

#SpikeYOLO
高性能低能耗目标检测网络
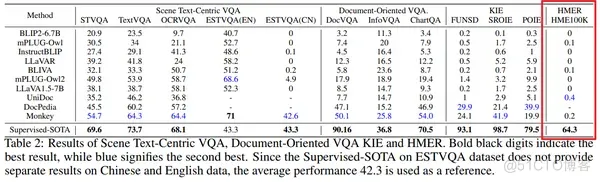
本文提出了目标检测框架SpikeYOLO,以及一种能够执行整数训练脉冲推理的脉冲神经元。在静态COCO数据集上,SpikeYOLO的mAP@50和mAP@50:95分别达到了66.2%和48.9%,比之前最先进的SNN模型分别提高了+15.0%和+18.7%。
中国科学院自动化所李国齐课题组
论文:https://arxiv.org/abs/2407.20708
代码:github.com/BICLab/SpikeYOLO
- 背景
脉冲神经元模拟了生物神经元的复杂时空动态,其利用膜电势融合时空信息,仅在膜电势超过阈值时发射二值脉冲信号。因此,脉冲神经网络只有在接收到脉冲信号时才会触发稀疏加法运算。当脉冲神经网络部署到神经形态芯片时,能发挥其最大的低功耗优势。例如,神经形态感算一体芯片Speck[1]采用异步电路设计,具有极低的静息功耗(低至0.42mW),在典型神经形态边缘视觉场景的功耗低至0.7mW。
然而,脉冲神经元的复杂内在时空动态和二值脉冲活动是一把“双刃剑”。一方面,复杂内在时空动态特性带来强大的信息表达能力,结合脉冲信号使能事件驱动计算获得低功耗特性;而另一方面,二值脉冲活动不可微分的特性使得SNN难以训练。因此,SNN在计算机视觉中的大多数应用仅限于简单的图像分类任务,而很少应用于更常用且具有挑战性的目标检测任务,且和ANN之间有着明显的性能差距。
- 本文主要贡献
本文目标是弥合SNN和ANN在目标检测任务上的性能差距。我们通过两项努力实现了这一目标。第一,网络架构方面,我们发现过于复杂的网络架构在直接加入脉冲神经元后会导致脉冲退化,从而性能低下。第二,脉冲神经元方面,将连续值量化为二值脉冲不可避免会带来信息损失,这是SNN领域长久存在且难以克服的一个问题。
基于此,本工作的主要贡献包括:
- 简化SNN架构以缓解脉冲退化。 本文提出了SpikeYOLO,一个结合YOLOv8宏观设计和Meta-SpikeFormer微观设计的目标检测框架,主要思想是尽量避免过于复杂的网络架构设计。
- 设计整数训练脉冲推理神经元以减少量化误差的影响。 提出一种I-LIF神经元,可以采用整数值进行训练,并在推理时等价为二值脉冲序列,有效降低脉冲神经元的量化误差。
- 最佳性能。 在静态COCO数据集上,本文提出的方法在mAP@50和mAP@50:95上分别达到了66.2%和48.9%,比之前最先进的SNN模型分别提高了+15.0%和+18.7%;在神经形态数据集Gen1上,本文的mAP@50达到了67.2%,比同架构的ANN提高了+2.5%,并且能效提升5.7×。
3. 方法3.1 架构设计
本文发现,YOLO过于复杂的网络模块设计会导致在直接加入脉冲神经元后出现脉冲退化现象。因此,本文提出的SpikeYOLO在设计上倾向于简化YOLO架构。SpikeYOLO将YOLOv8[5]的宏观设计与meta-SpikeFormer[4]的微观设计相结合,在保留了YOLO体系结构的总体设计原则的基础上,设计了meta SNN模块,包含倒残差结构、重参数化等设计思想。SpikeYOLO的具体结构如图1所示:
图1 SpikeYOLO总体架构
宏观设计: YOLO是一个经典的单阶段检测框架,它将图像分割成多个网格,每个网格负责独立地预测目标。其中一些经典的结构,如特征金字塔(FPN)等,在促进高效的特征提取和融合方面起着至关重要的作用。然而,随着ANN的发展,YOLO的特征提取模块愈发复杂。以YOLOv8的特征提取模块C2F为例,其通过复杂的连接方式对信息进行多次重复提取和融合,这在ANN中能增加模型的表达能力,但在SNN中则会引起脉冲退化现象。作为一种折衷方案,本文提出了SpikeYOLO。其保留了YOLO经典的主干/颈部/头部结构,并设计了Meta SNN模块作为微观算子。
微观设计: SpikeYOLO的微观设计参考了Meta-SpikeFormer[3],一个典型的脉冲驱动CNN+Transformer混合架构。我们发现Transformer结构在目标检测任务上表现不如简单的CNN架构,作为一种折中方案,本文提出的SpikeYOLO尽量避免过于复杂的网络架构设计。SpikeYOLO包含两种不同的卷积特征提取模块:SNN-Block-1和SNN-Block-2,分别应用于浅层特征提取和深层特征提取。两种特征提取模块的区别在于他们的通道混合模块(ChannelConv)不同。SNN-Block-1采用标准卷积进行通道混合(ChannelConv1),SNN-Block-2采用重参数化卷积进行通道混合(ChannelConv2),以减少模型参数量。SpikeYOLO的特征提取模块可被具体表示为:
3.2 神经元设计
脉冲神经元通过模拟生物神经元的通信方案,在空间和时间域上传播信息。然而,在将尖峰神经元的膜电位量化为二值脉冲时存在严重的量化误差,严重限制了模型的表达能力。为解决这个问题,本文提出了一种整数训练,脉冲推理的神经元I-LIF。I-LIF在训练过程中采用整数进行训练,在推理时通过拓展虚拟时间步的方法将整数值转化为二值脉冲序列以保证纯加法运算。
考虑传统的软重置的LIF神经元,其内部时空动力学可以被表示为:
上式中,Θ(·)是指示函数,将小于0的值置零,否则置1。这种二值量化方式带来了严重的量化误差。相比之下,I-LIF不将膜电势与神经元阈值做比较,而是对膜电势四舍五入量化为整数,其脉冲函数S[t]被重写为:
其中,round(·)是四舍五入量化函数,Clip(·)是裁剪函数,D是最大量化值。S[t]的发放结果被量化为[0,D]的整数,以降低模型量化误差。
推理时,I-LIF通过拓展虚拟时间步的方法,将整数值转化为二值脉冲序列,以保证网络的脉冲驱动特性,如图2所示。
图2 I-LIF训练和推理原理(在训练过程中发放的整数值2,在推理过程中转化为两个1)
图3展示了一个更加细节的例子(T=3,D=2)。在训练时,当膜电势为1.9时(如第一列),I-LIF发放一个值为2的整数,并将膜电势减去相应量化值;当膜电势为2.6时(如第三列),由于其高于最大量化值,I-LIF也只发放一个值为2的整数,而不会发放值为3的整数。在推理时,I-LIF拓展虚拟时间步(图中红色虚线部分),将整数值转化为二值脉冲序列,保证脉冲驱动。
图3 I-LIF发放模式举例
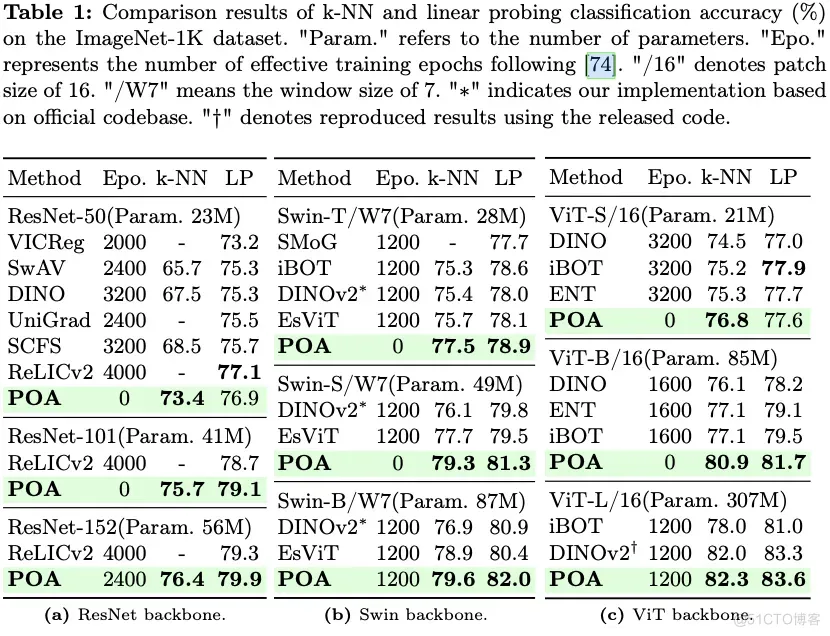
4.1 静态数据集
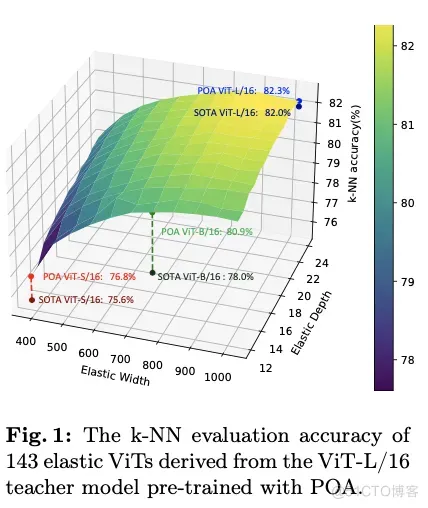
如图4所示,SpikeYOLO在COCO数据集上达到了66.2%的mAP@50和48.9%的mAP@50:95,分别比之前SNN领域的SOTA结果提升了+15.0%和+18.7%,超越DETR等ANN模型,并且仅需要84.2mJ的能耗。此外,增大量化值D的效果远远优于增加之间步长T,且能耗增幅更小。
图4 COCO 静态数据集实验结果
4.2 神经形态数据集
如图5所示,SpikeYOLO在神经形态数据集Gen1上同样取得了SNN领域的SOTA结果,map@50:95超过SNN领域的SOTA结果+9.4%。和同架构ANN网络相比,SpikeYOLO的mAP@50:95提高了+2.7%,并且能效提升5.7×。
图5 Gen1 神经形态数据集实验结果
4.3 消融实验
4.3.1 架构消融实验
本文在COCO数据集上进行不同模块的消融实验,包括移除重参数化卷积、采用SNN-Block-2替换SNN-Block-1,以及将Anchor-free检测头替换为Anchor-based检测头等。结果证明,SpikeYOLO拥有最先进的性能。
图6 COCO数据集架构消融实验结果
4.3.2 量化值实验
图7 Gen1数据集量化值消融实验结果
本文在Gen1数据集上分别测试了不同时间步T和量化值D对精度和能耗的影响。实验表明。适当增加T或D都有助于提升模型性能。另外,当提升D时,模型的能耗反而降低,一个可能的原因是输入数据是稀疏的事件数据,包含的有效信息较少,此时采用更精细的膜电势量化方案可以避免网络发放冗余脉冲,从而降低模型的平均发放率。
综上所述,本文提出了目标检测框架SpikeYOLO,以及一种整数训练脉冲推理的神经元I-LIF,并在静态和神经形态目标检测数据集上均进行了验证。全文到此结束,更多细节建议查看原文。
参考文献 https://github.com/ultralytics/ultralytics
#ControlNeXt
即插即用,效率远超ControlNet!贾佳亚团队重磅开源ControlNeXt:超强图像视频生成方法
本文提出了 ControlNeXt,一种先进且高效的可控图像和视频生成方法。ControlNeXt 采用简化和精简的架构,消除了重型辅助组件,以最小化延迟开销并减少可训练参数。
文章链接:https://arxiv.org/pdf/2408.06070
git链接:https://github.com/dvlab-research/ControlNeXt
项目链接:https://pbihao.github.io/projects/controlnext/index.html
亮点直击
- 提出了ControlNeXt,这是一种强大且高效的图像和视频生成方法,大幅减少了延迟开销和参数量。
- 引入了交叉归一化(Cross Normalization)用于微调预训练的大型模型,从而促进高效且稳定的训练收敛。
- ControlNeXt可以作为一个轻量级的即插即用模块,可以与其他LoRA权重集成,以无需额外训练的方式改变生成样式。
扩散模型在图像和视频生成方面展示了显著且稳定的能力。为了实现对生成结果的更大控制,研究人员引入了额外的架构,如ControlNet、Adapters和ReferenceNet,以整合条件控制。然而,当前可控生成方法通常需要大量额外的计算资源,尤其是在视频生成方面,并且在训练中面临挑战或控制效果较弱。本文提出了ControlNeXt:一种强大且高效的可控图像和视频生成方法。
首先设计了一个更简单且高效的架构,取代了沉重的额外分支,只需在基础模型上增加极少的成本。这种简洁的结构还使本文的方法能够无缝集成其他LoRA权重,实现样式更改而无需额外训练。在训练方面,减少了多达90%的可学习参数,相较于其他方法。此外,还提出了称为交叉归一化(Cross Normalization, CN)的方法,以替代“零卷积”实现快速且稳定的训练收敛。多项实验,使用不同的基础模型在图像和视频领域,证明了本文方法的稳健性。
方法
深入分析架构设计并对其进行剪枝,以构建一个简洁明了的结构。随后介绍交叉归一化(Cross Normalization),该方法用于通过引入额外的参数对大型预训练模型进行微调。
架构剪枝
动机。ControlNet的关键创新在于增加了一个控制分支,该分支提取条件控制并将其整合到主网络中。这个分支共享了可训练参数,这些参数初始化为原始分支一半的副本,并行运行,使用零卷积作为桥梁来整合条件控制。具体来说:
其中, 表示具有可学习参数 的神经模型, 表示零卷积层, 和 分别表示二维特征图和条件控制, 表示控制参数。预训练的大型生成模型 及其预训练参数 完全冻结,而ControlNet分支 则通过从主分支复制进行初始化。
然而,这样的设计虽然引入了控制能力,但也带来了显著的成本。额外的分支会使延迟最多增加50%,这一点在视频生成中尤为显著,因为每一帧都需要处理。此外,这些可训练参数量庞大且固定,几乎等同于所有预训练参数的一半。除了冗余之外,仅优化ControlNet也限制了整个模型的上限,因为它不会影响预训练的生成模型。为提高效率和简洁性,首先通过移除额外的分支简化了ControlNet的原始设计。接着,对预训练模型中选定的子集进行训练,从而得到一个更有效且高效的架构。
架构剪枝。 需要注意的是,预训练模型通常是在大规模数据集(例如LAION-5B)上进行训练的,而微调则始终在规模小得多的数据集上进行,往往小上千倍。基于此,认为预训练的大型生成模型已经足够强大,且无需引入如此大量的额外参数来实现控制生成的能力。
具体来说,移除了控制分支,并用一个轻量级的卷积模块代替,该模块仅由多个ResNet块组成。这个模块的规模远小于预训练模型,旨在从条件控制中提取指导信息,并将其与去噪特征对齐。由于其小巧的体积,更多地依赖生成模型本身来处理控制信号。在训练过程中,冻结了大部分预训练模块,并选择性地优化预训练生成模型中一小部分可训练参数。这种方法将可能由训练过程引起的遗忘风险降到最低。它还可以与参数高效的微调方法(如LoRA)结合使用。研究者们努力通过避免对原始架构进行重大修改来保持模型结构的一致性。直接训练这些模型还能带来更大的有效性和效率,并能自适应地调整可学习参数的规模以适应不同的任务。表达为:
其中, 表示预训练参数中的一个可训练子集, 而 是用于提取条件控制的轻量级卷积模块。基于上述流程, 力求在尽可能减少额外开销和延迟的同时, 保持模型的一致性。
关于条件控制的注入,观察到对于大多数可控生成任务,控制信号通常具有简单的形式或与去噪特征保持高度一致,因此无需在多个阶段插入控制信号。在单个选定的中间块中将控制信号与去噪分支集成,通过交叉归一化进行归一化后,直接将其添加到去噪特征中。该模块可以作为一个即插即用的模块,由轻量级卷积模块和可学习参数构成,这些参数是预训练模型的一个子集,其表示如下:
其中, , 且 。
交叉归一化
动机。 在对预训练大型模型进行持续训练时,通常面临的一个问题是如何适当地引入额外的参数和模块。由于直接组合新的参数通常会导致训练崩溃和收敛性差,最近的工作广泛采用了零初始化,即将连接预训练模型和新增模块的桥接层初始化为零。这种操作确保了在训练开始时新引入的模块不会产生影响,从而实现稳定的热身阶段。然而,零初始化可能导致收敛缓慢并增加训练挑战,因为它阻止了模块从损失函数中获得准确的梯度。这会导致一种称为“突发收敛”的现象,即模型在经过一段较长的训练时间后并没有逐渐学习条件,而是突然开始遵循这些条件。
本节分析了在添加新参数时训练崩溃的原因,并提出了交叉归一化作为零卷积的替代方案,以确保稳定和高效的训练。
交叉归一化。 研究者们发现训练崩溃的关键原因是引入的模块和预训练模型之间的数据分布不对齐和不兼容。经过大规模数据训练后,预训练生成模型通常表现出稳定的特征和数据分布,其特征是均值和标准差的一致性。然而,新引入的神经模块通常仅使用随机方法(例如高斯初始化)进行初始化。这导致新引入的神经模块产生具有显著不同均值和标准差的特征输出。直接添加或组合这些特征会导致模型不稳定。
归一化方法(如bn和层归一化)通过标准化层输入来提高训练稳定性和速度。它们通过将输入标准化为零均值和单位方差来实现这一点,这在神经网络训练中被广泛使用。受到这些方法的启发,本文提出了交叉归一化,以对齐处理过的条件控制和主分支特征,从而确保训练的稳定性和速度。
将来自主去噪分支和控制转移分支的特征图分别表示为 和 , 其中 。交叉归一化的关键是使用从主分支 计算的均值和方差来对条件特征 进行归一化, 以确保它们的对齐。首先, 计算去噪特征的均值和方差:
然后,使用去噪特征的均值和方差对控制特征进行归一化:
其中, 是为数值稳定性而添加的小常数, 是允许模型缩放归一化值的参数。
交叉归一化对齐了去噪特征和控制特征的分布,充当了连接扩散和控制分支的桥梁。它加速了训练过程,确保即使在训练开始时控制对生成的有效性,并减少对网络权重初始化的敏感性。
实验
本节展示了在各种任务和基础模型上进行的系列实验。本文的方法在图像和视频生成方面表现出卓越的效率和通用性。
通用性
为了展示本文方法的鲁棒性和通用性,首先在多个基于扩散的基础模型上实现了本文的方法,如Stable Diffusion 1.5、Stable Diffusion XL、Stable Diffusion 3 和 Stable Video Diffusion。这些实验涵盖了图像生成、高分辨率生成和视频生成等广泛任务,并使用了各种类型的条件控制。定性结果如下图1所示。结果表明,本文的方法具有鲁棒性和广泛的适应性,能够有效适应各种架构,并满足不同任务的要求。
各种条件控制。 ControlNeXt 还支持各种类型的条件控制。在这一小节中,选择了“mask”、“depth”(深度)、“canny”(边缘)和“pose”(姿态)作为条件控制,分别展示在下图5的从上到下的位置。
所有实验均基于Stable Diffusion 1.5架构进行构建。更多稳定视频生成的结果(利用姿态序列作为角色动画的指导)展示在图6中。SDXL的结果展示在图7中,通过提取输入图像中的Canny边缘并使用SDXL模型生成输出,实现了风格迁移。
训练收敛性
可控生成中的一个典型问题是训练收敛困难,这意味着需要数千步或更多步骤的训练才能学习条件控制。这种现象被称为“突发收敛问题”,发生在模型最初无法学习控制能力,然后突然获得这一技能。这主要由以下两个方面造成:
- 零卷积抑制了损失函数的影响,导致模型在学习初期难以有效开始学习,从而延长了热身阶段。
- 预训练生成模型完全冻结,而ControlNet作为一个适配器,无法立即影响模型。
在ControlNeXt中,消除了这两个限制,从而显著加快了训练收敛速度。使用了两种类型的控制进行了实验,结果和比较如下图3所示。可以看出,ControlNeXt在仅经过几百步训练后就开始收敛,而ControlNet则需要数千步。这显著缓解了突发收敛问题。
效率
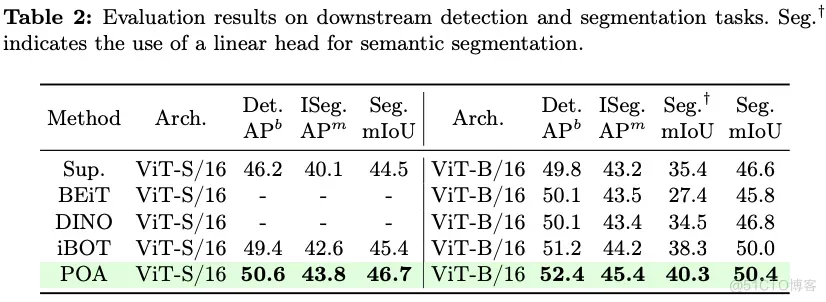
本文的方法仅向原始预训练模型添加了一个轻量级模块,确保其保持高效,并且不会引入显著的延迟。本节提供了更多细节,并进行了额外的实验以展示本文方法的效率。
参数。 首先,提供了关于参数的统计信息,包括总参数和可学习参数,这些统计仅计算了UNet模型(不包括VAE和编码器部分)。结果显示在下表1中。可以看出,本文的方法仅添加了一个轻量级模块,额外参数非常少,保持了与原始预训练模型的一致性。至于训练,本文的方法最多仅需不到10%的可学习参数,使其成为一个非常轻量且即插即用的模块。您还可以根据不同的任务和性能要求自适应调整可学习参数的数量。关于参数数量对模型影响的更多细节将在后文讨论。
推理时间。 研究者们比较了不同方法在各种基础模型上的推理时间。结果显示在下表2中,该表呈现了一个推理步骤的计算时间,仅考虑了UNet和ControlNet部分,排除了编码和解码过程。可以看出,由于本文的方法仅添加了一个轻量级模块,与预训练基础生成模型相比,其延迟增加极小。这确保了本文方法在效率上的显著优势。
即插即用
ControlNeXt 的设计旨在保持生成模型原始架构的一致性,确保其兼容性和有效性。它可以作为一个即插即用、无需训练的模块,与各种基础模型和开源 LoRA 无缝集成,实现生成风格的变化。
无需训练的集成。 研究者们首先收集了从 Civitai 下载的各种 LoRA 权重,涵盖了不同的生成风格。然后,在基于 SD1.5 架构的各种基础模型上进行了实验,包括 SD1.5、AnythingV3 和 DreamShaper。结果显示在下图8中。可以观察到,ControlNeXt 可以以无需训练的方式与各种基础模型和 LoRA 权重集成,有效地改变生成图像的质量和风格。这主要归因于本文方法的轻量级设计,该设计主要保持了预训练基础模型的一致性,并且仅添加了极少的附加模块。这些优势使其能够作为一个具有通用兼容性的即插即用模块。
稳定生成。 为了生成令人满意的结果,生成模型通常需要迭代调整提示。ControlNeXt 作为一个插件单元,能够以最小的努力和成本实现稳定生成。提供了一个简单的提示,“一个女人”,生成结果的比较(有无本文的方法)如下图9所示。
结论
本文提出了 ControlNeXt,一种先进且高效的可控图像和视频生成方法。ControlNeXt 采用简化和精简的架构,消除了重型辅助组件,以最小化延迟开销并减少可训练参数。这种轻量级设计使其能够作为一个即插即用模块,具有强大的鲁棒性和兼容性,并进一步支持与其他 LoRA 权重的集成,从而在无需额外训练的情况下改变生成风格。提出了交叉归一化,用于对预训练大型模型进行微调,处理新引入的参数,从而促进更快和更稳定的训练收敛。通过在各种图像和视频生成基础模型上的广泛实验,展示了本文方法的有效性和鲁棒性。
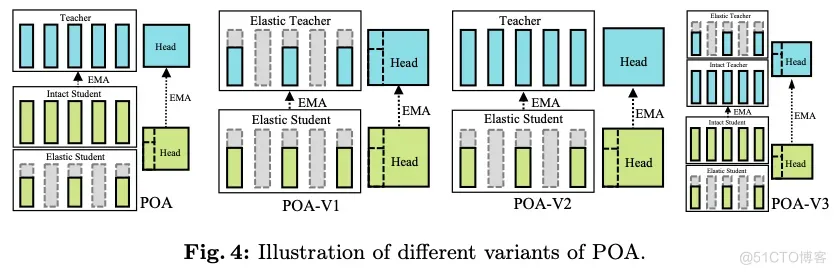
#POA
蚂蚁集团提出同时预训练多种尺寸网络的自监督范式
论文提出一种新颖的POA自监督学习范式,通过弹性分支设计允许同时对多种尺寸的模型进行预训练。POA可以直接从预训练teacher生成不同尺寸的模型,并且这些模型可以直接用于下游任务而无需额外的预训练。这个优势显著提高了部署灵活性,并有助于预训练的模型在各种视觉任务中取得SOTA结果。
论文地址:https://arxiv.org/abs/2408.01031
论文代码:https://github.com/Qichuzyy/POA
Abstract
大规模自监督预训练为一个基础模型处理多种不同的视觉任务铺平了道路。大多数预训练方法在一次训练中训练一个特定大小的单一模型。然而,在现实世界的场景中,由于各种计算或存储限制,需要大量的工作来开发一系列不同大小的模型进行部署。因此,在这项研究中,我们提出了一种新颖的三分支自监督训练框架,称为POA(Pre-training Once for All),来解决上述问题。我们的方法在现代自蒸馏范式中引入了一种创新的弹性student分支。在每个预训练步骤中,我们随机从原始student中抽样一个子网络来形成弹性student,并以自蒸馏的方式训练所有分支。一旦预训练完成,POA允许提取不同大小的预训练模型用于下游任务。值得注意的是,弹性student促进了多个不同大小模型的同时预训练,同时也作为各种大小模型的额外集合,增强了表示学习。大量实验证明了我们的POA的有效性和优势,包括k最近邻、线性探测评估以及多个下游任务的评估。它使用ViT、Swin Transformer和ResNet骨干网络实现了最先进的性能,并通过一次预训练会话生成了大约一百个不同大小的模型。代码可在以下链接找到:https://github.com/Qichuzyy/POA。
Introduction
通过自监督学习在大型模型中学习可泛化的视觉表示,近年来在各种视觉任务上取得了卓越的性能。然而,当部署到现实世界的应用程序时,大型模型必须根据计算、存储、功耗等各种资源限制进行调整。例如,一个良好设计的人工智能产品通常包括一套为不同场景量身定制的模型,比如Gemini Nano、Pro和Ultra。对于一个大型预训练模型,将其部署到具有不同资源约束的多个应用场景的常见解决方案包括额外的权重修剪、知识蒸馏,甚至从头开始重新训练一个小网络,这些都需要大量的开发工作。因此,这个问题引发了一个关键问题:是否可能进行一次预训练以同时生成多个具有不同大小的模型,每个模型都提供足够好的表示。
为了解决这一挑战,论文引入了一种名为POA(Pre-training Once for All)的新型自监督学习范式。POA建立在流行的teacher-student自蒸馏框架之上,具有一个额外的创新性弹性student分支。弹性student分支通过参数共享嵌入了一系列子网络,这是基于观察到对于现代网络结构来说,较小尺寸的模型是较大尺寸模型的子网络。此外,该分支的参数与原始的或完整的studennt共享。在每个预训练步骤中,从完整student中随机抽样一部分参数,形成相应的弹性studennt。原始完整student和弹性student都被训练以模拟teacher网络的输出。teacher本身通过对student参数的指数移动平均(EMA)不断优化,包括采样的弹性student。弹性student有助于在不同参数子集上进行有效和高效的预训练,从而成功地从预训练teacher中提取出高性能子网络,用于后续的下游场景。它还作为一种训练正则化形式,通过强制teacher和各种子网络之间的输出匹配来促进稳定的训练过程。
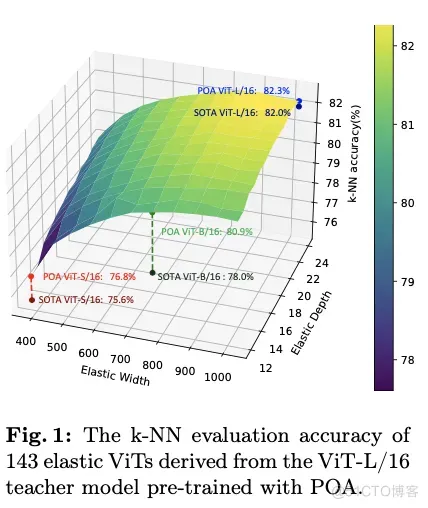
POA代表了第一个能够同时训练多个不同尺寸模型的自监督学习方法,每个模型在不需要进一步预训练的情况下,都能获得适用于不同资源约束的高质量表示。图1显示了通过POA预训练的ViT-L模型提取的143个子网络的k最近邻(k-NN)评估结果。通过选择不同的弹性宽度和深度,预训练teacher模型可以根据可用计算资源定制的适用于下游应用的合适模型,生成足够数量的候选子网络以供选择。值得注意的是,由于在同视图蒸馏上进行了精心设计,每个子网络都经过了良好训练,并表现出优越性能。特别是,ViT-S、ViT-B和ViT-L模型创造了新的基准,与那些由现有方法预训练的模型相比取得了SOTA结果。
为了严格评估方法的有效性,使用三种广泛使用的骨干架构,即ViT、Swin Transformer和ResNet,进行了大量实验。每个骨干架构都在ImageNet-1K数据集上进行了预训练,并使用k-NN和线性探测分类评估,以及在下游密集预测任务进行评估,如目标检测和语义分割。POA在单次预训练会话中跨多种模型尺寸实现了最先进的准确性。
本文的技术贡献总结如下:
POA是第一个将无监督表示学习和一次性模型生成集成到单个预训练会话中的预训练范式,解决了社区很少探讨的一次性预训练挑战。这对实际部署非常重要,因为实际部署通常需要一套模型。- 提出了一个新颖而优雅的组件,称为弹性
student(Elastic Student),具有一系列弹性算子,可以使POA与包括ViT、Swin Transformer和ResNet在内的流行骨干结构兼容,具备生成各种大小模型的能力。此外,还作为模型集成来平滑训练过程并改善学到的表示。 - 通过对
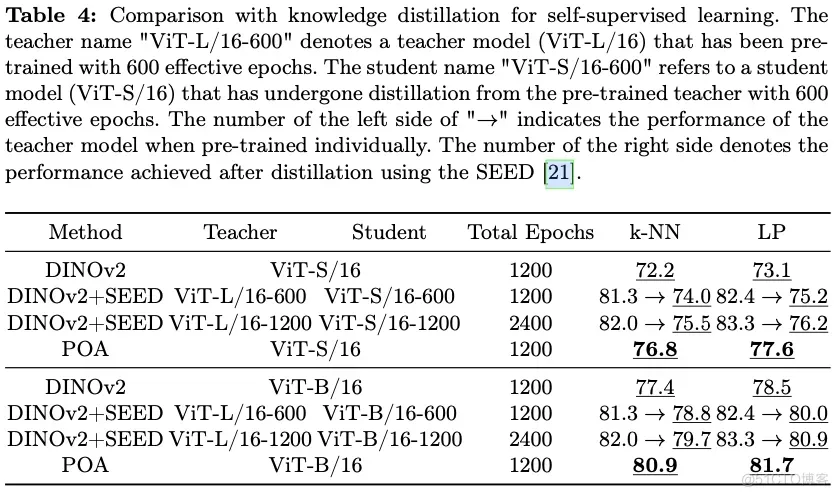
k-NN、线性探测和下游密集任务评估的彻底评估,在多个指标上展现出优于现有最先进预训练方法的性能。此外,将POA与自监督蒸馏(SEED)进行了比较,SEED是一种专为自监督学习设计的知识蒸馏方法,进一步验证了POA的有效性。
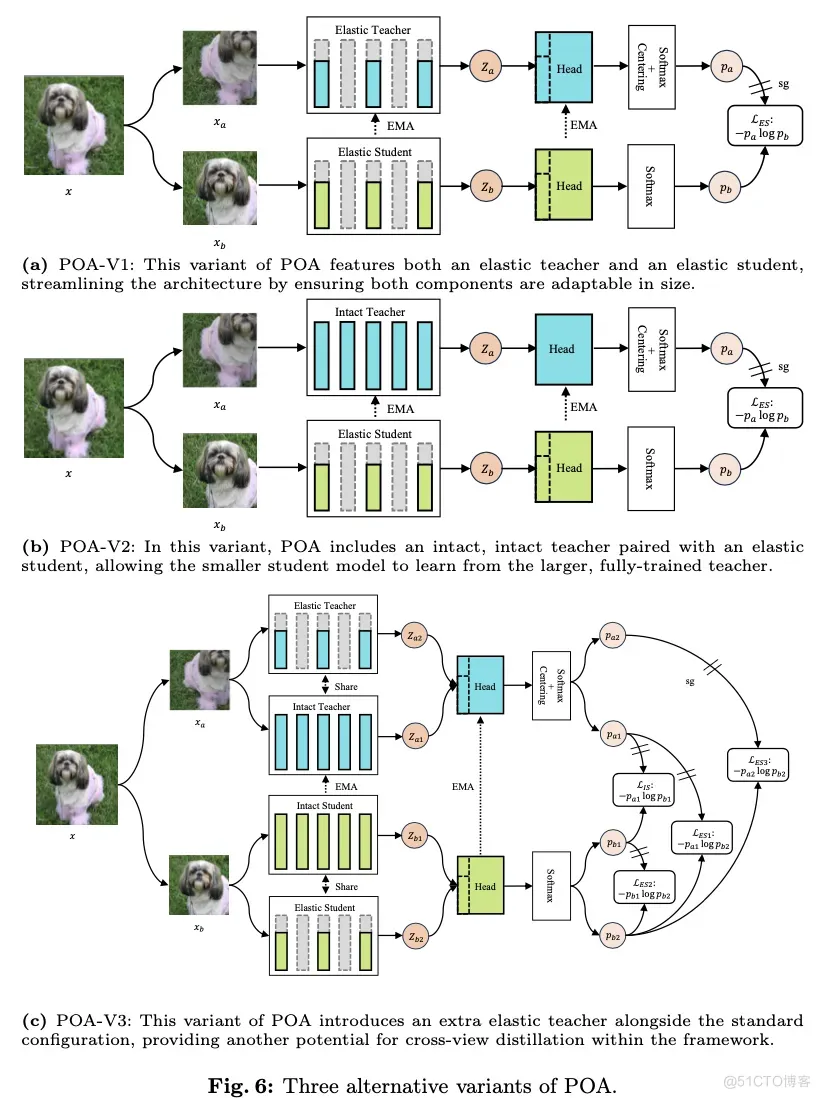
POA Self-supervised Learning Framework
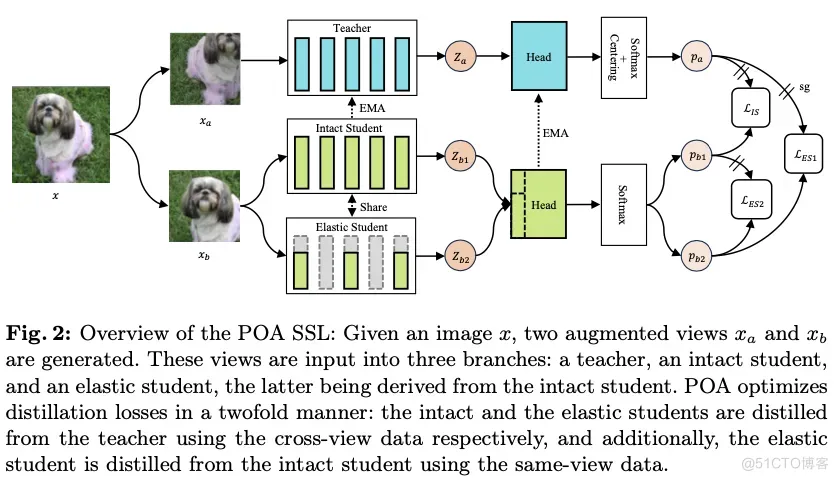
论文的主要目标是通过单次自监督预训练会话来预训练多种规模的模型,受到自蒸馏技术最新进展的启发,提出了一个名为POA的新型SSL(Self-supervised Learning)框架。POA架构如图2所示,包括一个teacher模型、一个完整的student模型、一个弹性student模型以及对应的头部。teacher模型使用student模型的指数移动平均(EMA)进行更新。弹性student模型是完整student模型的派生版本,其主干网络和头部参数是共享的。
在两个方面利用蒸馏技术:完整student和弹性student都是通过使用同一图像不同视图的teacher模型进行蒸馏,而弹性student还通过使用相同视图的完整student进行学习。交叉视图蒸馏作为一种表示学习形式,如所介绍的那样。值得注意的是,除了仅使用完整student进行常规EMA更新外,弹性student在每个预训练步骤中还提供一个随机抽样的子网络,参与teacher模型的EMA优化。这个过程实际上模拟了多个子网络的集成,这在监督学习领域也被证明是有益的。同视图蒸馏是完整student和弹性student之间的标准知识蒸馏,提升了弹性student的质量。
Design of Elastic Student
弹性student是一个子网络,其参数是从完整student中提取的。在transformer主干网络的背景下,宽度指的是标记的维度,而在卷积主干网络中,宽度表示通道数。深度则定义为transformer或卷积网络中基本块的数量。给定宽度和深度的值,会产生一定的网络结构。为简单起见,论文将重点放介绍ViT的弹性设计。
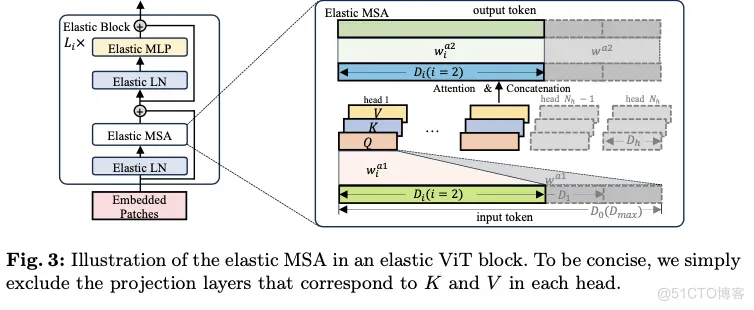
ViT的基本块主要由多头自注意力(MSA)模块和多层感知器(MLP)模块组成。在每个模块之前应用层归一化(LN),并在每个模块后使用残差连接。如图3的左侧所示,弹性块是指在ViT原始基本块中调整宽度后堆叠的弹性MSA、MLP和LN。在论文的方法中,弹性student分支是通过在每个训练迭代中组装特定数量的这些弹性块来构建的。
- Elastic MSA
一个原始或完整的 MSA 模块由三个主要组件组成, 即输入投影层, 包含注意力和连接的操作符, 以及输出投影层。将投影层定义为 , 其中 表示线性转换权重, 表示相应的偏置, 表示层的名称。如图 3 的右侧所示, 给定一个标记维度 , 其中 是注意力头的数量, 是头部维度, 具有长度 的输入序列 最初被投影以形成查询 、键 和值 。为了生成弹性 MSA, 定义了 M+1 个弹性宽度, 包括 , 间隔为 :
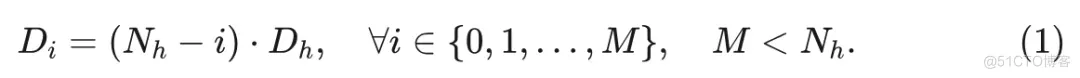
对于每个弹性宽度 , 从完整 MSA 中的相应输入投影层 中提取生成每个头部的 、 和 的权重 和偏置 ,如 和 。这里, 表示用于应对输入维度减少的缩放因子, 计算公式为 。随着宽度的减小, 弹性 MSA 中的注意力头数量自然减少到 。类似地, 对于输出投影层 , 权重 和偏置 被提取为:
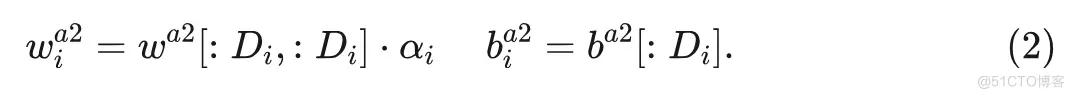
- Elastic MLP
ViT 块中的原始或完整 MLP 模块包含两个投影层。第一层 )将嵌入维度扩展了 倍, 通常在 ViT 结构中设置为 4 。然后, 第二层 ) 将其投影回原始维度。弹性 MLP 的两个层的参数以类似于公式 2 描述的方式提取, 如下所示:
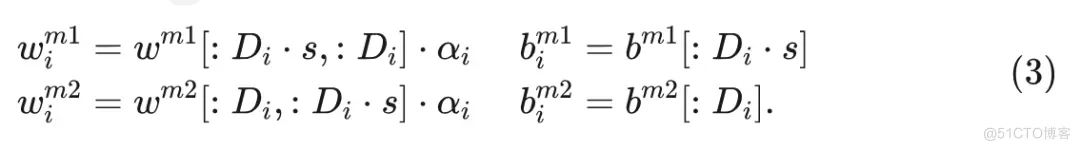
- Elastic LN
对于弹性LN,直接使用原始LN内部参数的前个元素,类似于公式2中的偏置提取。
- Elastic depth
要从包含 个块的完整 ViT 中创建一个包含 个弹性块的子网络, 引入了一组 N+1 个弹性深度,定义为 $L_i=L_{\max }-i, \forall i \in\{0,1, \ldots, N\}, N<l_{\max }$=”” 。对于特定深度=”” $l_i$=”” ,根据块=”” id=”” 在等间隔上选择相应的块。激活深度=”” 的每个块=”” $b=”” i=”” d_j^{l_i}$=”” 可以表示为:<=”” p=””>
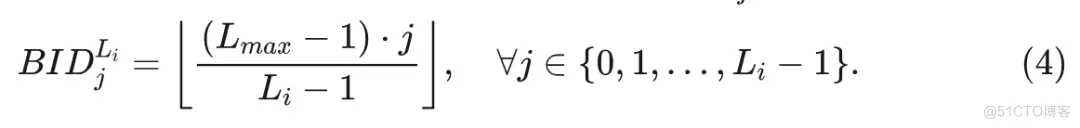
因此,通过结合弹性宽度和深度,可以生成总共个不同的子网络。例如,通过将弹性宽度设置为384,弹性深度设置为12,可以直接从如ViT-L的完整网络中提取一个ViT-S。在预训练的每次迭代中,随机选择其中一个子网络作为弹性student分支。
Distillation between Views
POA 根据其三个分支执行蒸馏。给定输入图像 的一对全局增强视图, 表示为 和 , teacher 编码器 使用 作为输入提取特征 。同时, 被输入到完整 stu dent 编码器 和弹性 student 编码器 中, 分别产生特征 和 。从 teacher 编码器输出的特征 经过 teacher 头部 处理, 然后使用 Sinkhorn-Knopp (SK)算法进行居中处理, 并使用温度缩放 softmax 进行归一化, 生成概率 , 如下所示:
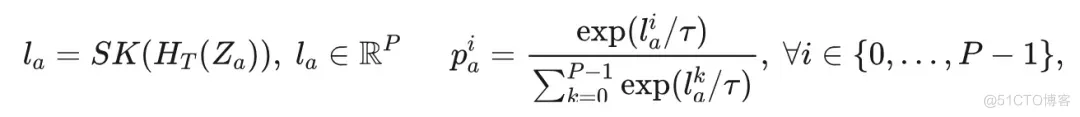
其中 是原型(logits ?)的数量, 是温度参数。类似地, 通过使用 student 头部 和 处理输出来计算完整和弹性 student 编码器的概率 和 。然后, 这些输出通过一个针对 student 量身定制的温度参数 的温度缩放 softmax 函数进行处理。值得注意的是, 和 共享相同的参数, 只是 的第一个投影层进行公式 2 的相应调整,以便对齐相应的维度。为简单起见, 省略了 和 的显式表达式, 因为它们遵循与公式 5 类似的计算方式。对于完整 student 分支, 使用跨视图数据从 teacher 进行蒸馏如下:

弹性student分支在POA框架中发挥着至关重要的作用。为了确保这一分支的充分训练,采用了从teacher和完整student分支进行的双重蒸馏。第一次蒸馏涉及到teacher模型,利用跨视图数据来引导表示学习。第二次是与完整student模型进行的蒸馏过程,使用同视图数据。这种同视图蒸馏负责将完整student学到的表示转移到弹性student分支。这种双重蒸馏过程的损失函数制定如下
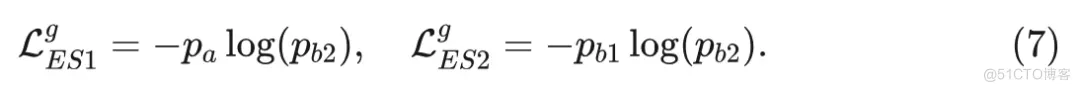
请注意,在这两个损失函数中,对所有原型求和,以计算相应概率分布之间的交叉熵损失。
Overall Loss of POA
根据SSL方法,采用多裁剪策略从单个图像中创建各种失真视图。除了之前提到的两个全局视图外,还生成 个分辨率较低的局部视图 。这些局部视图由两个student共同处理,以促进局部到全局的对应关系。完整和弹性student的局部蒸馏损失计算如下:
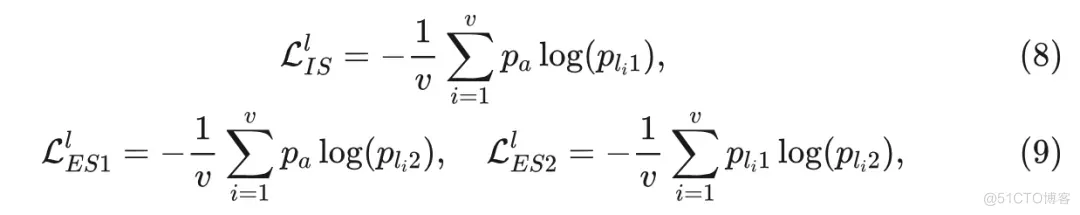
其中, 和 分别是完整和弹性 student 分支对于局部视图 产生的概率。完整和弹性 student 的总蒸馏损失通过将它们与因子 相加来计算:
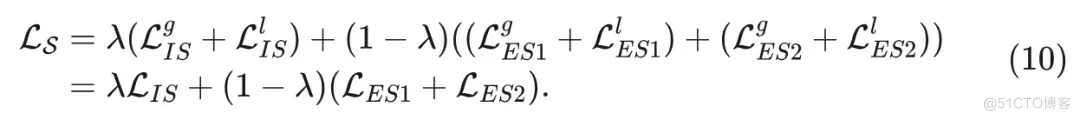
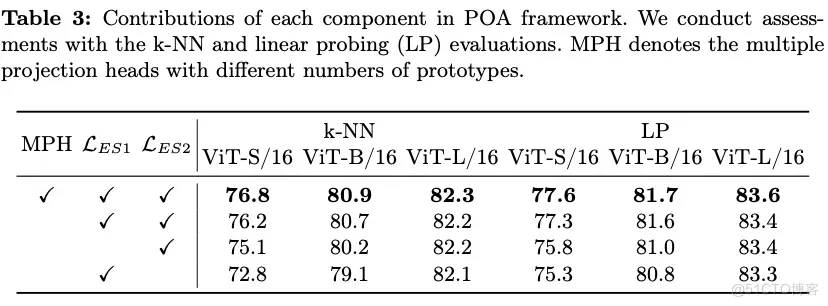
为了确保弹性 student 的每个子网络都得到充分的训练, 在主干网络之后引入了多个投影头 (MPH)。每个投影头具有完全相同的结构,只是原型数量不同。对于每个投影头,根据公式 1 0 计算完整和弹性 student 的蒸馏损失 。最终, 在具有 个投影头的 POA 框架中, 整体损失函数被表述为: 。
Experiments
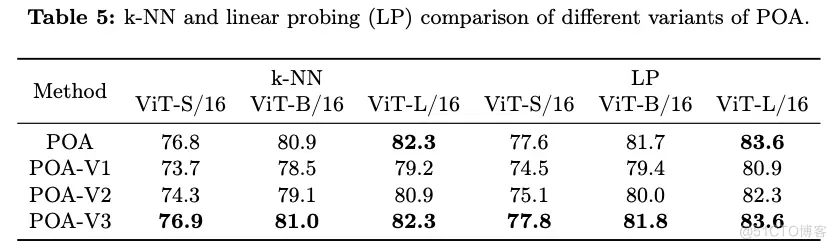
#HyperSOR
显著性程度预测新SOTA!基于上下文感知的超图网络框架
本文瞄准图像中物体显著程度预测问题,提出了一种新颖的上下文感知超图神经网络框架。通过深入分析大规模的显著物体数据集,揭示了场景上下文对于物体显著程度预测的重要性,并据此构建了一个能够捕捉场景语义关系并预测物体显著程度的深度模型HyperSOR。
1.论文简介
本文介绍发表于IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI 2024)上的工作“HyperSOR: Context-aware Graph Hypernetwork for Salient Object Ranking”。该工作瞄准图像中物体显著程度预测问题,提出了一种新颖的上下文感知超图神经网络框架。通过深入分析大规模的显著物体数据集,揭示了场景上下文对于物体显著程度预测的重要性,并据此构建了一个能够捕捉场景语义关系并预测物体显著程度的深度模型HyperSOR。该模型在显著性程度预测和场景图生成等任务上均展现出了SOTA性能。本文的主要贡献如下:
1.建立了一个大规模的显著物体排序(Salient Object Ranking,SOR)数据集,并提供了物体分割掩模、显著值和场景图的标注。
2.深入挖掘了显著物体排序的任务特点,并获得了关于场景上下文与物体显著程度之间相关性的一些发现。
3.提出了一个新颖的基于上下文感知的超图网络框架HyperSOR,通过显式学习场景图来利用场景上下文引导显著物体排序。
论文地址:https://ieeexplore.ieee.org/document/10443257
数据集地址:https://github.com/MinglangQiao/SalSOD
2. 数据库构建与分析
本文构建了一个新的数据库SalSOD,包含24,373张图像,以及图像内显著物体的多重标注:1) 语义分割掩膜和物体框,2) 物体显著值和显著程度排序,3) 场景图。下图展示了数据集的构建过程:(I)通过结合SALICON中的眼动标注数据和COCO的分割掩膜进行物体显著程度标注,(II)通过手动筛除不良样本进行标注细化,(III)通过清洗和对齐Visual Genome中的场景图获取场景图标注。图2展示了构建数据集的部分样例。
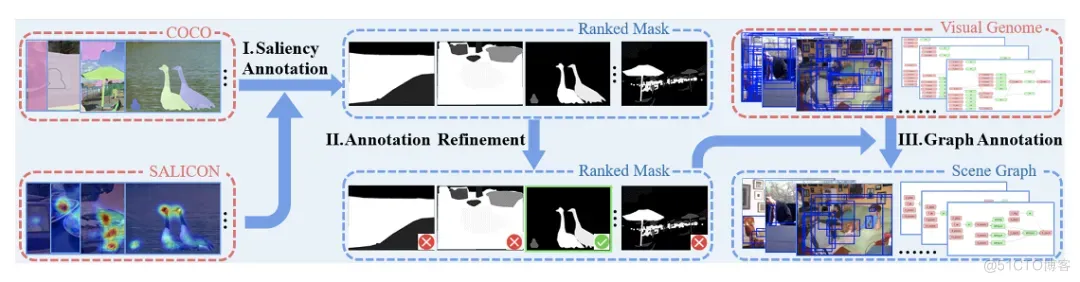
图1 数据库构建示意图
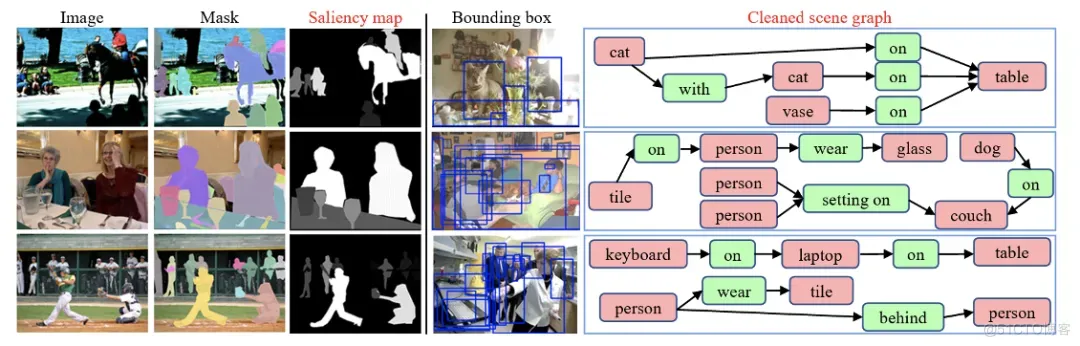
图2 数据库图像和标注示例
基于构建的数据集,我们分析发现,图像中物体的显著值与场景上下文信息密切相关。比如,当图像的场景图标注中,物体与其他对象具有较多的语义关联时,物体越容易具有较高的显著值,如图3所示。其原因可能在于,场景图标注人员在标注过程中,倾向于对显著/主体的物体进行更多的标注[1]。这个现象在场景图数据库和部分图像描述数据库中均有所体现。受此启发,我们提出利用场景图中的物体语义关联引导物体显著程度的预测。
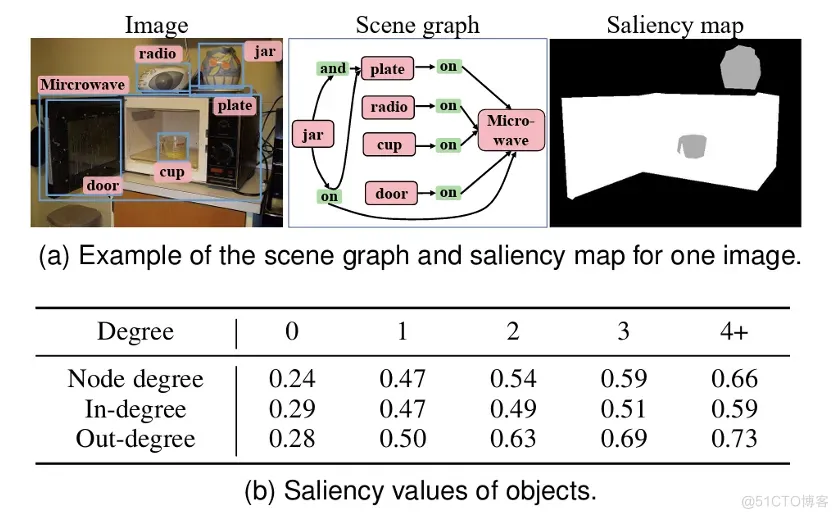
图3 物体显著值与物体语义关联数目间的关系
- 方法① HyperSOR的总体框架
图4是本文所提HyperSOR方法的框架图,HyperSOR方法由初始图(Initial Graph,IG)模块、场景感知图(scene perception graph,SPG)模块和排序预测图模块(ranking prediction graph,RPG)模块三个部分组成。其中,IG模块主要用于检测和分割物体,提取物体特征并构建融合物体语义与几何特征的初始图表征,供后续的SPG模块和RPG模块使用。SPG模块包含多层图注意力网络,用于学习物体间的语义关联并生成场景图。与SPG模块并行,IG模块的初始图表征也被输入到RPG模块以预测物体的显著性分数。RPG模块包含多层图注意力网络和超图引导网络(Graph hypernetwork),后者可将SPG模块捕获的场景上下文转移到RPG模块以指导物体显著分数的推理。最后,预测的显著分数与相应的分割掩模结合生成显著图。
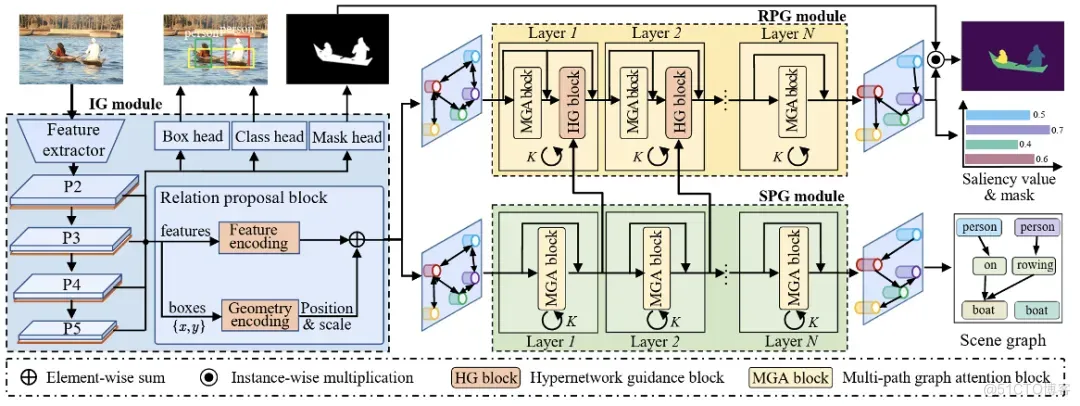
图4 网络框图
接下来我们将详细介绍IG、SPG和RPG模块。
② 初始图(IG)模块
在HyperSOR方法中,初始图(IG)模块被用于物体分割和图初始化。
物体分割。 本文应用 Mask R-CNN 进行物体分割, 得到物体区域以及相应的特征图 , 其中 n 是物体的数量。最终, 这些特征图被送入边界框、类别和掩膜头, 以推断出边界框图 、对象类别 和分割掩膜图 。
图初始化。 根据分割结果,构建包含物体表征和物体间关系的初始图。初始图中除了物体节点外,还包含关联节点,以更好地学习场景上下文信息。每个节点由一个初始特征向量表示, 设 表示第 i 个对象节点的初始向量, 而 是第 i 个和第 j 个对象节点之间谓词节点的初始向量,则物体节点和关联节点表示为
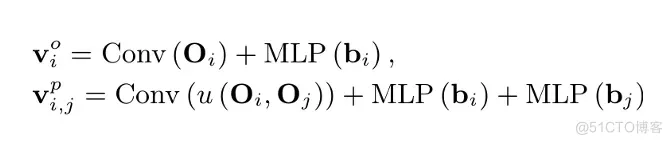
在上述方程中, 和 是第 i 个和第 j 个对象的特征图, 而 和 是它们的边界框。此外, 是卷积块, 用于将特征图投影到高维特征向量中, 而 是联合函数, 用于获得两个边界框的联合区域。
与物体检测中的对象提议类似, IG 模块为输入图像中的物体提供关联提议。为此, IG 模块估计物体间存在关联的置信度分数, 然后过滤掉不必要的关联, 并保留重要的关联。具体地, 设 表示三元组 的两条边的置信度分数, 则可通过考虑对象的语义和几何分数来计算, 如下所示:
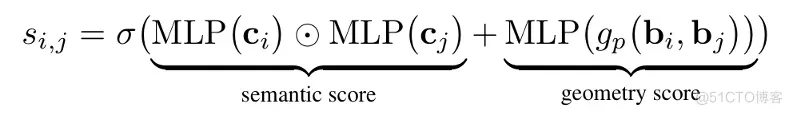
其中 和 分别为物体 i 和 j 的类别概率。 表示映射函数, 将边界框 和 映射为高维向量。在获得所有关联的置信度分数 后, 保留得分最高的 条边作为初始关联。最后, 使用初始节点特征和保留的关联构建初始图, 然后将其输入到 SPG 模块和 RPG 模块进行场景图生成和显著分数预测。
③ 场景感知图(SPG)模块
基于前文的数据分析, 物体的显著值与场景上下文高度相关, 因此本节设计了一个场景感知图模块来生成输入图像的场景图, 并捕捉场景上下文信息用于引导显著分数预测。SPG 模块包括 N 层多路径图注意力 (multi-path graph attention, MGA) 模块, 这些模块被用于更新初始图中每个节点的特征。SPG 模块的最后一层生成场景图, 包括每个对象的预测类别 和谓词 。
MGA模块。 初始图中包括了物体节点和谓词节点,前者包含三种连接方式,即物体→谓词、谓词→物体和物体→物体;而后者包含两种连接方式,即物体→谓词,谓词→物体。
对应地,我们在MGA块中为更新物体和谓词节点的特征设计了两条独立的路径。如下图所示,两种类型的节点通过两条路径分别进行节点特征的聚合与更新。
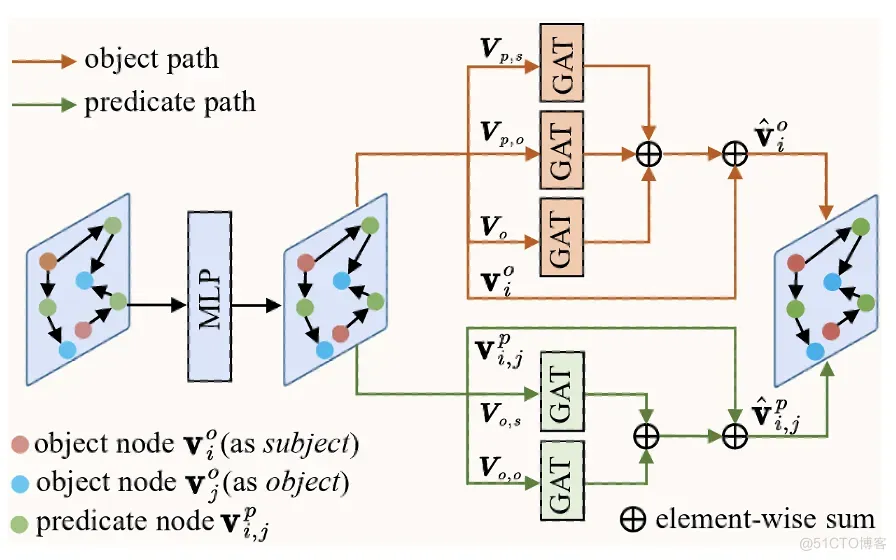
图5 MGA模块示意图
在物体节点更新路径中,三种类型的邻居节点分别被聚合以更新每个物体节点的特征。
具体来说,以第i个对象节点作为目标节点,邻居节点包括:
(1)在三元组主语→谓词→宾语中,目标节点为主语时的邻居谓词节点。对于这些节点,我们将特征集记为,目标节点是主语}。
(2)在三元组主语→谓词→宾语中,目标节点作为宾语的邻近谓词节点。对于这些节点,我们将特征集记为,目标节点是宾语}。
(3)其他物体节点。对于这些节点,我们将特征集记为 。这里我们参照[3]在聚合时连接所有物体节点的方式,以捕捉物体节点之间的潜在关系。
于是,第i个物体节点的特征可以按照以下方式进行更新:
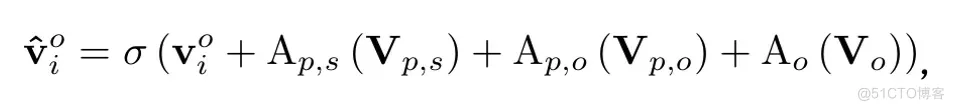
其中, 和 表示三个不同参数的图注意力网络[3](graph attention network,GAT)。这里选择GAT作为聚合函数主要基于以下两点考虑:1) GAT可以学习不同邻居节点的重要性并以注意力的方式进行聚合,因此对于场景图生成和物体显著分数预测的任务十分有效。(2) GAT在特征聚合方面具有较好的计算效率,因为它可以通过自注意力和参数共享的方式在不同的节点上并行计算。
在谓词节点的更新路径中, 按照类似的方式进行谓词节点特征的聚合与更新。在节点的关系三元组 $中v_{i, j}^p 、 v_i^o和v_j^o是相应节点的特征则谓词节点v_{i, j}^p$ 的特征更新过程可以表述为:
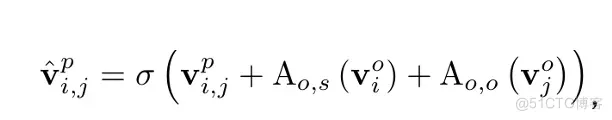
其中, 和 是两个不同的 GAT 网络, 而 表述 更新后的特征。
④ 排序预测图(RPG)模块
本节设计了RPG模块预测每个物体的显著值,进而得到物体的显著程度排名。与SPG模块类似,RPG模块也是建立在N层网络结构上,其中每层包含一个MGA块和一个超网络引导(hypernetwork guidance, HG)模块。其中,MGA模块用于更新图中的节点特征,而HG模块用于传递SPG模块学到的场景上下文信息。如下图所示,RPG模块的最后一层输出 个物体的显著值 ,它们与相应物体的分割掩模结合,生成SOR的最终显著性图。下面介绍HG模块的详细结构。
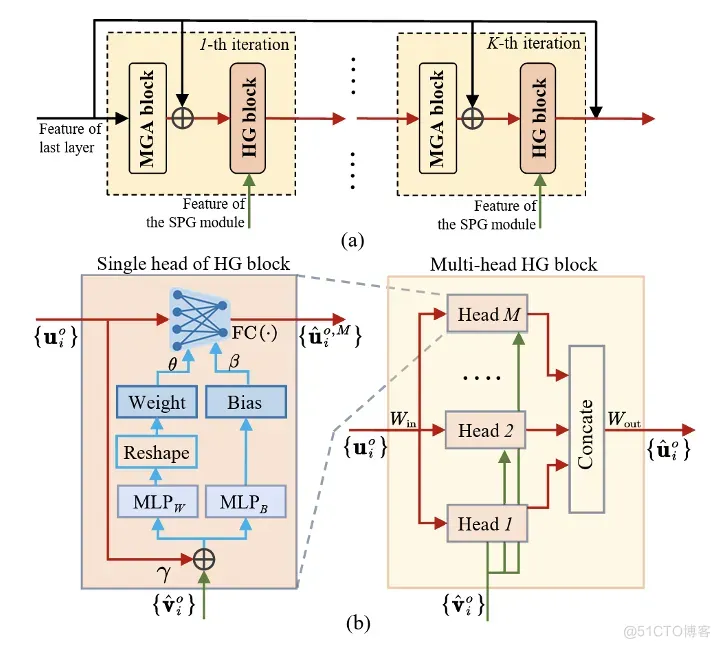
图6 RPG模块和HG模块示意图
HG模块。 即使对于同一类型的物体,其显著值也会随着场景上下文的变化而变化。因此,在RPG模块中,推断物体显著值的方式应根据场景上下文动态变化。对此,我们设计了HG模块,将SPG模块中的特征所包含的场景上下文信息转化为RGP模块中的模型参数,从而动态引导RGP中的特征更新过程。如图6(b)所示,HG模块结合了多头和超网络机制。以输入初始图中的第 个物体节点为例, 和 分别表示第 个物体节点的输入和输出的特征, 表示 SPG 模块中更新后的物体特征, 则 HG 模块的输出特征 可以在 条件下通过一个动态全连接层 获得:
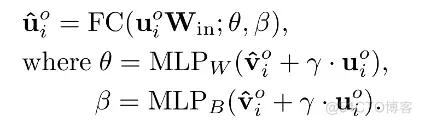
在上述方程中, 是一个可学习的矩阵, 用于降低输入特征的维度, 以减少计算复杂度。此外, 和 是全连接层 的可学习权重和偏置, 由两个多层感知机 (MLP) 生成, 即 ) 和 。如图 所示, MLP 的输入由 和 组成, 其中 为二者相加时的超参数。
为提高模型的学习能力,我们进一步设计了多头结构的HG模块,通过多个并行的超网络头来共同引导特征更新过程。假设HG块中有M个头,则M头HG块的结构图6 (b)右侧的子图所示,该结构可以表述如下:
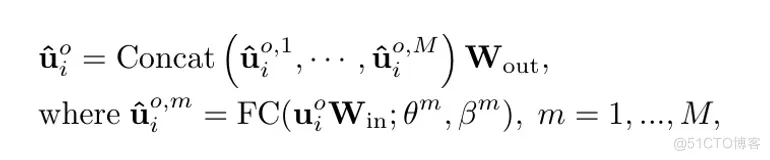
其中, 是一个可学习的矩阵, 它通过线性变换恢复输出特征的维度。在 HG 块中, 每个谓词节点的特征 也更新为 , 其更新方式与物体节点 相同。
- 实验与结果① 评价指标
为了评估显著物体排序的性能,本文采用了3个现有的评价指标,即 siris显著物体排序指标(siris’ salient object ranking,SSOR)、分割感知显著物体排序指标(segmentation-aware SOR,SA-SOR)和平均绝对误差(mean absolute error,MAE)。此外,本文还提出了一个新的评价指标 — 对称显著物体排序指标(symmetrical salient object ranking,SYSOR),其综合考虑了模型输出中物体过度预测和预测不足的情形。如图7所示,当预测显著图中存在冗余物体时,SSOR和SA-SOR可能无法准确地评估结果。

图7 不同评价指标的结果示例
为了解决该问题,本文提出了一种新的指标SYSOR, 通过正向和反向两次匹配分别计算预测结果和标注结果的相关系数,然后取二者的平均值作为评估结果。因此,SYSOR既能够处罚预测结果中缺失物体的情况,也能处罚存在冗余物体的情况。具体而言,给定标注的显著物体,首先计算标注的分割掩膜与预测的分割掩膜之间的IoU,并根据计算结果匹配标注物体在预测物体中对应的对象。对于没有匹配上的物体, 将其对应的预测物体的显著等级设置为 0 作为处罚。设 表示标注物体的显著性等级, 表示经过匹配后的预测物体的显著等级。另一方面, 基于预测物体在标注物体中进行匹配, 并获得 和 。通过这种方式, 当预测物体中存在缺失物体或者冗余物体时, 都会导致 SYSOR 的结果下降。最终, SYSOR 的计算过程可以表述为
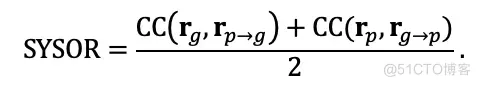
其中,为计算相关系数的操作。数学上,上式的第一项能够处罚预测结果中的缺失物体,第二项能够处罚预测结果中的冗余物体。如图7所示,SYSOR指标给出的结果更加合理。
② 显著物体排序任务评估
针对显著物体排序任务,我们在SalSOD、Siris和PASCAL-S数据库上均进行了实验。
从表格1可以看出,在SalSOD数据库上,本文的HyperSOR方法在4个指标上都显著超过了11个对比方法。特别地,相比于第二好的方法,HyperSOR在SYSOR和SA-SOR指标上分别获得了0.028和0.061的提升,提升幅度分别为4%和9.3%。此外,相比于RSDNet[120]、Liu[124]和Fang[127], 本文方法将SYSOR指标分别提升了0.188、0.047和0.028。在其他数据库上,本文方法在大部分指标上依然超过了对比方法。此外,从图8可以看出,本文HyperSOR方法的显著图结果更加接标注结果。上述结果表明,HyperSOR能够在各种场景下更准确地分割物体,并对物体显著程度进行更准确地排序。
③ 消融实验
IG模块作用分析。 为了分析IG模块的作用,将初始图的关联提议作为二分类任务。
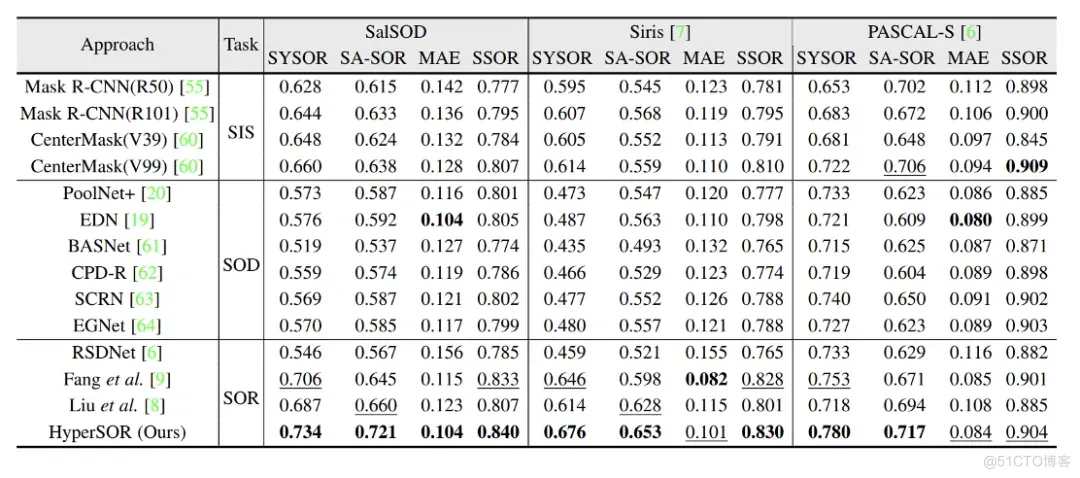
表1 本文方法和对比方法在不同数据库上的显著物体排序结果

图8 不同方法的显著图对比
具体地,对比了IG模块与三种同期领先的方法在VG150[219]测试集上的性能,包括IMP[219]方法(Iterative Message Passing IMP)、 MSDN[227]方法(Multi-level Scene Description Network)和Graph RCNN[217]方法。图9画出了本文方法的SPG模块和三种基准方法的ROC曲线。
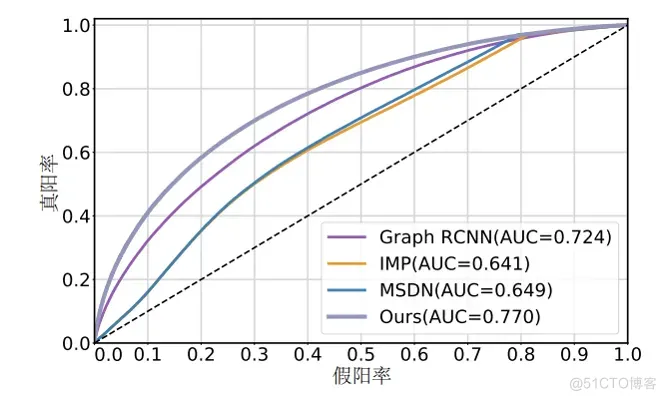
图9 不同方法在初始图关联提议任务上的ROC曲线
从实验结果可以看出,IG模块的效果要好于基准方法,这验证了IG模块的有效性。
HG模块作用分析。 首先,将RPG模块中的HG模块移除掉,记为“w/o HG”。然后,将HG模块中的超网络分别替换为经典的特征操作,包括特征拼接、特征求和、特征相乘。在表格2中,这几种模型分别记为“HG-CONCAT”、“HG-SUM”、“HG-MULTI”。从表2中可以看出移除HG模块后模型性能显著下降。此外,可以看出与“w/o HG”相比,特征拼接、特征求和、特征相乘等操作可以提高显著物体排序的性能,但仍旧低于使用超网络的HG模块。上述结果表明:在HG模块中使用超网络能够更有效地利用与显著物体排序相关的上下文信息,适用于不同的视觉场景。
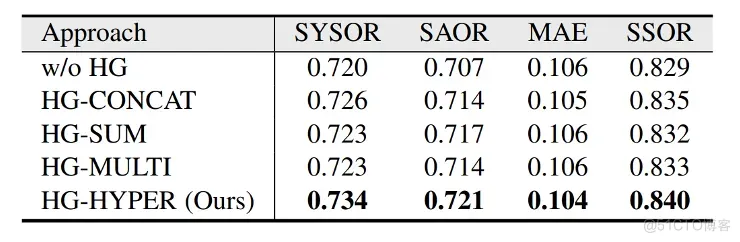
表2 不同HG模块配置下的显著物体排序结果
④ 场景图生成任务评估
为了验证了HyperSOR方法生成场景图的效果,对SPG模块在VG150上进行场景图生成评估,并与IMP[219]、 Unbiased[230]、 MSDN[227]和Graph RCNN[217]方法进行比较。生成的场景图在两个子任务上进行评估:场景图检测(scene graph detection, SGDet)和场景图分类(scene graph classification, SGCls)。如表3所示 ,SPG模块的SGDet和SGCls指标均高于基准方法。这表明SPG模块能够有效捕捉图像中的上下文信息并生成场景图。
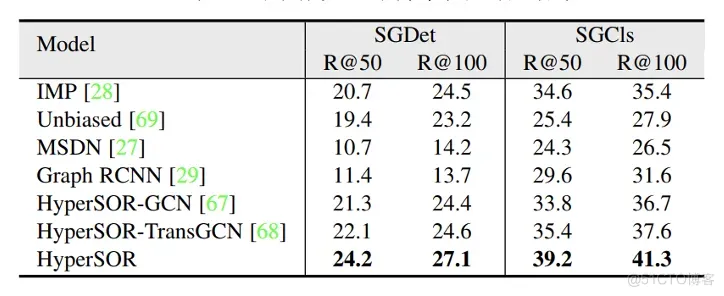
表3 不同方法的场景图生成结果
总结与展望
本文提出了一种场景上下文感知的显著物体排序方法。具体地,本文构建了一个包含24,373张图像的显著物体排序数据库,并在显著物体及其显著程度标注的基础上,引入了场景图标注数据。基于该数据库进行分析,发现物体的显著值与场景上下文信息密切相关。受此启发,设计了一种场景上下文感知的超图网络模型用于显著物体排序。在本文方法中,构建了一个初始图模块检测物体并构建基于语义和几何特征的初始图表征。此外,设计了一个基于图神经网络的多层场景图感知模块捕捉上下文信息并生成场景图。同时,设计了一个基于超网络的排序预测图模块,动态地传递场景上下文信息并引导显著物体排序。充分的实验表明:本文所提的HyperSOR方法在三个显著物体排序数据库上均超过了十一种领先的对比方法。开发板商城 天皓智联 TB上有视觉设备哦 支持AI相关~ 大模型相关也可用whaosoft aiot
在未来的工作中,探索HyperSOR方法的实际应用将是一个有趣的研究方向。比如,模型预测的显著图可以被用在多种计算机视觉和多媒体任务中,包括定位感兴趣区域、图像压缩、物体追踪和图像质量评价等。此外,将本文方法扩展到视频领域也是一个有意义的方向,比如设计动态的图神经网络学习物体在不同帧上的时序关联。
#SCNet
北大、哈工大、清华联合提出无需GT的自监督图像重建网络学习方法,代码已开源!
一、论文信息
- 论文标题:Self-Supervised Scalable Deep Compressed Sensing(自监督可变采样率的深度压缩感知)
- 论文作者:Bin Chen(陈斌), Xuanyu Zhang(张轩宇), Shuai Liu(刘帅), Yongbing Zhang†(张永兵), and Jian Zhang†(张健)(†通讯作者)
- 作者单位:北京大学深圳研究生院、清华大学深圳国际研究生院、哈尔滨工业大学(深圳)
- 发表刊物:International Journal of Computer Vision (IJCV)
- 发表时间:2024年8月13日
- 正式版本:https://link.springer.com/article/10.1007/s11263-024-02209-1
- ArXiv版本:https://arxiv.org/abs/2308.13777
- 开源代码:https://github.com/Guaishou74851/SCNet
二、任务背景
作为一种典型的图像降采样技术,自然图像压缩感知(Compressed Sensing,CS)的数学模型可以表示为,其中是原始图像真值(Ground Truth,GT),是采样矩阵,是观测值,是噪声。定义压缩采样率为。
图像CS重建问题的目标是仅通过观测值和采样矩阵来复原出GT 。基于有监督学习的方法需要搜集成对的观测值和GT数据,以训练一个重建网络。然而,在许多现实应用中,获得高质量的GT数据需要付出高昂的代价。
本工作研究的问题是自监督图像CS重建,即在仅给定一批压缩观测值和采样矩阵的情况下,训练一个图像重建网络。现有方法对训练数据的利用不充分,设计的重建网络表征能力有限,导致其重建精度和效率仍然不足。
三、主要贡献
- 技术创新点1:一套无需GT的自监督图像重建网络学习方法。
如图1(a)所示,在训练过程中,我们将每组观测数据随机划分为两个部分和,并输入重建网络,得到两个重建结果和。我们使用以下观测值域损失函数约束网络产生符合“交叉观测一致性”的结果:
进一步地,如图1(b)所示,为了增强网络的灵活性和泛化能力,使其能够处理任意采样率和任意采样矩阵的重建任务,我们对和进行随机几何变换(如旋转、翻转等),得到数据增广后的和,然后使用以下图像域损失函数约束网络,使其符合“降采样—重建一致性”:
其中和、和,以及和分别是随机生成的采样矩阵、噪声和采样率。
最终,结合以上两个损失函数,我们定义双域自监督损失函数为。
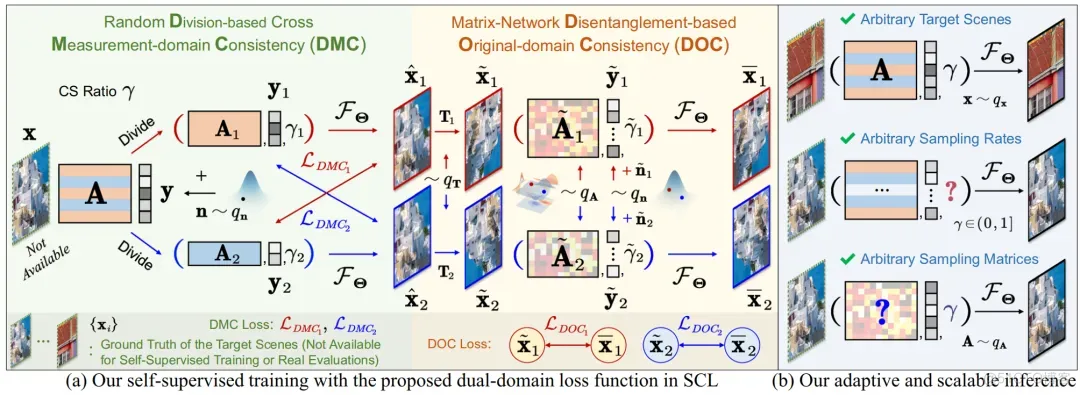
图1:提出的损失函数。
在训练阶段,我们使用以无需GT的自监督方式,学习一个支持任意采样率和采样矩阵的重建网络;在测试阶段,除了可以直接使用训练好的网络重建图像外,也可以使用在单个或多个测试样本上微调网络,以进一步提升重建精度。
- 技术创新点2:一个基于协同表示的图像重建网络。
如图2所示,我们设计的重建网络首先通过一个卷积层从观测值、采样矩阵与采样率中提取浅层特征,并依次注入可学习的图像编码和位置编码。接着,使用多个连续的深度展开网络模块对特征进行增强,每个模块对应于近端梯度下降算法的一个迭代步骤。最后,重建结果由一个卷积层和一个梯度下降步骤产生。
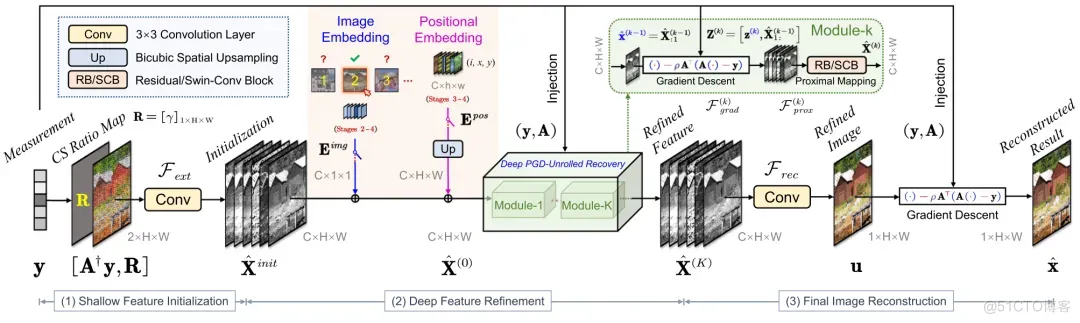
图2:提出的图像重建网络。
我们设计的重建网络结合了迭代优化算法的显式结构设计启发与神经网络模块的隐式正则化约束,能够自适应地学习待重建图像的深度协同表示,展现出强大的表征能力,在重建精度、效率、参数量、灵活性和可解释性等方面取得了良好的平衡。
四、实验结果
得益于提出的双域自监督损失函数与基于协同表示的重建网络,我们的方法在多个测试集(Set11、CBSD68、Urban100、DIV2K、我们构建的数据集)、多种数据类型(模拟/真实数据、1D/2D/3D数据)以及多个任务(稀疏信号恢复、自然图像压缩感知、单像素显微荧光计算成像)上均表现出优异的重建效果。同时,我们的方法展现出了对训练时未见过的采样矩阵与采样率的出色泛化能力。
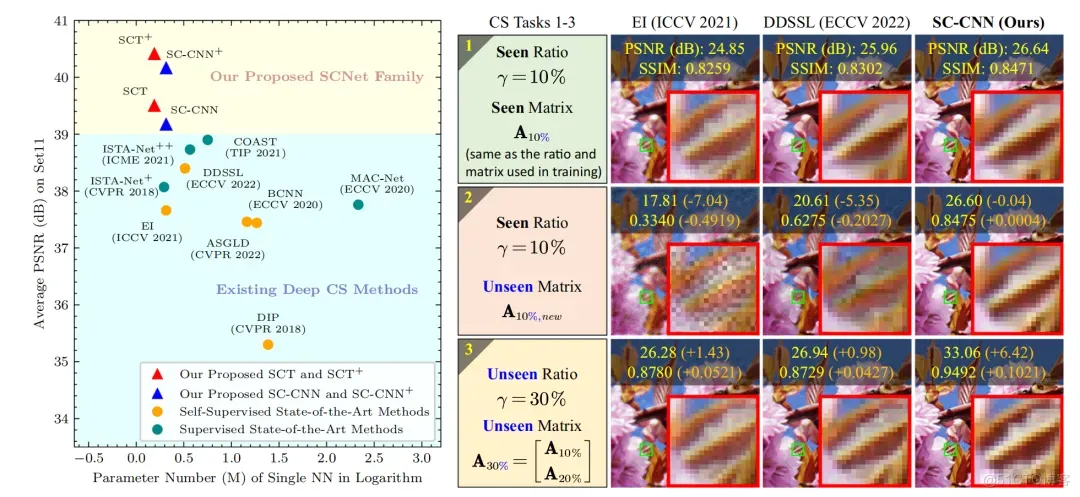
图3:我们的方法与现有其他方法的对比结果。
更多方法细节、实验结果与原理分析可参考我们的论文。
五、实验室简介
视觉信息智能学习实验室(VILLA)由张健助理教授于2019年创立并负责,专注于AI计算成像与底层视觉、可控内容生成与安全、三维场景理解等研究领域,已在Nature系列子刊Communications Engineering、SPM、TPAMI、IJCV、TIP、NeurIPS、ICLR、CVPR、ICCV和ECCV等高水平国际期刊和会议上发表了50余篇论文。
在计算成像与底层视觉方面,张健助理教授团队的代表性成果包括优化启发式深度展开重建网络ISTA-Net、COAST、ISTA-Net++,联合学习采样矩阵压缩计算成像方法OPINE-Net、PUERT、CASNet、HerosNet、PCA-CASSI,以及基于信息流增强机制的高通量广义优化启发式深度展开重建网络HiTDUN、SODAS-Net、MAPUN、DGUNet、SCI3D、PRL、OCTUF、D3C2-Net。团队还提出了基于自适应路径选择机制的动态重建网络DPC-DUN和用于单像素显微荧光计算成像的深度压缩共聚焦显微镜DCCM,以及生成式图像复原方法Panini-Net、PDN、DEAR-GAN、DDNM,受邀在信号处理领域旗舰期刊SPM发表专题综述论文。本工作提出的自监督重建网络学习方法SCNet进一步减少了训练重建网络对高质量GT数据的依赖。
如有侵犯您的版权,请及时联系3500663466#qq.com(#换@),我们将第一时间删除本站数据。












暂无评论内容