分类
标签
排序
EasyMR6.2 全面解读:四大功能深度优化,解锁全新大数据处理和计算体验
在刚刚过去的2024春季发布会上,袋鼠云带来了数栈产品V6.2版本的全新发布。其中,EasyMR 作为数栈V6.2中的一项关键能力,代表了袋鼠云对大数据生态的深入理解和持续创新。 EasyMR(后文统称EMR...
玩转云端 | 拥有HBlock这项“存储盘活绝技”,数据中心也能“热辣瘦身”!
夏天马上就要到了,“瘦身”不光是特定人群的需求,也是数据中心的需求。构建轻量化、低碳化、高性价比的新型数据中心,更有效地支撑经济社会数字化转型,已成为业界主流趋势。 如何让数据中心...

告别手动调度,海豚调度器 3.1.x 集群部署让你轻松管理多机!
转载自第一片心意 1 前言 由于海豚调度器官网的集群部署文档写的较乱,安装过程中需要跳转到很多地方进行操作,所以自己总结了一篇可以直接跟着从头到尾进行操作的文档,以方便后续的部署、升级...

手把手教你掌握SeaTunnel k8s运行Zeta引擎本地模式的技巧
转载自小虾米0.0 导读:随着Kubernetes的普及和发展,越来越多的企业和团队开始使用Kubernetes来管理和部署应用程序。然而,Kubernetes的默认工作方式可能不是最佳的选择,尤其是在需要更高效、...

指标+AI:迈向智能化,让指标应用更高效
近日,以“Data+AI,构建新质生产力”为主题的袋鼠云春季发布会圆满落幕,大会带来了一系列“+AI”的数字化产品与最新行业沉淀,旨在将数据与AI紧密结合,打破传统的生产力边界,赋能企业实现更...

对接HiveMetaStore,拥抱开源大数据
本文分享自华为云社区《对接HiveMetaStore,拥抱开源大数据》,作者:睡觉是大事。 1. 前言 适用版本:9.1.0及以上 在大数据融合分析时代,面对海量的数据以及各种复杂的查询,性能是我们使用一...

用DolphinScheduler轻松实现Flume数据采集任务自动化!
转载自天地风雷水火山泽 目的 因为我们的数仓数据源是Kafka,离线数仓需要用Flume采集Kafka中的数据到HDFS中。 在实际项目中,我们不可能一直在Xshell中启动Flume任务,一是因为项目的Flume任务...

利用 Amazon EMR Serverless、Amazon Athena、Apache Dolphinscheduler 以及本地 TiDB 和 HDFS 在混合部署环境中构建无服务器数据仓库(一)云上云下数据同步方案设计
引言 在数据驱动的世界中,企业正在寻求可靠且高性能的解决方案来管理其不断增长的数据需求。本系列博客从一个重视数据安全和合规性的 B2C 金融科技客户的角度来讨论云上云下混合部署的情况下如...

实战干货|Spark 在袋鼠云数栈的深度探索与实践
Spark 是一个快速、通用、可扩展的大数据计算引擎,具有高性能、易用、容错、可以与 Hadoop 生态无缝集成、社区活跃度高等优点。在实际使用中,具有广泛的应用场景: · 数据清洗和预处理:在大...
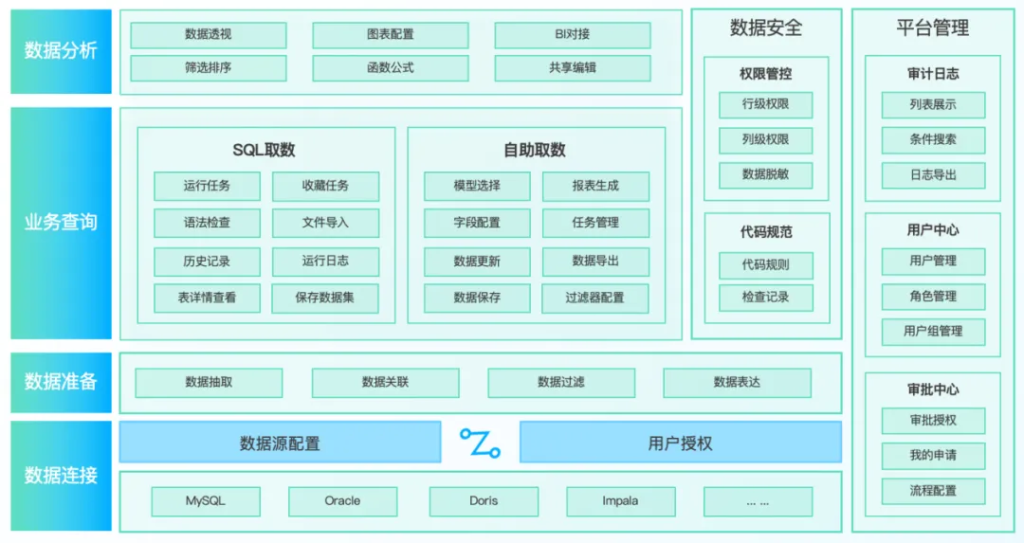
金融案例:统一查询方案助力数据治理与分析应用更高效、更安全
随着企业数据规模的增长和业务多元化发展,海量数据实时、多维地灵活查询变成业务常见诉求。同时多套数据库系统成为常态,这既带来了数据管理的复杂性,又加大了数据使用的难度,面对日益复杂的...