
原文作者:aircraft
原文链接:https://www.cnblogs.com/DOMLX/p/18779326
本来想写的是pytorch的入门教程的,不过想想入门教程需要解释的各种原理各种函数就觉得麻烦,还是先写一些实战篇的教程把。。。。。。偷懒中QAQ
Darknet-53 是一种高效的卷积神经网络架构,由 Joseph Redmon 在 YOLOv3 目标检测系统中首次提出,作为特征提取的骨干网络(Backbone)。其名称中的“53”表示网络包含 53 个卷积层。以下是该网络的详细介绍:
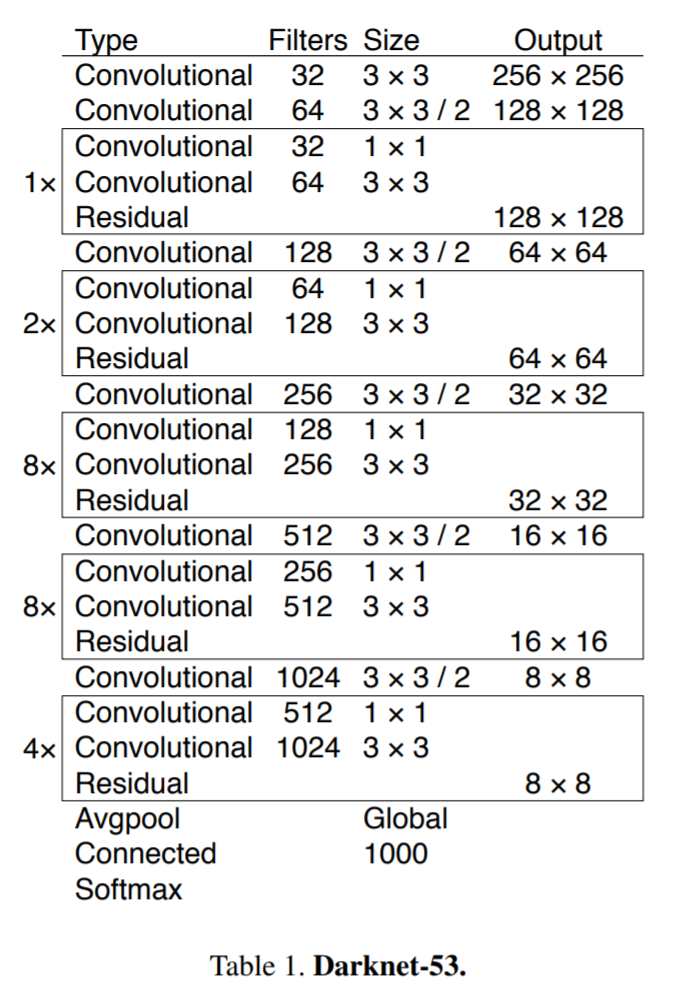
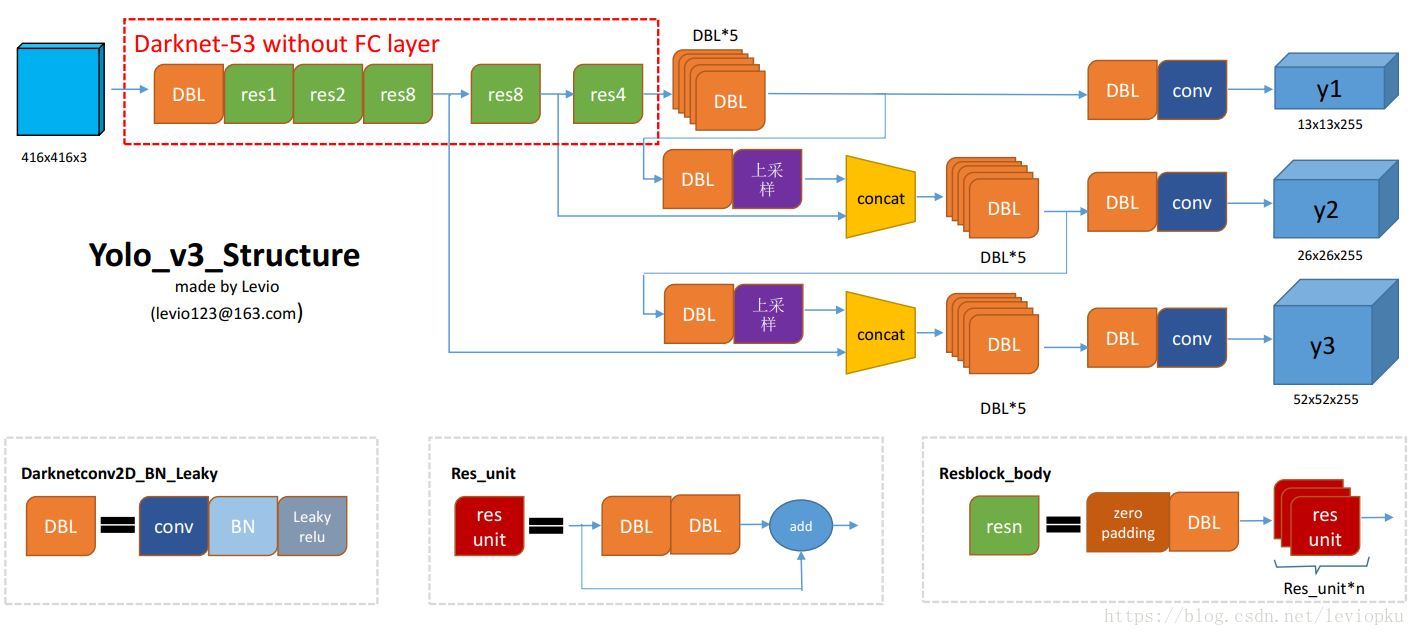
图一开始看不懂没关系,先理解代码再回来看图,你发现你就能看懂了。
一、核心设计理念
-
深层特征提取
通过堆叠卷积层和残差块(Residual Blocks),实现多尺度特征提取,适合处理复杂视觉任务。 -
残差连接优化
借鉴 ResNet 思想,引入跳跃连接(Shortcut Connections),解决深层网络梯度消失问题。 -
计算效率平衡
在模型深度与计算量之间取得平衡,适用于实时检测任务(如 YOLOv3)。
二、网络结构详解
1. 整体架构
Darknet-53 由 5 个阶段(Stage) 构成,每阶段通过下采样(Strided Convolution)缩小特征图尺寸,同时增加通道数:
| 阶段 | 操作序列 | 输出尺寸 (CIFAR-10) | 通道数变化 |
|---|---|---|---|
| Stage1 | Conv3x3 → Conv3x3/2 → ResBlock×1 | 16×16 | 3 → 64 |
| Stage2 | Conv3x3/2 → ResBlock×2 | 8×8 | 64 → 128 |
| Stage3 | Conv3x3/2 → ResBlock×8 | 4×4 | 128 → 256 |
| Stage4 | Conv3x3/2 → ResBlock×8 | 2×2 | 256 → 512 |
| Stage5 | Conv3x3/2 → ResBlock×4 | 1×1 | 512 → 1024 |
2. 残差块设计——-残差结构Residual
每个残差块包含 1×1 压缩 + 3×3 扩展 的双卷积结构:
ResBlock = Sequential( Conv1x1(in_ch, mid_ch), # 压缩通道至1/2 Conv3x3(mid_ch, in_ch) # 恢复原始通道数 )
- 跳跃连接:这里就是残差网络ResNet的核心思想了,输入参数直接与双卷积输出相加,公式:
output = ConvBlock(x) + x
这里想详细讲一下残差网络的优点:
为什么深层网络训练困难?——梯度消失问题
在深层神经网络中,信息需要通过多个层逐层传递。无论是前向传播(计算预测值)还是反向传播(计算梯度更新参数),信号都会经过多个非线性变换(如激活函数、矩阵乘法等)。梯度消失问题的本质是:
-
反向传播的链式法则
梯度通过反向传播算法计算,使用链式法则(Chain Rule)逐层求导。假设有 L 层网络,梯度是各层导数的乘积:

激活函数的导数问题
例如 Sigmoid 函数的导数最大值为0.25,ReLU 在负数区域的导数为0。当网络较深时,多个小导数的乘积会趋近于0。

实际效果:残差网络ResNet 是深度学习历史上第一个突破千层的网络,开启了超深度模型的新时代。
3. 分类头(本文代码实现)
- 全局平均池化:将最终特征图压缩至 1×1(
AdaptiveAvgPool2d(1)) - 全连接层:1024维特征 → 10类别概率(CIFAR-10)
三、技术优势
1. 残差连接的优势
- 梯度直传:跳跃连接为反向传播提供“高速公路”,缓解梯度消失,对于深层神经网络的反向转播的梯度更新,如果。
- 特征复用:原始输入信息直接传递,增强特征表达能力。
2. 计算效率
- 参数量对比(与 ResNet-152 对比):
模型 参数量 Top-1 准确率(ImageNet) Darknet-53 ~25M 77.2% ResNet-152 ~60M 78.3% - 推理速度:Darknet-53 的浮点运算量(FLOPs)更低,适合实时任务。
3. 多尺度特征提取
- 层级特征图:不同阶段输出不同尺度的特征图(如 8×8、4×4),适用于目标检测中的多尺度预测。
四、应用场景
-
目标检测
- 作为 YOLOv3/v4 的骨干网络,提取多尺度特征。
- 输出三个尺度的特征图(如 13×13、26×26、52×52)。
-
图像分类
- 用户代码适配 CIFAR-10 的 32×32 小尺寸图像,通过调整池化层实现分类。
五、本代码与原论文代码差异
| 特性 | 原版 Darknet-53 | 用户代码实现 |
|---|---|---|
| 输入尺寸 | 256×256(ImageNet) | 32×32(CIFAR-10) |
| 残差块 | 每个块使用两个 3×3卷积 | 1×1 + 3×3 卷积组合 |
| 分类头 | 全连接层(1000类) | 全局池化 + 全连接层 |
| 激活函数 | LeakyReLU(原版使用) | LeakyReLU(与原文一致) |
对于归一化函数BatchNorm2d可以看看这些博客:一文搞懂归一化(PyTorch) 和pytorch中对BatchNorm2d()函数的理解
卷积层和池化层的计算公式(图都是网上找的,怕你们看代码不知道经过卷积层和池化层后图像的长宽为什么这样变化的):


实例代码(里面的数据集都是在线下载大概160M左右,注释都已经打的非常的详细了噢,认真看注释就行了):
""" 基于Darknet-53的CIFAR-10分类完整实现 包含数据加载、模型定义、训练、测试、可视化全流程 """ # ----------------- 导入所需库 ----------------- import torch import torch.nn as nn from torch.nn import modules # 模块化神经网络组件 from torch.utils.data import DataLoader # 数据加载器 from torchvision.datasets import CIFAR10 # CIFAR-10数据集 from torchvision.transforms import transforms # 数据预处理 import matplotlib.pyplot as plt # 可视化绘图 import numpy as np # 数值计算 from sklearn.metrics import confusion_matrix, classification_report # 评估指标 import seaborn as sns # 美观的可视化 # ----------------- 基础模块定义 -----------------
class ConvBnLeaky(modules.Module): """卷积+批量归一化+LeakyReLU组合层""" def __init__(self, in_it, out_it, kernels, padding=0, strides=1): """ 参数说明: - in_it: 输入通道数 - out_it: 输出通道数 - kernels: 卷积核尺寸(整数或元组) - padding: 填充像素数(默认为0) - strides: 卷积步长(默认为1) """ super(ConvBnLeaky, self).__init__() self.convs = nn.Sequential( nn.Conv2d(in_it, out_it, kernels, padding=padding, stride=strides), # 卷积操作 nn.BatchNorm2d(out_it), # 批量归一化加速训练收敛 nn.LeakyReLU(0.1, inplace=True) # 带泄露的ReLU(负轴斜率0.1) ) def forward(self, x): """前向传播"""
return self.convs(x) class Resnet_Block(modules.Module): """残差模块(包含多个残差块)""" def __init__(self, ch, num_block=1): """ 参数说明: - ch: 通道数 - num_block: 残差块的数量 """ super(Resnet_Block, self).__init__() self.module_list = modules.ModuleList() # 存储子模块的列表 # 构建指定数量的残差块 for _ in range(num_block): resblock = nn.Sequential( # 第一个卷积压缩通道数 ConvBnLeaky(ch, ch//2, 1), # 1x1卷积(降维)
# 第二个卷积恢复通道数 ConvBnLeaky(ch//2, ch, 3, padding=1) # 3x3卷积(特征提取)
) self.module_list.append(resblock) def forward(self, x): """前向传播(含残差连接)"""
for block in self.module_list: # 残差连接公式:F(x) + x x = block(x) + x # 保留原始输入信息 return x # ----------------- 网络主体结构 -----------------
class Darknet_53(modules.Module): """Darknet-53主干网络""" def __init__(self, num_classes=10): super(Darknet_53, self).__init__() # 第一阶段(高分辨率特征提取) self.later_1 = nn.Sequential( ConvBnLeaky(3, 32, 3, padding=1), # 3→32通道(保持32x32分辨率) ConvBnLeaky(32, 64, 3, padding=1, strides=2), # 下采样至16x16 Resnet_Block(64, 1) # 1个残差块 ) # 第二阶段 self.later_2 = nn.Sequential( ConvBnLeaky(64, 128, 3, padding=1, strides=2), # 下采样至8x8 Resnet_Block(128, 2) # 2个残差块 ) # 第三阶段 self.later_3 = nn.Sequential( ConvBnLeaky(128, 256, 3, padding=1, strides=2), # 下采样至4x4 Resnet_Block(256, 8) # 8个残差块 ) # 第四阶段 self.later_4 = nn.Sequential( ConvBnLeaky(256, 512, 3, padding=1, strides=2), # 下采样至2x2 Resnet_Block(512, 8) # 8个残差块 ) # 第五阶段(深层特征提取) self.later_5 = nn.Sequential( ConvBnLeaky(512, 1024, 3, padding=1, strides=2), # 下采样至1x1 Resnet_Block(1024, 4) # 4个残差块 ) # 分类头 self.pool = nn.AdaptiveAvgPool2d((1,1)) # 全局平均池化(输出1x1x1024) self.fc = nn.Linear(1024, num_classes) # 全连接层(1024→10类别) def forward(self, x): """前向传播流程""" x = self.later_1(x) x = self.later_2(x) x = self.later_3(x) x = self.later_4(x) x = self.later_5(x) x = self.pool(x) # [batch,1024,1,1] x = torch.squeeze(x) # 去除冗余维度 → [batch,1024] x = self.fc(x) # [batch,10] return x # ----------------- 主函数(训练+测试) ----------------- def main(): # ----------------- 数据加载 ----------------- # 训练集(自动下载到./data目录) train_data = CIFAR10( root='./data', train=True, transform=transforms.ToTensor() # 转为Tensor并归一化到[0,1]
download=True )
train_loader = DataLoader( train_data, batch_size=64, shuffle=True # 训练时打乱数据顺序 ) # 测试集 test_data = CIFAR10( root='./data', train=False, transform=transforms.ToTensor(), download=True # 如果不存在则自动下载 ) test_loader = DataLoader( test_data, batch_size=64, shuffle=False # 测试不需要打乱顺序 ) # ----------------- 模型配置 ----------------- device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') net = Darknet_53().to(device) # 实例化模型并移至GPU criterion = nn.CrossEntropyLoss().to(device) # 交叉熵损失函数 optimizer = torch.optim.Adam(net.parameters(), lr=0.001) # Adam优化器 # ----------------- 训练循环 ----------------- print("开始训练...") train_losses = [] # 记录每个epoch的训练损失 train_accs = [] # 记录每个epoch的训练准确率 for epoch in range(10): net.train() # 设置为训练模式 total_correct = 0 # 累计正确预测数 total_loss = 0 # 累计损失值 # 迭代所有训练批次 for images, labels in train_loader: # 数据移至GPU images = images.to(device) labels = labels.to(device) # 前向传播 outputs = net(images) loss = criterion(outputs, labels) # 反向传播与优化 optimizer.zero_grad() # 清空梯度(重要!) loss.backward() # 计算梯度 optimizer.step() # 更新参数 # 统计训练指标 _, preds = torch.max(outputs, 1) # 获取预测类别(dim=1) total_correct += (preds == labels).sum().item() # 累计正确数 total_loss += loss.item() # 累计损失 # 计算epoch指标 epoch_acc = total_correct / len(train_data) # 准确率 = 正确数 / 总样本数 epoch_loss = total_loss / len(train_loader) # 平均损失 = 总损失 / 批次数 # 记录指标 train_losses.append(epoch_loss) train_accs.append(epoch_acc) # 打印训练进度 print(f"\nEpoch {epoch+1}/10") print(f"Train Loss: {epoch_loss:.4f} | Acc: {epoch_acc*100:.2f}%") # ----------------- 训练过程可视化 ----------------- plt.figure(figsize=(12, 5)) # 损失曲线(左图) plt.subplot(1, 2, 1) plt.plot(train_losses, 'b-o', label='Training Loss') plt.title("Training Loss Curve") plt.xlabel("Epochs") plt.ylabel("Loss") plt.legend() # 准确率曲线(右图) plt.subplot(1, 2, 2) plt.plot(train_accs, 'r-o', label='Training Accuracy') plt.title("Training Accuracy Curve") plt.xlabel("Epochs") plt.ylabel("Accuracy") plt.legend() plt.tight_layout() # 调整子图间距 plt.show() # ----------------- 测试集验证 ----------------- print("\n开始测试...") all_preds = [] # 存储所有预测结果 all_labels = [] # 存储所有真实标签 test_loss = 0 # 测试损失 net.eval() # 设置为评估模式(关闭Dropout等) with torch.no_grad(): # 禁用梯度计算(节省内存) for images, labels in test_loader: images = images.to(device) labels = labels.to(device) outputs = net(images) loss = criterion(outputs, labels) test_loss += loss.item() # 累计测试损失 _, preds = torch.max(outputs, 1) # 收集预测结果和标签(移至CPU) all_preds.extend(preds.cpu().numpy()) all_labels.extend(labels.cpu().numpy()) # 计算测试指标 test_loss = test_loss / len(test_loader) # 平均测试损失 test_acc = np.mean(np.array(all_preds) == np.array(all_labels)) # 测试准确率 # 打印测试结果 print("\n测试结果:") print(f"Test Loss: {test_loss:.4f} | Acc: {test_acc*100:.2f}%") print("\n分类报告(按类别统计):") print(classification_report(all_labels, all_preds, target_names=test_data.classes)) # ----------------- 混淆矩阵可视化 ----------------- cm = confusion_matrix(all_labels, all_preds) plt.figure(figsize=(10, 8)) sns.heatmap( cm, annot=True, # 显示数值 fmt='d', # 整数格式 cmap='Blues',# 蓝色系颜色 xticklabels=test_data.classes, # x轴类别名称 yticklabels=test_data.classes # y轴类别名称 ) plt.title("Confusion Matrix") plt.xlabel("Predicted Labels") plt.ylabel("True Labels") plt.show() # ----------------- 预测示例可视化 ----------------- classes = test_data.classes # 获取类别名称列表 # 从测试集中获取一批样本(10个) sample_images, sample_labels = next(iter(test_loader)) sample_images = sample_images.to(device) # 预测 net.eval() with torch.no_grad(): outputs = net(sample_images) _, preds = torch.max(outputs, 1) # 调整图像格式(适用于matplotlib显示) sample_images = sample_images.cpu().numpy() sample_images = np.transpose(sample_images, (0, 2, 3, 1)) # [B,C,H,W] → [B,H,W,C] # 绘制预测结果对比图 plt.figure(figsize=(15, 6)) for i in range(10): # 显示前10个样本 plt.subplot(2, 5, i+1) plt.imshow(sample_images[i]) plt.title(f"True: {classes[sample_labels[i]]}\nPred: {classes[preds[i]]}") plt.axis('off') # 关闭坐标轴 plt.tight_layout() plt.show() if __name__ == '__main__': main()
如果安装失败可以使用下面的方法试试安装scikit-learn
pip install –upgrade –force-reinstall –user scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
运行过程会打印损失和ACC
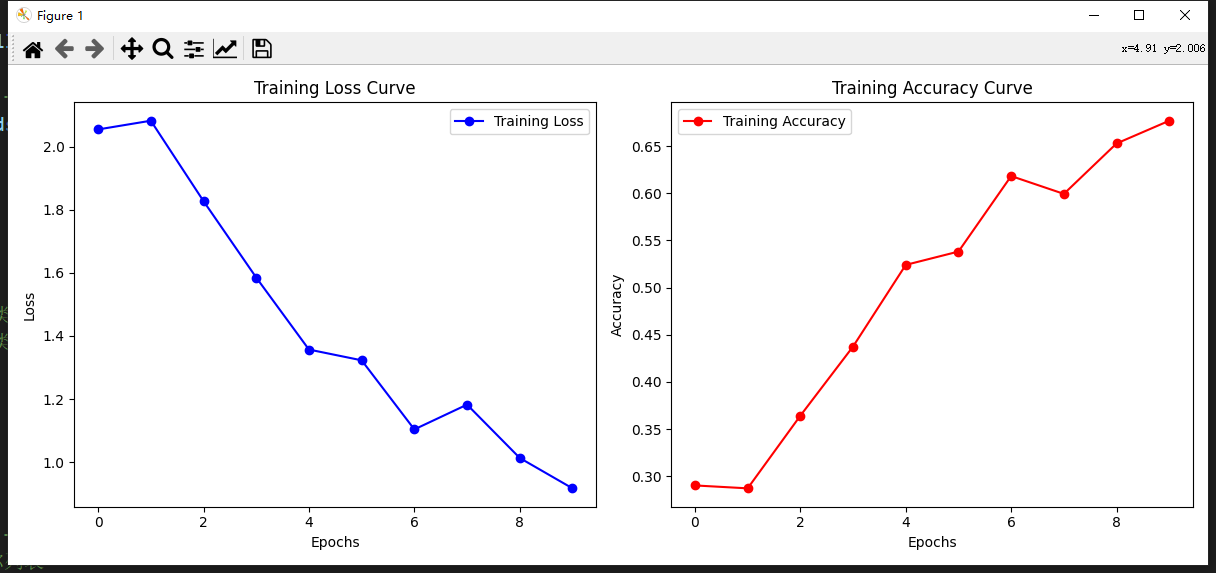
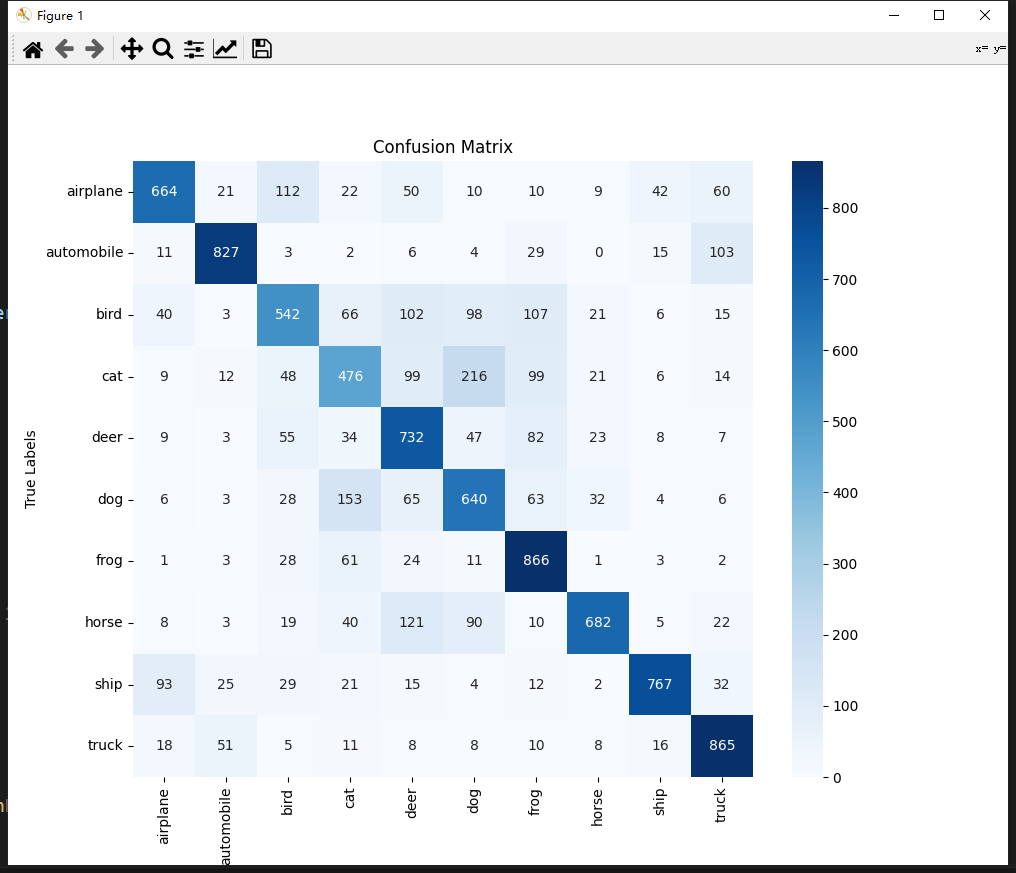
混淆矩阵显示结果:
预测示例可视化:

总结
Darknet-53 是一种高效平衡深度与计算量的骨干网络,其残差设计和层级特征提取能力使其在目标检测和分类任务中表现卓越。代码通过调整下采样策略和分类头,成功将其适配到小尺寸图像分类任务,展现了该架构的灵活性。作为YOLO网络组成的一部分,可以在学习YOLO之前可以先学习这个,等你把YOLO的几个零件学习完毕,自然就能很快的学完YOLO。
来源链接:https://www.cnblogs.com/DOMLX/p/18819617





没有回复内容