分类
标签
排序

SeaTunnel二次开发进阶:企业级复杂场景下的亿万级数据处理与智能容错机制
作者:史德昇 随着数据来源的不断复杂化及业务需求的快速演进,通用的数据集成框架在实际落地过程中往往面临诸多挑战:数据结构不规范、字段缺失、敏感信息混杂、数据语义不清等问题频繁出现。...
读数据自助服务实践指南:数据开放与洞察提效19质量可观测性服务
1. 质量可观测性服务 1.1. 数据用户需要确保峰值实际上反映了真实情况,而不是有数据质量问题的结果 1.2. 导致质量问题的情况 1.2.1. 不正确的源模式更改 1.2.2. 数据...
读数据自助服务实践指南:数据开放与洞察提效18模型部署服务
1. 模型部署服务 1.1. 编写一次性脚本来部署模型并不困难 1.2. 针对模型训练类型(在线与离线)、模型推理类型(在线与离线)、模型格式(PAML、PFA、ONNX等)、终端类型...

读数据自助服务实践指南:数据开放与洞察提效17管道编排服务
1. 管道编排服务 1.1. 查询或程序的运行时实例称为作业 1.1.1. 作业调度需要考虑到正确的依赖项 1.2. 作业管道需要按照特定的顺序进行编排,从数据接入到数据准备再到数据...

从零开始学Flink:开启实时计算的魔法之旅
在凌晨三点的数据监控大屏前,某电商平台的技术负责人突然发现一个异常波动:支付成功率骤降15%。传统的数据仓库此时还在沉睡,而基于Flink搭建的实时风控系统早已捕捉到这个信号,自动触发预警...
读数据自助服务实践指南:数据开放与洞察提效16查询优化服务
1. 查询优化服务 1.1. 好查询和坏查询之间的差别非常明显 1.2. 重复且长时间运行的查询是需要调优的 1.3. 痛点 1.3.1. 像Hadoop、Spark和Presto这样的查询引擎有太多...
读数据自助服务实践指南:数据开放与洞察提效15A_B测试服务
1. A/B测试服务 1.1. 部署多个模型并将其呈现给不同的客户集 1.2. 基于客户使用的行为数据来选出更好的模型 1.3. A/B测试(也称为桶式测试、拆分测试或受控实验)是一个从...
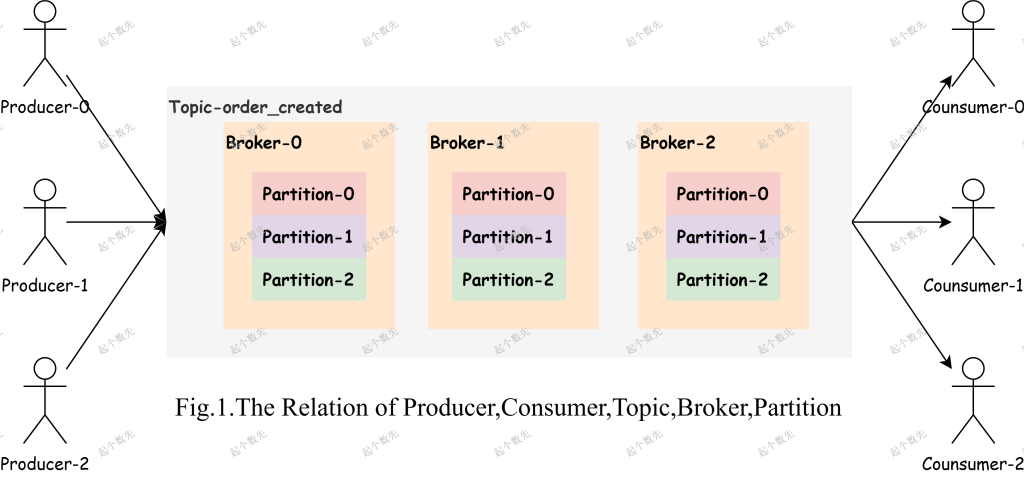
Kafka如何快速的入个门呢?
Kafka是什么? Kafka是Apache基金所维护的一个中间件项目,它是一个开源的分布式事件流平台,广泛用于构建高性能的数据管道、流式分析、数据集成以及关键业务应用。 这里面有几个点需要说明一下...
读数据自助服务实践指南:数据开放与洞察提效14持续集成服务
1. 持续集成服务 1.1. 通常,机器学习模型管道随着源模式的变化、特征逻辑、依赖数据集、数据处理配置、模型算法、模型特征和配置而不断演进 1.2. 在传统的软件工程中,代码是不...

boost_signals2开发者指南:无需依赖boost库的C++事件处理的优雅解决方案
引言 C++开发中,实现组件间松耦合通信一直是一个挑战。传统的回调函数和观察者模式虽然可行,但往往导致代码复杂且难以维护。Boost.Signals库提供了一种优雅的解决方案,通过信号与槽机制实现...