
应用层需要 AI 编译器


应用层需要 AI 编译器 从硬件角度以及底层软件的角度来看待为什么需要 AI 编译器的,而现在可以换一个上层应用视角来看待这个问题。 以深度神经网络为技术基础的人工智能领域在近些年发展十分迅速,从 10 年前,AI 技术可能只能解决图形分类等较为简单的任务,但如今无论是推荐系统、大语言模型、自动驾驶甚至 AI4S 等领域已经取得了十分显著的发展。 如今,AI 算法已经在很多领域取得了显著成果,这直接促进了 AI 算法的爆发式增长。同时,当前越来越多的公司愿意投入人力物理去开发自己的 AI 框架,这却间接导致了 AI 框架的碎片化和多样化。还有因地缘政治等因素,AI 芯片也变得加多样性,而不同的 AI 芯片都有着自己的编译体系,如图8-4所示。
![图片[1]-应用层需要 AI 编译器-后端开发牛翰社区-编程开发-牛翰网](https://niuimg.niucores.com/wp-content/uploads/2024/09/8003894586569845014.png) 图8-4 编译技术广泛运用于各种应用场景 目前,AI 领域的快速发展,导致每天都有各种各样的不同的 AI 算法被提出,这直接导致了两个重要的挑战。 第一个就是对于算子的优化,随着越来越来多的 AI 算法的诞生,这带来了更多的新算子。虽然简单的实现一个算子并不算是特别难的事情,但是这些算子还需要放在特定的 AI 芯片上进行优化,充分发挥硬件性能。而目前阶段算子的开发和维护还是以人工手动实现、优化、测试为主的,人工优化算子的工作量是非常大的。 虽然硬件供应商会发布一些通用性的优化算子库(如 MKL-DNN 和 CuDNN),但从人力成本的角度来说,这种工作是极度重复性的,MKL-DNN 和 CuDNN 背后是相似的算法,只不过由不同的公司两批不同的人来做的而已。从现实意义的角度,感觉意义并没有那么大。同时,硬件供应商提供优化后的算子库,一定程度上会限制用户编程的灵活性导致无法真正充分的发挥硬件性能,如图8-5所示。
图8-4 编译技术广泛运用于各种应用场景 目前,AI 领域的快速发展,导致每天都有各种各样的不同的 AI 算法被提出,这直接导致了两个重要的挑战。 第一个就是对于算子的优化,随着越来越来多的 AI 算法的诞生,这带来了更多的新算子。虽然简单的实现一个算子并不算是特别难的事情,但是这些算子还需要放在特定的 AI 芯片上进行优化,充分发挥硬件性能。而目前阶段算子的开发和维护还是以人工手动实现、优化、测试为主的,人工优化算子的工作量是非常大的。 虽然硬件供应商会发布一些通用性的优化算子库(如 MKL-DNN 和 CuDNN),但从人力成本的角度来说,这种工作是极度重复性的,MKL-DNN 和 CuDNN 背后是相似的算法,只不过由不同的公司两批不同的人来做的而已。从现实意义的角度,感觉意义并没有那么大。同时,硬件供应商提供优化后的算子库,一定程度上会限制用户编程的灵活性导致无法真正充分的发挥硬件性能,如图8-5所示。
![图片[2]-应用层需要 AI 编译器-后端开发牛翰社区-编程开发-牛翰网](https://niuimg.niucores.com/wp-content/uploads/2024/09/1372763597946773286.png) 图8-5编译技术支持通用性的优化算子库 第二个重大挑战是性能可移植性十分困难。由于大多数 NPU 使用 ASIC 设计芯片,其在神经网络场景对计算、存储和数据搬运做了很多特殊的指令优化,这使得与 AI 相关的计算得到了巨大的性能提升,比如 NVIDIA 在其一些芯片中提供的张量核 计算单元。如果相关 AI 框架使用了张量核 来优化其计算性能,必然会带来难以移植的问题。不同芯片有的提供类似 Tenosr Core 的矩阵计算单元,有的不提供。提供了矩阵计算单元的不同芯片,其编程范式又极不相同,这是限制可移植性的重要原因,如图8-6所示。 不同芯片厂商提供 XPU 的 ISA(Instruction Set Architectrue)千奇百怪,各不相同。而当前阶段又缺乏如 GCC、LLVM 等编译工具链,这使得针对 CPU 和 GPU 已有的优化算子库和针对语言的优化 Pass 很难移植到 NPU 上。这样的现状可能对于某个较为领先的硬件厂商来说是技术壁垒,是一种优势,但随着技术的不断发展,很多 idea 会被不断地相互借鉴,不断整合类似的 Pass,在 AI 编译器领域推出一个类似于 GCC 或者 LLVM 的编译器是非常有必要的。这会极大的促进 AI 领域的发展!
图8-5编译技术支持通用性的优化算子库 第二个重大挑战是性能可移植性十分困难。由于大多数 NPU 使用 ASIC 设计芯片,其在神经网络场景对计算、存储和数据搬运做了很多特殊的指令优化,这使得与 AI 相关的计算得到了巨大的性能提升,比如 NVIDIA 在其一些芯片中提供的张量核 计算单元。如果相关 AI 框架使用了张量核 来优化其计算性能,必然会带来难以移植的问题。不同芯片有的提供类似 Tenosr Core 的矩阵计算单元,有的不提供。提供了矩阵计算单元的不同芯片,其编程范式又极不相同,这是限制可移植性的重要原因,如图8-6所示。 不同芯片厂商提供 XPU 的 ISA(Instruction Set Architectrue)千奇百怪,各不相同。而当前阶段又缺乏如 GCC、LLVM 等编译工具链,这使得针对 CPU 和 GPU 已有的优化算子库和针对语言的优化 Pass 很难移植到 NPU 上。这样的现状可能对于某个较为领先的硬件厂商来说是技术壁垒,是一种优势,但随着技术的不断发展,很多 idea 会被不断地相互借鉴,不断整合类似的 Pass,在 AI 编译器领域推出一个类似于 GCC 或者 LLVM 的编译器是非常有必要的。这会极大的促进 AI 领域的发展!
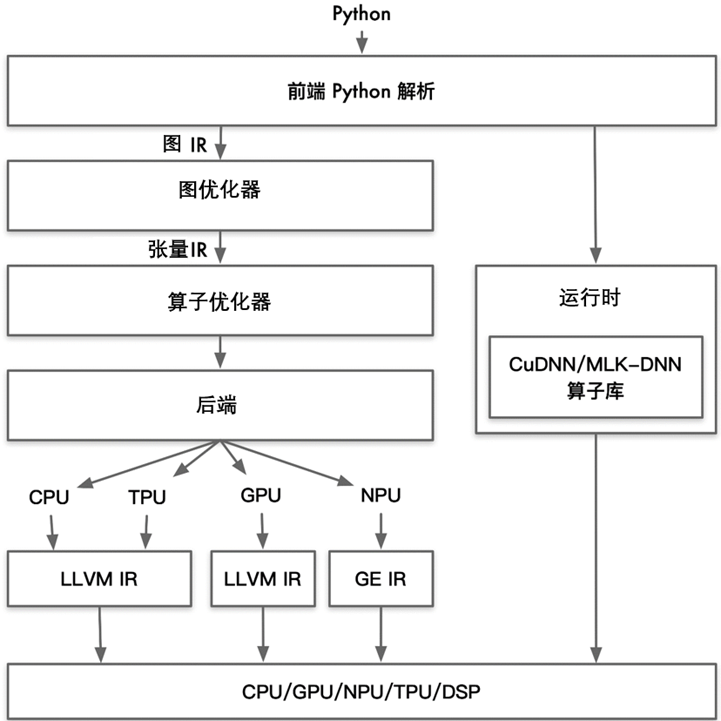 图8-6编译技术支持性能可移植性
图8-6编译技术支持性能可移植性





没有回复内容