
如何在 .NET 中 使用 ANTLR4
目录
- 前言
- ANTLR4 简介
- 语法分析基本概念
- 如何使用 ANTLR4
- 1. 安装 Antlr4.Runtime.Standard 包
- 2. 编写 ANTLR4 的语法规则文件
- 3. 生成语法分析器
- 直接使用 ANTLR4 官方提供的工具来生成语法分析器。
- 借助 Antlr4BuildTasks 项目自动生成语法分析器。
- 4. 编写代码来使用语法分析器
- 使用 Visitor 实现
- 使用 Listener 实现
- 构建自定义 AST 以解决复杂问题
- 参考资料
前言#
本文将介绍如何在 .NET 中使用 ANTLR4 构建语法分析器。由于篇幅限制,本文不会深入讲解 ANTLR4 的语法规则,相关内容可参考 ANTLR4 的官方文档或其他资料。本文将涵盖以下内容:ANTLR4 的开发环境搭建、语法规则编写、语法分析器生成以及语法分析器的使用。
本文中的例子相对简单,且未经过详细测试,旨在演示 ANTLR4 的基本用法。
实际开发的过程中,建议先去官方的这个 repo 查看是否已经有现成的 grammar 文件可以使用:https://github.com/antlr/grammars-v4
文中的代码示例已上传到 GitHub:
https://github.com/eventhorizon-cli/Antlr4Demo
ANTLR4 简介#
ANTLR(Another Tool for Language Recognition)是一个强大的语法分析器生成器,属于编译技术中的前端工具。它可以用来构建语法分析器,并借此开发编译器、解释器和翻译器等。
ANTLR4 是 ANTLR 的最新版本,它支持多种编程语言的语法分析器生成,包括 Java、C#、Python、JavaScript 等。ANTLR4 的语法规则使用一种类似于正则表达式的语法来定义,可以很方便地描述复杂的语法结构。
ANTLR4 的工作流程如下:
- 编写语法规则:通常使用 ANTLR4 的语法规则文件(.g4 文件)来定义语法规则。
- 生成语法分析器:使用 ANTLR4 工具来生成目标语言的语法分析器。
- 使用语法分析器进行语法分析:编写代码来使用生成的语法分析器进行语法分析。分析的结果通常是一个抽象语法树(AST)。
- 访问 AST:可以使用访问者模式(Visitor Pattern)或者监听器模式(Listener Pattern)来访问 AST,进行后续的处理,例如解释执行、编译等。
语法分析基本概念#
语法分析的过程分为两个阶段:词法分析(Lexical Analysis)和语法分析(Syntax Analysis)。
-
词法分析:将字符聚集为单词或者符号(token),例如将
1 + 2分解为1、+、2三个 token。 -
语法分析:输入的 token 被组织成一个树形结构,称为抽象语法树(Abstract Syntax Tree,AST),它表示了输入的语法结构。树的每个节点表示一个语法单元,这个单元的构成规则就叫做语法规则。每个节点还可以有子节点。
例如,表达式 1 + 2 * 3 的抽象语法树如下:
+ / \ 1 * / \ 2 3 如何使用 ANTLR4#
1. 安装 Antlr4.Runtime.Standard 包#
我们以加减乘除四则运算为例来介绍如何使用 ANTLR4 来构建语法分析器。
新建一个C#项目,在项目中添加 Antlr4.Runtime.Standard 包。
dotnet add package Antlr4.Runtime.Standard 2. 编写 ANTLR4 的语法规则文件#
接着我们需要编写一个 ANTLR4 的语法规则文件,文件的后缀名为 .g4,例如 Arithmetic.g4,文件的内容如下:
grammar Arithmetic; // grammar name 需要和文件名一致 // 语法规则 // op=('*'|'/') 表示 op 将 ‘*’ 或者 ‘/’ 标记为一个操作符号 // # MulDiv 将这个规则命名为 MulDiv,访问 AST 时会用到 expr: expr op=('*'|'/') expr # MulDiv | expr op=('+'|'-') expr # AddSub | INT # Int | '(' expr ')' # Parens ; // 词法规则 INT : [0-9]+ ; WS : [ \t\r\n]+ -> skip ; // 表示忽略空格 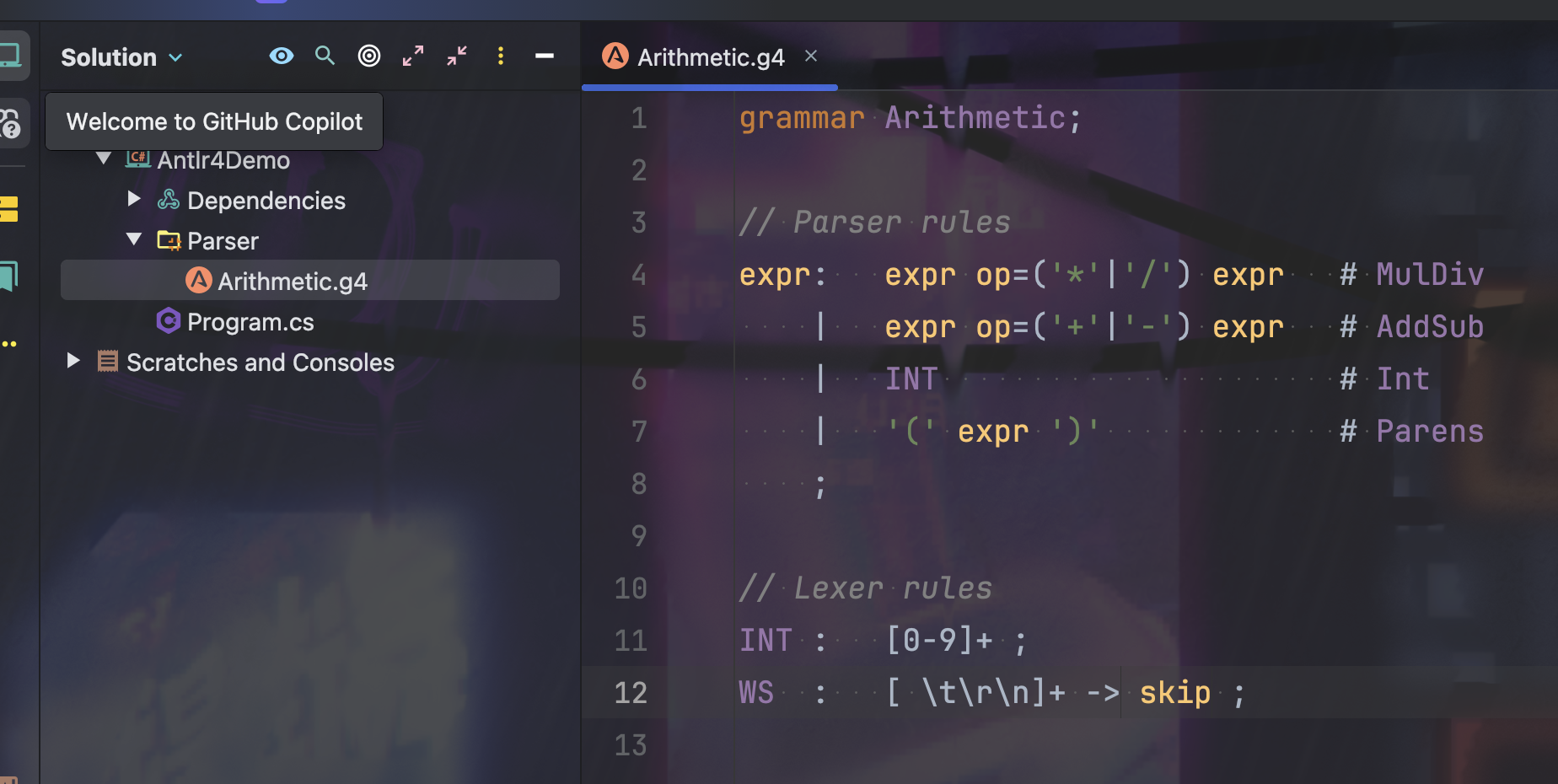
g4 文件的内容分为两部分:词法规则(Lexer Rules) 和 语法规则(Parser Rules)。
词法规则是用来定义词法单元的,例如数字、运算符、括号等。词法规则通常以大写字母开头。
语法规则是用来定义语法结构的,例如表达式、语句等。语法规则通常以小写字母开头。
在上面的例子中,我们定义了一个简单的四则运算语法规则,支持加减乘除和括号运算。我们还定义了一个整数类型的词法规则 INT,表示一个或多个数字。
expr 规则表示一个表达式,用 | 分隔的部分表示或的关系,例如 expr op=('*'|'/') expr | expr op=('+'|'-') expr 表示一个表达式可以是乘法或除法,也可以是加法或减法。
而加减乘除的优先级通过定义的顺序来决定,乘除法的规则在加减法之前,所以乘除法的优先级高于加减法。
在语法规则中,我们还可以使用 # 来为规则命名,例如 # MulDiv,表示这个规则的名字是 MulDiv。这个名字在访问 AST 时会用到。
规则支持递归定义,例如 expr: expr op=('*'|'/') expr 。
这边因为举的例子比较简单,可以直接在一个 g4 文件中同时定义语法规则和词法规则。对于复杂的语法规则,可以将语法规则和词法规则分开定义。
在 Rider 或 VS Code 中安装 ANTLR4 的插件,可以检查语法规则的正确性。
在 Rider 中安装 ANTLR4 的插件后,可以在 g4 文件选中 expr 规则,右键选择 Test Rule expr 来测试语法规则是否正确。
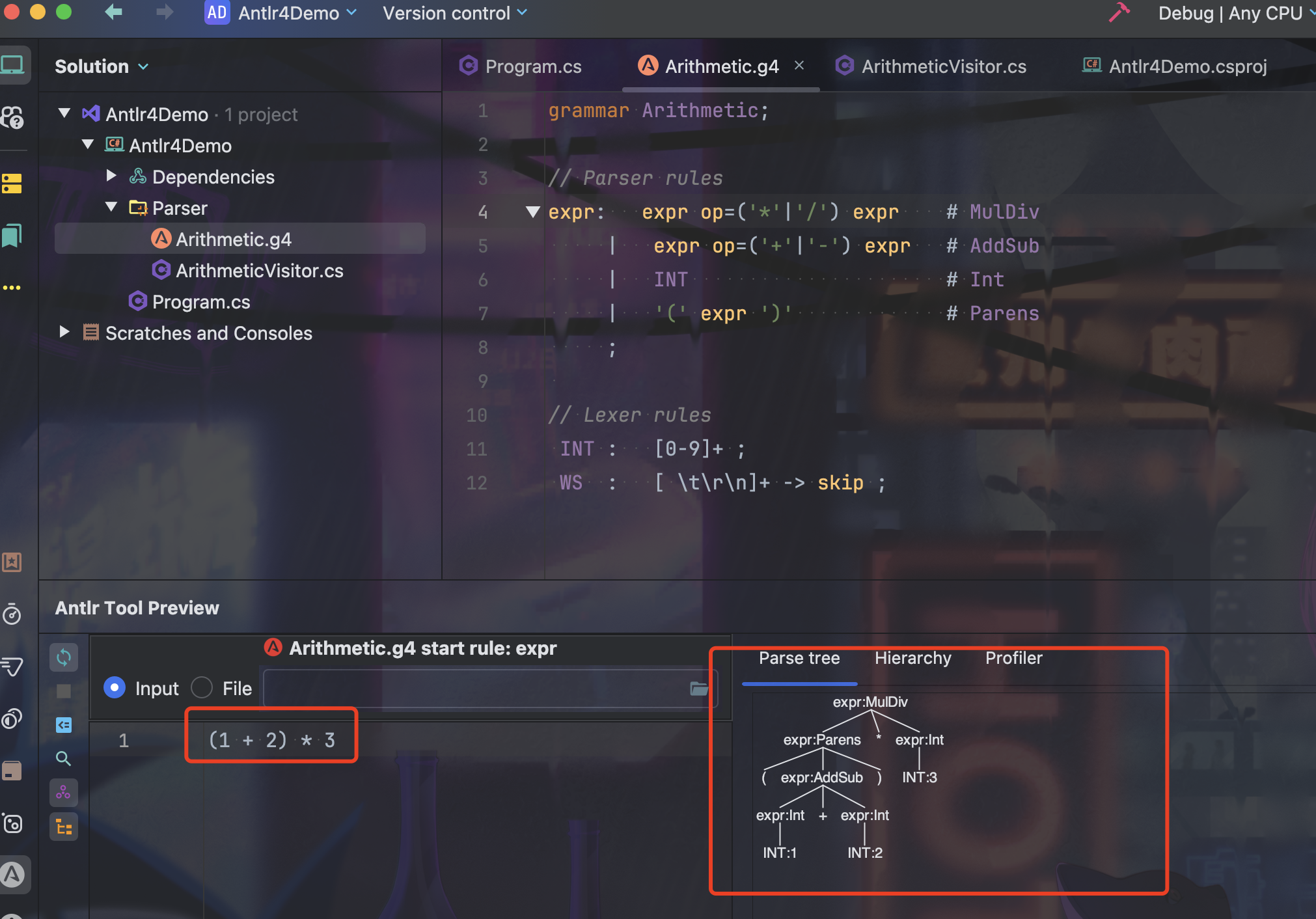
左侧的输入框中输入要测试的表达式,右侧的输出框中会以树形结构的方式显示语法分析的结果。
3. 生成语法分析器#
ANTLR4 是基于 Java 开发的,所以我们需要安装 Java 运行环境才能使用 ANTLR4 工具来生成语法分析器。
我们有两种方式来使用 ANTLR4 生成语法分析器,优先推荐使用 Antlr4BuildTasks 项目来自动生成语法分析器。
直接使用 ANTLR4 官方提供的工具来生成语法分析器。#
首先,我们需要下载 ANTLR4 工具,可以从 ANTLR4 的官方网站下载:https://www.antlr.org/download.html
写本文时,最新的版本是 4.13.2,下载地址为:
https://www.antlr.org/download/antlr-4.13.2-complete.jar
本文为方便演示,将 antlr-4.13.2-complete.jar 下载到 g4 文件所在的目录下。
接着就可以使用 Java 运行 ANTLR4 工具来生成语法分析器。
java -jar antlr-4.13.2-complete.jar -Dlanguage=CSharp Arithmetic.g4 其中,Arithmetic.g4 是我们编写的语法规则文件,-Dlanguage=CSharp 表示生成 C# 语言的语法分析器。
执行上面的命令后,会生成一些文件,其中包括 ArithmeticLexer.cs、ArithmeticParser.cs。
后面我们就可以使用生成的语法分析器来进行语法分析了。
借助 Antlr4BuildTasks 项目自动生成语法分析器。#
上面的方式需要手动下载 ANTLR4 工具,然后使用 Java 运行 ANTLR4 工具来生成语法分析器,还会生成一些必须需要添加到项目中的文件。这样的方式比较繁琐,我们可以使用 Antlr4BuildTasks 项目来自动生成语法分析器。
Antlr4BuildTasks 的 GitHub 地址为:
https://github.com/kaby76/Antlr4BuildTasks
Antlr4BuildTasks 是一个 MSBuild 任务,它可以自动下载 ANTLR4 工具,然后使用 ANTLR4 工具来生成语法分析器,最后将生成的语法分析器添加到项目中。它也会尝试下载 java 运行环境,如果 build 过程中出现错误,可以尝试手动安装全局的 java 运行环境。
除了安装 Antlr4BuildTasks 的包之外,我们还需要在项目文件(.csproj)中添加一些配置,完整 .csproj 文件如下:
<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>net9.0</TargetFramework> <ImplicitUsings>enable</ImplicitUsings> <Nullable>enable</Nullable> </PropertyGroup> <ItemGroup> <PackageReference Include="Antlr4.Runtime.Standard" Version="4.13.1"/> <PackageReference Include="Antlr4BuildTasks" Version="12.8.0" PrivateAssets="all"/> </ItemGroup> <ItemGroup> <Antlr4 Include="**\*.g4"/> </ItemGroup> </Project> <Antlr4 Include="**\*.g4"/> 表示将项目中所有的 .g4 文件都添加到 Antlr4 任务中。当然也可以指定具体的 .g4 文件路径。
在 build 项目时,Antlr4BuildTasks 会将 .g4 文件编译成的文件放在 obj 文件夹下,我们可以在 obj 文件夹下找到生成的语法分析器。
obj 文件夹下的文件是临时文件,会在每次 build 时重新生成,我们不需要将 obj 文件夹下的文件添加到项目中。
4. 编写代码来使用语法分析器#
接下来我们就可以编写代码来使用生成的语法分析器了。
访问 AST 的方式有两种:Visitor和 Listener。我们可以选择其中一种方式来访问 AST。
ANTLR4 会为我们生成一个 Parser,Parser 在遍历 AST 时会调用 Visitor 的 VisitXXX 方法,或者 Listener 的 EnterXXX 和 ExitXXX 方法。
使用 Visitor 实现#
下面我们以访问者模式为例,编写一个简单的 C# 程序来使用语法分析器。
ANTLR4 会为我们生成一个 ArithmeticBaseVisitor 类,我们可以继承这个类来完成对 AST 的访问。
在前面的 g4 文件中,我们为每个 AST 节点定义了一个名字, MulDiv、AddSub、Int、Parens 这些,对应 ArithmeticBaseVisitor 中的 VisitMulDiv、VisitAddSub、VisitInt、VisitParens 方法。
我们可以通过重写这些方法来实现对 AST 的访问:
public class ArithmeticVisitor : ArithmeticBaseVisitor<int> { // 解析乘除法 public override int VisitMulDiv(ArithmeticParser.MulDivContext context) { // context 包含了当前节点的信息 // context.expr(0) 和 context.expr(1) 分别表示乘除法的两个操作数 // 访问子节点,获取操作数的值 int left = Visit(context.expr(0)); int right = Visit(context.expr(1)); return context.op.Text switch { "*" => left * right, "/" => left / right, _ => throw new NotSupportedException($"Operator {context.op.Text} is not supported.") }; } // 解析加减法 public override int VisitAddSub(ArithmeticParser.AddSubContext context) { int left = Visit(context.expr(0)); int right = Visit(context.expr(1)); return context.op.Text switch { "+" => left + right, "-" => left - right, _ => throw new NotSupportedException($"Operator {context.op.Text} is not supported.") }; } // 去掉括号,访问括号内的表达式 public override int VisitParens(ArithmeticParser.ParensContext context) => Visit(context.expr()); // 解析整数 public override int VisitInt(ArithmeticParser.IntContext context) => int.Parse(context.INT().GetText()); } 定义好了 visitor 之后,我们就可以使用它来解析表达式了。
Console.WriteLine(Evaluate("1 + 2 * 3")); // 7 Console.WriteLine(Evaluate("(1 + 2) * 3")); // 9 int Evaluate(string expression) { // 创建词法分析器 var lexer = new ArithmeticLexer(new AntlrInputStream(expression)); var tokens = new CommonTokenStream(lexer); // 创建语法分析器,传入词法分析器的输出的token流 var parser = new ArithmeticParser(tokens); // 用 visitor 模式解析表达式 var visitor = new ArithmeticVisitor(); return visitor.Visit(parser.expr()); } 使用 Listener 实现#
ANTLR4 的 Parser 在遍历 AST 时会调用 Listener 的 EnterXXX 和 ExitXXX 方法,我们可以通过重写这些方法来实现对 AST 的访问。
EnterXXX 方法在进入节点时调用,ExitXXX 方法在离开节点时调用。
我们可以在 ExitXXX 方法里将操作数压入栈中,下次访问时就可以从栈中弹出操作数进行计算。
public class ArithmeticListener : ArithmeticBaseListener { // 使用栈来存储操作数 private readonly Stack<int> _stack = new(); public int Result => _stack.Pop(); public override void ExitMulDiv(ArithmeticParser.MulDivContext context) { int right = _stack.Pop(); int left = _stack.Pop(); int result = context.op.Text switch { "*" => left * right, "/" => left / right, _ => throw new NotSupportedException($"Operator {context.op.Text} is not supported.") }; _stack.Push(result); } public override void ExitAddSub(ArithmeticParser.AddSubContext context) { int right = _stack.Pop(); int left = _stack.Pop(); int result = context.op.Text switch { "+" => left + right, "-" => left - right, _ => throw new NotSupportedException($"Operator {context.op.Text} is not supported.") }; _stack.Push(result); } public override void ExitParens(ArithmeticParser.ParensContext context) { // ExitParens 方法在这里不需要做任何操作,因为我们已经在 MulDiv 和 AddSub 中处理了括号内的表达式 } public override void ExitInt(ArithmeticParser.IntContext context) { int value = int.Parse(context.INT().GetText()); _stack.Push(value); } } Console.WriteLine(Evaluate("1 + 2 * 3")); // 7 Console.WriteLine(Evaluate("(1 + 2) * 3")); // 9 int Evaluate(string expression) { // 创建词法分析器 var lexer = new ArithmeticLexer(new AntlrInputStream(expression)); var tokens = new CommonTokenStream(lexer); // 创建语法分析器,传入词法分析器的输出的token流 var parser = new ArithmeticParser(tokens); var listener = new ArithmeticListener(); // 解析表达式 parser.AddParseListener(listener); parser.expr(); // 获取结果 return listener.Result; } 构建自定义 AST 以解决复杂问题#
上面的例子中,我们在遍历 AST 时直接计算了表达式的值,这种方式在简单的表达式中是可以的,但如果表达式的处理逻辑比较复杂,更建议将 原始AST 转换成一个我们自定义的 AST,然后在后续的处理逻辑中使用这个自定义的 AST,将解析和处理逻辑分开,可以让代码更清晰,功能也容易实现。
下面我们定义一个比加减乘除法更复杂的需求:指定一个文件夹,用 sql 语句来查询文件夹下的 csv 文件,支持过滤条件、排序等操作。表名是文件名,字段名是 csv 文件的列名。
为简化起见,我们只支持简单的查询语句,支持 SELECT、FROM、WHERE、ORDER BY 等关键字。数据类型仅用字符串类型做示范,支持的过滤方式有 =、!=、LIKE,过滤条件之间只能用 AND 连接,排序方式支持 ASC 和 DESC。
这里我们将词法规则和语法规则分开定义,词法规则定义在 SqlLexer.g4 文件中,语法规则定义在 SqlParser.g4 文件中。
SqlLexer.g4 文件的内容如下:
lexer grammar SqlLexer; options { caseInsensitive = true; // 忽略大小写 } // 关键字 SELECT : 'SELECT' ; FROM : 'FROM' ; WHERE : 'WHERE' ; ORDER : 'ORDER' ; BY : 'BY' ; ASC : 'ASC' ; DESC : 'DESC' ; AND : 'AND' ; OR : 'OR' ; COMMA : ',' ; STAR : '*' ; // 运算符 EQ : '=' ; NEQ : '!=' ; LIKE : 'LIKE' ; // 字面量 STRING_LITERAL : '\'' ( ~('\'' | '\\') | '\\' . )* '\'' // 字符串字面量 ; // 标识符 IDENTIFIER : [a-z_][a-z0-9_]* // 用于表名、列名等 ; WS : [ \t\r\n]+ -> skip ; // 忽略空格 SqlParser.g4 文件的内容如下:
parser grammar SqlParser; options { tokenVocab=SqlLexer; } query : SELECT selectList FROM tableName (WHERE whereClause)? (ORDER BY orderByClause)? ; selectList : columnName (COMMA columnName)* | STAR ; columnName: IDENTIFIER ; tableName: IDENTIFIER ; whereClause : whereCondition (AND whereCondition)* ; whereCondition : columnName op=(EQ | NEQ) STRING_LITERAL | columnName op=LIKE STRING_LITERAL ; orderByClause : orderByCondition (COMMA orderByCondition)* ; orderByCondition : columnName (ASC | DESC)? ; 定义完后可以在 Rider 中使用 ANTLR4 的插件来检查语法规则的正确性,选中 query 规则,右键选择 Test Rule query 来测试语法规则是否正确。
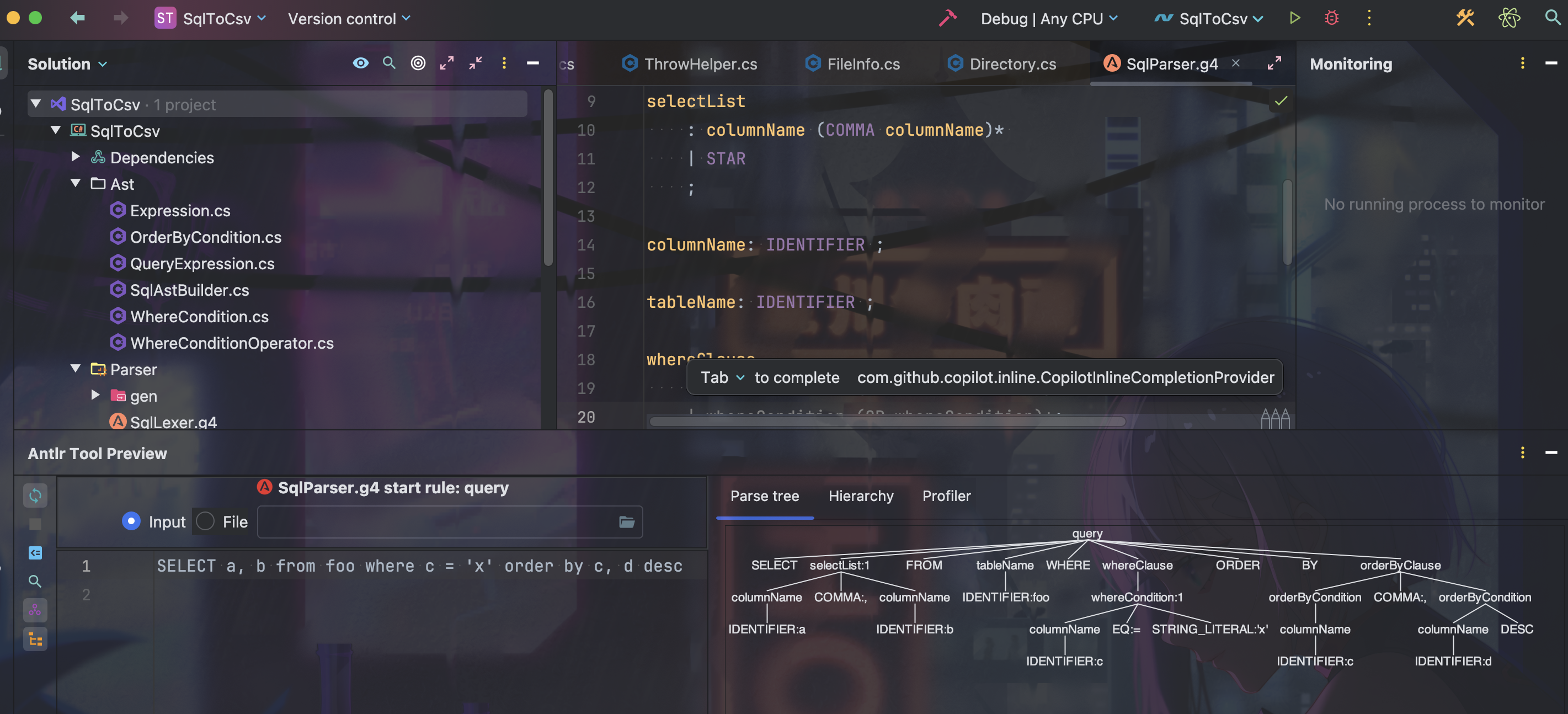
下面我们先定义一组类型用来表示 SQL 语句的 AST:
public abstract class Expression; public class QueryExpression : Expression { public required string TableName { get; init; } public required bool SelectAll { get; init; } public required IEnumerable<string> SelectList { get; init; } public required IEnumerable<WhereCondition> WhereConditions { get; init; } public required IEnumerable<OrderByCondition> OrderByConditions { get; init; } } public class WhereCondition : Expression { public required string ColumnName { get; init; } public WhereConditionOperator Operator { get; init; } public required string Value { get; init; } } public enum WhereConditionOperator { Equal, NotEqual, StartsWith, EndsWith, Contains } public class OrderByCondition : Expression { public required string ColumnName { get; init; } public bool IsDescending { get; init; } } 我们定义一个 SqlAstBuilder 类来实现对 SQL 语句的解析:
public class SqlAstBuilder : SqlParserBaseVisitor<QueryExpression> { public override QueryExpression VisitQuery(SqlParser.QueryContext context) { var selectList = context.selectList(); bool selectAll = selectList?.STAR() != null; var columns = selectList?.columnName() .Select(c => c.GetText()) .ToList() ?? []; var tableName = context.tableName().GetText(); var whereConditions = context.whereClause() ?.whereCondition() .Select(c => { var stringValue = c.STRING_LITERAL().GetText().Trim('\''); var opText = c.op.Text.ToUpperInvariant(); var op = WhereConditionOperator.Equal; if (opText == "=") { op = WhereConditionOperator.Equal; } else if (opText == "!=") { op = WhereConditionOperator.NotEqual; } else if (opText == "LIKE") { if (stringValue.StartsWith("%") && stringValue.EndsWith("%")) { op = WhereConditionOperator.Contains; stringValue = stringValue.Substring(1, stringValue.Length - 2); } else if (stringValue.StartsWith("%")) { op = WhereConditionOperator.EndsWith; stringValue = stringValue.Substring(1); } else if (stringValue.EndsWith("%")) { op = WhereConditionOperator.StartsWith; stringValue = stringValue.Substring(0, stringValue.Length - 1); } } else { throw new NotSupportedException($"Operator {c.op.Text} is not supported."); } return new WhereCondition { ColumnName = c.columnName().GetText(), Operator = op, Value = stringValue }; }) .ToList() ?? []; var orderByConditions = context.orderByClause() ?.orderByCondition() .Select(c => new OrderByCondition { ColumnName = c.columnName().GetText(), IsDescending = c.DESC() != null }) .ToList() ?? []; return new QueryExpression { SelectAll = selectAll, SelectList = columns, TableName = tableName, WhereConditions = whereConditions, OrderByConditions = orderByConditions }; } } SqlToCsvEngine 类用来执行 SQL 语句并从 CSV 文件中读取数据:
public class SqlToCsvEngine(DirectoryInfo csvDirectory) { public IEnumerable<Dictionary<string, string>> ExecuteQuery(string query) { // 创建词法分析器 var lexer = new SqlLexer(new AntlrInputStream(query)); // 创建语法分析器,传入词法分析器的输出的token流 var tokens = new CommonTokenStream(lexer); var parser = new SqlParser(tokens); // 将查询语句解析为自定义的 AST var astBuilder = new SqlAstBuilder(); var expression = astBuilder.Visit(parser.query()); // 处理 AST,执行查询 if (expression is not { } queryExpression) { throw new InvalidOperationException("Expected a query expression"); } // 读取 CSV 文件 var csvData = ReadCsv(queryExpression.TableName); // 过滤数据 var filteredData = csvData.Where(row => { // 处理 WHERE 条件 // 处理 WHERE 条件 bool isMatch = true; foreach (var condition in queryExpression.WhereConditions) { if (row.TryGetValue(condition.ColumnName, out var value)) { isMatch = condition.Operator switch { WhereConditionOperator.Equal => value == condition.Value, WhereConditionOperator.NotEqual => value != condition.Value, WhereConditionOperator.StartsWith => value.StartsWith(condition.Value), WhereConditionOperator.EndsWith => value.EndsWith(condition.Value), WhereConditionOperator.Contains => value.Contains(condition.Value), _ => throw new ArgumentOutOfRangeException() }; } else { throw new InvalidOperationException($"Column {condition.ColumnName} does not exist in CSV file."); } } return isMatch; }); // 处理 ORDER BY 条件 foreach (var orderByCondition in queryExpression.OrderByConditions) { Func<IEnumerable<Dictionary<string, string>>, Func<Dictionary<string, string>, string>, IEnumerable<Dictionary<string, string>>> orderByFunc; if (filteredData is IOrderedEnumerable<Dictionary<string, string>> orderedData) { orderByFunc = orderByCondition.IsDescending ? (_, keySelector) => orderedData.ThenByDescending(keySelector) : (_, keySelector) => orderedData.ThenBy(keySelector); } else { orderByFunc = orderByCondition.IsDescending ? Enumerable.OrderByDescending : Enumerable.OrderBy; } filteredData = orderByFunc(filteredData, row => { if (row.TryGetValue(orderByCondition.ColumnName, out var value)) { return value; } throw new InvalidOperationException( $"Order by column {orderByCondition.ColumnName} does not exist in CSV file."); }); } // 处理 SELECT 条件 if (queryExpression.SelectAll) { return filteredData; } var selectedData = filteredData.Select(row => { var selectedRow = new Dictionary<string, string>(); foreach (var columnName in queryExpression.SelectList) { if (row.TryGetValue(columnName, out var value)) { selectedRow[columnName] = value; } else { throw new InvalidOperationException($"Column {columnName} does not exist in CSV file."); } } return selectedRow; }); return selectedData; } private IEnumerable<Dictionary<string, string>> ReadCsv(string tableName) { var csvFile = new FileInfo(Path.Combine(csvDirectory.FullName, $"{tableName}.csv")); if (!csvFile.Exists) { throw new FileNotFoundException($"CSV file {csvFile.FullName} does not exist."); } using var reader = new StreamReader(csvFile.FullName);