分类
标签
排序

关键词感知检索
本文主要介绍带关键词感知能力的向量检索服务的优势、应用示例以及Sparse Vector生成工具。 背景介绍 关键词检索及其局限 在信息检索领域,'传统'方式是通过关键词进行信息检索,其大致过程为:...

hive基础知识分享(三)
写在前面 今天继续学习hive部分的知识。 Hive中如何实现行列转换 一行变多行 可以对表使用 LATERAL VIEW EXPLODE(),也可以直接使用 EXPLAIN() 函数来处理一行数据。 SELECT name, col1 FROM te...

hive基础知识分享(二)
写在前面 今天继续学习hive部分的知识。 Hive 相关知识 hive中不同的 count 区别 select clazz ,count(distinct id) as cnt ,count(*) as cnt ,count(1) as cnt_1 ,count(id) as cnt_id from st...
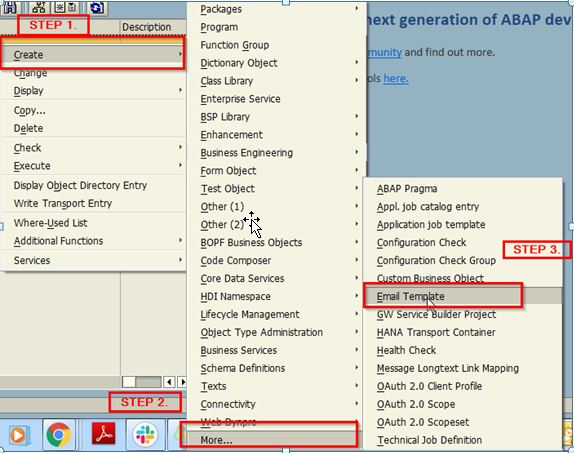
Apache DolphinScheduler + OceanBase,搭建分布式大数据调度平台的实践
本文整理自白鲸开源联合创始人,Apache DolphinScheduler PMC Chair,Apache Foundation Member 代立冬的演讲。主要介绍了DolphinScheduler及其架构、DolphinScheduler与OceanBase 的联合大数据...

袋鼠云港口数智化解决方案发布,数智引领,加速“智变”丨2024袋鼠云秋季发布会回顾
2023年12月,交通运输部印发《关于加快智慧港口和智慧航道建设的意见》,《意见》贯穿了“3条主线”,其中最首要的主线是“数字化”,数字化是基础,必须通过数字赋能建设、生产、运营、管理、...

hive基础知识分享(一)
写在前面 今天来学习hive部分的知识。 Hive 相关概念 Hive是什么? Apache Hive 是一个基于 Hadoop 的数据仓库工具,旨在通过 SQL 类似的查询语言(称为 HiveQL)来实现对存储在 HDFS(Hadoop D...
TableFill:一天搞定1000人的数据填报工作丨2024袋鼠云秋季发布会回顾
10月30日,袋鼠云成功举办了以“AI驱动,数智未来”为主题的2024年秋季发布会。大会深度探讨了如何凭借 AI 实现新的飞跃,重塑企业的经营管理方式,加速数智化进程。 会上,易知微产品经理林树...

Spark Streaming监听HDFS文件(Spark-shell)
需求:编写程序利用Spark Streaming 监控HDFS 目录/input目录下的文件,并对上传的文件进行词频统计。 首先,linux中需要有netcat,来实现监听功能,有的linux会自带这个软件,可以用下面...

利用 AWS 的事件驱动数据网格架构应对现代数据挑战
背景 在当今数据驱动的世界中,企业必须适应数据管理、分析和利用方式的快速变化。传统的集中式系统和单片式架构虽然在历史上已经足够,但已无法满足企业日益增长的需求,因...

DashText-快速开始
快速开始 DashText,是向量检索服务DashVector推荐使用的稀疏向量编码器(Sparse Vector Encoder),DashText可通过BM25算法将原始文本转换为稀疏向量(Sparse Vector)表达,通过DashText可大...