分类
标签
排序

成为Apache SeaTunnel贡献者的N种方式
如何参与开源贡献 参与开源贡献的常见方法有多种: 1)参与解答 在社区中, 帮助使用过程中遇到困难的人,帮他们解释框架的用法也算是一种贡献。 2)文档贡献 帮助框架来完善文档,比如说将英文...
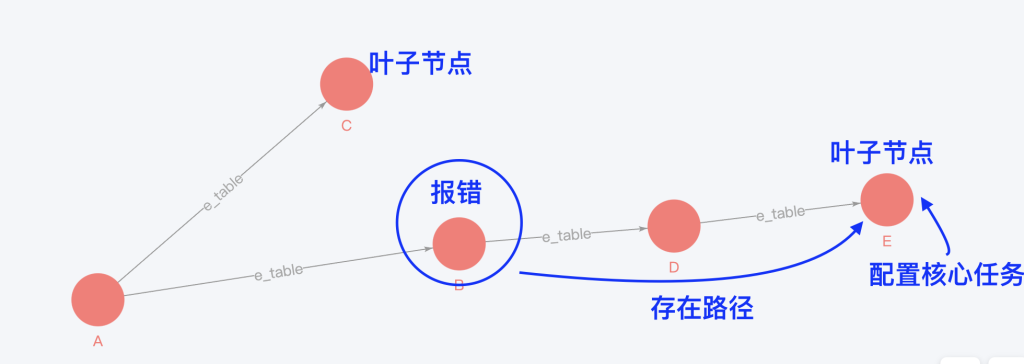
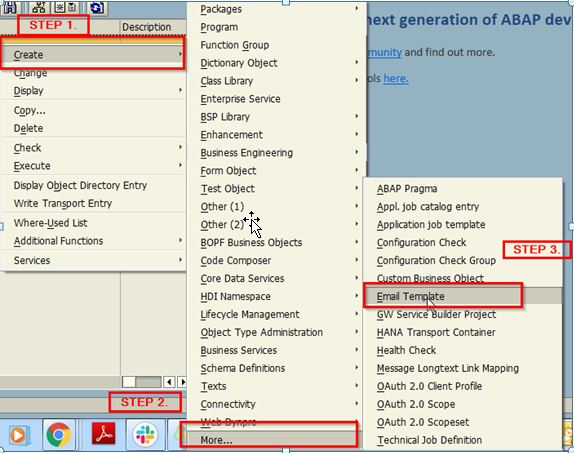
Apache DolphinScheduler使用图关系解决核心链路告警问题,减轻任务运维负担!
转载自程序员小陶 Apache DolphinScheduler 在使用过程中,肯定会有任务出现失败的情况,那么问题来了:调度任务的告警是需要人为配置的,在生产环境中,面对海量的任务,如何找到重要的任务,...

Apache DolphinScheduler用户线上Meetup火热来袭!
Apache DolphinScheduler 社区 8 月用户交流会精彩继续!本次活动邀请到老牌农牧产品实业集团铁骑力士架构工程师,来分享Apache DolphinScheduler在现代农牧食品加工场景中的应用实践。此外,还...

ambari2.8+ambari-metrics3.0+bigtop3.2编译、打包、安装
bigtop编译 资源说明: 软件及代码镜像 开发包镜像 github访问 编译相关知识 技术知识 bigtop编译流程及经验总结 各模块编译难度及大概耗时(纯编译耗时,不包含下载文件和排错时间) centos 真...

ClickHouse的向量处理能力
ClickHouse的向量处理能力 引言 在过去,非结构化数据(如文本、图片、音频、视频)通常被认为难以在数据库中直接使用,因为这些数据类型的多样性和复杂性。然而,随着技术的发展,嵌入技术可以...
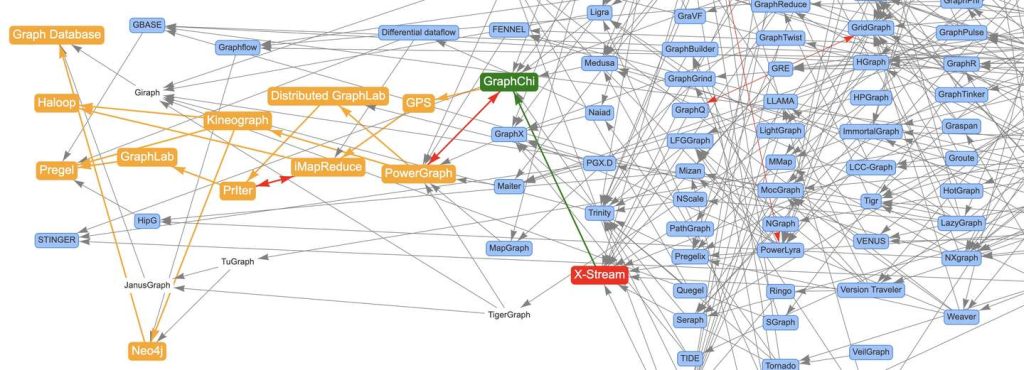
我用Awesome-Graphs看论文:解读X-Stream
X-Stream论文:《X-Stream: Edge-centric Graph Processing using Streaming Partitions》 前面通过文章《论文图谱当如是:Awesome-Graphs用200篇图系统论文打个样》向大家介绍了论文图谱项目Aw...

ambari+ bigtop 编译、打包、部署步骤总览
1 ambari + bigtop 构建大数据基础平台 1.1 参考: 1.2 参考 amabri bigtop 打包部署 2 ambari+bigtop编译、打包、部署 2.0 基础环境准备 2.1 ambari编译 2.2 ambari-metrics编译 2.3 bigtop编...
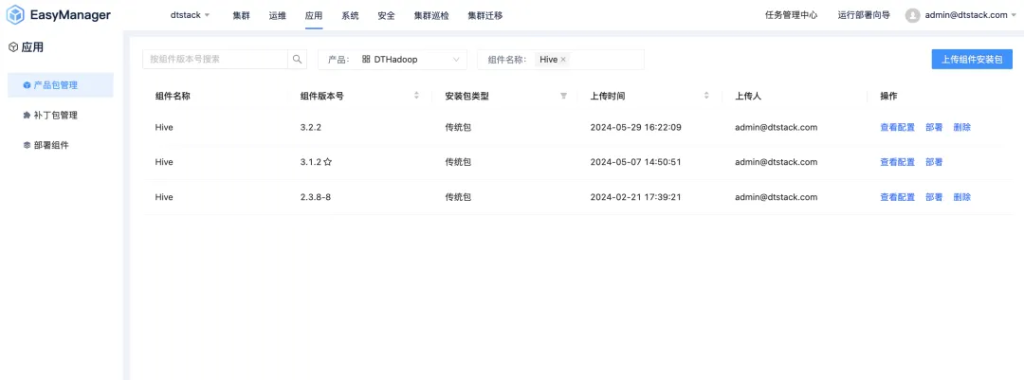
优化数据处理效率,解读 EasyMR 大数据组件升级
EasyMR 作为袋鼠云基于云原生技术和 Hadoop、Hive、Spark、Flink、Hbase、Presto 等开源大数据组件构建的弹性计算引擎。此前,我们已就其展开了多方位、多角度的详尽介绍。而此次,我们成功接入...
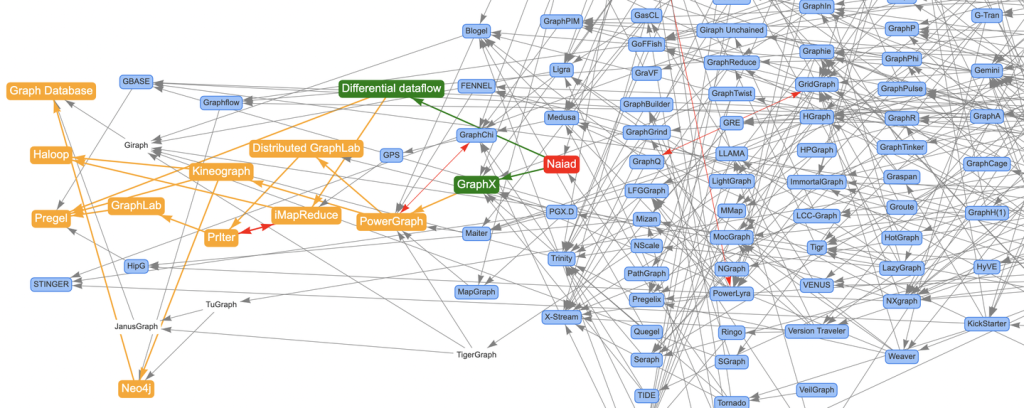
我用Awesome-Graphs看论文:解读Naiad
Naiad论文:《Naiad: A Timely Dataflow System》 前面通过文章《论文图谱当如是:Awesome-Graphs用200篇图系统论文打个样》向大家介绍了论文图谱项目Awesome-Graphs,并分享了Google的Pregel、...
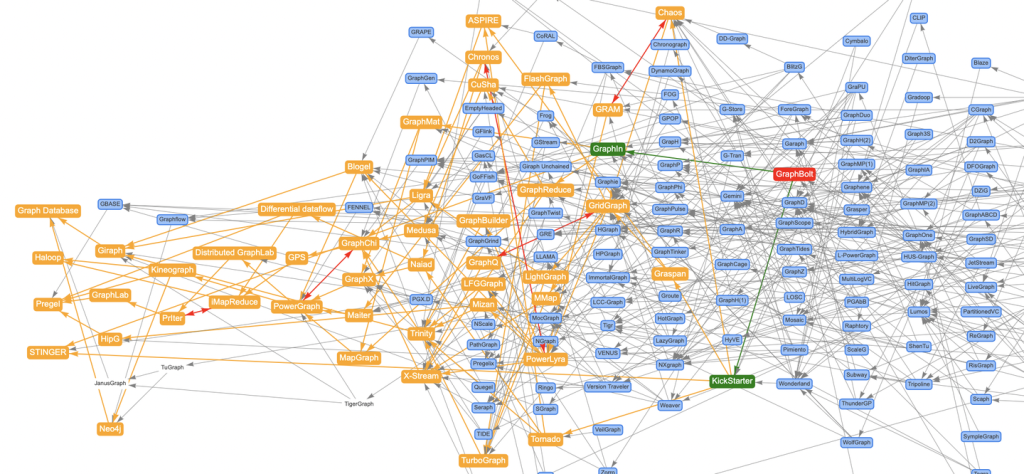
我用Awesome-Graphs看论文:解读GraphBolt
GraphBolt论文:《GraphBolt: Dependency-Driven Synchronous Processing of Streaming Graphs》 前面通过文章《论文图谱当如是:Awesome-Graphs用200篇图系统论文打个样》向大家介绍了论文图谱...