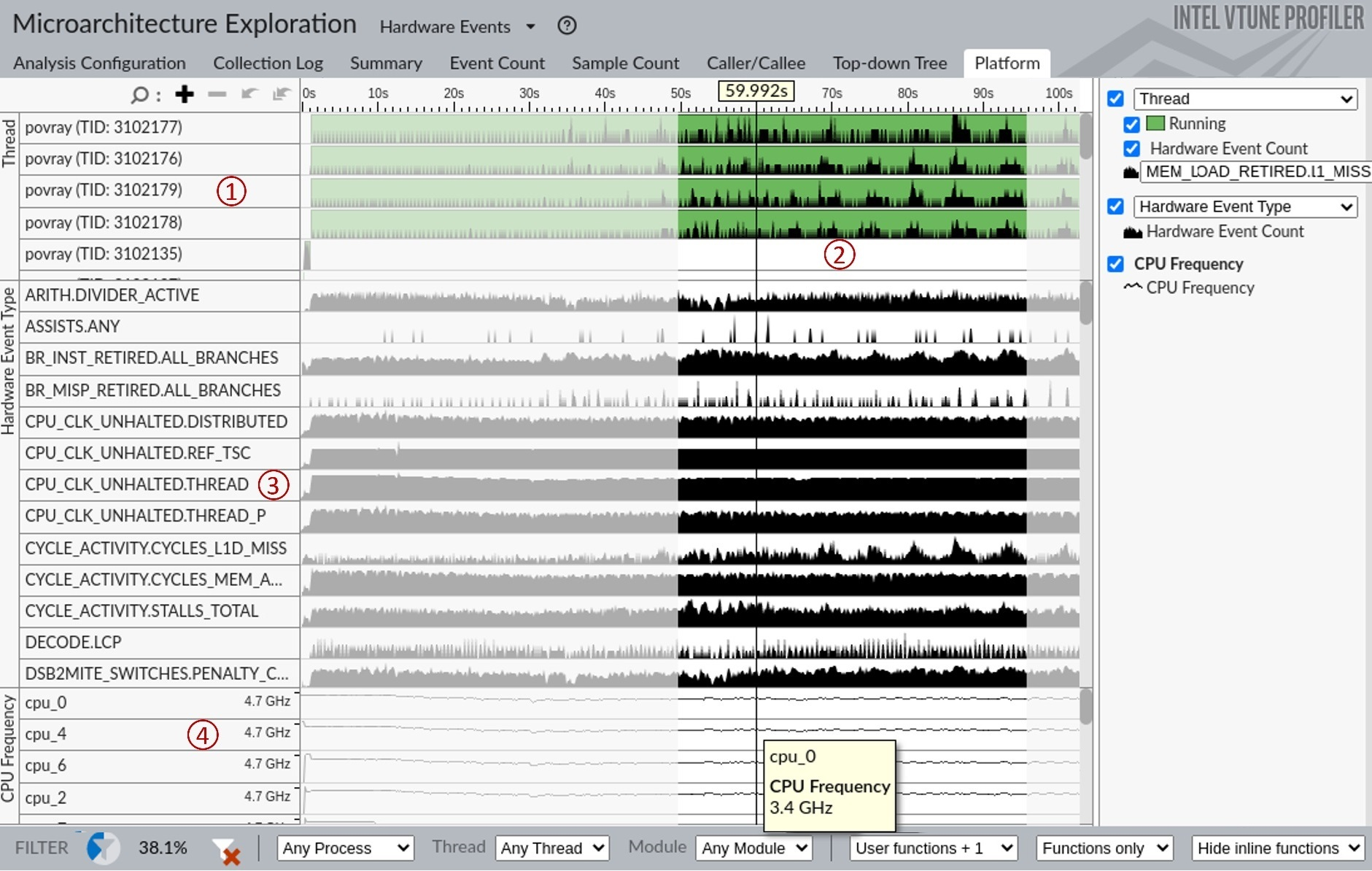
上图比较复杂,需要解释一下。顶部面板用 1 表示,是一个时间线视图,显示了我们的四个工作线程在一段时间内相对于 L1 缓存未命中的行为,以及主线程 (TID: 3102135) 的一些微小活动,该线程会生成所有工作线程。黑条越高,在任何给定时刻发生的事件(在本例中为 L1 缓存未命中)就越多。请注意,所有四个工作线程的 L1 未命中偶尔会激增。我们可以使用此视图观察工作负载的不同或可重复阶段。然后,要确定当时执行了哪些函数,我们可以选择一个间隔并单击“过滤”以仅关注运行时间的那部分。用 2 表示的区域是此类过滤的一个示例。要查看更新的函数列表,您可以转到事件计数视图。所有 VTune 时间线视图都提供此类过滤和缩放功能。(注意,调用栈并没有一直通向主函数。出现这种情况的原因是,在基于硬件的收集中,VTune 使用 LBR 对调用堆栈进行采样,但深度有限。我们很可能正在处理递归函数,要进一步研究,用户必须深入代码。)
用 3 表示的区域显示了收集到的性能事件及其随时间的分布情况。这次不是按线程查看,而是显示所有线程的汇总数据。除了观察执行阶段,还可以直观地提取一些有趣的信息。例如,我们可以看到执行的分支数量很多(BR_INST_RETIRED.ALL_BRANCHES),但错误预测率却很低(BR_MISP_RETIRED.ALL_BRANCHES)。由此可以得出结论,分支错误预测并不是 POV-Ray 的瓶颈。如果向下滚动,就会发现 L3 错失次数为零,L2 缓存错失也非常罕见。这告诉我们,99% 的内存访问请求都是由 L1 处理的,其余的都是由 L2 处理的。结合这两项观察结果,我们可以得出结论,应用程序很可能受到了计算的约束,即 CPU 忙于计算,而不是等待内存或从错误预测中恢复。
最后,底部面板 4 显示了四个硬件线程的 CPU 频率图。悬停在不同的时间片上,我们可以看到这些内核的频率在 3.2-3.4GHz 区域内波动。
7.2 AMD uProf(略)
7.3 Apple Xcode Instruments(略)
7.4 Linux Perf
Linux Perf 可能是世界上使用最多的性能剖析器,因为它在大多数 Linux 发行版上都有提供,这使得广大用户都能使用它。包括 Ubuntu、Red Hat 和 Debian 在内的许多流行 Linux 发行版都支持 Perf。它包含在内核中,因此你可以在任何运行 Linux 的系统上获取操作系统级别的统计数据(页面故障、CPU 迁移等)。截至 2024 年年中,剖析器支持 x86、ARM、PowerPC64、UltraSPARC 和其他一些 CPU 类型。在这些平台上,perf 可以访问硬件性能监控功能,例如性能计数器。有关 Linux perf 的更多信息,请访问其维基页面。
如何配置 Linux perf 安装 Linux perf 非常简单,只需一条命令即可完成:
$ sudo apt-get install linux-tools-common linux-tools-generic linux-tools-`uname -r`
此外,除非出于安全考虑,否则可以考虑更改以下默认设置:
# Allow kernel profiling and access to CPU events for unprivileged users
$ echo 0 | sudo tee /proc/sys/kernel/perf_event_paranoid
$ echo kernel.perf_event_paranoid=0 | sudo tee -a /etc/sysctl.d/local.conf
# Enable kernel modules symbols resolution for unprivileged users
$ echo 0 | sudo tee /proc/sys/kernel/kptr_restrict
$ echo kernel.kptr_restrict=0 | sudo tee -a /etc/sysctl.d/local.con
7.4.1 你能用它做什么?
一般来说,Linux perf 可以做其他剖析器能做的大部分事情。硬件供应商会优先在 Linux perf 中启用它们的功能,这样当新的 CPU 上市时,perf 就已经支持它了。大多数人使用的主要命令有两个。第一个命令是 perf stat,用于报告指定性能事件的计数。第二条命令是 perf record,用于在采样模式下对应用程序或系统进行剖析,之后通常会使用 perf report,根据采样数据生成报告。
perf record 命令的输出是原始的样本转储。许多建立在 Linux perf 基础上的工具都能解析原始转储文件,并提供新的分析类型。下面是其中最著名的几种:
- 火焰图,将在第 7.5 节讨论。
- KDAB Hotspot,这是一种可视化 Linux perf 数据的工具,其界面与 Intel VTune 非常相似。如果您使用过英特尔 VTune,那么 KDAB Hotspot 对您来说就再熟悉不过了。
- Netflix Flamescope该工具可显示应用程序运行时采样事件的热图。您可以观察到工作负载行为的不同阶段和模式。Netflix 工程师使用该工具发现了一些非常微妙的性能错误。此外,您还可以在热图上选择一个时间范围,并为该时间范围生成火焰图。
7.4.2 不能用它做什么
Linux perf 是一种命令行工具,缺乏图形用户界面(GUI),因此很难过滤数据、观察工作负载行为随时间的变化、放大运行时的部分内容等。通过 perf report 命令,可以获得有限的控制台输出,虽然不如其他图形用户界面剖析器方便,但也能满足快速分析的需要。幸运的是,正如我们刚才提到的,有一些 GUI 工具可以对 Linux perf 的原始输出进行后处理和可视化。
参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
7.5 火焰图
火焰图是可视化剖析数据和程序中最频繁代码路径的一种常用方法。它能让我们看到哪些函数调用占用了最多的执行时间。下图 x264 视频编码基准的火焰图示例,由 Brendan Gregg 开发的开源脚本生成。如今,只要在剖析会话期间收集调用堆栈,几乎所有剖析器都能自动生成火焰图。
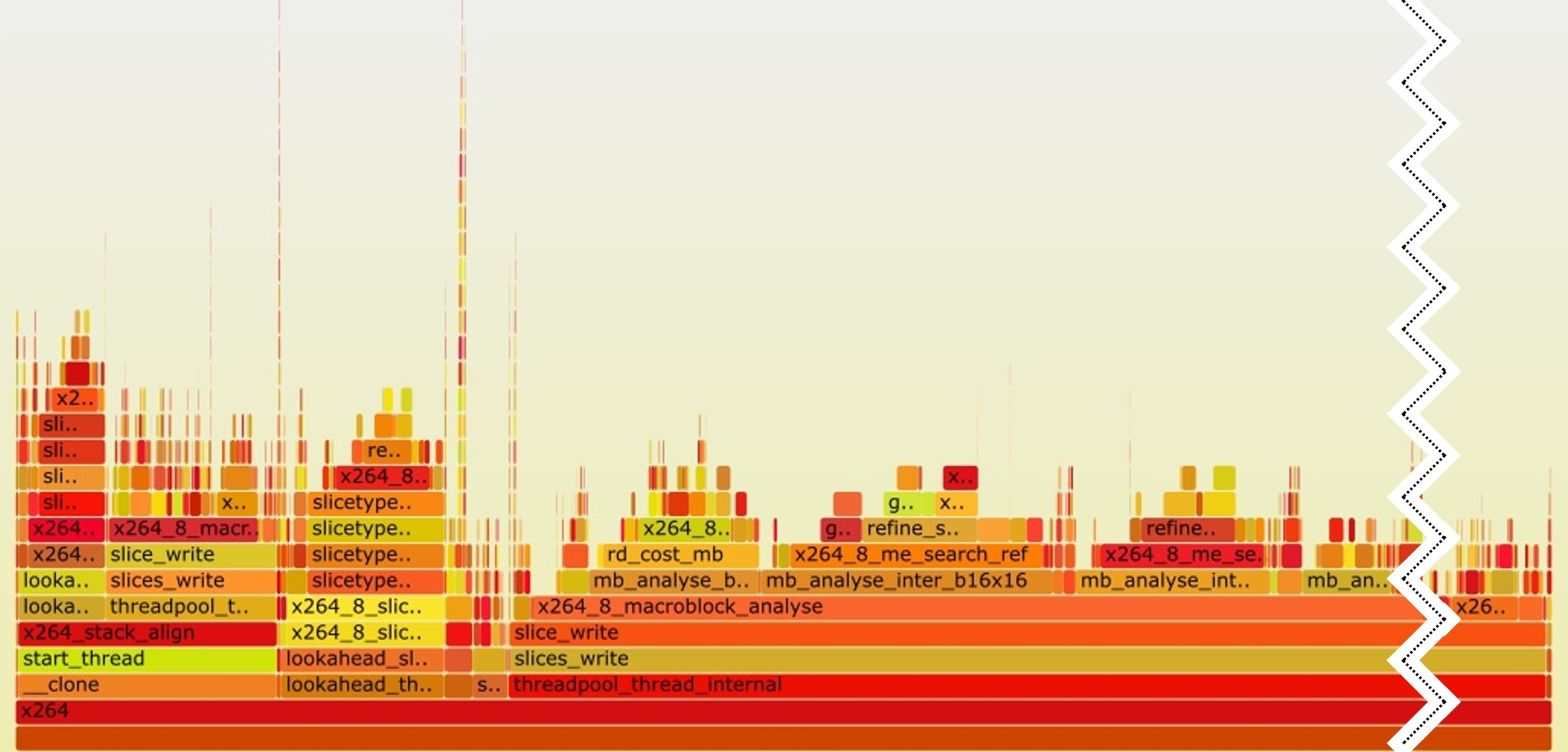
矩形的宽度表示函数本身和函数调用的相对执行时间。函数调用是从下往上进行的,因此我们可以看到程序中最热的路径是 x264 → threadpool_thread_internal → … → x264_8_macroblock_analyse。函数 threadpool_thread_internal 及其调用占程序所用时间的 74%。但自身时间,即函数本身花费的时间却很少。同样,我们可以对 x264_8_macroblock_analyse 进行同样的分析,它占了运行时间的 66%。通过这种可视化的方式,您可以很直观地了解到大部分时间都花在了哪里。
火焰图是交互式的。你可以点击图像上的任意条,它就会放大到该特定代码路径。您可以不断缩放,直到发现某个地方与您的预期不符,或者您发现了一个叶/尾函数–现在您已经掌握了可用于分析的可行信息。另一种策略是找出程序中最热的函数(从火焰图中并不能立即看出),然后自下而上地查看火焰图,试图了解从哪里调用这个最热的函数。
有些工具喜欢使用冰柱图,它是火焰图的倒置版本(参见第 7.9 节中的示例)。
7.6 Windows 事件跟踪
微软开发了一种全系统范围的跟踪工具,名为 Windows 事件跟踪(ETW Event Tracing for Windows)。它最初用于帮助设备驱动程序开发人员,但后来也用于分析通用应用程序。ETW 适用于所有受支持的 Windows 平台(x86 和 ARM),并提供相应的平台安装包。ETW 记录用户和内核代码中的结构化事件,支持完整的调用堆栈跟踪,可帮助您观察运行系统中的软件动态,解决许多具有挑战性的性能问题。
7.6.1 配置
从 Windows 10 开始,使用 WPR.exe 记录 ETW 数据无需额外下载。但要启用全系统剖析,您必须是管理员并启用 SeSystemProfilePrivilege。Windows 性能记录器工具支持一套适用于常见性能问题的内置记录配置文件。您可以通过创建扩展名为 .wprp 的自定义性能记录器配置文件 xml 文件来满足您的记录需求。
如果您不仅想记录,还想查看记录的 ETW 数据,则需要安装 Windows 性能工具包 (WPT)。您可以从 Windows SDK或 ADK下载页面下载。Windows SDK 非常庞大,您不一定需要它的所有部分。在本例中,我们只启用了 Windows 性能工具包的复选框。您可以将 WPT 作为自己应用程序的一部分进行再分发。
7.6.2 您可以用它做什么?
- 通过 125 微秒到 10 秒的可配置 CPU 采样率识别热点。默认值为 1 毫秒,运行时开销约为 5-10%。
- 确定是什么阻塞了某个线程以及阻塞了多长时间(例如,延迟事件信号、不必要的线程休眠等)。
- 检查磁盘处理读/写请求的速度,并找出启动该工作的原因。
- 检查文件访问性能和模式(包括导致无磁盘 IO 的缓存读/写)。
- 跟踪 TCP/IP 协议栈,查看数据包如何在网络接口和计算机之间流动。
通过可配置的调用堆栈跟踪(内核和用户模式调用堆栈合并),所有进程的上述项目都会在全系统范围内被记录。您还可以添加自己的 ETW 提供商,将全系统范围的跟踪与您的应用程序行为关联起来。您可以通过检测代码来扩展收集的数据量。例如,您可以在源代码中的函数中注入进入/离开 ETW 跟踪钩子,以测量某个函数的执行频率。
7.6.3 不能做的事
- ETW 跟踪对检查 CPU 微体系结构瓶颈没有帮助。为此,请使用特定于供应商的工具,如 Intel VTune、AMD uProf、Apple Instruments 等。
ETW 跟踪可捕获系统级所有进程的动态,但可能会产生大量数据。例如,捕获线程上下文切换数据以观察各种等待和延迟,每分钟可轻松生成 1-2 GB 的数据。这就是为什么在不覆盖以前存储的跟踪数据的情况下,连续数小时记录大容量事件是不现实的。
如果您想了解有关 ETW 的更多信息,附录 D 中有更详细的讨论。我们将探讨记录和分析 ETW 的工具,并介绍一个调试程序缓慢启动的案例研究。
7.7 专业剖析器和混合剖析器
目前探讨的大多数工具都属于采样剖析器。当您想识别代码中的热点时,这些工具非常有用,但在某些情况下,它们可能无法提供分析所需的粒度。根据剖析器的采样频率和程序的行为,大多数函数的运行速度都可能快到无法在剖析器中显示。在某些情况下,您可能需要手动定义程序中需要持续测量的部分。例如,视频游戏平均以每秒 60 帧 (FPS) 的速度渲染帧(屏幕上显示的最终图像);有些显示器允许高达 144 FPS。在 60 FPS 的情况下,每帧只需 16 毫秒就能完成工作,然后进入下一帧。
开发人员会特别注意超过这一临界值的帧数,因为这会导致游戏出现明显的卡顿,破坏玩家的游戏体验。采样剖析器很难捕捉到这种情况。开发人员创建的剖析器可提供在特定环境中有用的功能,通常带有标记 API,您可以用它来手动检测代码。这样,您就可以观察特定函数或代码块(后称为区域)的性能。就游戏行业而言,该领域有多种工具:一些直接集成到虚幻等游戏引擎中,而另一些则作为外部库和工具提供,可以集成到您的项目中。最常用的剖析器包括 Tracy、RAD Telemetry、Remotery 和 Optick(仅限 Windows)。接下来,我们将展示Tracy因为它似乎是最受欢迎的项目之一;不过,这些概念也适用于其他剖析器。
7.7.1 使用 Tracy 可以做什么
- 调试程序中的性能异常,例如慢帧。
- 将慢速事件与系统中的其他事件关联起来。
- 查找慢速事件的共同特征。
- 检查源代码和程序集。
- 在代码更改后进行 “前后 ”比较。
7.7.2 Tracy 不能做的事
- 检查 CPU 微架构问题,例如收集各种性能计数器。
7.7.3 案例研究: 使用 Tracy 分析慢速帧
在本例中,我们将使用 ToyPathTracer程序,这是一个简单的路径追踪器,是一种简化的光线追踪技术,可将每像素数千条光线射入场景,从而渲染出逼真的图像。为了处理一帧图像,该程序将每行像素的处理分配给一个单独的线程。
为了模拟 Tracy 可以帮助诊断问题根源的典型场景,我们手动修改了代码,使某些帧比其他帧消耗更多时间。清单 7.1 显示了代码大纲以及添加的 Tracy 工具。请注意,我们是随机选择帧来减速的。此外,我们还包含了 Tracy 的头文件,并在要跟踪的函数中添加了 ZoneScoped 和 FrameMark 宏。插入 FrameMark 宏可在剖析器中识别单个帧。每帧的持续时间将在时间轴上显示,这非常有用。
每个帧可以包含多个区域,由 ZoneScoped 宏指定。与帧类似,一个区域也有许多实例。每当我们进入一个区域,Tracy 就会捕捉该区域新实例的统计数据。ZoneScoped 宏会在堆栈上创建一个 C++ 对象,记录该对象生命周期范围内代码的运行时活动。Tracy 将此范围称为区域。在区域入口处,会捕获当前的时间戳。一旦函数退出,对象的析构函数将记录一个新的时间戳,并将此定时数据与函数名称一起存储。
#include "tracy/Tracy.hpp"
void TraceRowJob() {
ZoneScoped;
if (frameCount == randomlySelected)
DoExtraWork();
// ...
}
void RenderFrame() {
ZoneScoped;
for (...) {
TraceRowJob();
}
FrameMark;
}
Tracy 有两种运行模式:一种是存储所有时序数据,直到剖析器连接到应用程序(默认模式);另一种是仅在剖析器连接后才开始记录。后一种模式可以在编译应用程序时通过指定 TRACY_ON_DEMAND 预处理器宏来启用。如果要发布可根据需要进行剖析的应用程序,则应首选这种模式。使用此选项,可以将跟踪代码编译到应用程序中,除非附加剖析器,否则几乎不会对运行中的程序造成任何开销。剖析器是一个独立的应用程序,可连接到运行中的应用程序,捕获并显示实时剖析数据,也称为 “飞行记录器 ”模式。剖析器可以在单独的机器上运行,这样就不会干扰正在运行的应用程序。但请注意,这并不意味着仪器代码造成的运行时开销会消失。它仍然存在,只是在这种情况下避免了可视化数据的开销。
我们使用 Tracy 调试程序,并找出某些帧比其他帧慢的原因。数据是在配备 Ryzen 7 5800X 处理器的 Windows 11 机器上采集的。程序是用 MSVC 19.36.32532 编译的。Tracy 的图形界面相当丰富,但遗憾的是包含的细节太多,无法在一张截图上一一呈现,因此我们将其分成几块。在顶部,有一个时间轴视图,如下图所示,经过裁剪以适合页面大小。它只显示了第 76 帧的一部分,渲染耗时 44.1 毫秒。在该图中,我们可以看到主线程和在该帧中处于活动状态的五个 WorkerThreads。包括主线程在内的所有线程都在执行工作,以推进最终图像的渲染进度。如前所述,每个线程都在 TraceRowJob 区域内处理一行像素。每个 TraceRowJob 区域实例都包含许多不可见的小区域。Tracy 会折叠内部区域,只显示折叠实例的数量。例如,在主线程中的第一个 TraceRowJob 下,数字 4,109 就是这个意思。
请注意嵌套在 TraceRowJob 区域下的 DoExtraWork 区域实例。这一观察结果已经能让我们有所发现,但在实际应用中可能就不那么明显了。我们暂时不讨论这个问题。

该视图显示了主线程和五个工作线程正在渲染一个帧。在主面板的正上方,有一个直方图显示所有记录帧的时间(见下图)。通过直方图可以更容易地发现那些完成时间比平均时间长的帧。在本例中,大多数帧的时间约为 33 毫秒(黄色条)。但是,有些帧的耗时比平均耗时长,因此用红色标出。如截图所示,当鼠标指向直方图中的条形图时,会显示一个工具提示,显示特定帧的详细信息。在本例中,我们显示的是最后一帧的详细信息。

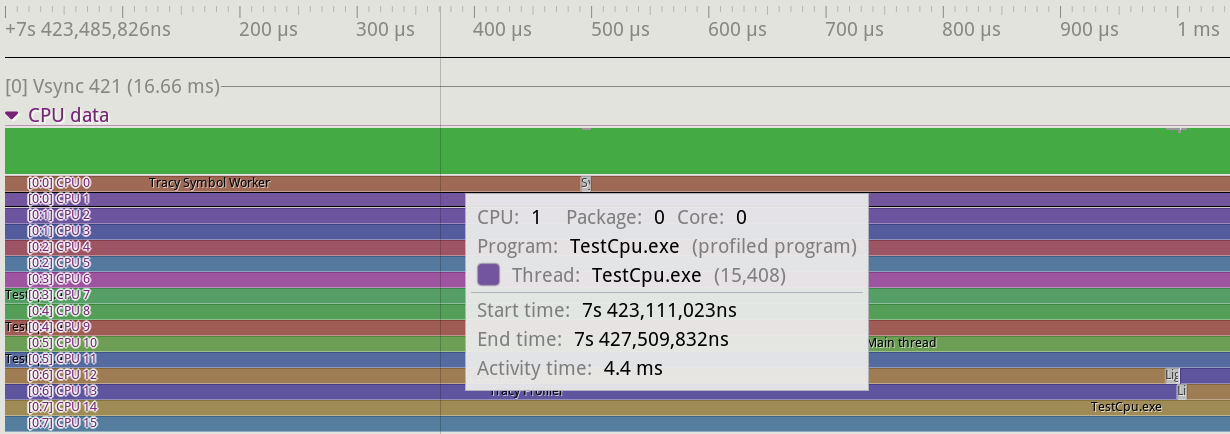
下图展示了剖析器的 CPU 数据部分。该区域显示特定线程在哪个内核上执行,还显示上下文切换。该部分还将显示 CPU 上运行的其他程序。如图所示,将鼠标悬停在 CPU 数据视图的特定部分时,会显示特定线程的详细信息。详细信息包括线程运行的 CPU、父程序、单个线程和时序信息。我们可以看到,在整个程序运行过程中,TestCpu.exe 线程仅在 CPU 1 上运行了 4.4 毫秒。
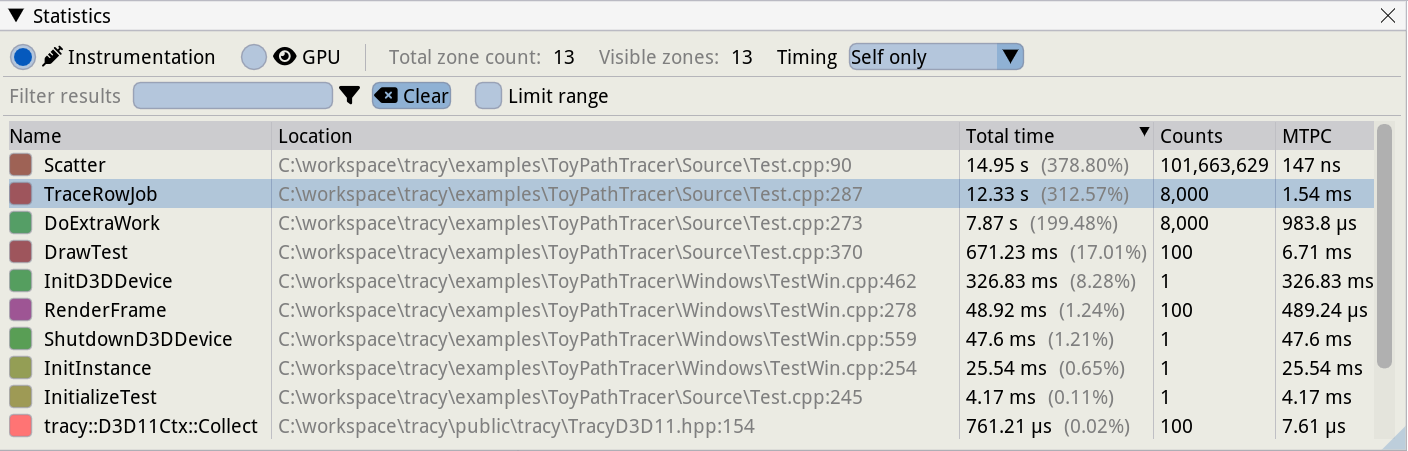
接下来的面板提供了程序的运行时间(热点)信息。下图是 Tracy 统计窗口的截图。我们可以查看记录的数据,包括给定函数的总活动时间、174 次活动时间、174 次活动次数和 174 次活动时间。
您可以查看每个 CPU 内核在任何特定时刻的工作情况。还可以在主视图中选择一个时间范围,过滤与时间间隔相对应的信息。
我们展示的最后一组面板可以让我们更深入地分析单个区域实例。点击主时间轴视图或 CPU 数据视图中的任何区域实例后,Tracy 会打开一个区域信息窗口,显示该区域实例的详细信息。它显示了区段本身或其子区段消耗了多少执行时间。在此示例中,执行 TraceRowJob 函数耗时 19.24 毫秒,但函数本身(不包括其调用)的耗时为 1.36 毫秒,仅占 7%。其余时间由子区消耗。
不难发现,调用 DoExtraWork 占用了大部分时间,在 19.24 毫秒中占了 16.99 毫秒(见图 7.12 左侧面板)。请注意,此特定 TraceRowJob 实例的运行时间几乎是平均情况的 4.4 倍。
中奖了!我们找到了其中一个运行缓慢的实例,在这个实例中,TraceRowJob 函数因为一些额外的工作而运行缓慢。一种方法是单击 DoExtraWork 行来检查此区域实例。这将更新 “区信息 ”视图,显示 DoExtraWork 实例的详细信息,以便我们深入了解导致性能问题的原因。该视图还显示了源文件和代码行,而代码行正是该区的起始位置。因此,另一种策略是检查源代码,以了解当前 TraceRowJob 实例比平常花费更多时间的原因。
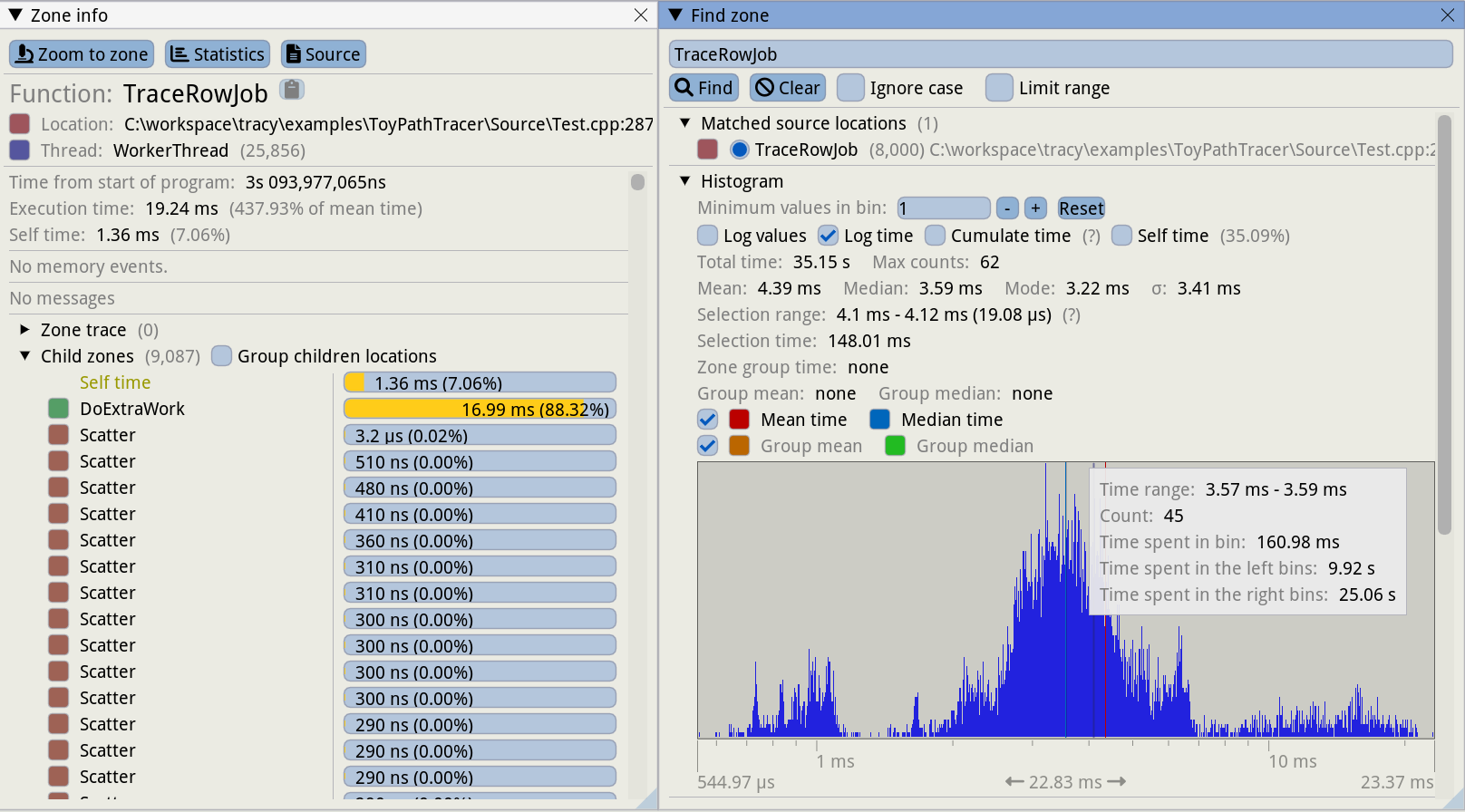
让我们看看这是否是所有慢帧的共同问题。单击统计按钮,将显示查找区域面板(上图右侧所示)。在这里,我们可以看到汇总所有区实例的时间直方图。这对于确定执行函数时的变化程度特别有用。观察右侧的直方图,我们会发现 TraceRowJob 函数的中位持续时间为 3.59 毫秒,大多数调用的持续时间在 1 到 7 毫秒之间。不过,也有少数情况持续时间超过 10 毫秒,峰值为 23 毫秒。请注意,时间轴是对数。查找区域 “窗口还提供了其他数据点,包括检查区域的平均值、中位数和标准偏差。
现在,我们可以检查其他慢速实例,找出它们之间的共同点,这将有助于我们确定问题的根本原因。从该视图中,您可以选择其中一个运行缓慢的区段。这将在 Zone Info 窗口中更新该区实例的详细信息,单击 Zoom to zone(缩放至区)按钮后,主窗口将聚焦于这个运行缓慢的区。在这里,我们可以检查所选的 TraceRowJob 实例是否与我们刚才分析的那个实例具有相似的特征。
Tracy 的其他功能 Tracy 可监控整个系统的性能,而不仅仅是应用程序本身。
它的行为也类似于传统的采样剖析器,因为它会报告与被剖析程序同时运行的应用程序的数据。该工具通过跟踪内核上下文切换来监控线程迁移和空闲时间(管理员权限)。区域统计(调用次数、时间、直方图)是精确的,因为 Tracy 会捕捉每个区域的进入/退出,但系统级数据和源代码级数据是采样的。
在示例中,我们对代码中有趣的区域进行了手动标记。不过,这样做并不是开始使用 Tracy 的严格要求。您可以对未修改的应用程序进行剖析,然后在知道哪里需要仪器时再添加仪器。Tracy 还提供了许多其他功能,在本概述中无法一一介绍。下面是一些值得注意的功能:
- 跟踪内存分配和锁。
- 会话比较。这对于确保变更带来预期收益至关重要。可以加载两个剖析会话,比较更改前后的区域数据。
- 源代码和汇编视图。如果调试符号可用,Tracy 还能像英特尔 VTune 和其他剖析器一样,显示源代码和相关程序集中的热点。
与英特尔 VTune 和 AMD uProf 等其他工具相比,使用 Tracy 无法获得同等水平的 CPU 微体系结构洞察力(如各种性能事件)。这是因为 Tracy 无法利用特定平台的硬件特性。使用 Tracy 进行剖析的开销取决于你激活了多少个区域。Tracy 的作者提供了他在一个进行图像压缩的程序上测出的一些数据:使用两种不同的压缩方案,开销分别为 18% 和 34%。总共测试了 2 亿个区,每个区的平均开销为 2.25 ns。该测试使用了一个非常热的函数。在其他情况下,开销会低得多。虽然可以将开销保持在较低水平,但在确定要对哪些代码段进行剖析时仍需谨慎,尤其是在决定将其用于生产时。
来源链接:https://www.cnblogs.com/testing-/p/18722460





没有回复内容